基于LLM的优化器评测-非凸函数
- 目标函数
- 测试结果
- 测试代码
- 测试日志
背景:
很多时候我们需要为系统寻找最优的超参.比如模型训练,推理的量化等.本文尝试将LLM当成优化器,帮忙我们寻找最优的超参.
验证方法:
- 1.设计一个已知最优解的多项式,该多项式有3个变量(因为3个变量可以通过plot_surface+时间的方式可视化)
- 2.通过多轮对话的方式,让LLM根据我们的反馈输出下一组最优解,找到最优解后退出
- 3.测试不同的LLM供应商,比较其寻找最优超参的效率
- 4.测试了随机梯度下降算法、遗传算法、模拟退火算法、贝叶斯算法
小结
- 1.LLM可以做为优化器,求最优解,比传统的优化器效果好
目标函数
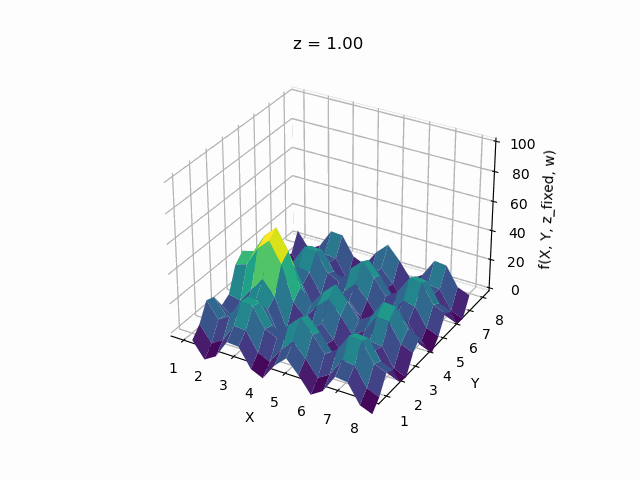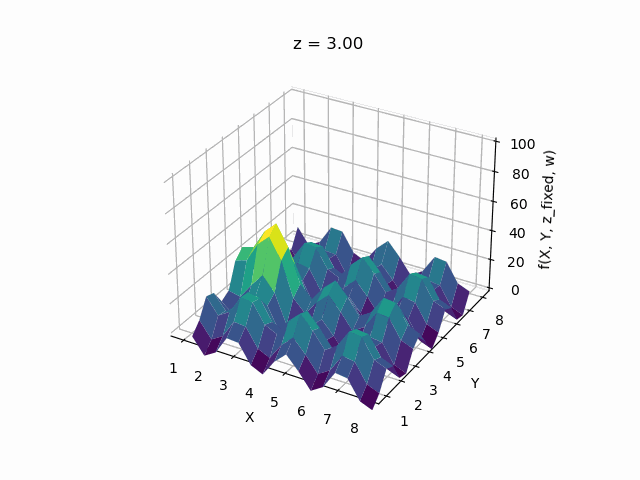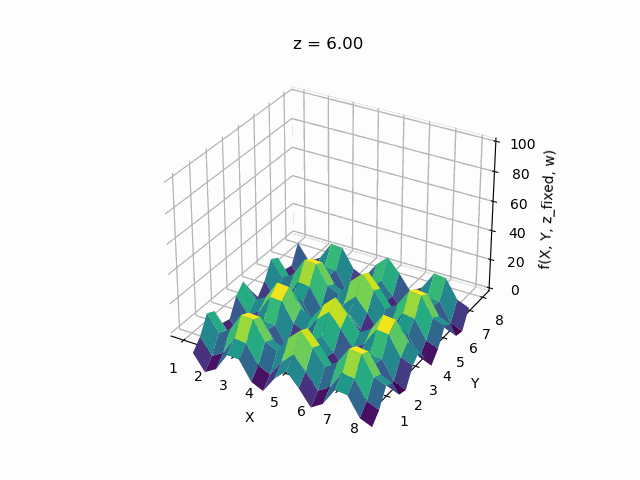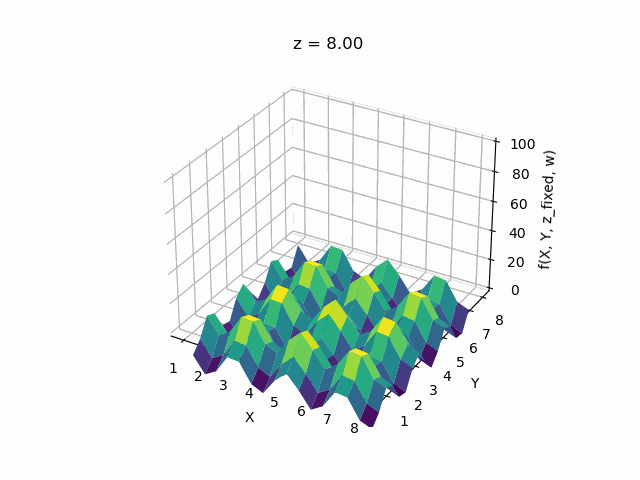
测试结果
| 模型 | 几次迭代找到了最优解 |
|---|---|
| dashscope(qwen-max) | 2 |
| moonshot(kimi moonshot-v1-128k) | 2 |
| qianfan(ERNIE-4.0-8K) | 6 |
| sparkai(3.5) | 30>没有找到最优解 |
| gemini(gemini-1.5-flash) | 1 |
| azure(gpt-4o) | 4 |
| 遗传算法 | 50 |
| 模拟退火算法 | 351 |
| pytorch随机梯度下降算法 | 30>没有找到最优解 |
| 贝叶斯算法 | 66 |
测试代码
import re
import os
import logging
import random
import numpy as np
import os
logger = logging.getLogger('llm_logger')
logger.setLevel(logging.DEBUG) # 设置日志级别
# 创建一个handler,用于写入日志文件
log_file = 'llm_opt_non_convex_function.log'
file_handler = logging.FileHandler(log_file)
file_handler.setLevel(logging.DEBUG)
# 创建一个handler,用于将日志输出到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
# 设置日志格式
formatter = logging.Formatter('%(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
# 将handlers添加到logger
logger.addHandler(file_handler)
logger.addHandler(console_handler)
system_prompt="你是一个人工助手,帮助用户进行参数优化"
constrain='''
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
'''
question =f'''
背景及需求:
我有二台8卡的GPU服务器手于训练一个LLM模型,因为不同的超参会导致不同的性能.我已经写好一个脚本,输入一些参数,运行脚本后,会输出训练的性能tokens/sec(这个值越大越好)。
我会告诉你有哪些输入参数以及它们的约束,你输出参数列表,之后我会利用你提供的参数列表运行训练脚本,得到tokens/sec,并将该值反馈给你。
你根据我的反馈,思考如何配置这些参数,可以让tokens/sec最大化。
通过这样不断的迭代,求出近似最优解
参数
1.HL_DP
2.HL_TP
3.HL_PP
{constrain}
明白我的要求了吗?,如果明白,请输出第一组参数列表
'''
import os
iters=0
def objective_function(X,Y,Z):
global iters
part1 = 100 * np.exp(-(X - 2)**2 - (Y - 4)**2 - (Z - 2)**2)
part2 = 10 * np.sin(X * 3) + 10 * np.cos(Y * 3) + 10 * np.sin(Z * 3)
output= part1 + part2
iters+=1
if output>=102:
logger.info("iters:{} find best var X:{:.2f} Y{:.2f} Z:{:.2f} OUT:{:.2f}".format(iters,X,Y,Z,output))
os._exit(0)
return output
def run_script(output):
params=re.findall(r'\[(.*?)\]',output)
if len(params)>0:
params=params[-1]
match=re.findall(r'.*HL_DP=(\d+).*HL_TP=(\d+).*HL_PP=(\d+)',params)
if len(match)>0:
match=[int(x) for x in match[0]]
HL_DP,HL_TP,HL_PP=match
if HL_DP*HL_TP*HL_PP!=16:
return f"非法参数,请重新输入.{constrain}"
speed=objective_function(HL_DP,HL_TP,HL_PP)
return f"经过测试,上面参数对应的性能为tokens/sec:{speed:.3f},请给出新的参数配置"
return f"非法参数,请重新输入.{constrain}"
def moonshot():
logger.info("\n ######################## moonshot ######################## ")
'''
pip install --upgrade 'openai>=1.0'
https://platform.moonshot.cn/docs/api/chat#多轮对话
'''
MOONSHOT_API_KEY="sk-"
from openai import OpenAI
client = OpenAI(
api_key = MOONSHOT_API_KEY,
base_url = "https://api.moonshot.cn/v1",
)
history = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question},
]
def chat(query, history):
if query is not None:
history.append({
"role": "user",
"content": query
})
completion = client.chat.completions.create(
model="moonshot-v1-128k",
messages=history,
