目录
引言
一、Pod调度策略
(一)基本概述
(二)调度原则
(三)Predicate常见算法
(四)优先级排序
(五)调度过程
1.过滤阶段
2.优先级排序
3.选择最优节点
4.绑定阶段
二、指定调度节点
(一)nodeName
1.定义
2.示例
(二)nodeSelector
1.定义
2.示例
(三)区别
三 、节点亲和性
(一)基本介绍
(二)键值运算关系
(三)亲和策略
1.硬策略
2.软策略
(四)设置节点亲和性
1.定义硬策略
2.定义软策略
3.同时定义软硬策略
四、Pod亲和性与反亲和性
(一)基本定义
(二)Pod亲和
1.定义
2.作用
3.配置
3.1 创建亲和pod
3.2 定义硬策略
3.3 定义软策略
(三)Pod反亲和
1.定义
2.作用
3.配置
3.1 硬反亲和
3.2 软反亲和
五、污点与容忍
(一)污点
1.污点定义
2.污点效果
3.污点的应用
4.污点的配置与管理
4.1 设置污点
4.2 去除污点
(二)容忍
1.容忍的定义
2.容忍的组成
3.容忍的配置
3.1 设置容忍参数
3.2 查看结果
(三)资源优化
1.多master使用
2.Node更新
3.维护操作
3.1 cordon(封锁、警戒)
3.2 drain(驱逐)
(四)故障排除思路
1.环境设置
2.pod事件处理
引言
在Kubernetes集群中,Pod是最小的可部署单元,它封装了应用程序及其依赖的运行环境。然而,Pod并不会自行选择在哪个节点上运行,而是由Kubernetes的调度器(kube-scheduler)来负责。本文将深入探讨Kubernetes中的Pod调度机制,包括其工作原理、调度决策的因素以及如何定义Pod的调度策略
一、Pod调度策略
(一)基本概述
在Kubernetes中,Pod的调度策略主要由kube-scheduler组件负责。kube-scheduler根据集群的状态和Pod的调度需求,选择合适的节点来运行Pod。调度决策基于一系列的规则和策略,包括资源的可用性、节点的标签、Pod的亲和性与反亲和性等。
(二)调度原则
1.公平性原则
确保每个Pod都要被调度,即使因为资源不够而无法立即调度。这意味着所有Pod都将被纳入调度器的考虑范围,等待资源满足时再进行调度。
2.资源合理分配原则
根据多种策略选择合适的Node,并且使资源利用率尽量高。这包括考虑节点的CPU、内存、磁盘等资源的可用性和Pod的资源请求。
kube-scheduler在过滤阶段会检查候选节点的可用资源是否满足Pod的资源请求,从而确保Pod能够在资源充足的节点上运行。
3.可自定义原则
内部支持多种调度策略,用户可以选择亲和性、优先级、污点等控制调度结果。
用户可以根据实际需求自定义调度策略,以满足特定的应用场景和工作负载需求。
例如,用户可以通过节点亲和性规则将Pod调度到具有特定标签的节点上,或者通过Pod亲和性和反亲和性规则将Pod调度到与其他Pod具有特定关系的节点上。
4.调度流程
kube-scheduler给Pod做调度选择时包含两个步骤:过滤和打分。
过滤阶段:调度器会排除所有不满足Pod特定调度需求的节点,得到一个包含所有可调度节点的列表。
打分阶段:调度器会根据当前启用的打分规则为每一个可调度节点进行打分,最后选择得分最高的节点来运行Pod。
如果存在多个得分最高的节点,kube-scheduler会从中随机选取一个。
5.考虑因素
在做调度决定时,kube-scheduler会考虑多种因素,包括单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局部性、负载间的干扰等等。
这些因素共同决定了Pod的最终调度结果,确保了Pod能够运行在最适合的节点上。
6.抢占机制
Kubernetes还提供了抢占(Preemption)机制,允许终止低优先级的Pod以便高优先级的Pod可以调度运行。
当集群资源不足时,抢占机制可以确保高优先级的Pod能够优先获得资源并得到调度。
(三)Predicate常见算法
在Kubernetes(k8s)中,Predicate(过滤)的常用算法主要用于在调度过程中筛选符合条件的节点。这些算法通过一系列规则对集群中的节点进行过滤,确保选出的节点能够满足待调度Pod的资源需求和约束条件。以下是一些常用的Predicate算法:
1.PodFitsResources
作用:检查节点上剩余的资源(如CPU、内存等)是否大于Pod请求的资源。
原理:通过比较节点上的可用资源与Pod的requests字段来确定节点是否满足Pod的资源需求。
2.PodFitsHost
作用:如果Pod指定了NodeName,检查节点名称是否和Pod指定的NodeName匹配。
原理:直接比较Pod的spec.nodeName字段与节点名称是否一致。
3.PodFitsHostPorts
作用:检查节点上已经使用的端口是否和Pod申请的端口冲突。
原理:遍历节点上所有已运行的Pod,检查其占用的端口是否与待调度Pod申请的端口冲突。
4.PodSelectorMatches
作用:过滤掉和Pod指定的label不匹配的节点。
原理:根据Pod的nodeSelector字段或affinity字段中的nodeAffinity规则,检查节点的label是否与Pod的要求匹配。
5.CheckNodeCondition
作用:检查节点的状态是否满足调度条件,如节点是否可调度(Schedulable)、是否处于Ready状态等。
