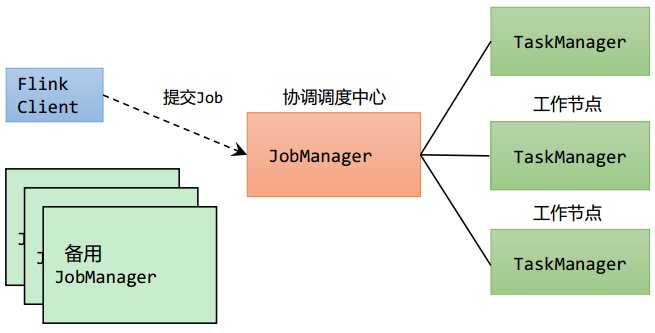
关键组件
- Client,代码由客户端获取并做转换,之后提交给JobManger
- JobManager,对作业进行中央调度管理,获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。
- TaskManager,数据的处理操作
在emr上自建standalone集群,文件分发脚本xsync
#!/bin/bash
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
nodelist=$(yarn node -list 2> /dev/null | awk 'NR > 2 {print $1}' | awk -F: '{print $1}')
for host in $nodelist
do
echo ==================== $host ====================
for file in $@
do
if [ -e $file ]
then
pdir=$(cd -P $(dirname $file); pwd)
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
先进入节点中创建flink文件(root用户)
#!/bin/bash
nodelist=$(yarn node -list 2> /dev/null | awk 'NR > 2 {print $1}' | awk -F: '{print $1}')
for node in $nodelist; do
echo "Executing commands on $node"
ssh -o StrictHostKeyChecking=no $node "
sudo mkdir -p /usr/lib/flink/
sudo chown -R hadoop:hadoop /usr/lib/flink
"
done
将/usr/lib/flink/同步到其他节点上
xsync /usr/lib/flink
xsync /etc/flink/conf.dist
重新软连接
#!/bin/bash
nodelist=$(yarn node -list 2> /dev/null | awk 'NR > 2 {print $1}' | awk -F: '{print $1}')
for node in $nodelist; do
echo "Executing commands on $node"
ssh -o StrictHostKeyChecking=no $node "
sudo rm /usr/lib/flink/conf
sudo ln -s /etc/flink/conf.dist/ /usr/lib/flink/conf
"
done
直接启动失败,需要指定workfile
No workers file. Please specify workers in 'conf/workers'.
root用户下写入workers配置
yarn node -list 2> /dev/null | awk 'NR > 2 {print $1}' | awk -F: '{print $1}' > /usr/lib/flink/conf/workers
echo $(hostname).cn-north-1.compute.internal:8081 > /usr/lib/flink/conf/masters
jobmanager配置
# JobManager 节点地址.
jobmanager.rpc.address: $(hostname).cn-north-1.compute.internal
jobmanager.bind-host: 0.0.0.0 # default
rest.address: 0.0.0.0 # webui
rest.bind-address: 0.0.0.0
taskmanager配置
echo taskmanager.host: $(hostname).cn-north-1.compute.internal >> /usr/lib/flink/conf/flink-conf.yaml
echo taskmanager.bind-host: 0.0.0.0 >> /usr/lib/flink/conf/flink-conf.yaml
修改权限
sudo chown -R hadoop:hadoop /var/lib/flink
启动集群
-
不知道为什么worker节点始终无法启动taskmanagerrunner,最终发现没有权限
-
这个路径是提供webui上传jar文件用的
mkdir: cannot create directory ‘/var/run/flink’: Permission denied /usr/lib/flink/bin/flink-daemon.sh: line 82: /var/run/flink: No such file or directory flock: 200: Bad file descriptor Starting taskexecutor daemon on host ip-192-168-28-247. /usr/lib/flink/bin/flink-daemon.sh: line 145: /var/run/flink/flink-hadoop-taskexecutor.pid: No such file or directory
/usr/lib/flink/bin/start-cluster.sh
在master上查看日志
最终taskmanager成功注册

