文章目录
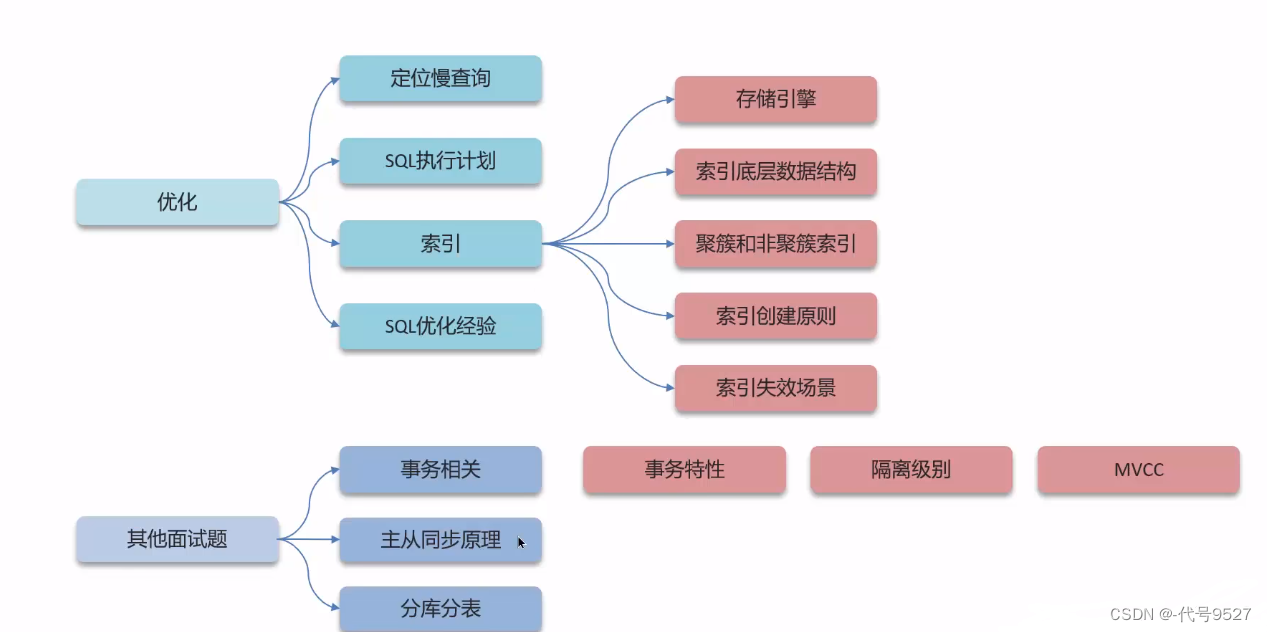
- 1、定位慢查询
- 2、慢查询的原因分析
- 3、索引
- 3.1 数据结构选用:二叉树 & 红黑树
- 3.2 数据结构选用:B+树
- 4、聚簇索引、非聚簇索引、回表查询
- 4.1 聚簇索引、非聚簇索引
- 4.2 回表查询
- 5、覆盖索引、超大分页优化
- 5.1 覆盖索引
- 5.2 超大分页处理
- 6、索引的创建
- 7、索引的失效
- 8、SQL优化的经验
- 9、面试
1、定位慢查询
- Arthas在线查看方法耗时
- 运维工具Prometheus
- 链路追踪工具Skywalking、Zipkin、OpenTemplate

- MySQL自带的慢日志:记录执行超过n秒的SQL
//修改配置文件,文件位置
/etc/my.cnf
//开启慢查询开关,生产环境不建议开启,会损失部分性能
slow_query_log=1
//设置超过2秒的SQL
long_query_time=2