原理:根据节点的状态信息(如Node Condition)来确定节点是否满足调度要求。
6.CheckNodeUnschedulable
作用:检查节点是否设置了unschedulable标签,即节点是否禁止调度新的Pod。
原理:直接检查节点的unschedulable字段是否为true。
7.NoDiskConflict
作用:检查Pod请求的存储卷(Volume)是否与节点上已存在的存储卷冲突。
原理:通过比较Pod的volumeMounts和volumes字段与节点上已挂载的存储卷来确定是否存在冲突。
8.MatchNodeSelector
作用:根据Pod的nodeSelector字段筛选出满足特定label的节点。
原理:与PodSelectorMatches类似,但更侧重于根据Pod的nodeSelector字段进行筛选。
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。 经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序
(四)优先级排序
在过滤阶段之后,kube-scheduler会对可调度节点进行优先级排序。这个排序过程是通过一系列优先级函数来实现的,每个函数都会为节点打分。
优先级函数的打分规则可以根据实际需求进行定制。Kubernetes内置了一些默认的优先级函数,如
LeastRequestedPriority:优先选择资源利用率最低的节点。
BalancedResourceAllocation:在CPU和内存资源利用率之间寻求平衡。
SelectorSpreadPriority:尽量将Pod分散到不同的节点上,以实现负载均衡。
NodeAffinityPriority:根据Pod的NodeAffinity/NodeSelector要求给节点打分。
TaintTolerationPriority:根据Pod是否能够容忍节点的Taint来给节点打分。
kube-scheduler会将这些优先级函数的分数进行加权求和,得到每个节点的最终得分。
(五)调度过程
1.过滤阶段
kube-scheduler首先会应用一系列的过滤规则来排除不满足Pod调度需求的节点。这些算法通过一系列规则对集群中的节点进行过滤,确保选出的节点能够满足待调度Pod的资源需求和约束条件。
2.优先级排序
等到过滤阶段完成后,会根据优先级函数来对每个节点进行打分
3.选择最优节点
根据节点的最终得分,kube-scheduler会选择得分最高的节点来运行Pod。
如果有多个节点得分相同,kube-scheduler可能会随机选择一个节点,或者根据其他策略(如轮询、最少调度Pod数等)来选择。
4.绑定阶段
一旦选择了最优节点,kube-scheduler就会将这个调度决策通知给kube-apiserver,这个过程叫做绑定(Bind)
在绑定之后,Pod就被分配到了指定的节点上,并由该节点上的kubelet负责启动和运行Pod。
二、指定调度节点
在Kubernetes中,指定Pod调度的节点通常可以通过两种方式实现:nodeName字段和nodeSelector字段
首先获取节点信息
[root@master01 data]#kubectl get node
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 11d v1.20.11
node01 Ready <none> 11d v1.20.11
node02 Ready <none> 11d v1.20.11
(一)nodeName
1.定义
当Pod的spec.nodeName字段被设置为某个Node的名称时,Kubernetes调度器(kube-scheduler)会直接将该Pod调度到指定的Node上,而不会考虑其他的调度策略和规则。
这种方式会跳过kube-scheduler的调度策略,直接进行强制匹配
2.示例
定义yaml文件
[root@master01 data]#vim nginx-nodename.yaml
[root@master01 data]#cat nginx-nodename.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-node
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeName: node01 #指定调度到node01节点上
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80查看结果
[root@master01 data]#kubectl apply -f nginx-nodename.yaml
deployment.apps/nginx-node created
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-node-57b9b96f46-ctz6v 1/1 Running 0 16s 10.244.1.137 node01 <none> <none>
nginx-node-57b9b96f46-dbdq6 1/1 Running 0 16s 10.244.1.136 node01 <none> <none>
nginx-node-57b9b96f46-k8jsg 1/1 Running 0 16s 10.244.1.138 node01 <none> <none>

