💡💡💡本文改进:替换YOLOv10中的PSA进行二次创新,1)EMA替换 PSA中的多头自注意力模块MHSA注意力;2) EMA直接替换 PSA;
在NEU-DET案列进行可行性验证,1)mAP50从0.683提升至0.698;2)mAP50从0.683提升至0.695;
改进1结构图:

改进2结构图:

1.YOLOv10介绍

论文: https://arxiv.org/pdf/2405.14458
代码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
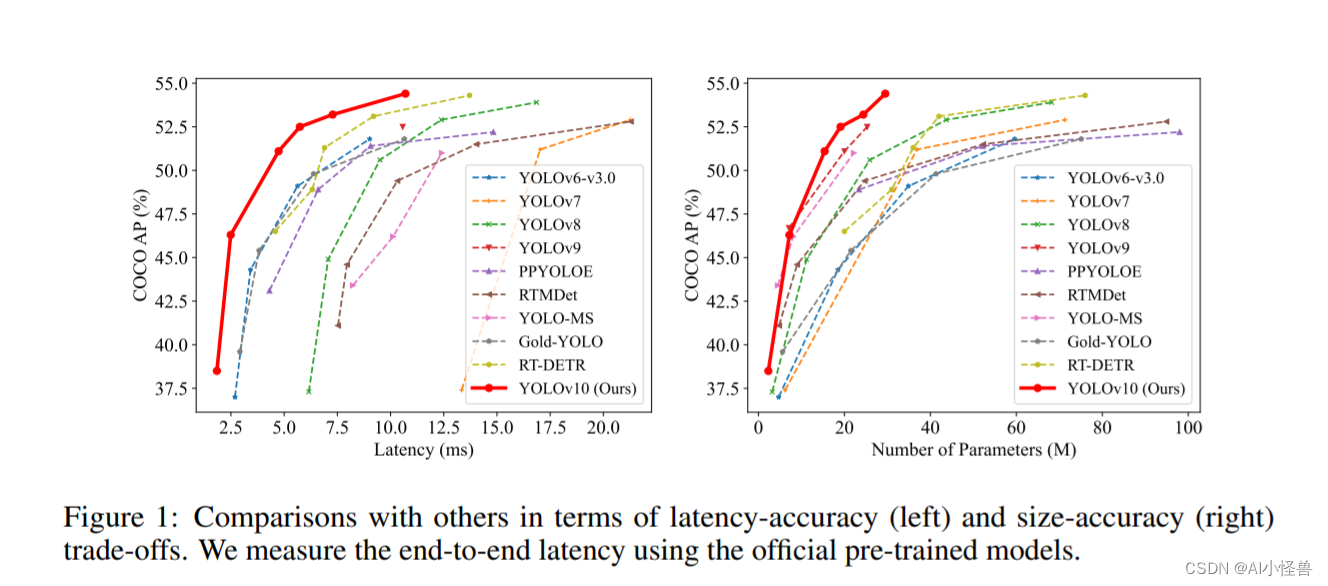
摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成为实时目标检测领域的主导范例。研究人员已经探索了YOLOS的架构设计、优化目标、数据增强策略等,并取得了显著进展。然而,对用于后处理的非最大抑制(NMS)的依赖妨碍了YOLOS的端到端部署,并且影响了推理延迟。此外,YOLOS中各部件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的性能。这导致次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOS的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法带来了有竞争力的性能和低推理延迟。此外,我们还介绍了YOLOS的整体效率-精度驱动模型设计策略。我们从效率和精度两个角度对YOLOS的各个组件进行了全面优化,大大降低了计算开销,增强了性能。我们努力的成果是用于实时端到端对象检测的新一代YOLO系列,称为YOLOV10。广泛的实验表明,YOLOV10在各种模型规模上实现了最先进的性能和效率。例如,在COCO上的类似AP下,我们的YOLOV10-S比RT-DETR-R18快1.8倍,同时具有2.8倍更少的参数和FLOPS。与YOLOV9-C相比,YOLOV10-B在性能相同的情况下,延迟减少了46%,参数减少了25%。
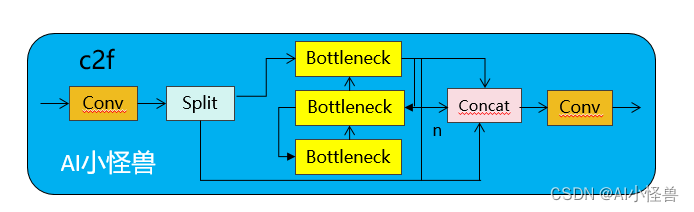
1.1 C2fUIB介绍
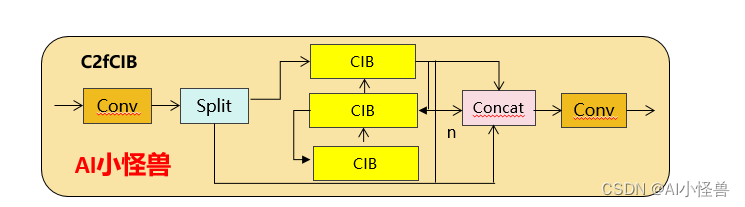
为了解决这个问题,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计降低被证明是冗余的阶段复杂度。我们首先提出了一个紧凑的倒置块(CIB)结构,它采用廉价的深度可分离卷积进行空间混合,以及成本效益高的点对点卷积进行通道混合
C2fUIB只是用CIB结构替换了YOLOv8中 C2f的Bottleneck结构
实现代码ultralytics/nn/modules/block.py
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