temperature=0.3,
top_p=0.1
)
result = completion.choices[0].message.content
history.append({
"role": "assistant",
"content": result
})
return result
result=None
for i in range(30):
logger.info(f" ---------------------------------- iteration {i} ---------------------------------- ")
output=chat(result, history)
logger.info(output)
result= run_script(output)
logger.info(result)
def dashscope():
logger.info("\n ######################## dashscope ######################## ")
'''
https://help.aliyun.com/zh/dashscope/developer-reference/api-details?spm=a2c4g.11186623.0.0.45375120QTaSov
'''
from http import HTTPStatus
import dashscope
dashscope.api_key="sk-"
from dashscope import Generation
messages = [{'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': question}]
for i in range(30):
logger.info(f" ---------------------------------- 第{i}轮 ---------------------------------- ")
response = Generation.call(model="qwen-max", messages=messages,result_format='message')
if response.status_code == HTTPStatus.OK:
messages.append({'role': response.output.choices[0]['message']['role'],
'content': response.output.choices[0]['message']['content']})
output=response.output.choices[0]['message']['content']
logger.info(output)
result=f"{run_script(output)}"
logger.info(result)
messages.append({"role":"user","content":result})
else:
logger.info('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
break
def qianfan():
logger.info("\n ######################## qianfan ######################## ")
import qianfan
os.environ["QIANFAN_AK"] = ""
os.environ["QIANFAN_SK"] = ""
'''
pip install qianfan
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t
'''
messages = [{'role': 'user', 'content': question}]
for i in range(30):
logger.info(f" ---------------------------------- 第{i}轮 ---------------------------------- ")
response = qianfan.ChatCompletion().do(endpoint="completions_pro", messages=messages,
temperature=0.7, top_p=0.8, penalty_score=1,
disable_search=False, enable_citation=False)
messages.append({'role': "assistant",'content': response.body["result"]})
output=response.body["result"]
logger.info(output)
result=f"{run_script(output)}"
logger.info(result)
messages.append({"role":"user","content":result})
def sparkai():
logger.info("\n ######################## sparkai ######################## ")
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
'''
pip install --upgrade spark_ai_python
https://www.xfyun.cn/doc/spark/Web.html#_1-接口说明
'''
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
SPARKAI_DOMAIN = 'generalv3.5'
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
temperature=0.1
)
history = [
ChatMessage(role="system",content=system_prompt)
]
history.append(ChatMessage(role="user",content=question))
handler = ChunkPrintHandler()
for i in range(30):
logger.info(f" ---------------------------------- 第{i}轮 ----------------------------------")
a = spark.generate([history], callbacks=[handler])
history.append(a.generations[0][0].message)
output=a.generations[0][0].text
logger.info(output)
result=f"{run_script(output)}"
logger.info(result)
history.append(ChatMessage(role="user",content=result))
def gemini():