慢SQL被记录到/var/lib/mysql/localhost-slow.log

2、慢查询的原因分析
慢SQL通常是因为:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
前三种,可尝试使用SQL执行计划分析原因:
# SELECT语句前添加EXPLAIN或DESC,查看SQL语句执行情况的信息
EXPLAIN select * from t_table;
DESC select * from t_table;

此时SELECT返回的不是表数据,是一些执行信息:
- possible: key 当前sql可能会使用到的索引
- key: 当前sql实际命中的索引
- key_len: 索引占用的大小,key和key_len搭配,检查是否存在索引失效
- Extra:额外的优化建议

- type:这条sql的连接的类型,性能由好到差为NULL、system、const、eq_ref、ref、range、index、all
system:查询MySQL系统内置库的表
const:根据主键查询
eq_re:主键索引查询或唯一索引查询
ref:索引查询
range:范围查询
index:索引树扫描,遍历整个索引
all:不走索引,全盘扫描
3、索引
一种用于高效查数据的数据结构,以某种方式指向表里的数据。如下表,不加索引,查age=45的数据,就是逐行对比 + 遍历整个表直至最后一行,效率低下

如果去维护一个类似二叉树的结构,再查age=45的数据,则直接从根节点开始⇒ 45 > 36,去右侧 ⇒ 45 < 48 ⇒去左侧 ⇒ 查找完毕,如此,查找效率提升,这即索引的思想
3.1 数据结构选用:二叉树 & 红黑树
MySQL索引底层的数据结构是B+树。不选二叉树是因为:
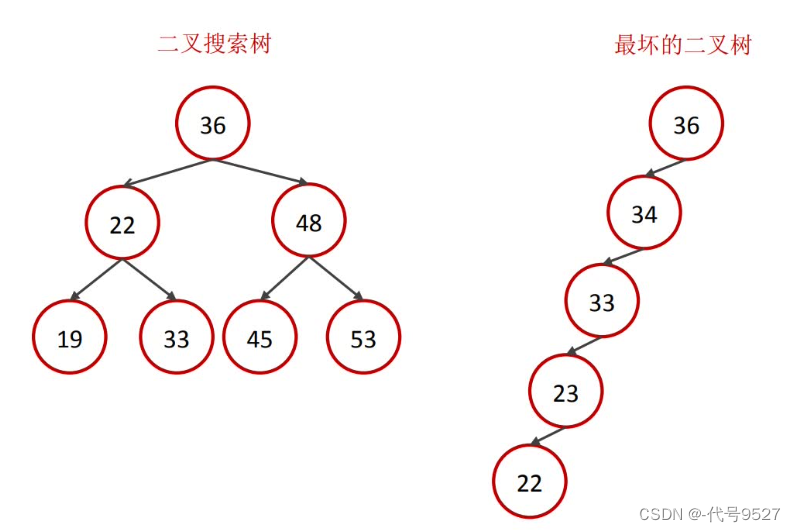
如果数据递增或递减,此时二叉树变链表,即最坏情况的二叉树效率很低。既然二叉树有平衡性问题,那再考虑自平衡的二叉树 ⇒ 红黑树
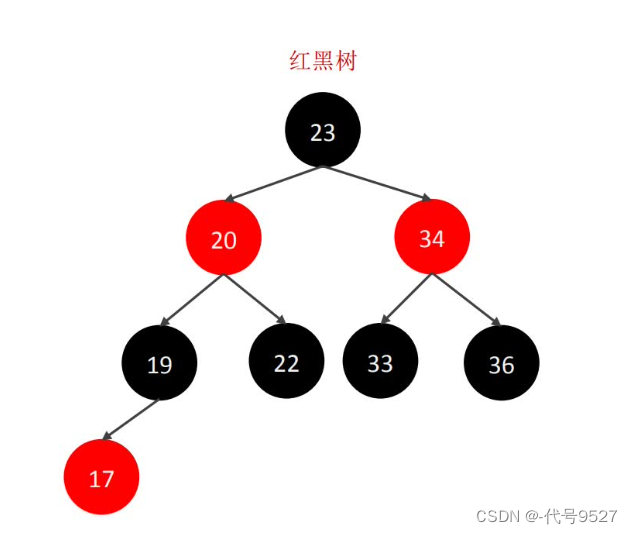
