🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- K-近邻算法(KNN)全面解析
- 概述
- 1. 基本概念与原理
- 1.1 KNN算法定义
- 1.2 距离度量
- 1.3 K值选择
- 1.4 分类决策规则
- 1.5 回归决策规则
- 2. 算法实现步骤
- 2.1 数据预处理
- 2.2 计算距离
- 2.3 选择K值
- 2.4 预测类别/值
- 2.5 算法优化策略
- 准备工作
- 示例代码
- 代码解释
- 3. KNN算法优缺点
- 3.1 优点
- 3.2 缺点
- 3.3 改进措施
- 4. 应用实例
- 4.1 图像识别
- 4.2 推荐系统
- 4.3 医疗诊断
- 5. 性能评估与参数调优
- 5.1 交叉验证
- 5.2 K值的选择策略
- 5.3 距离权重调整
- 6. 与其他算法对比
- 7. 结论与展望
K-近邻算法(KNN)全面解析
概述
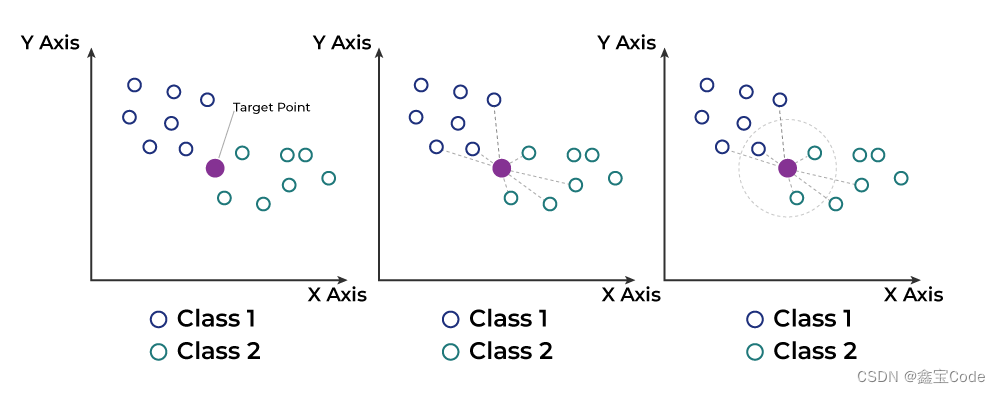
K-近邻算法(K-Nearest Neighbors, KNN)是一种基于实例的学习方法,属于监督学习范畴。它的工作原理简单直观:给定一个训练数据集,对新的输入实例,KNN算法通过计算其与训练集中每个实例的距离,找出距离最近的K个邻居,然后根据这些邻居的类别(对于分类任务)或值(对于回归任务)来预测新实例的类别或值。KNN因其简单高效和无需训练过程的特点,在众多领域中得到广泛应用,如模式识别、推荐系统、图像分类等。
1. 基本概念与原理
1.1 KNN算法定义
KNN算法的核心思想是“物以类聚”,即相似的数据应有相似的输出。通过测量不同特征空间上的距离来量化相似性。
1.2 距离度量
常见的距离度量方法包括欧氏距离、曼哈顿距离、切比雪夫距离及余弦相似度等。选择合适的距离度量方法对KNN的性能至关重要。
1.3 K值选择
K值的选择直接影响预测结果。K值较小,模型复杂度高,易过拟合;K值较大,模型更简单,但可能欠拟合。通常通过交叉验证来确定最优K值。
1.4 分类决策规则
对于分类任务,K个最近邻中出现次数最多的类别被作为预测结果。可采用多数投票法或其他加权投票机制。
1.5 回归决策规则
在回归问题中,K个邻居的目标值的平均(或加权平均)被用作预测值。
2. 算法实现步骤
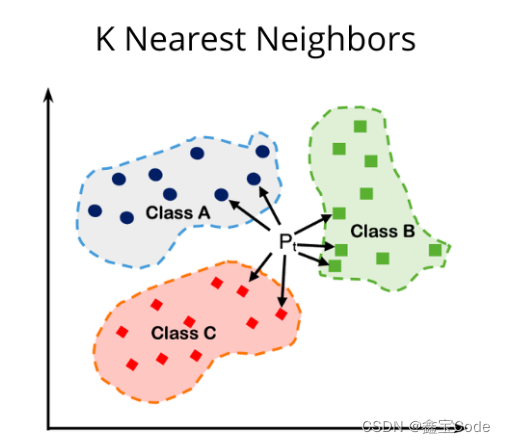
2.1 数据预处理
包括标准化、归一化等,确保不同特征之间的比较有意义。
2.2 计算距离
根据选定的距离度量方法,计算待预测样本与训练集中每个样本的距离。
2.3 选择K值
根据问题的具体情况和性能评估结果,确定一个合适的K值。
2.4 预测类别/值
依据分类或回归的决策规则进行预测。
2.5 算法优化策略
如使用KD树、Ball Tree等数据结构加速最近邻搜索,以及考虑距离加权等策略提高预测精度。
当然,为了使文章更加生动实用,下面我将用Python语言和scikit-learn库来展示KNN算法的一个简单实现示例,主要关注于分类任务。请注意,实际应用中还需要考虑数据预处理、模型评估等步骤,这里为了简化,我们直接从构建模型到预测。
准备工作
首先,确保你的环境中安装了numpy和scikit-learn库。如果未安装,可以通过pip安装:
pip install numpy scikit-learn
示例代码
假设我们有一个简单的分类数据集,我们将使用Iris数据集作为例子,这是scikit-learn内置的一个经典数据集。
# 导入所需库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, accuracy_score
# 加载数据
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 设置K值