logger.info("\n ######################## gemini ######################## ")
'''
pip install google-generativeai
https://ai.google.dev/api/python/google/generativeai
'''
import google.generativeai as genai
genai.configure(api_key="")
model = genai.GenerativeModel('gemini-1.5-flash')
chat = model.start_chat(history=[])
response = chat.send_message(question)
for i in range(30):
logger.info(f" ---------------------------------- 第{i}轮 ----------------------------------")
output=response.text
logger.info(output)
result=f"{run_script(output)}"
logger.info(result)
response = chat.send_message(result)
def azure():
logger.info("\n ######################## azure ######################## ")
from openai import AzureOpenAI
endpoint = "https://xx-completion.openai.azure.com/"
deployment = "gpt-4o"
client = AzureOpenAI(
azure_endpoint=endpoint,
api_key="",
api_version="2024-02-01",
)
messages=[
{
"role": "assistant",
"content": "你是一个人工助手,帮助用户进行参数优化"
},
{
"role": "user",
"content": question
}
]
response = client.chat.completions.create(model=deployment,messages=messages)
for i in range(30):
logger.info(f" ---------------------------------- 第{i}轮 ----------------------------------")
output = response.choices[0].message.content
messages.append({"role": "assistant", "content": output})
logger.info(output)
result=f"{run_script(output)}"
messages.append({"role": "user", "content": result})
logger.info(result)
response = client.chat.completions.create(model=deployment,messages=messages)
def decode_chromosome(chromosome, bounds, num_genes):
""" 解码染色体为实际值 """
decoded_values = []
for i in range(len(bounds)):
binary_str = chromosome[i*num_genes:(i+1)*num_genes]
integer_value = int(''.join(map(str, binary_str)), 2)
value = int(bounds[i][0] + (bounds[i][1] - bounds[i][0]) * integer_value / (2**num_genes - 1))
decoded_values.append(value)
return decoded_values
def generate_population(size, num_genes, bounds):
""" 生成初代种群 """
population = []
for _ in range(size):
chromosome = np.random.randint(2, size=len(bounds) * num_genes).tolist()
population.append(chromosome)
return population
def fitness_function(chromosome, bounds, num_genes):
decoded_values = decode_chromosome(chromosome, bounds, num_genes)
return objective_function(*decoded_values)
def selection(population, fitnesses):
""" 轮盘赌选择 """
total_fitness = sum(fitnesses)
pick = np.random.uniform(0, total_fitness)
current = 0
for chrom, fit in zip(population, fitnesses):
current += fit
if current > pick:
return chrom
return population[-1]
def crossover(parent1, parent2, crossover_rate):
if np.random.rand() < crossover_rate:
point = np.random.randint(1, len(parent1) - 1)
child1 = parent1[:point] + parent2[point:]
child2 = parent2[:point] + parent1[point:]
return [child1, child2]
else:
return [parent1, parent2]
def mutate(chromosome, mutation_rate):
for i in range(len(chromosome)):
if np.random.rand() < mutation_rate:
chromosome[i] = 1 - chromosome[i]
def genetic_algorithm(objective_function, bounds, population_size, num_genes, generations, crossover_rate, mutation_rate):
population = generate_population(population_size, num_genes, bounds)
best_chromosome = None
best_fitness = -float('inf')
for generation in range(generations):
