虽然现成的大型语言模型 (LLM) 功能强大,但企业发现,根据其专有数据定制 LLM 可以释放更大的潜力。检索增强生成 (RAG) 已成为这种定制的主要方法之一。RAG 模型将大型语言模型强大的语言理解能力与检索组件相结合,使其能够从外部数据源收集相关信息。这使模型能够“读取”和利用企业数据来生成输出,从而产生更准确、更符合上下文的答案,并使用最新信息进行更新。
有许多工具可以帮助企业构建 RAG 架构;但是,构建高性能 RAG 系统需要对架构的每个步骤进行优化。本文将重点介绍在企业范围内构建有效 RAG 架构的数据准备流程和注意事项。
AI 模型的好坏取决于其数据。实施 RAG 需要精心准备模型将从中学习和检索上下文的数据源。清理、构建和优化大型知识库以将其提取到矢量数据库中可能具有挑战性,因为数据源通常包含结构化和非结构化数据。
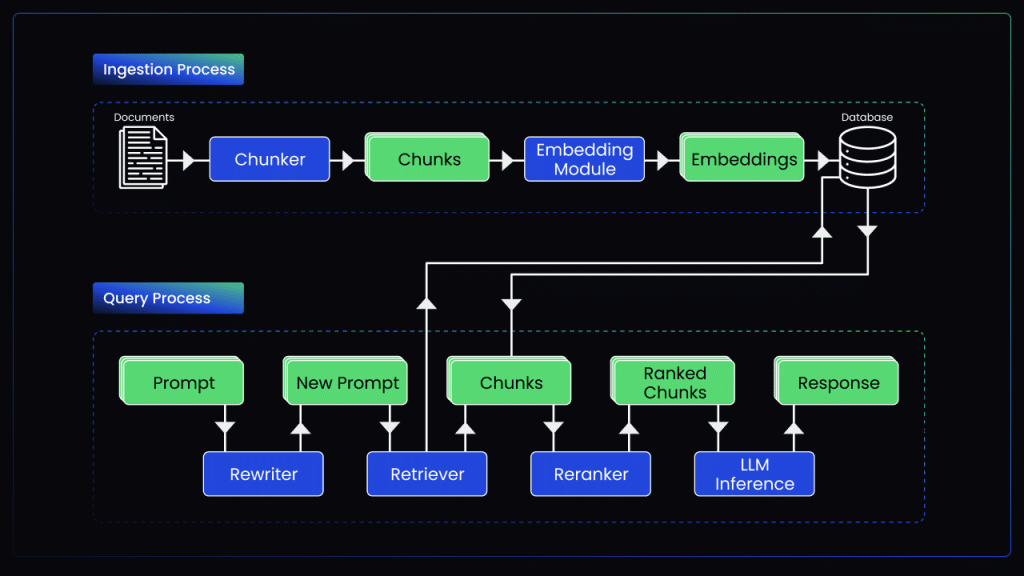
数据源整理过流程
- 数据源:用于构建 RAG 架构知识库的数据源是基础。它们必须是全面、高质量的来源,能够准确涵盖系统将要查询的领域和主题。此过程通常涉及选择符合您的用例要求的企业结构化和非结构化数据存储库的相关子集,并听取专家的意见。
- 数据清理:原始数据通常很嘈杂,包含不相关的内容、过时的信息和重复数据。这给 RAG 实施带来了挑战,因为模型无法从其知识库中检索相关且准确的信息,从而对生成产生负面影响。例如,Jira 或 Confluence 中的企业知识通常包含用户评论和版本更改历史记录,这些内容与存储在知识库中无关。在将数据输入矢量存储之前,有效的数据清理技术(例如过滤和重复数据删除)至关重要。
- 隐私/PII:企业数据集通常包含敏感和私人信息。作为数据准备过程的一部分,企业需要根据其用例和潜在最终用户定义如何处理这些数据。在内部用例中,LLM 可以合并有关个人的信息,例如查询“谁是沃尔玛账户的销售代表?”但是,对于外部用例,泄露有关个人的信息可能会导致隐私侵犯。即使设置了防护措施,对抗性攻击也可能导致训练数据意外泄露。确保适当处理 PII 元素,并在适当的情况下检测、过滤、编辑和用合成数据替换,可以保护隐私,同时保持数据实用性并防止潜在的合规性问题。
- 文本提取: 企业数据有多种格式,包括 PDF、PowerPoint 演示文稿和图像。从这些非结构化和半结构化来源中提取干净、可用的文本对于构建全面的知识库至关重要。文本提取的方法可能因文档的结构、形式和复杂性而异。简单的情况可能使用标准文本提取工具来解决,而更复杂的文档可能需要结合使用自动化工具和人工注释。
- 文本规范化:来自多个来源的数据通常在拼写、缩写、数字格式和引用样式等方面缺乏一致性。这可能会导致相同的概念被视为不同的实体,并且模型匹配度较低。应用规范化规则来标准化拼写、语法、测量和一般命名法对于最大限度地利用文本数据至关重要。