查看其中一个pod的详细事件信息
[root@master01 data]#kubectl describe pod nginx-node-57b9b96f46-ctz6v |sed -n '/Events/,/$$/p'
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 4m18s kubelet Container image "nginx:1.18.0" already present on machine
Normal Created 4m18s kubelet Created container nginx
Normal Started 4m18s kubelet Started container nginx
#查看详细事件(发现未经过scheduler调度分配),nodeName会绕过scheduler调度器(二)nodeSelector
1.定义
nodeSelector是Pod规格(spec)中的一个字段,它允许用户根据Node的标签(labels)来选择Node。
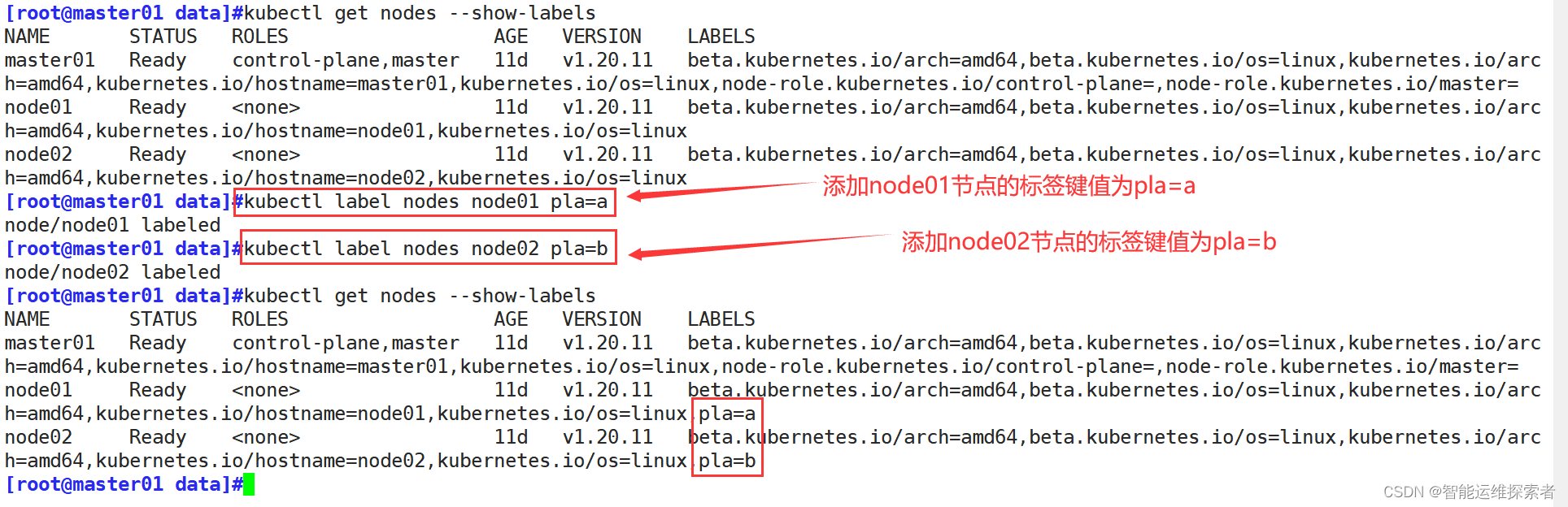
通过kubectl get nodes --show-labels命令可以查看集群中所有Node的标签信息。
在Pod的spec.nodeSelector字段中,可以指定一个或多个键值对,这些键值对需要与Node的标签完全匹配,Pod才会被调度到该Node上。
2.示例
2.1 自定义标签
| 指令 | 作用 |
| kubectl get <资源类型> <资源名称> --show-labels | 查看标签 |
| kubectl get <资源类型> -l key=value | 精确查找带有指定标签的资源 |
| kubectl label <资源类型> <资源名称> key = value | 创建标签 |
| kubectl label <资源类型> <资源名称> key = value --overwrite | 修改标签值 |
| kubectl label <资源类型> <资源名称> key- | 删除标签 |
2.2 编写yaml文件
[root@master01 data]#vim nginx-selector.yaml
[root@master01 data]#cat nginx-selector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-selector
spec:
replicas: 3
selector:
matchLabels:
app: nginx01
template:
metadata:
labels:
app: nginx01
spec:
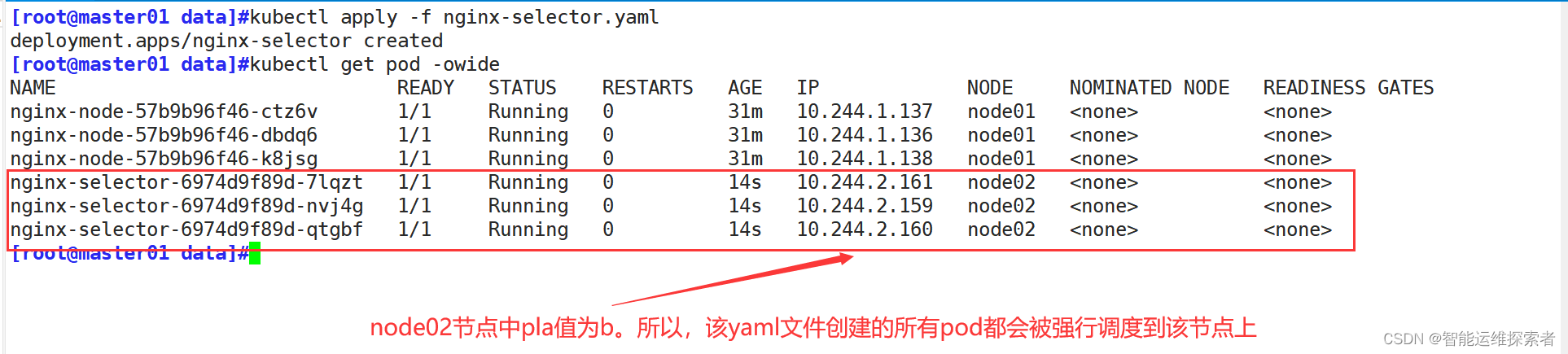
nodeSelector:
pla: b #选择标签键值为pla=b的node节点
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80所有执行文件创建的pod实例,都会被调度到指定标签的节点上
定义此标签会记录调度信息到event事件中
[root@master01 data]#kubectl describe pod nginx-selector-6974d9f89d-7lqzt |sed -n '/Event/,/$$/p'
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m57s default-scheduler Successfully assigned default/nginx-selector-6974d9f89d-7lqzt to node02
Normal Pulled 3m57s kubelet Container image "nginx:1.18.0" already present on machine
Normal Created 3m57s kubelet Created container nginx
Normal Started 3m56s kubelet Started container nginx
#scheduler成功将pod调度到node02上(三)区别
• 使用nodeName字段可以直接指定Pod调度的Node,绕过kube-scheduler的调度策略。
如果指定的节点不存在,Pod将无法被调度
如果指定的节点没有足够的资源来容纳Pod,Pod调度将失败
• 使用nodeSelector字段可以根据Node的标签来选择Pod调度的Node,这是一种更为灵活的方式,因为它允许根据多个标签进行匹配。
灵活性:可以通过标签选择多个节点,而不仅仅是单个节点。
可预测性:节点标签在大多数情况下是可预测和稳定的。
扩展性:可以轻松添加或修改节点的标签,以满足不同的Pod调度需求
三 、节点亲和性
(一)基本介绍
节点亲和性允许用户根据节点的标签来选择Pod的调度位置。通过指定节点的标签和操作符(如In、NotIn、Exists、DoesNotExist等),用户可以定义Pod应该被调度到哪些节点上,或者不应该被调度到哪些节点上。
(二)键值运算关系
●In:label 的值在某个列表中 pending
●NotIn:label 的值不在某个列表中
●Gt:label 的值大于某个值
●Lt:label 的值小于某个值
●Exists:某个 label 存在
●DoesNotExist:某个 label 不存在
(三)亲和策略
节点亲和性规则可以是必需的(requiredDuringSchedulingIgnoredDuringExecution:硬策略),也可以是偏好的(preferredDuringSchedulingIgnoredDuringExecution:软策略)。
1.硬策略
• Pod必须被调度到满足条件的节点上。
• 如果没有满足条件的节点,Pod将不会被调度,而是保持在待调度(Pending)状态。
• 提供了更强的保证,确保Pod只会在满足特定条件的节点上运行。
2.软策略
• 调度器会尽可能地满足这些条件,但如果没有符合规则的节点,Pod仍可能被安排到其他节点上。
• 提供了更大的灵活性,允许在资源有限的情况下进行调度
(四)设置节点亲和性
使用 Pod 规约中的 .spec.affinity.nodeAffinity 字段来设置节点亲和性