fitnesses = [fitness_function(chrom, bounds, num_genes) for chrom in population]
current_best_fitness = max(fitnesses)
if current_best_fitness > best_fitness:
best_fitness = current_best_fitness
logger.info(f"Generation {generation*len(population)}")
best_chromosome = population[fitnesses.index(best_fitness)]
new_population = []
for _ in range(population_size // 2):
parent1 = selection(population, fitnesses)
parent2 = selection(population, fitnesses)
offspring = crossover(parent1, parent2, crossover_rate)
new_population.extend(offspring)
for chrom in new_population:
mutate(chrom, mutation_rate)
population = new_population
best_values = decode_chromosome(best_chromosome, bounds, num_genes)
return best_values, best_fitness
def run_genetic_algorithm():
logger.info("\n ######################## genetic_algorithm ######################## ")
random.seed(0)
np.random.seed(0)
# 参数设置
bounds = [(1, 8), (1, 8), (1, 8)]
population_size = 50
num_genes = 16
generations = 1000
crossover_rate = 0.7
mutation_rate = 0.01
# 运行遗传算法
best_solution, best_value = genetic_algorithm(objective_function, bounds, population_size, num_genes, generations, crossover_rate, mutation_rate)
logger.info(f"最佳解: X={best_solution[0]}, Y={best_solution[1]}, Z={best_solution[2]}")
logger.info(f"最大值: {best_value}")
def simulated_annealing(objective_function, bounds, initial_temp, temp_min, alpha, max_iter):
# 初始化起始点
X = random.randint(*bounds['X'])
Y = random.randint(*bounds['Y'])
Z = random.randint(*bounds['Z'])
# 初始化当前解和当前最佳解
current_solution = (X, Y, Z)
current_solution=[int(x) for x in current_solution]
current_value = objective_function(*current_solution)
best_solution = current_solution
best_value = current_value
# 初始化温度
temp = initial_temp
for i in range(max_iter):
logger.info("iteration: %d" % i)
# 生成新的候选解
candidate_solution = (
np.clip(current_solution[0] + np.random.normal(0, 1), *bounds['X']),
np.clip(current_solution[1] + np.random.normal(0, 1), *bounds['Y']),
np.clip(current_solution[2] + np.random.normal(0, 1), *bounds['Z'])
)
candidate_solution=[int(x) for x in candidate_solution]
candidate_value = objective_function(*candidate_solution)
# 接受新解的概率
if candidate_value > current_value:
accept_probability = 1
else:
accept_probability = np.exp((candidate_value - current_value) / temp)
# 根据概率决定是否接受新解
if accept_probability > random.uniform(0, 1):
current_solution = candidate_solution
current_value = candidate_value
# 更新最佳解
if current_value > best_value:
best_solution = current_solution
best_value = current_value
# 温度逐渐降低
temp = max(temp_min, temp * alpha)
return best_solution, best_value
def run_simulated_annealing():
logger.info("\n ######################## run_simulated_annealing ######################## ")
random.seed(0)
np.random.seed(0)
# 定义搜索空间
bounds = {
'X': (1, 8),
'Y': (1, 8),
'Z': (1, 8)
}
# 模拟退火参数
initial_temp = 10000
temp_min = 1e-10
alpha = 0.99
max_iter = 10000
# 运行模拟退火算法
best_solution, best_value = simulated_annealing(objective_function, bounds, initial_temp, temp_min, alpha, max_iter)
logger.info(f"最佳解: X={best_solution[0]}, Y={best_solution[1]}, Z={best_solution[2]}")
logger.info(f"最大值: {best_value}")
def run_sgd():