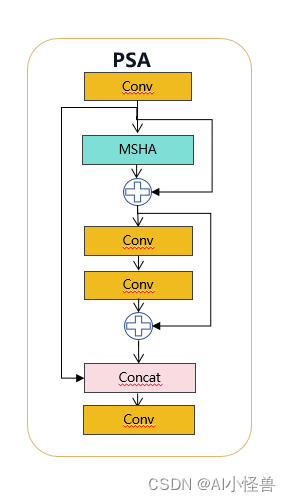
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))1.2 PSA介绍
具体来说,我们在1×1卷积后将特征均匀地分为两部分。我们只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
实现代码ultralytics/nn/modules/block.py
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))1.3 SCDown
OLOs通常利用常规的3×3标准卷积,步长为2,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本O(9HWC^2)和参数数量O(18C^2)。相反,我们提议将空间缩减和通道增加操作解耦,以实现更高效的下采样。具体来说,我们首先利用点对点卷积来调整通道维度,然后利用深度可分离卷积进行空间下采样。这将计算成本降低到O(2HWC^2 + 9HWC),并将参数数量减少到O(2C^2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在减少延迟的同时保持了有竞争力的性能。
实现代码ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))2.YOLOv10加入注意力机制
2.1.EMA注意力介绍

论文:https://arxiv.org/abs/2305.13563v1
通过通道降维来建模跨通道关系可能会给提取深度视觉表示带来副作用。本文提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。
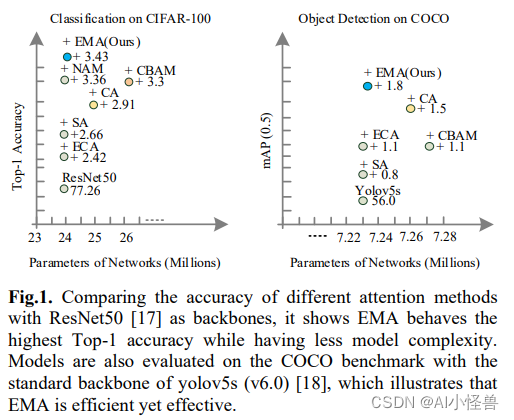
提出了一种新的无需降维的高效多尺度注意力(efficient multi-scale attention, EMA)。请注意,这里只有两个卷积核将分别放置在并行子网络中。其中一个并行子网络是一个1x1卷积核,以与CA相同的方式处理,另一个是一个3x3卷积核。为了证明所提出的EMA的通用性,详细的实验在第4节中给出,包括在CIFAR-100、ImageNet-1k、COCO和VisDrone2019基准上的结果。图1给出了图像分类和目标检测任务的实验结果。我们的主要贡献如下:
本文提出了一种新的跨空间学习方法,并设计了一个多尺度并行子网络来建立短和长依赖关系。
1)我们考虑一种通用方法,将部分通道维度重塑为批量维度,以避免通过通用卷积进行某种形式的降维。
2)除了在不进行通道降维的情况下在每个并行子网络中构建局部的跨通道交互外,我们还通过跨空间学习方法融合两个并行子网络的输出特征图。
3)与CBAM、NAM[16]、SA、ECA和CA相比,EMA不仅取得了更好的结果,而且在所需参数方面效率更高。
2.2 NEU-DET数据集为案列进行对比实验