关闭集群
/usr/lib/flink/bin/stop-cluster.sh
jpsall脚本
#!/bin/bash
masternode=$(hostname).cn-north-1.compute.internal
nodelist=$(yarn node -list 2> /dev/null | awk 'NR > 2 {print $1}' | awk -F: '{print $1}')
for host in $masternode $nodelist
do
echo =============== $host ===============
ssh $host jps
done
在yarn模式下,提交 JAR 文件后,它就会变成由 Flink JobManager 管理的作业。
- JobManager 位于托管 Flink 会话 Application Master 进程守护程序的 YARN 节点上
集群生命周期大于job,因此实际上对应session模式
flink run --jobmanager localhost:8081 /usr/lib/flink/examples/streaming/WordCount.jar --input s3://zhaojiew-tmp/shakespeare/ --output s3://zhaojiew-tmp/flinkoutput
flink run --jobmanager localhost:8081 -c org.example.wc.WordCountBatch flinkall-1.0.0.jar
部署模式
session模式
启动flink session
- 5.5.0 版本中添加了
flink-yarn-session命令作为yarn-session.sh脚本的包装程序以简化执行
flink-yarn-session -d

启动session后提交任务
flink run --jobmanager yarn-cluster -yid application_1704427099392_0001 /usr/lib/flink/examples/streaming/WordCount.jar --input s3://zhaojiew-tmp/shakespeare/ --output s3://zhaojiew-tmp/flinkoutput
Caused by: software.amazon.awssdk.services.s3.model.S3Exception: null (Service: S3, Status Code: 400, Request ID: 8XKQF6W01QDQCRTD, Extended Request ID: Bsi6AK3alrxV5OYL5aZhu05h/RusTGUBm9P9hRu5dFu0whCv68DKpvFjf8CYL9Wc5zSEoaL759M=)
可以设置region
- 看起来是6.15版本的emr_flink存在问题,默认region不对
-Dfs.s3a.bucket.endpoint.region=cn-north-1
在resourcemanager的Tracking UI会跳转到flink jobmanager
但是flink的taskmanager日志并没有汇聚到yarn历史服务器中
查看session fluster的ip和端口号


或者直接在提交jar界面看ip和端口地址,监听的是内网ip
- 找到后可以在idea中注册
per-job模式
直接运行batch任务
flink run -m yarn-cluster -Dexecution.runtime-mode=BATCH flinktutorial17-1.0.jar
不同类型任务的name

application模式
提交任务
-
将jar拷贝到
/usr/lib/flink/lib下 -
指定作业入口类,脚本会到 lib 目录扫描所有的 jar 包
/usr/lib/flink/bin/standalone-job.sh start --job-classname org.example.wc.WordCountBatch
Starting standalonejob daemon on host ip-192-168-30-184.
启动taskmanager
/usr/lib/flink/bin/taskmanager.sh start
在application模式下,yarn中同样没有记录
查看jps进程

在master上查看日志
yarn运行模式
yarn运行模式下同样可以使用三种部署模式
session模式
flink-yarn-session -d命令参数
- Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,YARN 会按照需求动态分配 TaskManager 和 slot
-d:分离模式
-jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB
-nm(--name):配置在 YARN UI 界面上显示的任务名
-qu(--queue):指定 YARN 队列名
-tm(--taskManager):配置每个 TaskManager 所使用内存。
per-job模式
提交任务
/usr/lib/flink/bin/flink run -t yarn-per-job -c org.example.wc.WordCountBatch flinkall-1.0.0.jar
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application",
"yarn-application".
如下报错的解决
- 在 flink 的/opt/module/flink-1.17.0/conf/flink-conf.yaml 配置文件中设置classloader.check-leaked-classloader: false

application模式
提交任务
/usr/lib/flink/bin/flink run-application -t yarn-application -c org.example.wc.WordCountBatch flinkall-1.0.0.jar
/usr/lib/flink/bin/flink run-application -t yarn-application s3://zhaojiew-bigdata/app/WordCount.jar --input s3://zhaojiew-tmp/shakespeare/ --output s3://zhaojiew-tmp/flinkoutput
可以看到print输出此时在jobmanager中
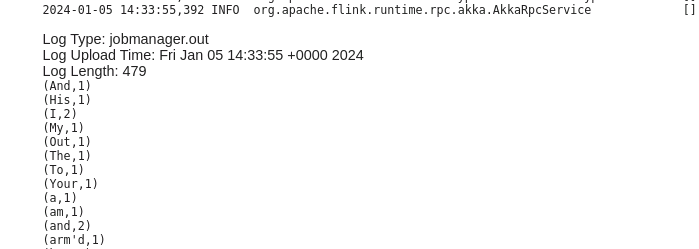
但是看起来并不支持将jar存储在s3?已知问题,怀疑和flink本身有关,因为使用s3作为input和output是没有问题的

可以在提交任务时指定依赖,并非任务jar
bin/flink run-application -t yarnapplication -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flinkdist" -c com.atguigu.wc.SocketStreamWordCount
hdfs://hadoop102:8020/flink-jars/FlinkTutorial-1.0-SNAPSHOT.jar