logger.info("\n ######################## run_sgd ######################## ")
import torch
def function(X,Y,Z):
part1 = 100 * torch.exp(-(X - 2)**2 - (Y - 4)**2 - (Z - 2)**2)
part2 = 10 * torch.sin(X * 3) + 10 * torch.cos(Y * 3) + 10 * torch.sin(Z * 3)
return part1 + part2
# 定义搜索空间
bounds = {
'X': (1, 8),
'Y': (1, 8),
'Z': (1, 8)
}
# 初始点(随机在范围内选择)
X = torch.tensor([torch.rand(1).item() * (bounds['X'][1] - bounds['X'][0]) + bounds['X'][0]], requires_grad=True)
Y = torch.tensor([torch.rand(1).item() * (bounds['Y'][1] - bounds['Y'][0]) + bounds['Y'][0]], requires_grad=True)
Z = torch.tensor([torch.rand(1).item() * (bounds['Z'][1] - bounds['Z'][0]) + bounds['Z'][0]], requires_grad=True)
# 学习率和最大迭代次数
lr = 0.1
max_iter = 32
optimizer = torch.optim.SGD([X, Y, Z], lr=lr)
for i in range(max_iter):
optimizer.zero_grad()
# 计算目标函数值
value = function(X, Y, Z)
if round(value.item())==102:
break
# 反向传播计算梯度
loss = -torch.log(value) # 我们要最大化目标函数值,所以取负值进行最小化
loss.backward()
# 更新参数
optimizer.step()
# 梯度裁剪,确保解在边界内
with torch.no_grad():
X.clamp_(bounds['X'][0], bounds['X'][1])
Y.clamp_(bounds['Y'][0], bounds['Y'][1])
Z.clamp_(bounds['Z'][0], bounds['Z'][1])
#if i % 1000 == 0: # 每1000步打印一次当前解
logger.info(f"Iteration {i}: X={X.item()}, Y={Y.item()}, Z={Z.item()}, Value={value.item()}")
final_value = function(X, Y, Z)
logger.info(f"最佳解: X={X.item()}, Y={Y.item()}")
logger.info(f"最大值: {final_value.item()}")
def run_bayes():
import numpy as np
from bayes_opt import BayesianOptimization
logger.info("\n ######################## run_bayes ######################## ")
# 定义搜索空间
pbounds = {
'X': (1, 8),
'Y': (1, 8),
'Z': (1, 8),
}
# 设置贝叶斯优化器
optimizer = BayesianOptimization(
f=objective_function,
pbounds=pbounds,
random_state=1
)
# 执行优化
optimizer.maximize(
init_points=10, # 初始随机选择的点数
n_iter=100, # 优化迭代次数
)
# 打印最佳值和对应的参数
logger.info(f"最佳解: {optimizer.max['params']}")
logger.info(f"最大值: {optimizer.max['target']}")
def run(func):
global iters
iters=0
import multiprocessing as mp
p = mp.Process(target=func,args=())
p.start()
p.join()
def vis_animation():
import math
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.animation import FuncAnimation, PillowWriter
def polynomial(X,Y,Z):
return 100*np.exp(-(X - 2)**2 - (Y - 4)**2 - (Z - 2)**2)
def non_convex_function(X, Y, Z):
part1 = 100 * np.exp(-(X - 2)**2 - (Y - 4)**2 - (Z - 2)**2)
part2 = 10 * np.sin(X * 3) + 10 * np.cos(Y * 3) + 10 * np.sin(Z * 3)
return part1 + part2
# 生成 x 和 y 的网格
x = np.linspace(1, 8, 16)
y = np.linspace(1, 8, 16)
x, y = np.meshgrid(x, y)
# 创建图形和轴
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 更新函数
def update(z):
ax.clear()
z_values = non_convex_function(x, y, z)
print(z,np.max(z_values))
ax.plot_surface(x, y, z_values, cmap='viridis')
ax.set_zlim(0, 100)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('f(X, Y, z_fixed, w)')
ax.set_title(f'z = {z:.2f}')
# 创建动画
ani = FuncAnimation(fig, update, frames=np.linspace(1, 8, 8), interval=1000)
ani.save('non_convex_function.gif', writer=PillowWriter(fps=1))
# 显示动画
plt.show()
if __name__ == '__main__':
#vis_animation()
run(dashscope)
run(moonshot)
run(qianfan)
run(sparkai)
run(gemini)
run(azure)
run(run_genetic_algorithm)