1.定义硬策略
首先查看节点的标签

1.1 编写文件
[root@master01 data]#vim node-required.yaml
[root@master01 data]#cat node-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: require
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity: #定义pod亲和性规则
nodeAffinity: #定义为节点亲和性规则
requiredDuringSchedulingIgnoredDuringExecution: #调度时使用硬策略
nodeSelectorTerms: #定义节点选择器列表
- matchExpressions: #匹配表达式列表
- key: pla #要匹配的节点标签的键
operator: NotIn #使用的操作符,表示不匹配的值,意为不在该标签上
values: #节点标签的值列表
- b #节点标签的值,这里指定了Pod不被调度到标签值为"b"的节点上
1.2 查看亲和性结果
[root@master01 data]#kubectl apply -f node-required.yaml
pod/require created
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
require 1/1 Running 0 13s 10.244.1.139 node01 <none> <none>
#该pod被调度到pla值不为"b"的节点上,即node01
[root@master01 data]#vim node-required.yaml
[root@master01 data]#kubectl apply -f node-required.yaml
pod/require1 created
[root@master01 data]#vim node-required.yaml
[root@master01 data]#kubectl apply -f node-required.yaml
pod/require2 created
#修改Pod名称,创建多个Pod验证
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
require 1/1 Running 0 49s 10.244.1.139 node01 <none> <none>
require1 1/1 Running 0 12s 10.244.1.140 node01 <none> <none>
require2 1/1 Running 0 3s 10.244.1.141 node01 <none> <none>
1.3 不满足硬限制
如果硬策略不满足条件,Pod 状态一直会处于 Pending 状态
[root@master01 data]#cat node-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: require3
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: pla
operator: In #设置操作符为In,表示只在指定的节点上创建Pod
values:
- c #修改为不存在的标签值当创建该Pod时,它会被kubernetes系统接收,但是会因为调度策略,找不到创建的节点,导致一直处于Pending状态
[root@master01 data]#kubectl apply -f node-required.yaml
pod/require3 created
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
require 1/1 Running 0 8m52s 10.244.1.139 node01 <none> <none>
require1 1/1 Running 0 8m15s 10.244.1.140 node01 <none> <none>
require2 1/1 Running 0 8m6s 10.244.1.141 node01 <none> <none>
require3 0/1 Pending 0 6s <none> <none> <none> <none>2.定义软策略
[root@master01 data]#kubectl delete pod --all #删除所有pod2.1 编写yaml文件
[root@master01 data]#vim node-preferred.yaml
[root@master01 data]#cat node-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: preferred01
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution: #定义为软策略规则
- weight: 10 #设置该规则的权重。若有多个软策略,数值越大,权重就越大,优先级越高
preference: #定义具体的亲和性偏好
matchExpressions:
- key: pla
operator: In
values:
- c注意:
在硬策略中matchExpressions字段需要以"-"进行缩进,以 "- matchExpressions: "表示
在软策略中matchExpressions字段则不需要加- 直接以 " matchExpressions: "表示即可
软策略中权重范围为1-100
2.2 查看亲和结果
[root@master01 data]#kubectl apply -f node-preferred.yaml
pod/preferred01 created
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferred01 1/1 Running 0 9s 10.244.1.142 node01 <none> <none>
#即使找不到满足亲和条件的node,同样可以调度到其它node节点上创建
[root@master01 data]#vim node-preferred.yaml
metadata:
name: preferred02
......
[root@master01 data]#kubectl apply -f node-preferred.yaml
pod/preferred02 created
[root@master01 data]#vim node-preferred.yaml
metadata:
name: preferred03
......
[root@master01 data]#kubectl apply -f node-preferred.yaml
pod/preferred03 created
#修改名称创建多个pod
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferred01 1/1 Running 0 101s 10.244.1.142 node01 <none> <none>
preferred02 1/1 Running 0 11s 10.244.2.162 node02 <none> <none>
preferred03 1/1 Running 0 3s 10.244.2.163 node02 <none> <none>即使不满足亲和条件,schedule依然会寻找其它合适的节点创建pod
3.同时定义软硬策略
当同时定义软硬策略,硬策略具有最高的优先级。调度器在尝试调度Pod时,会首先检查硬策略是否满足。如果不满足,则不会考虑软策略,而是将Pod保持在待调度状态
软策略的优先级低于硬策略。当硬策略被满足后,调度器会尝试满足软策略,但如果无法满足,Pod仍然可以被调度到其他节点上
[root@master01 data]#kubectl delete pod --all #删除所有pod3.1 定义文件
[root@master01 data]#cat node-pre-req.yaml
apiVersion: v1
kind: Pod
metadata:
name: pre-req-pod
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: pla
operator: In
values:
- b
#硬策略,表示将pod只在key值为b的节点上创建
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: pla
operator: NotIn
values:
- b
#软策略,表示优先在key值不为b的节点上创建pod
3.2 查看结果
当执行上述文件后,由于硬策略的优先级要高于软策略,所以pod实例会在硬策略制定的pod上创建
[root@master01 data]#kubectl apply -f node-pre-req.yaml
pod/pre-req-pod created
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pre-req-pod 1/1 Running 0 5s 10.244.2.164 node02 <none> <none>
同样的,当硬策略不生效时,软策略同样无效
[root@master01 data]#vim node-pre-req1.yaml
[root@master01 data]#cat node-pre-req1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pre-req-pod01
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: pla
operator: In
values:
- c
#硬策略,定义pod只在key值为c的node上创建
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: pla
operator: In
values:
- b
#软策略,优先在key值为b的node上创建pod
由于key值为c的node节点不存在,所以pod会一直处于Pending状态,不会去考虑软策略
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pre-req-pod 1/1 Running 0 7m18s 10.244.2.164 node02 <none> <none>
pre-req-pod01 0/1 Pending 0 6s <none> <none> <none> <none>
小结
- 当硬策略和软策略同时定义时,硬策略首先生效,并且具有最高优先级。
- 如果硬策略无法满足(即集群内没有满足条件的节点),Pod将不会被调度。
- 如果硬策略满足,调度器将尝试满足软策略,但如果无法满足,Pod仍然可以被调度到其他节点上
四、Pod亲和性与反亲和性
(一)基本定义
Pod亲和性与反亲和性允许用户根据其他Pod的标签或拓扑关系来选择Pod的调度位置。这些规则可以帮助用户将需要相互协作的Pod调度到同一节点上,或者将需要隔离的Pod调度到不同的节点上。
Pod亲和性规则表示Pod应该被调度到与其他Pod满足特定关系的节点上,而Pod反亲和性规则则表示Pod不应该被调度到与其他Pod具有特定关系的节点上。
这些规则同样可以是硬性的(requiredDuringSchedulingIgnoredDuringExecution)
也可以是软性的(preferredDuringSchedulingIgnoredDuringExecution)
(二)Pod亲和
Pod亲和性(Pod Affinity)在Kubernetes中是一种重要的调度策略,它允许用户指定规则,使得Pod更倾向于被调度到满足特定条件的节点上运行,或者与已经在特定节点上运行的其他Pod部署在一起
1.定义
Pod亲和性允许用户定义Pod与特定节点或其他Pod的共存关系。
它通过匹配节点的标签(label)或其他Pod的标签来实现这种关系。
2.作用
资源协同:当Pod需要与具有特定标签的Node或已经在特定Node上运行的Pod紧密合作时(如共享硬件加速器或进行高效的数据交互),可以利用Pod亲和性将这些Pod调度到一起。
负载分片:在大规模集群中,可以根据业务需求,将相似类型的Pod调度到同一组Node上,以实现数据局部性、减少网络开销或优化整体性能。
3.配置
[root@master01 data]#kubectl delete pod --all #删除所有podPod亲和性通过kubectl explain查看pod.spec.affinity.podAffinity字段进行配置

