参考资料
- CloudWatch代理配置参考
- Prometheus的CloudWatch代理配置
本文旨在明确以下几个问题
- eks的container insight addon包括哪些组件?分别起什么作用?
- eks的cwagent的指标获取具体包括那些部分?数据源是什么?
- eks的cwagent如何获取eks性能指标?
- eks的cwagent如何将采集的eks性能指标发送到cloudwatch?
- eks的cwagent如何获取peometheus相关exporter指标?
- eks的cwagent如何将采集的promethes指标发送到cloudwatch?
建议不要跳读,本文总体结构如下图
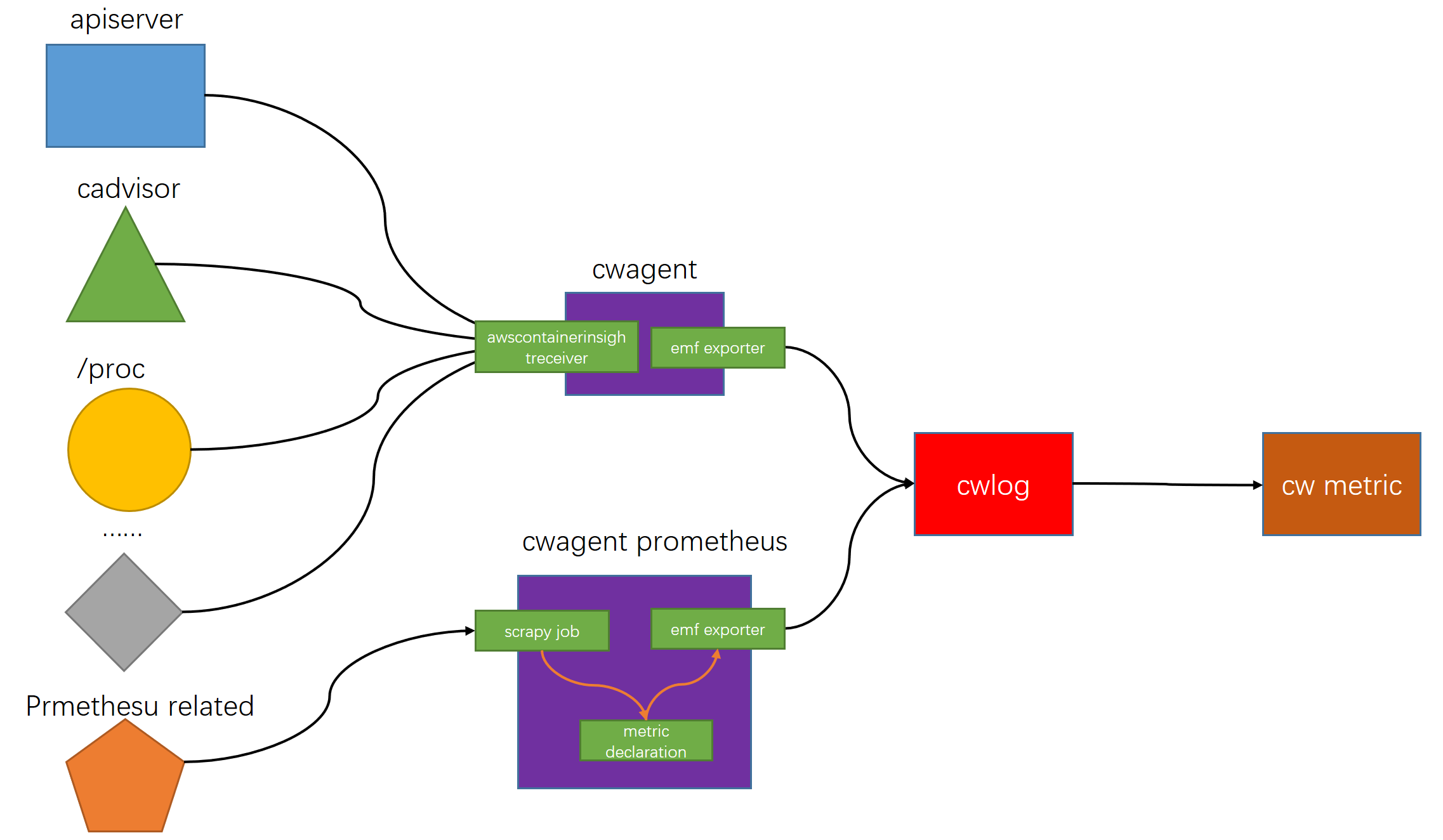
逻辑上container insight需要收集三部分内容,包括指标,追踪和日志。负责这三部分数据的组件分别为cwagent(前两者)和fluentbit,这里我们只讨论cwagent的运行过程。
总的来看,container insight能够获取的指标包括两部分:1. eks性能指标。2. prometheus指标
eks基本性能指标
我们首先来看开启安装container insight addon之后获取的eks基本指标部分。
首先简单解释下emf日志,emf可以理解为aws定义的指标数据格式,当按照emf规范发送日志文件到cw log(api为PutLogEvents)时,会自动在cw的对应namespace中生成指标。例如示例中的程序运行之后,会在MyApp命名空间下生成指标ProcessingLantency
也就是说cwagent在收集eks性能指标和prometheus指标时,是通过性能日志的方式发送到cwlog,然后由cw来异步生成自定义指标
开启可观察性addon之后,查看eks中cwagent的默认配置如下,其中有个参数叫enhanced_container_insights
{"agent":{"region":"cn-north-1"},"logs":{"metrics_collected":{"app_signals":{"hosted_in":"test127"},"kubernetes":{"cluster_name":"test127","enhanced_container_insights":true}}},"traces":{"traces_collected":{"app_signals":{}}}}
让我们来看一下这个名为enhanced_container_insights的参数具体是在做什么?首先是这个translate函数,从注释中可以看出该函数会将集群中cwagent的cm配置文件转换为otel配置。因此,实际上cwagent上传emf格式的日志文件直接复用了otel exporter的逻辑,可以直接将其看作otel collector的exporter部分。关于otel的内容,可以将其理解为数据管道,从不同的source接受指标数据,在经过处理后发送到不同的exporter中。
// Translate creates an awsemf exporter config based on the input json config
func (t *translator) Translate(c *confmap.Conf) (component.Config, error) {
这一点实际在cwagent的日志中已经出现端倪,例如其中的kind":"exporter","data_type":"metrics