红黑树时间复杂度为O(log n),但其也是一个二叉树,每个节点最多只能两个分支,因此,大数据量下,红黑树会很高。 ⇒ B树,每个节点可以多个分支,是一种多叉路衡查找树。以一颗5阶B树为例(最大度数mas-degree为5,每个节点最多存储4个key)
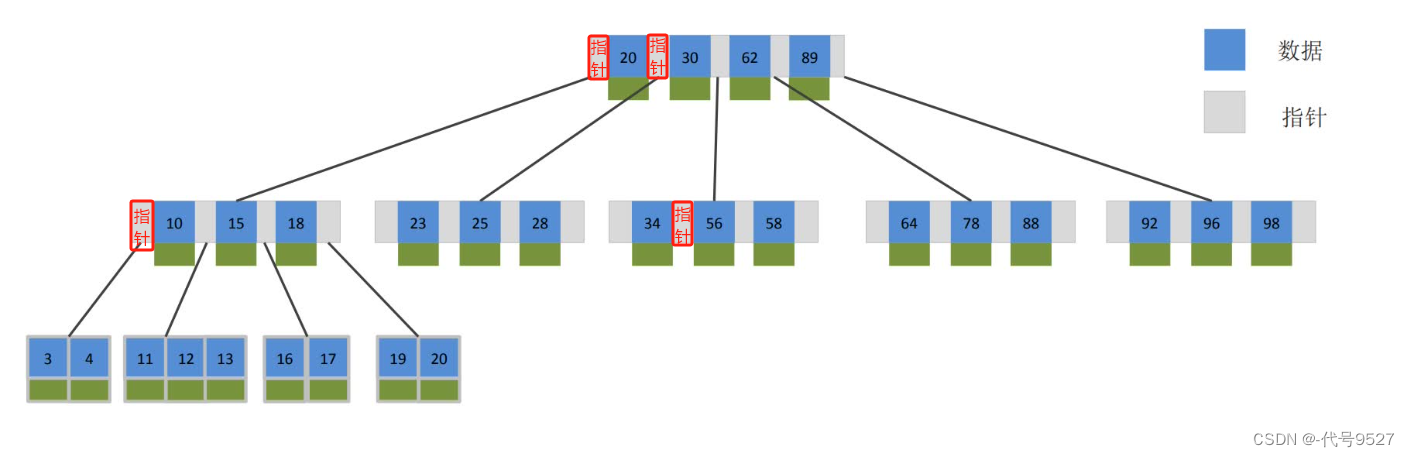
图中的灰色部分,存储指针,指向子节点。如20左侧的指针,指向的就是20以内的数据,20和30之间的指针,则指向20~30之间的数据,以此类推。且绿色部分存储的是对应的那条数据。
3.2 数据结构选用:B+树
相比二叉树,B树是一种矮胖树,B+树则是B树的一种优化,非叶子节点只存储指针,不存储数据。只有在叶子节点才去存储对应的数据,前面的非叶子节点起一个导航的作用,非叶子节点上就匹配到的数据,在叶子节点上也能找到这个数。
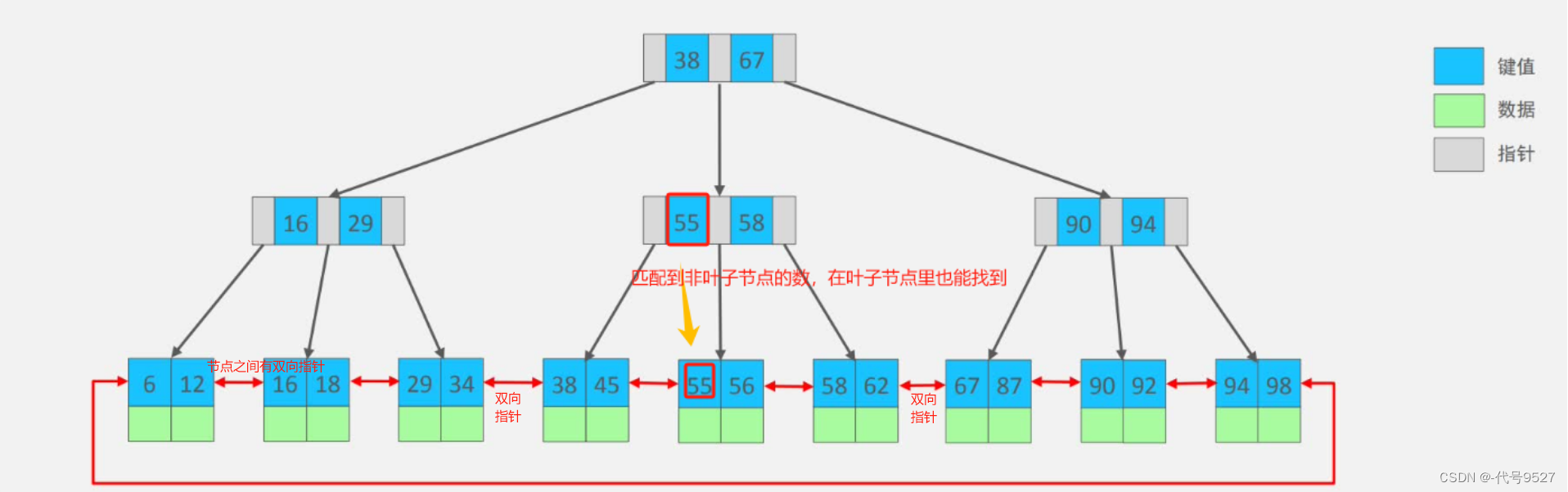
MySQL默认的存储引擎InnoDB默认使用B+树实现索引。相比B树,B+树:
