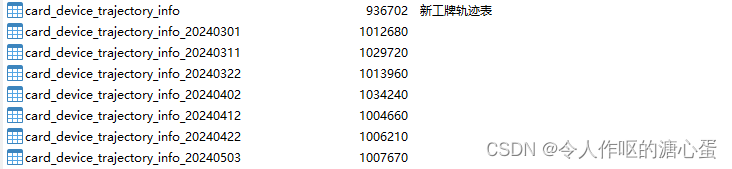
数据库用的pgsql,在表数据超过100w条的时候执行定时任务进行了分表,分表后表名命名为原的表名后面拼接时间,如原表名是card_device_trajectory_info,分表后拼接时间后得到card_device_trajectory_info_20240503,然后分表后把原来的表重置为空。这样就把100w条数据放到了card_device_trajectory_info_20240503里面,card_device_trajectory_info重置空,以此类推。但是我在java业务代码中,我想查询之前的那条数据就查不到了,要怎么关联上之前分出去的表去查询呢?
首先,我们要获取到表名,因为表名是不明确的,所以要通过模糊查询的方式获取表名
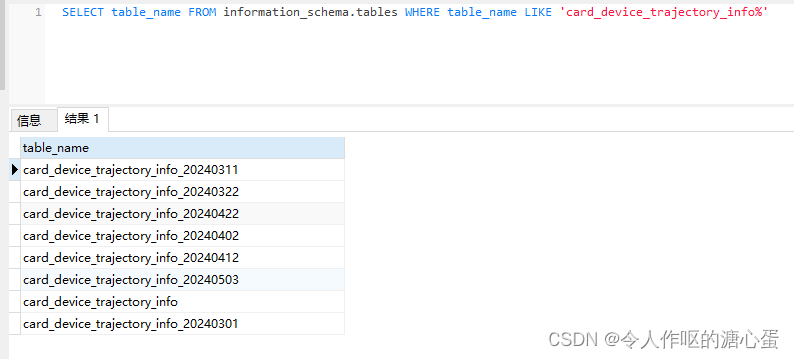
可以用List<String>去存储表明,然后获取列表的大小去做一个循环,从每一张表中查询,直到循环结束。但是这种方式极可能影响性能消耗,所以。。。
下面是代码示例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class Main {
public static void main(String[] args) {
String baseTableName = "card_device_trajectory_info"; // 基础表名
String url = "jdbc:postgresql://localhost:5432/your_database";
String user = "your_username";
String password = "your_password";
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement()) {
String sql = "SELECT table_name FROM information_schema.tables WHERE table_name LIKE '" + baseTableName + "%'";
ResultSet rs = stmt.executeQuery(sql);
// 处理查询结果,获取所有分表名称
while (rs.next()) {
String tableName = rs.getString("table_name");
// 根据业务逻辑处理分表名称,比如存入集合或者数组中
}
// 根据业务逻辑构建查询语句来查询特定的分表
for (String tableName : yourTableCollection) { // 替换yourTableCollection为你保存分表名称的集合或数组
String querySql = "SELECT * FROM " + tableName + " WHERE your_condition_here";
// 执行查询操作并处理结果
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
如果数据量很大且分表很多,那么逐个查询并遍历所有分表的方式可能会影响性能并消耗大量时间和资源。针对这种情况,可以考虑以下一些优化方案来减少性能消耗:
- 分页查询:可以考虑对每张分表进行分页查询,以减少单次查询返回的数据量,从而降低查询的性能消耗。
- 并发查询:可以考虑使用多线程或异步方式,并发地查询多张分表,以缩短整体查询所需的时间。
- 数据预处理:如果业务允许,可以考虑在数据写入时进行预处理,将需要频繁查询的数据进行汇总或者合并存储,以减少查询时的分表数量和数据量。
- 数据库分区:考虑根据业务需求对数据库进行分区,将数据分散存储到不同的物理存储中,从而减少单个查询涉及的数据量。
- 数据缓存:对查询结果进行缓存,避免重复查询相同的数据,提高查询效率。






![[算法][数字][leetcode]2769.找出最大的可达成数字](https://img-blog.csdnimg.cn/direct/282ccc3317fa4ea697aec5bc1e37c6c0.png)