3.1 创建亲和pod
定义一个yaml文件,创建一个pod实例,并制定好标签
[root@master01 data]#vim pod.yaml
[root@master01 data]#cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod01
labels:
pod: pod01
spec:
containers:
- name: nginx
image: nginx:1.18.0
[root@master01 data]#kubectl apply -f pod.yaml
pod/pod01 created
[root@master01 data]#kubectl get pod -owide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod01 1/1 Running 0 8m20s 10.244.1.162 node01 <none> <none> pod=pod01
#此pod在node01节点上创建,且标签指定标签为pod=pod013.2 定义硬策略
首先修改node节点的pla标签,使他们的pla值相同,则它们属于同一组(域)

注释:
如果两个节点使用此键标记并且具有相同的标签值,则调度器会将这两个节点视为处于同一拓扑域中。 调度器试图在每个拓扑域中放置数量均衡的 Pod
当node01的标签值为pla=a,而node02的标签值为pla=b则它们不属于同一组(拓扑域)。
如果两个节点的标签值都相同,如pla=a,则它们属于同一组
以硬策略为例
[root@master01 data]#vim pod-required.yaml
[root@master01 data]#cat pod-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod02
labels:
pod: pod01
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
podAffinity: #Pod亲和性规则,用于定义Pod与其他Pod的共存关系
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和性规则
- labelSelector: #用于选择具有特定标签的Pod
matchExpressions: #标签选择器的表达式列表,用于定义如何匹配Pod的标签
- key: pod #要匹配的标签的键
operator: In #操作符,In表示值必须在给定的列表中
values: #标签的值列表
- pod01 #指定pod值为pod01的pod实例
topologyKey: pla #用于指定拓扑域的范围。
#在Pod亲和性规则中,它通常用于指定哪些节点被视为“同一组”。
使用该yaml文件生成的pod实例都会与标签为pod=01的pod实例部署在一起
[root@master01 data]#kubectl apply -f pod.yaml
pod/pod02 created
[root@master01 data]#vim pod.yaml
[root@master01 data]#kubectl apply -f pod.yaml
pod/pod03 created
[root@master01 data]#vim pod.yaml
[root@master01 data]#kubectl apply -f pod.yaml
pod/pod04 created
#修改文件中的name: pod02字段,创建多个pod
[root@master01 data]#kubectl get pod -owide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod01 1/1 Running 0 9m33s 10.244.1.162 node01 <none> <none> pod=pod01
pod02 1/1 Running 0 25s 10.244.1.163 node01 <none> <none> pod=pod01
pod03 1/1 Running 0 19s 10.244.1.164 node01 <none> <none> pod=pod01
pod04 1/1 Running 0 4s 10.244.1.165 node01 <none> <none> pod=pod01
3.3 定义软策略
首先指定在node02节点上创建一个自定义名称,标签值为pod=pod100的pod实例
[root@master01 data]#vim pod.yaml
[root@master01 data]#cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-test
labels:
pod: pod100
spec:
nodeName: node02
containers:
- name: nginx
image: nginx:1.18.0
[root@master01 data]#kubectl apply -f pod.yaml
pod/pod-test created
[root@master01 data]#kubectl get pod pod-test -owide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod-test 1/1 Running 0 3m53s 10.244.2.167 node02 <none> <none> pod=pod100
#查看pod所在node节点,以及标签定义软策略yaml文件
[root@master01 data]#vim pod-preferred.yaml
[root@master01 data]#cat pod-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod05
labels:
pod: pod01
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
podAffinity: #Pod亲和性规则,用于定义Pod与其他Pod的共存关系
requiredDuringSchedulingIgnoredDuringExecution: #软策略
- labelSelector: #用于选择具有特定标签的Pod
matchExpressions: #标签选择器的表达式列表,用于定义如何匹配Pod的标签
- key: pod #要匹配的标签的键
operator: In #操作符,In值在此表示pod会优先创建在给定的列表中
values: #标签的值列表
- pod10 #指定pod值为pod10的pod实例,此值为不存在的值
topologyKey: pla #用于指定拓扑域的范围以上述文件为例,通过修改 name: pod05 的值创建多个pod
[root@master01 data]#kubectl apply -f pod-preferred.yaml
pod/pod05 created
[root@master01 data]#sed -ri 's/pod05/pod06/' pod-preferred.yaml
[root@master01 data]#kubectl apply -f pod-preferred.yaml
pod/pod06 created
[root@master01 data]#sed -ri 's/pod06/pod07/' pod-preferred.yaml
[root@master01 data]#kubectl apply -f pod-preferred.yaml
pod/pod07 created
[root@master01 data]#sed -ri 's/pod07/pod08/' pod-preferred.yaml
pod/pod08 created
[root@master01 data]#sed -ri 's/pod08/pod09/' pod-preferred.yaml
[root@master01 data]#kubectl apply -f pod-preferred.yaml
pod/pod09 created
#由于node01节点的pod实例较多,即使定义软策略,也会根据资源进行调度
#在找不到匹配的pod情况下,会优先匹配节点资源较少的node02上
#如果node02节点上有pod标签,那么它会将接下来创建的pod,都调度到node02上,直到资源持平
(三)Pod反亲和
Pod反亲和(Pod Anti-Affinity)在Kubernetes中是一种重要的调度策略,它主要用于确保Pod在集群中的分布满足特定的反亲和性规则,从而实现资源优化、故障隔离和满足特定的业务需求
1.定义
Pod反亲和性是一种调度策略,它确保满足特定条件的Pod不会被调度到同一节点上,以避免节点过载或实现故障隔离。
2.作用
高可用性:通过设置Pod反亲和性,可以确保相同服务的不同实例分布在不同的节点上,从而避免单一节点故障影响整个服务。
资源隔离:当某些Pod消耗大量资源时,为了避免资源竞争或达到更好的负载均衡效果,可以设置反亲和性,确保这些Pod不会被调度到同一台机器上
同样的反亲和用也分为两类
硬反亲和性(RequiredDuringSchedulingIgnoredDuringExecution):如果集群中没有满足条件的节点,Pod将不会被调度,而是保持在待调度(Pending)状态。
软反亲和性(PreferredDuringSchedulingIgnoredDuringExecution):调度器会尽可能地满足,但即使没有符合规则的节点,Pod仍可能被安排到其他节点上。
3.配置
[root@master01 data]#kubectl delete pod --all #删除所有pod分别在node01与node02创建pod实例,定义不同的标签值