run(run_simulated_annealing)
run(run_sgd)
run(run_bayes)
测试日志
######################## dashscope ########################
---------------------------------- 第0轮 ----------------------------------
明白了,根据您的要求,我们将首先在满足约束条件下尝试一组初始参数。由于您希望找到使得tokens/sec最大化的参数组合,而没有提供具体的偏好或起始点,我将从一个均衡的分配开始,即尽量使HL_DP、HL_TP、HL_PP的值接近它们的几何平均值,同时满足它们的乘积等于16的条件。
给定约束 HL_DP * HL_TP * HL_PP = 16,我们可以先尝试如下的初始化分配:
\[ HL_DP = 4, HL_TP = 2, HL_PP = 2 \]
这是因为4*2*2=16,满足约束条件,并且较为平衡地分配了并行度。
所以,第一组参数列表为:
\[ [HL_DP=4, HL_TP=2, HL_PP=2] \]
请使用这组参数运行您的训练脚本,并将获得的tokens/sec值反馈给我,以便我们进一步优化参数。
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- 第1轮 ----------------------------------
了解到上一组参数的性能后,让我们尝试调整参数以探索可能的更高性能。为了优化,我们将以一定策略调整这些参数,比如增加数据并行(HL_DP)以减少通信开销,或者调整模型并行(HL_TP)和管道并行(HL_PP)来寻找更佳的负载平衡。基于之前的设置,我们可以尝试减少数据并行数,增加模型或管道并行数,因为较大的数据并行可能导致更多的通信开销,尤其是在较小的模型规模下。
新参数建议如下:
\[ HL_DP = 2, HL_TP = 4, HL_PP = 2 \]
这里,我们将数据并行减半(HL_DP=2),同时将模型并行翻倍(HL_TP=4),保持总并行数不变(2*4*2=16),以期望通过减少数据并并行的通信成本来提升整体性能。
新的参数列表为:
\[ [HL_DP=2, HL_TP=4, HL_PP=2] \]
请使用这组参数运行训练脚本,并再次反馈tokens/sec的性能结果。
iters:2 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## moonshot ########################
---------------------------------- iteration 0 ----------------------------------
明白了您的要求。根据参数约束 HL_DP * HL_TP * HL_PP = 16,我们可以有多种组合方式。为了最大化 tokens/sec,我们可以尝试一些常见的组合,比如平衡每个参数的值。
第一组参数列表如下:
[HL_DP=4,HL_TP=2,HL_PP=2]
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- iteration 1 ----------------------------------
根据您提供的反馈,tokens/sec为1.475。由于HL_DP、HL_TP和HL_PP的乘积必须等于16,我们可以尝试调整这些参数以探索不同的配置。
考虑到平衡性,我们可以保持HL_TP和HL_PP的乘积为8,然后尝试不同的HL_DP值。以下是新的参数配置:
[HL_DP=2,HL_TP=4,HL_PP=2]
这个配置保持了HL_TP和HL_PP的乘积为8,同时降低了HL_DP的值,可能会影响并行度,但也可能因为减少了内存占用而提高性能。请运行这个配置并提供新的性能数据。
iters:2 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## qianfan ########################
---------------------------------- 第0轮 ----------------------------------
明白您的要求,以下是我给出的第一组参数列表,供您进行训练脚本的运行和性能测试:
[HL_DP=2,HL_TP=2,HL_PP=4]
请您使用这组参数运行训练脚本,并将得到的tokens/sec值反馈给我,以便我进行后续参数调整,以最大化训练性能。
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- 第1轮 ----------------------------------
感谢您提供性能反馈。根据之前的结果,我将为您生成一组新的参数配置,以尝试进一步提高`tokens/sec`性能。请注意,由于我们只能通过迭代来逼近最优解,这个过程可能需要多次尝试。
新的参数配置如下:
[HL_DP=4, HL_TP=2, HL_PP=2]
请您使用这组新参数再次运行训练脚本,并将得到的`tokens/sec`值反馈给我。我们将根据这个反馈继续调整参数,直到找到近似最优的性能配置。
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- 第2轮 ----------------------------------
从您提供的反馈来看,新参数配置[HL_DP=4, HL_TP=2, HL_PP=2]的性能tokens/sec仍然是1.475,与之前的配置性能相同。这表明在这两种配置下,性能可能达到了一个局部最优值,或者性能受到其他未调整因素的影响。
为了继续探索可能的性能提升,我会建议尝试一些不同的参数组合,以期找到更好的配置。以下是一组新的参数供您测试:
[HL_DP=1, HL_TP=4, HL_PP=4]
请您再次使用这组参数运行训练脚本,并反馈得到的`tokens/sec`值。我们将根据这个新反馈来调整参数,继续寻求性能的最大化。记住,这个过程可能需要多次迭代,每次反馈都将帮助我们更接近最优解。
经过测试,上面参数对应的性能为tokens/sec:5.158,请给出新的参数配置
---------------------------------- 第3轮 ----------------------------------
非常感谢您提供新的性能反馈。根据最新的结果,`tokens/sec:5.158` 表明这组参数配置显著提升了性能。为了继续优化,我会基于当前的最佳配置进行调整,以尝试进一步增加性能。
以下是一组新的参数配置供您测试:
[HL_DP=1, HL_TP=8, HL_PP=2]
请您使用这组参数再次运行训练脚本,并反馈得到的 `tokens/sec` 值。我们将继续根据反馈调整参数,以逼近更优的性能配置。希望这次调整能带来进一步的性能提升。
经过测试,上面参数对应的性能为tokens/sec:2.859,请给出新的参数配置
---------------------------------- 第4轮 ----------------------------------