NEU-DET钢材表面缺陷共有六大类,一共1800张,
类别分别为:'crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches'
2.3 实验结果分析
2.3.1 训练方式
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOv10
if __name__ == '__main__':
model = YOLOv10('ultralytics/cfg/models/v10/yolov10n-EMA_attention.yaml')
#model.load('yolov10n.pt') # loading pretrain weights
model.train(data='data/NEU-DET.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)原始YOLOv10n结果如下:
原始mAP50为0.683
YOLOv10n summary (fused): 285 layers, 2696756 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:12<00:00, 1.27it/s]
all 486 1069 0.634 0.662 0.683 0.392
crazing 486 149 0.409 0.248 0.298 0.0996
inclusion 486 222 0.677 0.774 0.768 0.411
patches 486 243 0.789 0.868 0.905 0.582
pitted_surface 486 130 0.752 0.722 0.757 0.492
rolled-in_scale 486 171 0.549 0.561 0.561 0.263
scratches 486 154 0.63 0.797 0.807 0.505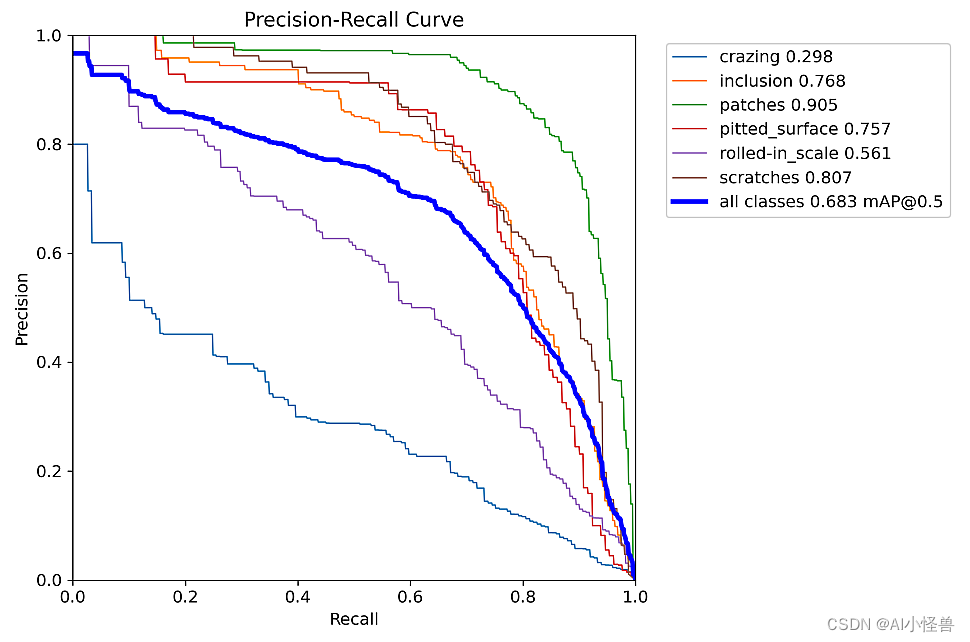
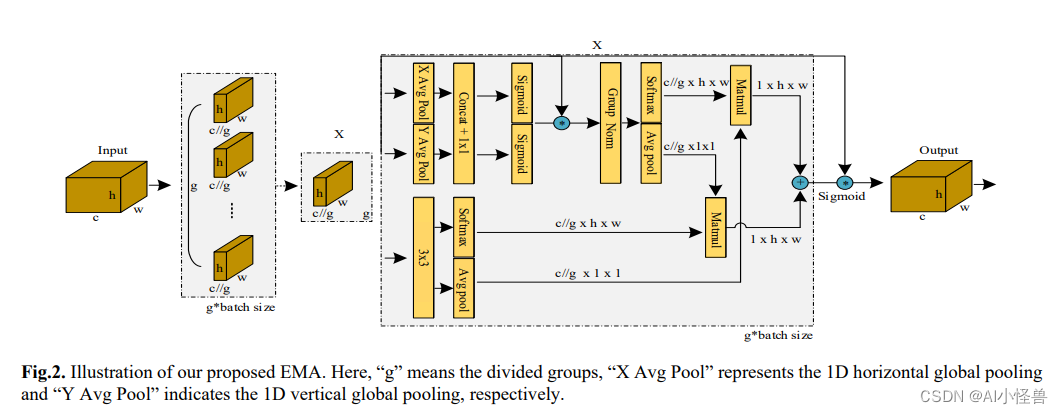
2.3.2 EMA替换 MHSA注意力
替换PSA中的MHSA注意力为EMA,结构图和代码如下

class EMA_attention(nn.Module):
def __init__(self, channels, factor=8):
super(EMA_attention, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
class EMA_imporve(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert (c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = EMA_attention(self.c)