3.1 硬反亲和
[root@master01 data]#vim pod-anti.yaml
[root@master01 data]#cat pod-anti.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-03
labels:
pod: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
podAntiAffinity: #定义Pod的反亲和性规则
requiredDuringSchedulingIgnoredDuringExecution: #硬策略
- labelSelector: #选择具有特定标签的Pod
matchExpressions: #定义匹配标签的列表
- key: pod #定义标签键的名称
operator: In #定义操作符为In示值必须在给定的列表中
values: #指定标签键的值
- nginx1 #值为nginx1,即建立的名称为nginx-01的pod
topologyKey: pla #指定拓扑域注意:按照上述文件直接创建,pod会处于Pending状态

这是因为定义了拓扑域为pla(topologyKey: pla),由于指定的所在的node01节点上带有pla=a的键值,而node02上同样具有pla=a的标签,它们同属于一个拓扑域,所以该pod没有可用的node节点,则会进入Pending状态

修该其中一个node节点的标签值,将它们从同一个拓扑域中分离开

此时pod就会正常运行

3.2 软反亲和
[root@master01 data]#vim pod-anti1.yaml
[root@master01 data]#cat pod-anti1.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-04
labels:
pod: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
podAffinityTerm:
labelSelector:
matchExpressions:
- key: pod
operator: In
values:
- nginx1
topologyKey: pla
#同样的,软反亲和,定义的亲和策略为在pla拓扑域的中,带有pod=nginx1标签的pod所在的节点上
#软反亲和表示与上述条件相反
#注意:在定义拓扑域时,另一个节点的值不要与pod反亲和所在的节点上的值相同,否则无法调度那么执行该文件创建的pod同样会调度到node02节点上

五、污点与容忍
污点与容忍是Kubernetes提供的一种节点排斥机制。通过给节点添加污点,可以阻止某些Pod在该节点上运行,除非这些Pod具有匹配的容忍设置。污点可以是键值对的形式,表示节点的某种属性或状态。而容忍则是Pod的一种属性,表示Pod可以容忍哪些污点。
污点与容忍机制可以帮助管理员控制哪些Pod可以在哪些节点上运行,从而满足特定的需求或策略。例如,管理员可以将某些节点标记为专门用于运行特定类型的应用或工作负载,通过给这些节点添加污点,并要求只有具有相应容忍设置的Pod才能在这些节点上运行。
(一)污点
在Kubernetes(K8s)中,污点(Taints)是一个重要的概念,用于实现Pod的调度控制。以下是关于污点的详细解释:
1.污点定义
污点是什么:污点是一种定义在节点上的键值型属性数据,用于让节点拒绝将Pod调度运行于其上,除非该Pod对象具有接纳节点污点的容忍度(Toleration)。
键值型数据:污点由三个部分组成:key、value和effect。其中key和value是污点的名称和值,而effect则定义了污点的效果。
2.污点效果
污点的效果(Effect)主要有三种类型:
NoSchedule:新的不能容忍此污点的Pod对象不会被调度至当前节点,但已在该节点上运行的Pod对象不受影响。
PreferNoSchedule:Kubernetes会尽量避免将新的不能容忍此污点的Pod对象调度至当前节点,但如果没有其他可用节点,仍然会调度。类似于节点亲和与pod亲和中的软策略
NoExecute:新的不能容忍此污点的Pod对象不会被调度至当前节点,而且已在该节点上运行但不再满足匹配规则的Pod对象将被驱逐。
master就是因为有 NoSchedule 污点,k8s 才不会将 Pod 调度到 master 节点上
[root@master01 data]#kubectl describe nodes master01 |grep -i taint
Taints: node-role.kubernetes.io/master:NoSchedule
[root@master01 data]#3.污点的应用
控制Pod调度:通过给节点添加污点,可以确保某些特定的Pod不会被调度到这些节点上,从而实现了对Pod调度的精细控制。例如在进行升级时,将node节点设置污点,等到升级完毕后,再将污点去除
资源隔离:例如,可以通过给master节点添加污点来确保Kubernetes系统组件使用的资源不会被其他Pod占用。
特殊硬件资源预留:如果某些节点配备了特殊硬件,可以通过给这些节点添加污点来确保只有特定的Pod才能使用这些资源。
4.污点的配置与管理
[root@master01 data]#kubectl delete pod --all #删除所有pod4.1 设置污点
可以使用kubectl taint命令给节点添加污点。,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。
污点的组成格式如下:key=value:effect首先查各节点的标签

同样以标签键pla为例,将pla=b设置为污点
[root@master01 data]#kubectl describe nodes node02 |grep -i taint
Taints: pla=b:NoSchedule
#设置污点效果为NoSchedule,表示不能容忍此污点的新的pod将不会在node02上建立
#已经运行的则不会有影响使用deployment副本控制器创建三个pod副本
[root@master01 data]#vim pod.yaml
[root@master01 data]#cat pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-nginx
spec:
replicas: 3
selector:
matchLabels:
pod: nginx
template:
metadata:
labels:
pod: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80创建副本后,副本会将所有的pod都调度到node01节点上