感谢您提供新的性能数据。从最新的结果来看,`tokens/sec:2.859` 相较于前一次有所降低,这表明我们在上一次调整中可能走过了最优点。在继续探索最优参数配置的过程中,我们需要参考之前的最佳结果,并据此作出更细致的调整。
考虑到之前的最佳性能是在配置 `[HL_DP=1, HL_TP=4, HL_PP=4]` 下获得的 `tokens/sec:5.158`,我们将尝试在这组参数附近进行微调,以期待能够找到更高的性能点。
新的参数配置建议如下:
[HL_DP=1, HL_TP=4, HL_PP=4] 的微调版本,由于这组参数已经给出过较好的性能,我们可以尝试在其周围进行细微的变动:
[HL_DP=1, HL_TP=3, HL_PP=5.333] (注意:由于HL_PP需要是整数,这里取了近似值5.333,实际操作中可能需要取整,如5或6,并进行相应微调以保持乘积为16)
或者,我们尝试另一种不同的策略,以增加数据的多样性:
[HL_DP=2, HL_TP=2, HL_PP=6]
请您选择其中一组参数进行测试,或者根据您对模型的理解,自行微调这些参数进行测试。测试后,请继续提供 `tokens/sec` 的性能反馈,以便我们进一步调整和优化。
注意:在实际操作中,如果由于硬件或软件的限制,某些参数组合无法实现(例如,某些值必须为整数或特定范围的数),您需要根据实际情况进行调整,并反馈调整后的实际参数和性能。这将有助于我们更精确地指导后续的参数优化过程。
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第5轮 ----------------------------------
非常抱歉给出了非法参数,我疏忽了参数必须严格满足乘法等于16的约束。请允许我重新提供一组符合要求的参数。
新的参数配置如下:
[HL_DP=2, HL_TP=4, HL_PP=2]
请您使用这组参数运行训练脚本,并反馈得到的`tokens/sec`值。我会确保未来的参数调整严格遵守所给约束条件。感谢您的理解和耐心!
iters:5 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## sparkai ########################
---------------------------------- 第0轮 ----------------------------------
明白了,这是一组参数列表:
[HL_DP=0.5, HL_TP=0.5, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第1轮 ----------------------------------
非常抱歉,我的回答有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第2轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第3轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第4轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第5轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第6轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第7轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第8轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第9轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第10轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第11轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第12轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第13轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第14轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第15轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第16轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第17轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第18轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第19轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第20轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第21轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第22轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第23轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第24轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第25轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第26轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第27轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.5, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第28轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.5, HL_TP=0.25, HL_PP=0.25]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
---------------------------------- 第29轮 ----------------------------------
非常抱歉,我的回答仍然有误。根据参数约束,HL_DP乘以HL_TP乘以HL_PP等于16,因此需要重新计算参数值。
以下是一组满足约束的参数列表:
[HL_DP=0.25, HL_TP=0.25, HL_PP=0.5]
非法参数,请重新输入.
参数约束:
1.HL_DP乘以HL_TP乘以HL_PP等于16
输出格式(严格按照这个格式输出,且每次只输出一组参数,不要换行):
[HL_DP=?,HL_TP=?,HL_PP=?]
