【摘要】由于图神经网络 (GNN) 通常会随着分布变化而出现性能下降,因此分布外 (OOD) 泛化在图学习中引起了越来越多的关注。挑战在于,图上的分布变化涉及节点之间错综复杂的互连,并且数据中通常不存在环境标签。在本文中,我们采用自下而上的数据生成视角,并通过因果分析揭示了一个关键观察结果:GNN 在 OOD 泛化中失败的关键在于来自环境的潜在混杂偏差。后者误导模型利用自我图特征与目标节点标签之间的环境敏感相关性,导致在新的未见节点上出现不良的泛化。基于这一分析,我们引入了一种概念上简单但原则性的方法,用于在节点级分布变化下训练稳健的 GNN,而无需事先了解环境标签。我们的方法采用了一种源自因果推理的新学习目标,该目标协调了环境估计器和专家混合 GNN 预测器。新方法可以抵消训练数据中的混杂偏差,并促进学习可推广的预测关系。大量实验表明,我们的模型可以有效地增强各种分布偏移下的泛化能力,并且在图 OOD 泛化基准上比最先进的方法提高高达 27.4% 的准确率。
原文:Graph Out-of-Distribution Generalization via Causal Intervention
地址:https://arxiv.org/abs/2402.11494
代码:https://github.com/fannie1208/CaNet
出版:www 24
机构: 上海交通大学写的这么辛苦,麻烦关注微信公众号“码农的科研笔记”!
1 研究问题
本文研究的核心问题是: 如何设计一个图神经网络模型,使其能够在结点属性分布发生变化时,仍然保持良好的泛化性能。
假设一个社交网络中,用户的爱好与其朋友的年龄分布密切相关。在大学生群体中,朋友都比较年轻的用户往往更喜欢篮球运动。但是这种相关性可能只在大学生群体中成立,对于职场社交网络LinkedIn,用户的年龄与其爱好的相关性可能就很弱。如果我们基于大学生的社交网络训练了一个用于预测用户爱好的图神经网络,那么将其直接应用于LinkedIn,可能会遇到泛化失败的问题。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
图数据中的分布变化往往涉及到结点之间的复杂交互与关联,需要模型能够充分考虑不同结点的结构化特征。
-
在图学习问题中,每个结点所处的环境信息通常是隐含的,难以直接获取。这为模型从观测数据中推断有用的环境信息,以指导学习过程,带来了障碍。
针对这些挑战,本文提出了一种基于因果干预的"因果网络(CaNet)"方法:
CaNet巧妙地借鉴了因果推理中的 do-calculus 思想,通过显式地对环境变量建模,消除了隐含的混淆偏差。具体来说,它引入了一个环境估计器,负责基于输入的局部子图推断可能的环境信息。同时,图神经网络的每一层都配备了一组 mixture-of-expert 的传播单元,可以动态地根据推断的环境选择不同的传播方式。通过环境估计器和图神经网络的协同优化,CaNet 可以自动地发现观测数据中的稳定关系,同时避免捕获那些容易受环境变化影响的虚假相关性。这一设计理念犹如为图神经网络装上了一副"透视镜",让它对不可见的因果机制具备了感知和适应的能力。
2 研究方法
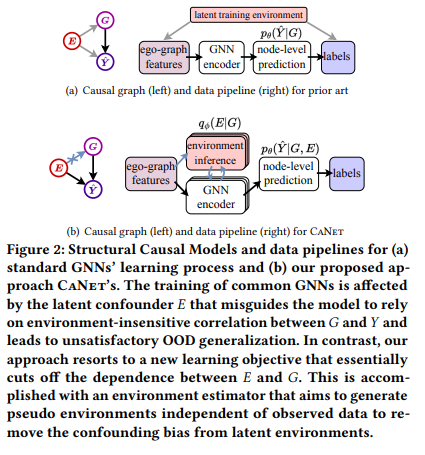
2.1 因果分析