注释
所以在设置污点时,最好新建一个标签,或在hostname主机标签等、各node节点值不一样的标签上设置污点
带有污点的节点,可以使用nodeName选项绕过Scheduler调度创建
4.2 去除污点
同样可以使用kubectl taint命令去除节点的污点
删除污点:kubectl taint node node-name key:effect-
[root@master01 data]#kubectl taint node node02 pla-
node/node02 untainted
[root@master01 data]#kubectl describe nodes node02 |grep -i taint
Taints: <none>此时设置node01节点的污点效果为NoSchedule,新的不能容忍此污点的新的pod将不会在node01上建立,但是已经在运行的则不会受到影响

但是当污点效果设置为NoExecute时,则该节点上的pod实例将会被区别,由于是由deployment管理的pod节点,它会将pod调度到其它可以使用的节点上
[root@master01 data]#kubectl taint node node01 pla=a:NoExecute
node/node01 tainted
[root@master01 data]#kubectl describe nodes node01 |grep -i taint
Taints: pla=a:NoExecute
#更新污点效果为NoExecute污点会将node01节点上的pod驱逐,deployment会重新在node02节点上建立新的pod

注释:若是在所有的Node节点上都设置了污点后,此时Pod将无法创建成功
(二)容忍
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但我们可以在 Pod 上设置容忍(Tolerations),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上
1.容忍的定义
作用:通过配置容忍,管理员可以控制Pod在具有特定污点的节点上的行为,从而实现资源的精细管理和隔离。例如,可以使用容忍来确保某些Pod只能运行在具有特定硬件或软件特性的节点上,或者防止Pod被驱逐到不受信任的节点上
位置:容忍定义在Pod的spec.tolerations字段中。
2.容忍的组成
容忍通常包含以下几个部分:
键(Key):与污点的键相匹配。
值(Value):与污点的值相匹配。如果不指定值,Pod将容忍所有值的同名污点。
效应(Effect):与污点的效应相匹配。常见的效应包括NoSchedule、PreferNoSchedule和NoExecute。
容忍期限(TolerationSeconds)(仅对NoExecute效应有效):指定Pod在节点被赋予NoExecute污点后,能够继续在该节点上运行的时间(以秒为单位)。超过这个时间后,Pod将被驱逐。
操作符(Operator):用于指定容忍与污点的匹配方式。常见的操作符包括Equal和Exists。Equal要求键、值和效应都完全匹配,而Exists只要求键和效应匹配。
3.容忍的配置
此时按之前操作,node01的污点效果为NoExecute
[root@master01 data]#kubectl describe nodes node01 |grep -i taint
Taints: pla=a:NoExecute
[root@master01 data]#kubectl delete deployments.apps pod-nginx
deployment.apps "pod-nginx" deleted
#删除之前创建的deployment3.1 设置容忍参数
[root@master01 data]#vim tolerations.yaml
[root@master01 data]#cat tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: tolerations
labels:
pod: nginx
spec:
nodeName: node01 #指定在node01节点上创建
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80
tolerations: #定义Pod可以容忍的节点污点
- effect: "NoExecute" #污点的效应
key: "pla" #污点的键。Pod可以容忍具有这个键的污点
operator: "Equal" #定义如何与污点的值进行比较。Equal表示Pod仅容忍具有指定值的污点
tolerationSeconds: 40 #当Pod所在的节点被添加了匹配的污点后,Pod可以继续在该节点上运行的时间(秒)
value: "a" #污点的值。Pod可以容忍具有这个值的污点
----------------------------------------------------------------------------
---
在此文件中key、vaule、effect 都要与 Node 上设置的 taint 保持一致
---
operator:表示如何与污点的值进行比较,此参数有Equal与Exists两个选项
#Equal
'Pod将仅容忍节点上键(key)和值(value)与toleration中指定的键和值相匹配的污点。
例如node01节点上的pla=a,当toleration定义键和值为pla与a它会容忍,pla=b则不会容忍
如果value字段在容忍中未指定,则Equal操作符默认会使用空字符串作为值进行比较。'
#Exists
'当operator设置为Exists时,Pod将容忍所有具有指定键(key)的污点,而不管它们的值(value)
是什么。这允许Pod容忍同一类别(即具有相同键)的所有污点,而不必指定特定的值。
例如当有pla这个键的所有节点都设置污点时,不需要指定值,所有含有pla键的节点,都会被容忍'
---
tolerationSeconds:允许pod存在时间
'表示当Pod所在的节点被添加了匹配的污点后,Pod还可以继续在该节点上运行的时间(秒)
例如上述文件中设置为40,表示该pod在有污点的节点上创建后,如果污点没有被删除,它只会
在节点上存在40秒,40秒后,将会被删除'
3.2 查看结果
创建pod后进行追踪
[root@master01 data]#kubectl apply -f tolerations.yaml
pod/tolerations created
[root@master01 data]#kubectl get pod tolerations -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tolerations 1/1 Running 0 34s 10.244.2.185 node01 <none> <none>
[root@master01 data]#kubectl get pod tolerations -w
NAME READY STATUS RESTARTS AGE
tolerations 1/1 Running 0 12s
tolerations 1/1 Terminating 0 40s
tolerations 0/1 Terminating 0 42s
tolerations 0/1 Terminating 0 51s
tolerations 0/1 Terminating 0 51s
#可以看到,在40秒时,pod被移除
当所有节点的pla键都设置污点时,定义pod的容忍的文件operator值设置为Exists,那么它将会容忍所有带有pla键的节点
首先将node02节点添加污点
[root@master01 data]#kubectl taint node node02 pla=b:NoExecute
node/node02 tainted
[root@master01 data]#kubectl describe nodes node02 |grep -i taint
Taints: pla=b:NoExecute
修改yaml文件,定义operator值设置为Exists
[root@master01 data]#vim tolerations.yaml
[root@master01 data]#cat tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: tolerations
labels:
pod: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80
tolerations:
- effect: "NoExecute"
key: "pla"
operator: "Exists"
tolerationSeconds: 40
---
apiVersion: v1
kind: Pod
metadata:
name: tolerations1
labels:
pod: nginx
spec:
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80
tolerations:
- effect: "NoExecute"
key: "pla"
operator: "Exists"
tolerationSeconds: 40
--------------------------------------------------------------------
#同时创建2个pod
#删除nodeName: node01,不指定创建节点
#删除value: "a",不指定值
#修改operator: 的值为Exists,所有含有pla键的节点,都会被容忍