- 磁盘读写代价更低(只有叶子节点存数据)
- 查询效率更稳定(最后都要落到叶子节点)
- 适合于区间查询(叶子节点之间的双向指针,比如查6~34这个区间的数,先从根节点对比,走左边,到16,再走左边,到6,再跟双向指针拿到6到34的数据,不需要再从根节点开始重新找一次)
4、聚簇索引、非聚簇索引、回表查询
4.1 聚簇索引、非聚簇索引
聚簇索引(又叫聚集索引),即B+树的叶子节点保存的是整行数据。非聚簇索引(又叫二级索引),即B+树单独叶子节点存储的是那行数据对应的主键

聚簇索引选取规则:(节点里存哪个)
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB 会自动生成一个rowid 作为隐藏的聚集索引
如下:建立聚簇索引时,这张表有主键ID,因此,节点中存储的是ID值,最后,叶子节点中存的那个row是整条数据值。
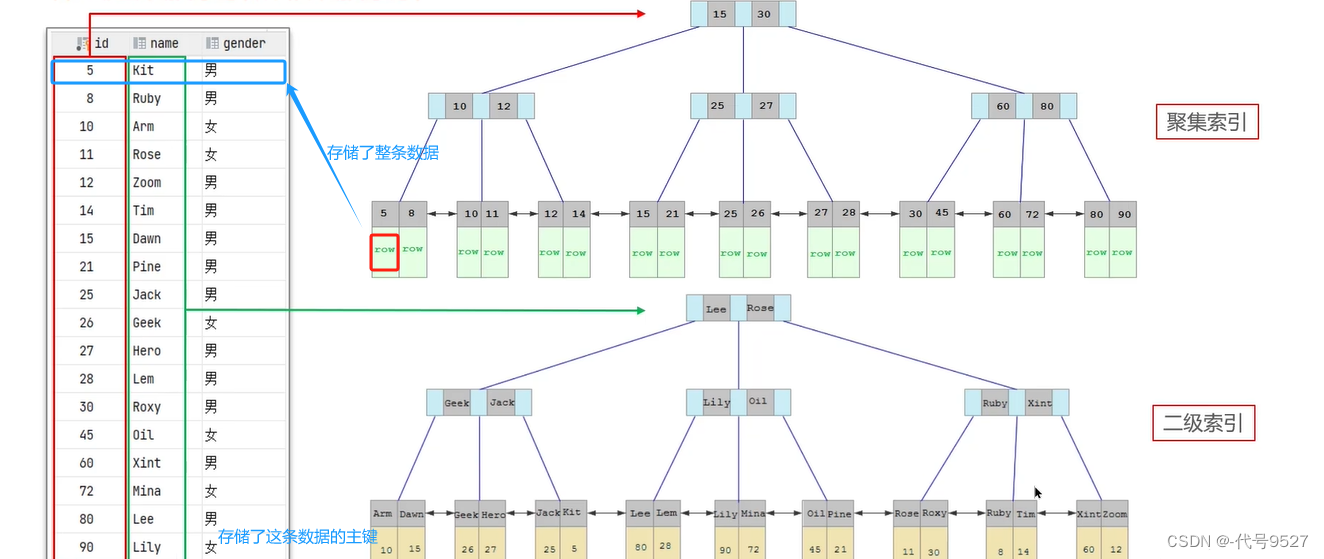