2024-04-13T10:39:58Z I! {"caller":"awsemfexporter@v0.89.0/emf_exporter.go:119","msg":"Start processing resource metrics","kind":"exporter","data_type":"metrics","name":"awsemf/containerinsights","labels":{"http.scheme":"https","k8s.namespace.name":"amazon-cloudwatch","net.host.name":"neuron-monitor-service.amazon-cloudwatch.svc","
net.host.port":"8000","service.instance.id":"neuron-monitor-service.amazon-cloudwatch.svc:8000","service.name":"containerInsightsNeuronMonitorScraper"}}
而以下判断环境的标准,就是cwagent配置文件的metrics_collected部分是否有对应的字段
// 环境的判断逻辑
if t.isAppSignals(c) {
defaultConfig = getAppSignalsConfig()
} else if isEcs(c) {
defaultConfig = defaultEcsConfig
} else if isKubernetes(c) {
defaultConfig = defaultKubernetesConfig // 对应enhanced_container_insights的部分
} else if isPrometheus(c) {
defaultConfig = defaultPrometheusConfig
} else {
return cfg, nil
}
// 具体的判断逻辑如下,prometheus指标对应的就是EMFProcessorKey这部分配置
prometheusBasePathKey = common.ConfigKey(common.LogsKey, common.MetricsCollectedKey, common.PrometheusKey)
emfProcessorBasePathKey = common.ConfigKey(prometheusBasePathKey, common.EMFProcessorKey)
// 字段实际代表的字面值
MetricsCollectedKey = "metrics_collected"
PrometheusKey = "prometheus"
EMFProcessorKey = "emf_processor"
最终转换之后的yaml文件为示例文件,这也是性能日志组名称为/aws/containerinsights/{ClusterName}/performance来由
按照以上逻辑,那么最终转换后的cwagent配置也需要按照otel emfexporter的配置方式进行配置,并且最终的eks性能日志种类和配置文件也能逐一对应上。
综上所述,一个简单的enhanced_container_insights参数实际上会生成一系列的eks性能日志,这暂时和prometheus没有关系。
eks中的prometheus指标
实际上文档中明确提到cwagent针对prometheus指标进行了定制,“支持Prometheus 的 CloudWatch 代理可发现并收集 Prometheus 指标”
那什么叫适用于prometheus的cwagent?eks集群中的组件cwagent-prometheus和cwagent有什么区别?