#注释,此时node01与node02节点都被设置了污点创建后在新的终端上追踪pod状态
[root@master01 data]#kubectl apply -f tolerations.yaml
pod/tolerations created
pod/tolerations1 created
[root@master01 data]#kubectl get pod -w
NAME READY STATUS RESTARTS AGE
tolerations 0/1 Pending 0 0s
tolerations 0/1 Pending 0 0s
tolerations1 0/1 Pending 0 0s
tolerations1 0/1 Pending 0 0s
tolerations 0/1 ContainerCreating 0 0s
tolerations1 0/1 ContainerCreating 0 0s
tolerations 1/1 Running 0 2s
tolerations1 1/1 Running 0 3s
tolerations 1/1 Terminating 0 40s
tolerations1 1/1 Terminating 0 40s
tolerations 0/1 Terminating 0 41s
tolerations1 0/1 Terminating 0 41s
tolerations 0/1 Terminating 0 42s
tolerations 0/1 Terminating 0 42s
tolerations1 0/1 Terminating 0 49s
tolerations1 0/1 Terminating 0 49s(三)资源优化
1.多master使用
当有多个master存在时,可以将备用的master的污点状态设置为PreferNoSchedule,这样的话,会尽可能避免此节点,当其它节点不可调用(资源顶峰、节点故障、节点更新等)时,可以使用master进行临时调度,待资源恢复时,再将pod转移
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule2.Node更新
当某个node节点需要资源更新时,为防止业务长时间中断,可以依次升级node,首先将需要升级的node节点设置污点,将pod资源调度到其它node节点上(如master资源充足也可以临时调用),等到该节点升级完毕后,去除污点。依次类推,将所有节点更新升级
kubectl taint node node-name key=value:NoExecute
#设置污点
-------------------------------------------------------------------------------
kubectl taint node node-name key:NoExecute-
#去除污点3.维护操作
3.1 cordon(封锁、警戒)
作用:阻止新的 Pods 被调度到该节点上。当一个节点被标记为 cordon 时,已经在该节点上运行的 Pods 不会被驱逐,但新的 Pods 不会被调度到这个节点。
使用场景:通常用于节点的维护或升级,确保在维护期间不会有新的工作负载被分配到该节点上。
命令示例:kubectl cordon node01
首先删除node节点的污点
[root@master01 data]#kubectl taint node node01 pla-
node/node01 untainted
[root@master01 data]#kubectl taint node node02 pla-
node/node02 untainted
[root@master01 data]#kubectl describe nodes node01 |grep -i taint
Taints: <none>
[root@master01 data]#kubectl describe nodes node02 |grep -i taint
Taints: <none>
#去除node的污点使用cordon指令,封锁节点
[root@master01 data]#kubectl cordon node01
node/node01 already cordoned
[root@master01 data]#kubectl describe nodes node01|grep -i taint
Taints: node.kubernetes.io/unschedulable:NoSchedule
#其污点状态默认为node.kubernetes.io/unschedulable:NoSchedule
恢复调度:使用 kubectl uncordon node01 命令可以恢复节点的调度状态,允许新的 Pods 调度到该节点上。
[root@master01 data]#kubectl uncordon node01
node/node01 uncordoned
[root@master01 data]#kubectl describe nodes node01|grep -i taints
Taints: <none>
3.2 drain(驱逐)
作用:驱逐节点上的所有 Pods,即将它们从节点上移除并重新调度到其他可用的节点上。在执行 drain 操作时,可以指定一些选项,如忽略 DaemonSets 管理的 Pods,或者强制驱逐即使 Pods 有对应的容忍度。
使用场景:当需要对某个节点进行维护、升级或删除时,可以使用 drain 命令来确保节点上的 Pods 被安全地迁移到其他节点。
命令示例:
kubectl drain node01:基本驱逐命令,会驱逐节点上的所有 Pods(除了 DaemonSets 管理的 Pods)。
kubectl drain node01 --ignore-daemonsets=true:忽略 DaemonSets 管理的 Pods,驱逐其他所有 Pods。
kubectl drain node01 --force --ignore-daemonsets --delete-local-data:强制驱逐所有 Pods(包括 DaemonSets),并删除 Pods 的本地数据。注意,使用 --force 选项可能会导致数据丢失,请确保在使用前备份重要数据。
[root@master01 data]#kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cordon01 1/1 Running 0 7m56s 10.244.2.191 node02 <none> <none>
cordon02 1/1 Running 0 7m56s 10.244.2.192 node02 <none> <none>
[root@master01 data]#kubectl drain node02 --ignore-daemonsets=true --delete-emptydir-data --force
node/node02 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-flannel/kube-flannel-ds-xwklx...
evicting pod default/cordon02
evicting pod default/cordon01
pod/cordon02 evicted
pod/cordon01 evicted
node/node02 evicted
[root@master01 data]#kubectl get pod -owide
No resources found in default namespace.
[root@master01 data]#kubectl describe nodes node02|grep -i taint
Taints: node.kubernetes.io/unschedulable:NoSchedule
#同样的,污点状态为NoSchedule
------------------------------------------------------------------------------------
#在驱逐过程中drain命令,会自动做两件事情
1.设定此node为不可调度状态
2.evict驱逐pod
恢复调度:和 cordon 一样,使用 kubectl uncordon node1 命令可以恢复节点的调度状态。
[root@master01 data]#kubectl uncordon node02
node/node02 uncordoned
[root@master01 data]#kubectl describe nodes node02|grep -i taints
Taints: <none>
简单来说
cordon的作用类似于NoSchedule
drain的作用类似于NoExecute
(四)故障排除思路
在k8s的操作中,由于组件较多,任何一步有错误,都可能导致整个k8s集群陷入不可以状态,下面我就结合工作中的一些操作做一总结
1.环境设置
防火墙策略、核心防护可能会导致节点之间无法通信
swap分区会导致kubelet无法启动,kubelet无法启动,意味着网络插件与kube-proxy容器无法启动
集群信息:使用kubectl get node查看集群信息,确保节点之间通信正常
2.pod事件处理
kubectl describe <资源类型> <资源名称>:查看资源详细信息
kubectl get events:指令查看所有事件信息,并使用grep过滤关键字
kubectl exec –it pod_name bash :进入容器查看,只限于处于Running状态
kubectl logs pod_name:查看pod日志,在Failed状态下
journalctl -xefu kubelet:查看kubelet日志