再比如给表的name字段建立非聚簇索引,节点存储name的值,最后的叶子节点,存储的是这条数据的主键值
4.2 回表查询
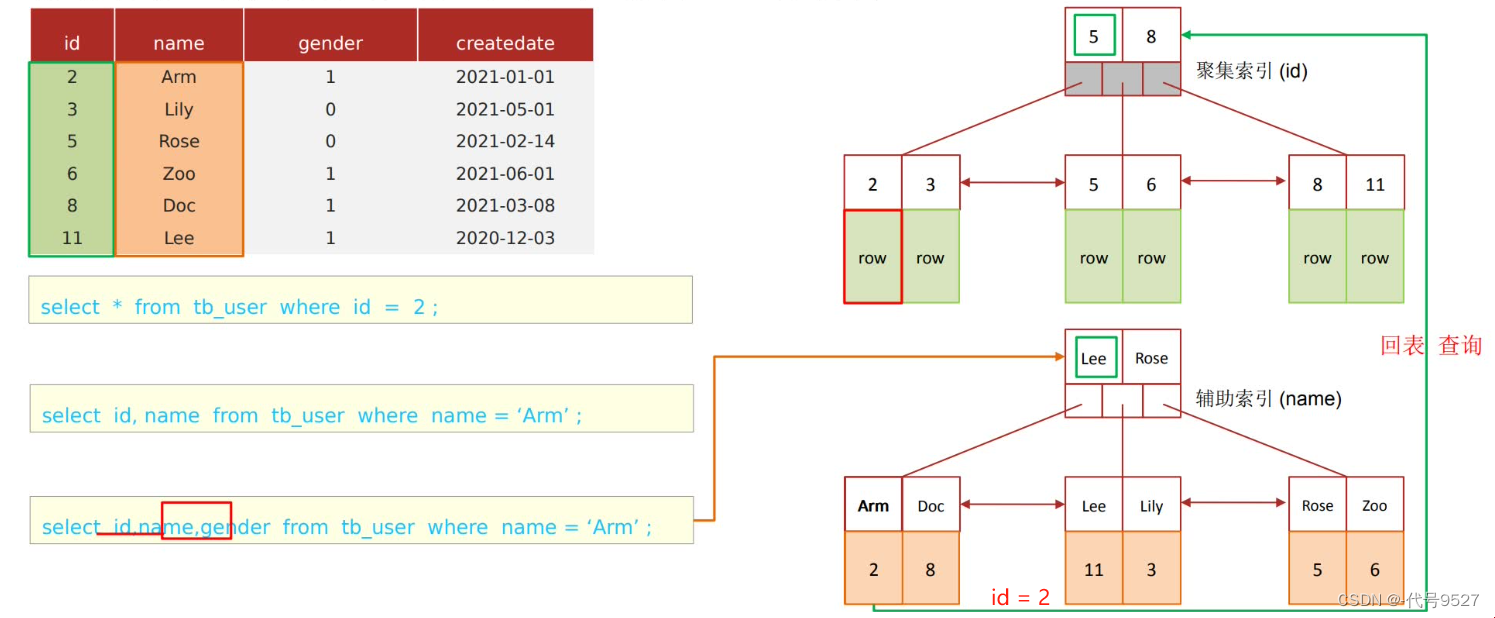
select * form user where name = 'Arm';
给name字段加了非聚簇索引,因此,执行如上SQL,先根据name的非聚簇索引的B+树 ⇒ A小于L,走左边,到G和J,再走左边,找到Arm ⇒ 因为是select *,而非聚簇索引的叶子节点存的是主键 ⇒ 拿着主键,回到聚簇索引,从其根节点开始查 ⇒ 聚簇索引的叶子节点存了整行数据,返回select * 的结果
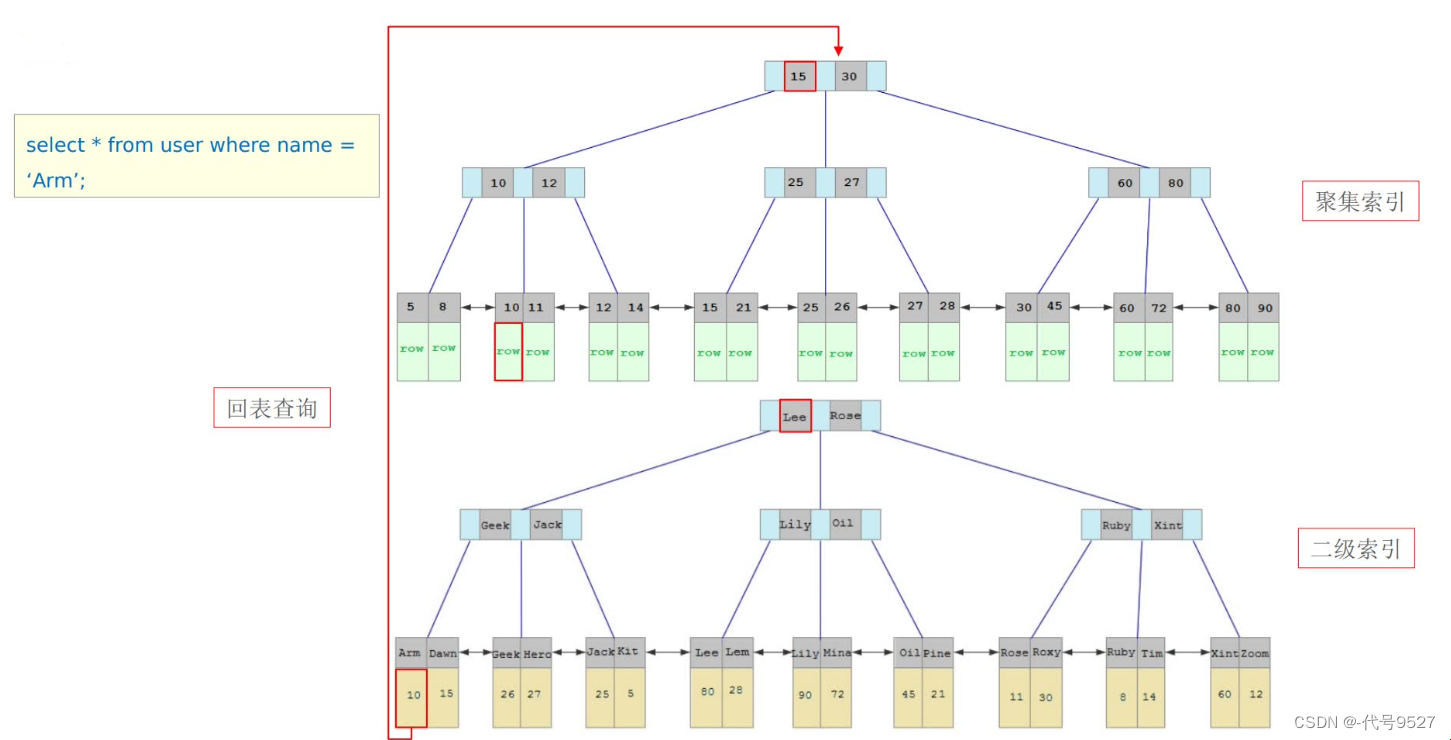
总之,回表查询就是:先根据非聚簇索引找到主键值,再根据主键值到聚簇索引拿到整行数据
5、覆盖索引、超大分页优化
5.1 覆盖索引
即查询使用了索引,并且你需要返回的字段,在索引中能够全部找到。
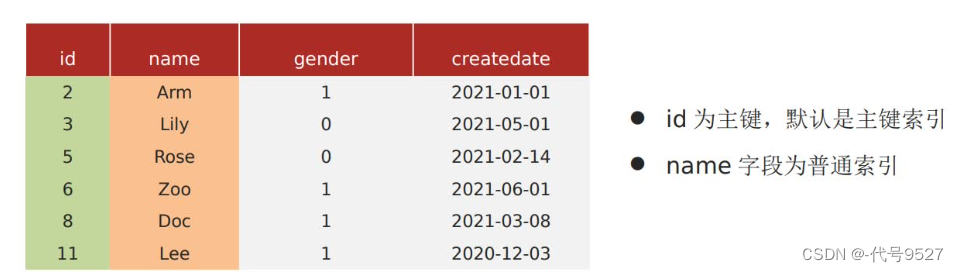