实际上,cwagent需要两种配置来抓取prometheus指标
- prometheus配置文件
- cwagent配置文件
这个cwagent-prometheus和通过addon默认安装的cwagent是两个相同的容器,区别仅仅是配置文件不同,字段从kubernetes变更为prometheus。配置文件如下,这部分对应文档中提到的默认支持的组件指标
- 以下配置文件的解释参考,会匹配prometheus上带有Service标签的指标,并检查内容是否符合label_matcher的正则表达式 规则
{
"logs": {
"metrics_collected": {
"prometheus": {
"prometheus_config_path": "/etc/prometheusconfig/prometheus.yaml",
"emf_processor": {
"metric_declaration": [
"source_labels": ["Service"],
"label_matcher": ".*nginx.*",
...
}
结合上面的结论和pod日志,可见prometheus同样是通过otel exporter发送的,只不过这里的name为awsemf/prometheus。prometheus性能日志日志组为/aws/containerinsights/{ClusterName}/prometheus
2024-04-13T11:01:04Z I! {"caller":"awsemfexporter@v0.89.0/emf_exporter.go:164","msg":"Finish processing resource metrics","kind":"exporter","data_type":"metrics","name":"awsemf/prometheus","labels":{}}
我们来看cwagent-prometheus的日志,首先将配置文件转换为toml,之后再将其转换为yaml文件
2024/04/13 14:28:32 I! Config has been translated into TOML /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml
2024/04/13 14:28:32 I! Config has been translated into YAML /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.yaml
最终形成的文件确实是otel的exporter配置
exporters:
awsemf/prometheus:
...
log_group_name: /aws/containerinsights/<cluster-name>/prometheus
log_stream_name: '{JobName}'
...
和eks性能日志相比,有一点显著的不同。即eks性能日志的指标来源来自于cadvisor,实例/proc,pod本身,apiserver。而prometheus的指标来自于应用程序的exporter。
因此知道了cwagent如何将prometheus指标发送到cw,下一个问题是cwagent从哪里获取到prometheus指标呢?
以ecs中的java/JMX指标为例,jvm指标实际上是通过JMX Exporter获取到的,并通过指定端口暴露为promethes格式的指标文本,cwagent则会抓取这些指标并发送到cw log中
- ecs中的支持prometheus的cwagent并不是托管,开启container insight并不会自动捕获这部分指标,需要额外部署sidecar
- 如果需要捕获任务的prometheus指标,需要指定任务容器的dockerLabels,包括ECS_PROMETHEUS_EXPORTER_PORT(任务的prometheus指标暴露的端口)和Java_EMF_Metrics(是否开启cwagent的emf嵌入式指标收集)
- 示例模板中显示cwagent的配置文件中,prometheus部分代表cwagent对prometheus指标的服务发现配置,emf_processor部分则代表导出emf日志的匹配逻辑,如果任务的dockerLables中包括Java_EMF_Metrics,则会将prometheus导出为emf日志
同样eks的示例中可以看到cwagent-prometheus(支持prometheus)会从 http://CLUSTER_IP:9404/metrics收集指标,其中9404是jmx导出器的默认端口
- apiserver中的指标是cwagent通过kubernetes_sd_config中的pod部分自动发现的(这部分类似于prometheus的运行逻辑),具体的配置为名为prometheus-config的configmap
- 可见在eks中cwagent首先通过服务发现获取pod指标,然后将其转化为emf格式发送到cwlog,之后通过emf的异步加载机制转化为cw指标
在cwagent的plugins/inputs/prometheus部分存在如下逻辑,可见即使不安装prometheus,cwagent-prometheus也能够使用标准的prometheus配置文件来获取相关的指标(cwagent支持标准的prometheus抓取配置)。这应该也是cwagent-prometheus要用到prometheus配置文件的原因。作为印证,这篇文档也提到了prometheus工作负载的安全组要求,访问方向为cwagent-prometheus访问具体的pod
以下是相关的代码片段
// Start scraping prometheus metrics from prometheus endpoints
p.wg.Add(1)
go Start(p.PrometheusConfigPath, receiver, p.shutDownChan, &p.wg, mth)
为了进一步验证我们部署JMX应用,这里直接使用arthas的demo程序