论文首先从因果的角度来分析GNN面临分布外泛化问题的根本原因。如图2(a)所示,论文使用有向无环图建模了节点的ego-graph特征、节点标签和环境因素之间的因果依赖关系。可以看到,作为未观测的混淆因素,会影响和的生成过程。当使用最大似然估计来训练GNN时,由于忽略了的影响,模型会错误地学习到由某些特定的引起的和之间的强相关性(如在大学生群体中,"朋友年轻"和"喜欢打篮球"往往同时成立)。然而,这类相关性是不稳定的,一旦测试环境发生变化(如职场人士的社交网络),先前学到的相关性便不再成立。这导致了GNN在分布外数据上的泛化性能显著下降。
2.2 因果干预
为了消除环境因素的混淆偏差,进而提升GNN的分布外泛化性能,论文提出了一种基于因果干预的方法。借助后门调整公式,论文指出,优化干预分布而非观测分布,可以有效避免环境因素的混淆。然而,的求解需要穷举所有可能的环境,这在实际中是不可行的。为此,论文进一步引入变分推断,得到的一个变分下界,如式(5)所示:
其中,是根据节点的ego-graph特征来推断环境因素的估计器,是给定ego-graph特征和推断的环境标签来预测节点标签的GNN。通过最大化该变分下界,可以得到协同优化的算法:环境估计器尽可能准确地推断环境因素,同时要求推断结果与ego-graph特征保持独立;而GNN预测器则根据ego-graph特征和推断的环境因素来预测节点标签。通过协同学习,模型可以学习到与具体环境无关的稳定预测模式,进而提升分布外泛化性能。
2.3 模型实例化
在CaNet中,环境估计器将环境因素表示为一系列伪环境标签向量,其中表示GNN的层数。如式(6-7)所示(太难打了,公式见原文),对于每个节点的第层表示,环境估计器首先计算该节点属于每个伪环境的概率,然后通过Gumbel-Softmax技巧对重参数化,得到。
GNN预测器的核心是一个层的混合专家传播网络,每一层包含个专家分支。如式(8-9)所示,每个分支采用独立的参数,并由推断的伪环境标签进行选择。不同分支学习ego-graph特征的不同组合模式,赋予模型更强的表征能力。GNN预测器的最后一层输出节点表示,并通过全连接层映射为节点标签的预测值。
算法1总结了CaNet的前向计算和训练优化流程。其中,环境估计器和GNN预测器通过梯度下降法交替优化,协同学习对分布外泛化有利的预测模式。

5 实验
5.1 实验场景介绍
该论文提出了一个处理图神经网络节点级别分布差异的因果干预方法CaNet。实验主要在节点属性预测任务中,验证CaNet相比其他模型在训练集和测试集节点分布不一致情况下的泛化优势。同时通过消融实验、超参数分析等进一步探究模型内部机制。
5.2 实验设置
-
Datasets:使用Cora、Citeseer、Pubmed、Twitch、Arxiv、Elliptic等6个不同规模和属性的节点预测数据集,通过时间属性、子图、动态快照等不同方式构建训练集和测试集的分布差异
-
Baseline:ERM, IRM, DeepCoral, DANN, GroupDRO, Mixup等通用OOD方法;SR-GNN, EERM等图数据OOD方法;均使用GCN和GAT作为编码器骨干
-
Implementation details:基于PyTorch 1.13和PyG 2.1, Adam优化器,训练500轮,网格搜索超参数
-
metric:Accuracy, ROC-AUC, macro F1
5.3 实验结果
5.3.1 实验一、不同数据集上的性能对比
