1、Pandas 文本处理
Pandas 文本处理操作实例
在本章中,我们将使用基本的Series / Index讨论字符串操作。在随后的章节中,我们将学习如何在DataFrame上应用这些字符串函数。
Pandas提供了一组字符串函数,可以轻松地对字符串数据进行操作。最重要的是,这些函数忽略(或排除)缺少的/ NaN值。
几乎所有这些方法都可用于Python字符串函数(请参阅: https://docs.python.org/3/library/stdtypes.html#string-methods)。因此,将Series对象转换为String对象,然后执行该操作。
我们看看每个操作如何执行。
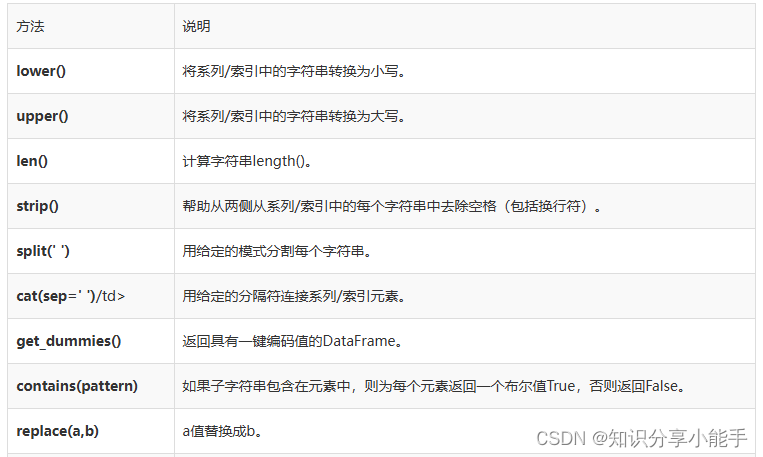
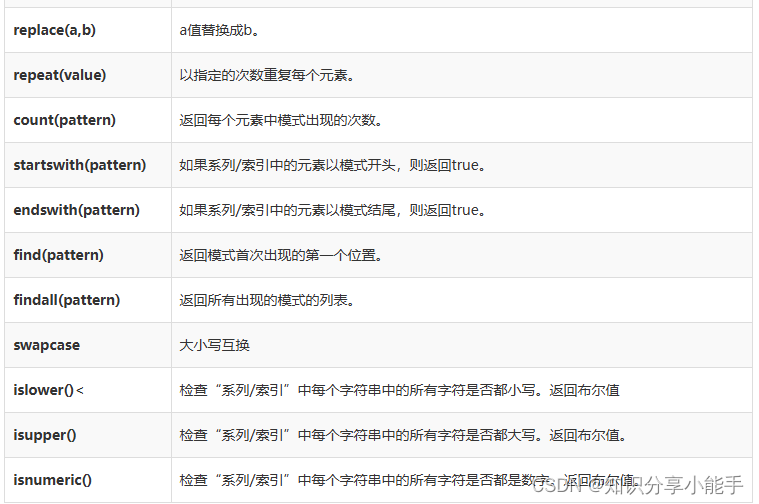
我们来创建一个Series,看看以上所有功能如何工作。
import pandas as pd
import numpy as np
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith'])
print(s)
运行结果:
0 Tom
1 William Rick
2 John
3 Alber@t
4 NaN
5 1234
6 SteveSmith
dtype: object
1.1、lower()
import pandas as pd
import numpy as np
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234', 'SteveSmith'])
print(s.str.lower())
运行结果:
0 tom
1 william rick
2 john
3 alber@t
4 NaN
5 1234
6 stevesmith
dtype: object
1.2、upper()
import pandas as pd
import numpy as np
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith'])
print(s.str.upper())
运行结果:
0 TOM
1 WILLIAM RICK
2 JOHN
3 ALBER@T
4 NaN
5 1234
6 STEVESMITH
dtype: object
1.3、len()
import pandas as pd
import numpy as np
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith'])
print(s.str.len())
运行结果:
0 3.0
1 12.0
2 4.0
3 7.0
4 NaN
5 4.0
6 10.0
dtype: float64
1.4、strip()
import pandas as pd
import numpy as np
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print s
print ("After Stripping:")
print(s.str.strip())
运行结果:
0 Tom
1 William Rick
2 John
3 Alber@t
dtype: object
After Stripping:
0 Tom
1 William Rick
2 John
3 Alber@t
dtype: object
1.5、split(pattern)
import pandas as pd
import numpy as np
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print s
print ("Split Pattern:")
print(s.str.split(' '))
运行结果:
0 Tom
1 William Rick
2 John
3 Alber@t
dtype: object
Split Pattern:
0 [Tom, , , , , , , , , , ]
1 [, , , , , William, Rick]
2 [John]
3 [Alber@t]
dtype: object
1.6、cat(sep=pattern)
import pandas as pd
import numpy as np
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.cat(sep='_'))
运行结果:
Tom _ William Rick_John_Alber@t
1.7、get_dummies()
import pandas as pd
import numpy as np
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.get_dummies())
运行结果:
William Rick Alber@t John Tom
0 0 0 0 1
1 1 0 0 0
2 0 0 1 0
3 0 1 0 0
1.8、contains ()
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.contains(' '))
运行结果:
0 True
1 True
2 False
3 False
dtype: bool
1.9、replace(a,b)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print s
print ("After replacing @ with $:")
print(s.str.replace('@','))
运行结果:
0 Tom
1 William Rick
2 John
3 Alber@t
dtype: object
After replacing @ with $:
0 Tom
1 William Rick
2 John
3 Alber$t
dtype: object
1.10、repeat(value)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.repeat(2))
运行结果:
0 Tom Tom
1 William Rick William Rick
2 JohnJohn
3 Alber@tAlber@t
dtype: object
1.11、count(pattern)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print ("每个字符串中的“ m”数:")
print(s.str.count('m'))
运行结果:
每个字符串中的“ m”数:
0 1
1 1
2 0
3 0
1.12、startswith(pattern)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print ("Strings that start with 'T':")
print(s.str. startswith ('T'))
运行结果:
0 True
1 False
2 False
3 False
dtype: bool
1.13、endswith(pattern)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print ("Strings that end with 't':")
print(s.str.endswith('t'))
运行结果:
Strings that end with 't':
0 False
1 False
2 False
3 True
dtype: bool
1.14、 find(pattern)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.find('e'))
运行结果:
0 -1
1 -1
2 -1
3 3
dtype: int64
“ -1”表示元素中没有匹配到。
1.15 、findall(pattern)
import pandas as pd
s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t'])
print(s.str.findall('e'))
运行结果:
0 []
1 []
2 []
3 [e]
dtype: object
空列表([])表示元素中没有匹配到
1.16、swapcase()
import pandas as pd
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t'])
print(s.str.swapcase())
运行结果:
0 tOM
1 wILLIAM rICK
2 jOHN
3 aLBER@T
dtype: object
1.17、islower()
import pandas as pd
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t'])
print(s.str.islower())
运行结果:
0 False
1 False
2 False
3 False
dtype: bool
1.18、isupper()
import pandas as pd
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t'])
print(s.str.isupper())
运行结果:
0 False
1 False
2 False
3 False
dtype: bool
1.19、isnumeric()
import pandas as pd
s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t'])
print(s.str.isnumeric())
运行结果:
0 False
1 False
2 False
3 False
dtype: bool



![[Android]将私钥(.pk8)和公钥证书(.pem/.crt)合并成一个PKCS#12格式的密钥库文件](https://img-blog.csdnimg.cn/direct/254530f1f33f4653ba488c11ae8a58aa.png)