wget https://arthas.aliyun.com/math-game.jar
java -jar math-game.jar
构建镜像
FROM openjdk:8-jre-alpine
RUN mkdir -p /opt/jmx_exporter
COPY ./jmx_prometheus_javaagent-0.19.0.jar /opt/jmx_exporter
COPY ./math-game.jar /opt/jmx_exporter
COPY ./start_exporter_example.sh /opt/jmx_exporter
COPY ./config.yaml /opt/jmx_exporter
RUN chmod -R o+x /opt/jmx_exporter
RUN apk add curl
ENTRYPOINT exec /opt/jmx_exporter/start_exporter_example.sh
配置文件为
---
rules:
- pattern: ".*"
启动脚本为
$ cat start_exporter_example.sh
java -javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent-0.19.0.jar=9404:/opt/jmx_exporter/config.yaml -jar /opt/jmx_exporter/math-game.jar
在eks上部署
apiVersion: apps/v1
kind: Deployment
metadata:
name: app4jvmexporter
namespace: default
labels:
app: app4jvmexporter
spec:
replicas: 1
selector:
matchLabels:
app: app4jvmexporter
template:
metadata:
labels:
app: app4jvmexporter
spec:
restartPolicy: Always
containers:
- name: app4jvmexporter
image: xxxxxxxxxxxx.dkr.ecr.cn-north-1.amazonaws.com.cn/jmxtest
imagePullPolicy: Always
使用以下命令验证JVM pod指标暴露
curl http://192.168.0.128:9404/metric
# HELP java_lang_MemoryPool_UsageThresholdSupported java.lang:name=Metaspace,type=MemoryPool,attribute=UsageThresholdSupported
# TYPE java_lang_MemoryPool_UsageThresholdSupported untyped
java_lang_MemoryPool_UsageThresholdSupported{name="Metaspace",} 1.0
java_lang_MemoryPool_UsageThresholdSupported{name="Eden Space",} 0.0
...
在实际scrap时出现指标不支持的问题,参考trouble shooting手段修改cwagent为debug模式查看具体丢弃的指标
2024-04-13T16:41:17Z D! [6/1000] Unsupported Prometheus metric: coredns_dns_request_duration_seconds_bucket with type: histogram
索性直接在原来的prometheus配置文件后面添加静态配置,ip地址是jmx pod的ip
- job_name: 'test-jmx-pod'
static_configs:
- targets: ["192.168.0.128:9404"]
查看日志实际上已经抓取到了,但是由于缺少metaData导致无法处理。经过测试这个和规则的标签有关,添加额外的relabel之后解决
2024-04-13T16:54:09Z E! metricsHandler NO metaData for jvm_memory_pool_allocated_bytes_created | 192.168.0.128:9404 | test-jmx-pod
之后出现类似以下报错,表明cwagent的metric declaration部分没有match
2024-04-13T16:59:02Z D! {"caller":"awsemfexporter@v0.89.0/metric_translator.go:285","msg":"Dropped batch of metrics: no metric declaration matched labels","kind":"exporter","data_type":"metrics
","name":"awsemf/prometheus","Labels":"{\"ClusterName\":\"test127\",\"instance\":\"192.168.0.128:9404\",\"job\":\"test-jmx-pod\",\"prom_metric_type\":\"gauge\",\"state\":\"NEW\"}","Metric Names
":["jvm_threads_state"]}
典型的性能日志如下
{
"ClusterName": "test127",
"Timestamp": "1713027659523",
"Version": "0",
"instance": "192.168.0.128:9404",
"job": "test-jmx-pod",
"jvm_memory_pool_bytes_committed": 1310720,
"jvm_memory_pool_bytes_init": 0,
"jvm_memory_pool_bytes_max": 1073741824,
"jvm_memory_pool_bytes_used": 1131256,