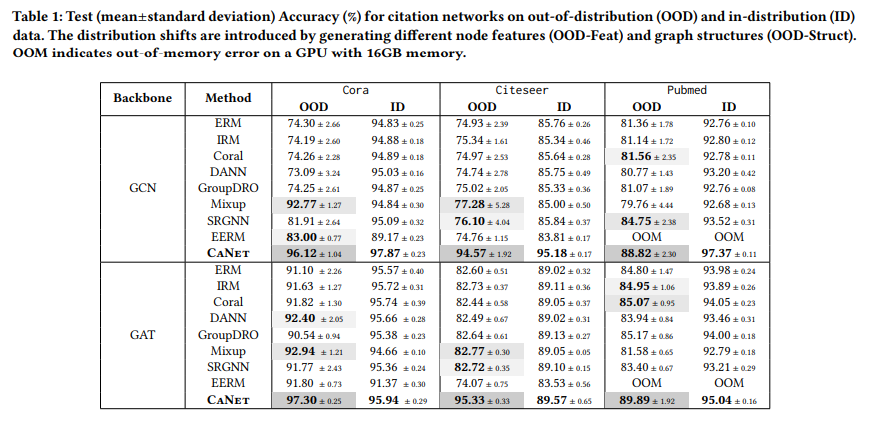
目的:在多个数据集上验证CaNet相比其他模型处理分布差异节点的优势
涉及图表:表1,表3,图4
实验细节概述:在Cora、Citeseer、Pubmed上测试合成特征和结构导致的分布差异;在Arxiv上测试不同时间的论文节点;在Twitch上测试不同子图的节点;在Elliptic上测试不同时间快照的节点
结果:
-
CaNet在所有OOD测试集上显著优于对应的基线,在ID测试集上也有竞争力的表现
-
在Cora和Citeseer上,CaNet在OOD数据的绝对性能接近ID数据
-
在Arxiv的跨时间差异最大的测试集上,CaNet超出次优baseline 14.1%和27.4%
-
在Elliptic的动态图快照测试集上,CaNet平均超出次优baseline 12.16%
5.3.2 实验二、消融实验
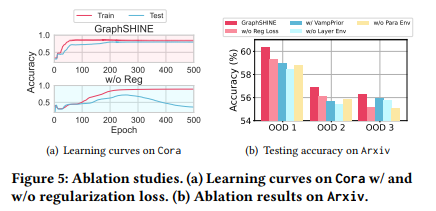
目的:验证正则化损失、层级环境推断等关键组件的有效性
涉及图表:图5
实验细节概述:去除正则化损失、使用复杂先验分布、采用全局环境表示、使用非参数环境估计器等简化变体
结果:
-
正则化损失和层级环境推断能有效提升OOD性能
-
简单先验分布优于复杂先验,更利于泛化
5.3.3 实验三、超参数分析
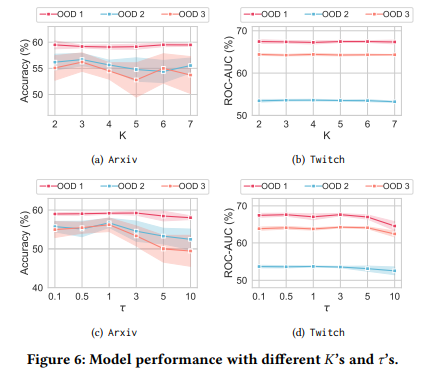
目的:探究伪环境数K和温度τ对模型性能的影响
涉及图表:图6
实验细节概述:在Arxiv和Twitch上分别评估不同K和τ下模型在各OOD测试集的表现
结果:
-
性能对K不太敏感,过大或过小的K在Arxiv的OOD 2/3上可能降低性能
-
适中的τ(如1)效果最佳,过大的τ会导致性能下降
5.3.4 实验四、可视化分析

目的:直观展现不同分支学习到的权重模式差异
涉及图表:图7,8,9,10
实验细节概述:可视化K=3时模型在Arxiv和Twitch上第一层和最后一层不同分支的权重矩阵
结果:不同分支权重有明显差异,说明mixture-of-expert结构能学习到区分不同伪环境的表达模式,利于泛化
4 总结后记
本论文针对图神经网络在面对分布偏移时泛化能力较差的问题,从因果分析的角度揭示了其根源在于未观测到的环境混淆因素。基于此分析,提出了一种通过因果干预改进图神经网络泛化性的方法CaNet。该方法引入了环境估计器和混合专家传播网络,可以在没有先验环境标签的情况下,通过优化一个新的学习目标来捕获对环境不敏感的预测关系,从而提高模型的分布外泛化能力。实验结果表明,该模型在多个具有不同类型分布偏移的数据集上,相比现有方法可以显著提升泛化性能,泛化准确率提升高达27.4%。
疑惑和想法:
-
除了节点层面的分布偏移,该方法是否可以推广到处理图层面或子图层面的分布偏移?
-
环境估计器推断出的伪环境标签对应着什么物理含义?能否赋予它们可解释性?
-
除了混合专家传播网络,是否可以设计其他形式的条件传播机制来建模环境因素对节点表示的影响?
可借鉴的方法点:
-
从因果分析角度揭示模型泛化不足的根源,为诊断和改进其他类型的图学习任务提供了新的思路。
-
通过优化包含对抗正则化项的目标函数来消除混淆偏差,可以推广到其他需要增强鲁棒性的机器学习场景。
-
环境估计器和条件传播网络的思想可以借鉴到图预训练等其他图表示学习任务中,以建模不同图之间的差异。