k = 3
# 创建KNN分类器对象
knn = KNeighborsClassifier(n_neighbors=k)
# 训练模型(实际上KNN是懒惰学习,此处"训练"实质上是存储数据)
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 评估模型
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
代码解释
-
导入必要的库和模块:
load_iris用于加载Iris数据集,train_test_split用于数据集的分割,KNeighborsClassifier是KNN分类器的实现,classification_report和accuracy_score用于评估模型性能。 -
数据加载与分割:使用
load_iris()加载数据集,然后将其划分为训练集和测试集,以便后续的训练和评估。 -
模型构建:通过设置
n_neighbors=k创建KNN分类器实例,其中k是我们选择的邻居数量。 -
训练与预测:虽然KNN是懒惰学习,不涉及实际的“训练”过程,但调用
fit方法实际上是存储训练数据。之后,使用predict方法对测试集进行预测。 -
性能评估:最后,通过计算准确率和打印分类报告来评估模型的表现。
此代码示例展示了如何使用scikit-learn快速实现KNN分类器,从数据准备到模型评估的全过程。在实际应用中,还应考虑数据预处理、参数调优等以进一步提升模型性能。
3. KNN算法优缺点
3.1 优点
- 简单易懂:无需训练过程,实现简单。
- 无参数学习:除了K值外,没有其他需要调节的参数。
- 适用于多分类问题。
3.2 缺点
- 计算成本高:特别是对于大规模数据集,每次预测都需要遍历整个训练集。
- 对噪声敏感:训练数据中的异常值会对预测结果产生较大影响。
- 存储需求大:需要存储全部训练数据。
3.3 改进措施
- 使用近似最近邻搜索算法减少计算量。
- 对数据进行降维处理,减少计算复杂度。
- 引入软间隔和距离加权等策略提高鲁棒性。
4. 应用实例
4.1 图像识别
KNN可用于手写数字识别,通过像素值作为特征,实现对数字的分类。
4.2 推荐系统
基于用户或物品的相似度,KNN可以为用户推荐与其过去偏好相似的内容。
4.3 医疗诊断
利用病人的各项指标作为特征,KNN可以帮助预测疾病类型或风险等级。
5. 性能评估与参数调优
5.1 交叉验证
采用K折交叉验证来评估模型的泛化能力,避免过拟合。
5.2 K值的选择策略
通过网格搜索、随机搜索等方法寻找最优K值,结合具体问题的准确率、召回率等评价指标。
5.3 距离权重调整
考虑距离对预测的影响,较近的邻居给予更大的权重,提高预测准确性。
6. 与其他算法对比
与其他机器学习算法相比,KNN的解释性强,但计算效率低;而如支持向量机、决策树等虽然可能在效率和准确性上有所优势,但模型复杂度较高,解释性较差。
7. 结论与展望
K-近邻算法以其简洁高效的特点,在众多领域展现了广泛的应用价值。随着计算技术的发展,尤其是近似最近邻搜索算法的进步,KNN的效率问题正逐步得到缓解。未来,结合深度学习等技术,KNN有望在大数据背景下展现出更多潜力,为解决复杂问题提供有力工具。
本文全面介绍了K-近邻算法的基本原理、实现步骤、优缺点、应用实例以及性能评估与调优方法,并对比了与其他算法的不同之处,旨在为读者提供一个系统且深入的理解框架。希望对从事机器学习研究与应用的读者有所启发。





![[算法][数字][leetcode]2769.找出最大的可达成数字](https://img-blog.csdnimg.cn/direct/282ccc3317fa4ea697aec5bc1e37c6c0.png)