"pool": "Compressed Class Space",
"prom_metric_type": "gauge"
}
既然cwagent-prometheus能够抓取prometheus指标,那我们可以进一步定制指标吗?当然可以,文档中有个配置获取prometheus抓取apiserver的例子,最终发送的指标在ContainerInsights/Prometheus名称空间中
最后,知道了cwagent-prometheus是使用标准配置文件配置scrap job的,那么回过头来看cwagent获取eks集群性能日志这个逻辑,它是怎么获取这部分数据的呢?显然cwagent原生是没有这个能力的,所以标准配置文件中看不到这部分内容,这也是kubernetes和prometheus字段在这里不存在的原因。
既然cwagent能够抓取类似apiserver,cadvisor指标,那么就必然有个源头。结合上面的逻辑,很容易想到cwagent同样是通过prometheus的scrap任务获取eks性能日志的,并且通过直接和kubernetes服务发现功能集成实现无缝对接。只不过这里的prometheus配置文件是默认配置。
我们进一步来看cwagent为什么能够使用prometheus配置文件,参考adot文档的prometheus配置部分,和集群中cwagent-prometheus的配置简直如出一辙,那么我们就有理由猜测,不仅仅是导出到emf这部分,包括获取利用集群服务发现获取prometheus规范指标同样是利用otel的receiver来实现的。
To monitor your Kubernetes applications and clusters, we specifically use the
kubernetes_sd_configs. We can choose between various Kubernetes objects to discover and scrape including endpoints, pods, nodes, services and ingresses. For each of these objects, we provide a default configuration.The Prometheus Receiver monitors each applications deployment using the service endpoints. Specifically, it scrapes and collects metrics from the
/metricsendpoint
在receiver代码部分同样存在translate逻辑,并且显然不是emf exporter的配置参数
"WithKubernetes": {
input: map[string]interface{}{
"logs": map[string]interface{}{
"metrics_collected": map[string]interface{}{
"kubernetes": map[string]interface{}{
"metrics_collection_interval": float64(10),
"cluster_name": "TestCluster",
},
},
},
},
want: &awscontainerinsightreceiver.Config{
ContainerOrchestrator: eks,
CollectionInterval: 10 * time.Second,
ClusterName: "TestCluster",
LeaderLockName: "cwagent-clusterleader",
LeaderLockUsingConfigMapOnly: true,
TagService: true,
},
},
然后我们根据关键词awscontainerinsightreceiver就找到了cw对于otel的贡献部分,这里有一个专门的receiver名叫awscontainerinsightreceiver,所以cwagent实际上是复用了otel的receiver来获取性能指标的。
此外还有额外收获,"ECS 代理和 CloudWatch 代理支持 CloudWatch Container Insights,以收集许多资源(如 CPU、内存、磁盘和网络)的基础设施指标"这句话也解释了为什么我们在ecs中开启consight insight之后就拥有了收集容器指标的超能力,原来一切都是美好的otel
AWS Container Insights Receiver (
awscontainerinsightreceiver) is an AWS specific receiver that supports CloudWatch Container Insights. CloudWatch Container Insights collect, aggregate, and summarize metrics and logs from your containerized applications and microservices.The collector process needs root permission to be able to read the content of the files. This requirement comes from the fact that this component is based on cAdvisor.
综上看来,cwagent远比想象中能做的事更多, 通过集成otel库扩展了原有能力,能够对指标,日志和追踪进行全方位的支持。可以认为cwagent镜像就是个定制过的otel collector。


![[Android]将私钥(.pk8)和公钥证书(.pem/.crt)合并成一个PKCS#12格式的密钥库文件](https://img-blog.csdnimg.cn/direct/254530f1f33f4653ba488c11ae8a58aa.png)