######################## gemini ########################
---------------------------------- 第0轮 ----------------------------------
明白您的要求。
为了找到最佳参数组合,需要先对参数空间进行探索。鉴于您没有提供任何关于模型或硬件的具体信息,我将假设以下几点:
1. **模型大小**: 模型越大,对内存的需求越高。
2. **数据并行**: 数据并行是指将数据分成多个部分,分配到不同的GPU上进行训练。
3. **模型并行**: 模型并行是指将模型的不同部分分配到不同的GPU上进行训练。
基于这些假设,我建议您从以下参数组合开始:
**[HL_DP=2,HL_TP=4,HL_PP=2]**
请根据这组参数运行您的训练脚本,并告诉我得到的tokens/sec。我会根据您的反馈,调整参数组合,帮助您找到近似最优解。
iters:1 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## azure ########################
---------------------------------- 第0轮 ----------------------------------
明白了,请输出第一组参数列表:
[HL_DP=1, HL_TP=2, HL_PP=8]
经过测试,上面参数对应的性能为tokens/sec:1.957,请给出新的参数配置
---------------------------------- 第1轮 ----------------------------------
[HL_DP=2, HL_TP=2, HL_PP=4]
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- 第2轮 ----------------------------------
[HL_DP=4, HL_TP=2, HL_PP=2]
经过测试,上面参数对应的性能为tokens/sec:1.475,请给出新的参数配置
---------------------------------- 第3轮 ----------------------------------
[HL_DP=2, HL_TP=4, HL_PP=2]
iters:4 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## genetic_algorithm ########################
Generation 0
iters:130 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## run_simulated_annealing ########################
iteration: 0
....
iteration: 351
iters:353 find best var X:2.00 Y4.00 Z:2.00 OUT:102.85
######################## run_sgd ########################
Iteration 0: X=6.614494800567627, Y=5.238071441650391, Z=7.860743045806885, Value=-10.35390567779541
Iteration 1: X=6.473637104034424, Y=5.236456871032715, Z=7.855504512786865, Value=-11.61599349975586
Iteration 2: X=6.300701141357422, Y=5.2361674308776855, Z=7.854565143585205, Value=-14.592155456542969
Iteration 3: X=6.1468682289123535, Y=5.236084461212158, Z=7.854295253753662, Value=-19.474750518798828
Iteration 4: X=6.0320634841918945, Y=5.236048221588135, Z=7.854177474975586, Value=-23.976463317871094
Iteration 5: X=5.950539588928223, Y=5.236027717590332, Z=7.854111671447754, Value=-26.840965270996094
Iteration 6: X=5.893289089202881, Y=5.2360148429870605, Z=7.85407018661499, Value=-28.403541564941406
Iteration 7: X=5.853184223175049, Y=5.236006736755371, Z=7.854043006896973, Value=-29.2062931060791
Iteration 8: X=5.825105667114258, Y=5.236001014709473, Z=7.854024410247803, Value=-29.60835838317871
Iteration 9: X=5.805449962615967, Y=5.235997200012207, Z=7.854011535644531, Value=-29.80744743347168
Iteration 10: X=5.791690826416016, Y=5.235994338989258, Z=7.854002475738525, Value=-29.905494689941406
Iteration 11: X=5.782059669494629, Y=5.235992431640625, Z=7.853996276855469, Value=-29.953655242919922
Iteration 12: X=5.775317668914795, Y=5.23599100112915, Z=7.853991985321045, Value=-29.97728157043457
Iteration 13: X=5.770598411560059, Y=5.235990047454834, Z=7.853989124298096, Value=-29.988866806030273
Iteration 14: X=5.767294883728027, Y=5.235989570617676, Z=7.853986740112305, Value=-29.994544982910156
Iteration 15: X=5.7649827003479, Y=5.235989093780518, Z=7.85398530960083, Value=-29.997325897216797
Iteration 16: X=5.763363838195801, Y=5.235988616943359, Z=7.853984355926514, Value=-29.998689651489258
Iteration 17: X=5.762230396270752, Y=5.235988140106201, Z=7.853983402252197, Value=-29.999359130859375
Iteration 18: X=5.76143741607666, Y=5.235988140106201, Z=7.853982925415039, Value=-29.999685287475586
Iteration 19: X=5.7608819007873535, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999845504760742
Iteration 20: X=5.760493278503418, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999923706054688
Iteration 21: X=5.760221481323242, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999961853027344
Iteration 22: X=5.760031223297119, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999980926513672
Iteration 23: X=5.759897708892822, Y=5.235988140106201, Z=7.853982448577881, Value=-29.99999237060547
Iteration 24: X=5.7598042488098145, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999996185302734
Iteration 25: X=5.759738922119141, Y=5.235988140106201, Z=7.853982448577881, Value=-29.999998092651367
Iteration 26: X=5.759693145751953, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
Iteration 27: X=5.7596611976623535, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
Iteration 28: X=5.759638786315918, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
Iteration 29: X=5.759623050689697, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
Iteration 30: X=5.759612083435059, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
Iteration 31: X=5.759604454040527, Y=5.235988140106201, Z=7.853982448577881, Value=-30.0
最佳解: X=5.759604454040527, Y=5.235988140106201
最大值: -30.0
######################## run_bayes ########################
iters:66 find best var X:2.18 Y4.13 Z:2.07 OUT:106.42