- 分块策略:按照上述步骤,需要将文档拆分成较短的“块”或段落,以便检索组件将其与查询匹配并传递给语言模型。目标是将文档拆分成可检索的单元,以保持关键信息的完整、相关上下文。常用方法包括固定大小分块、基于文档的分块和语义分块。一般来说,人类对数据是否应放在现有块中或形成新块的评估仍然被认为是黄金标准,一种称为“代理分块”的新兴、更先进的方法试图模仿这种人类行为。理想的块大小在具有足够的上下文和效率之间取得平衡,而总结或分层分块等方法也适用于长文档。
- 实体识别和标记:虽然从知识库中派生出的区块构成了向量存储的核心,但使用元数据(如源详细信息、主题和数据中的关键实体)丰富这些区块可以显著提高 RAG 模型的准确性。针对人员、组织、产品、概念和实体链接的命名实体识别 (NER) 可以帮助模型连接段落并增强检索相关性。这可以使用具有自动化技术和人机验证的数据注释平台系统地完成,以确保注释的准确性和一致性,并在必要时包括领域专家。
查询流程
- 段落排名:检索组件显示与查询匹配的候选段落后,在将它们传递给语言模型之前,按相关性对其进行排名和筛选至关重要。这可以避免从相关性较低的段落生成响应。排名可以利用相似度得分、上下文推理、元数据属性和查询段落对齐。
- 提示工程与设计: RAG 模型的有效性很大程度上取决于通过在内容(查询 + 上下文)中添加相关检索数据来增强用户输入。这些提示必须经过精心设计,才能有效获取和利用检索到的上下文,同时与输出响应所需的风格和语气保持一致。
持续评估和优化
上述数据考虑因素对于 RAG 的成功都至关重要。然而,由于存在许多变动因素,因此在整个训练过程中,可能很难了解其有效性和影响。
持续的测试、评估和优化对于有效识别和监控性能差距至关重要。组件评估对于解决特定问题非常有用,例如,评估检索是否来自向量存储中的最佳来源。端到端评估可用于根据目标用例评估整个系统的质量,最终目标是生成对人类最终用户有价值的响应。
利用 Appen 的专业知识
用于训练 RAG 模型的数据可能很复杂,对于希望部署 LLM 的企业来说仍然是一个挑战。Appen 的 AI 数据注释平台可让您无缝增强和集成专有数据,帮助提高以数据为核心的 RAG 实施的成功率。
立即联系 Appen,了解我们的专业知识和先进平台如何帮助您加速 RAG 之旅。






![[Halcon学习笔记]Halcon窗口进行等比例显示图像](https://img-blog.csdnimg.cn/img_convert/424adf96e08fefe296458054e277565f.webp?x-oss-process=image/format,png)