self.ffn = nn.Sequential(
Conv(self.c, self.c * 2, 1),
Conv(self.c * 2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))实验结果如下:
mAP50从0.683提升至0.698
YOLOv10n-EMA summary (fused): 283 layers, 2648564 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:10<00:00, 1.53it/s]
all 486 1069 0.69 0.635 0.698 0.391
crazing 486 149 0.539 0.22 0.351 0.117
inclusion 486 222 0.686 0.716 0.748 0.407
patches 486 243 0.803 0.868 0.907 0.566
pitted_surface 486 130 0.784 0.715 0.779 0.503
rolled-in_scale 486 171 0.615 0.468 0.553 0.256
scratches 486 154 0.712 0.825 0.853 0.5 
2.3.3 EMA直接替换 PSA
结构图如下
mAP50从0.683提升至0.695
YOLOv10n-EMA_attention summary (fused): 272 layers, 2448450 parameters, 0 gradients, 8.0 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:10<00:00, 1.56it/s]
all 486 1069 0.662 0.641 0.695 0.393
crazing 486 149 0.432 0.163 0.318 0.117
inclusion 486 222 0.664 0.73 0.749 0.405
patches 486 243 0.78 0.864 0.908 0.584
pitted_surface 486 130 0.848 0.723 0.806 0.52
rolled-in_scale 486 171 0.586 0.567 0.572 0.263
scratches 486 154 0.665 0.798 0.815 0.468 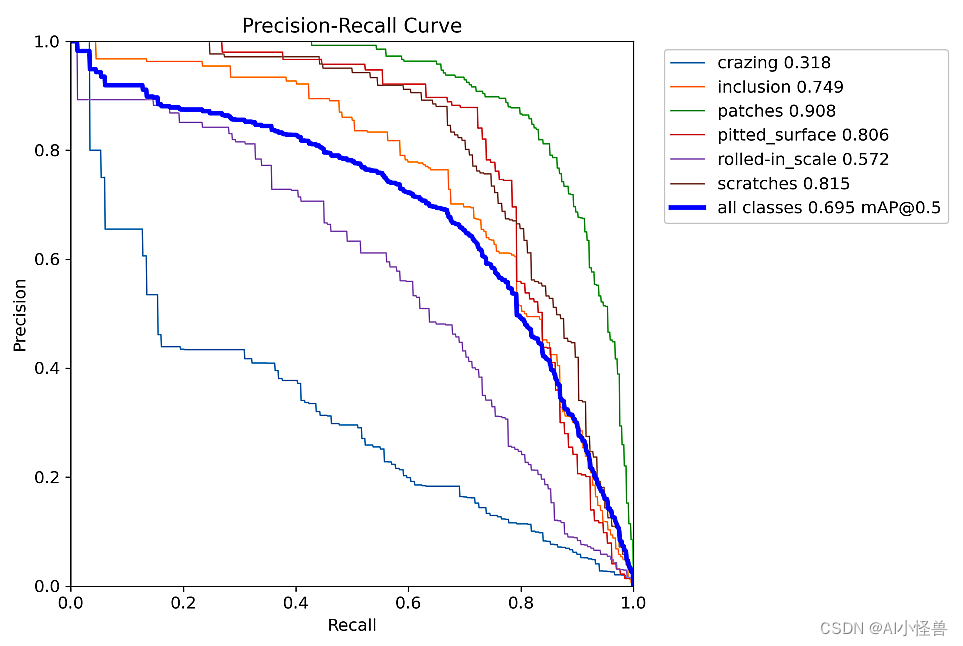
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!






![[Halcon学习笔记]Halcon窗口进行等比例显示图像](https://img-blog.csdnimg.cn/img_convert/424adf96e08fefe296458054e277565f.webp?x-oss-process=image/format,png)