select * form tb_user where id = 1;
是覆盖索引,虽然select * ,但其where是根据id过滤的,即用的是主键索引、聚簇索引,索引的叶子节点存了整行数据,需要返回的字段,在索引中能够全部找到
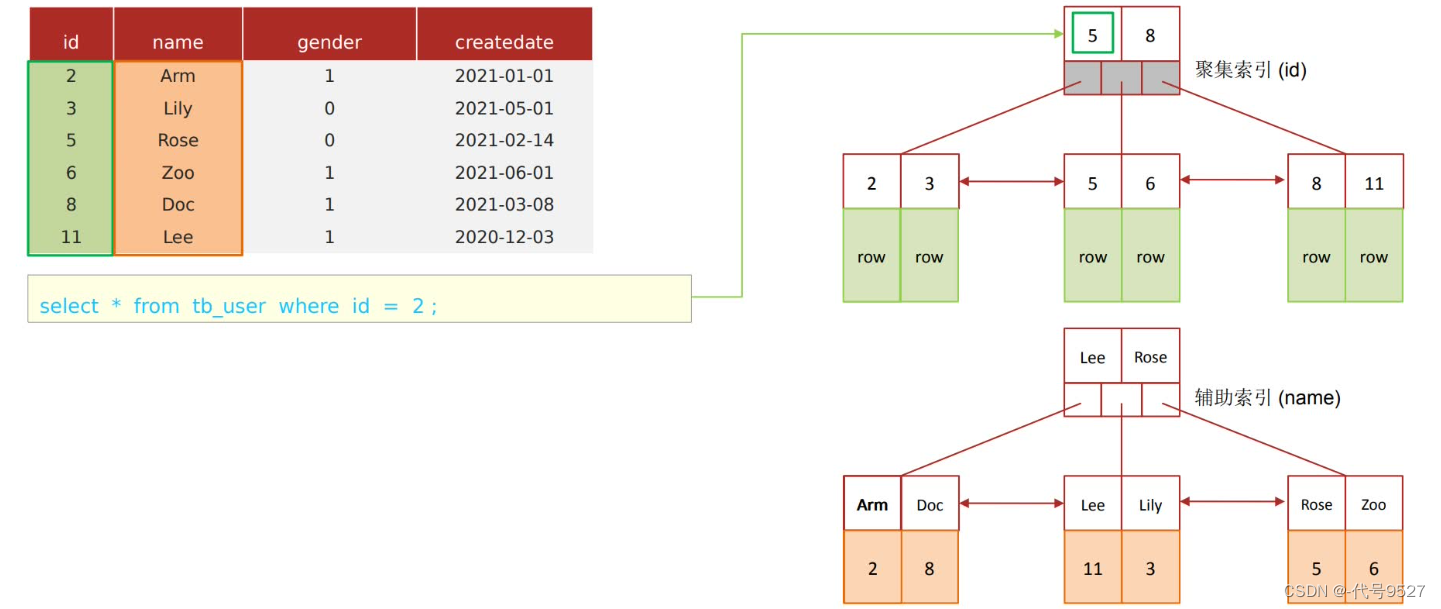
select id, name from tb_user where name = 'Arm';
是覆盖索引,where根据name过滤,走name的非聚簇索引,最后叶子节点存了id,而最后需要返回的就是id和name
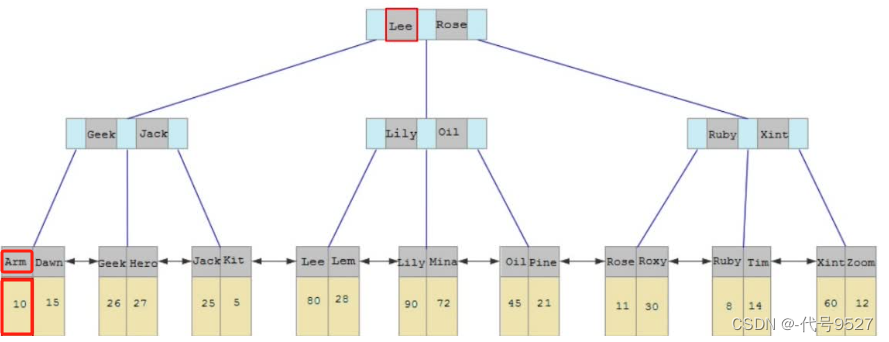
select id, name, gender from tb_user where name = 'Arm';
不是覆盖索引,索引中拿不到gender值,需要回表查询
很明显,能一次查询出来的,符合覆盖索引的,效率最高,走回表查询的SQL,效率低
5.2 超大分页处理
使用limit分页查,需要对数据进行排序,数据量很大时,效率很低
比如,limit 900 0000,10,此时,需要排序前9000010行数据,再返回9000000到9000010行这10行:

解决方案是:覆盖索引 + 子查询

即先根据主键去分页order by id ,不select *,而是select id,再和原来的表关联查
6、索引的创建
需要创建索引的场景:
- 数据量大(单表超过10万行),且查询频繁
- 给常作为
where、order by、group by操作的字段创建索引 - 如果字段是字符串类型,且长度很长,给其建立索引压力大,可截取前几个字,建立前缀索引

- 多用联合索引,而不是单列索引。因为如果给A + B两个字段建立了联合索引,刚好又select A, B from table where A = 1;就是覆盖索引,避免了回表,查询效率更高。下图即给name、status、address三个字段建了联合索引

- 索引并不是越多越好,因为增删改也要同步去维护索引,索引多了,会影响增删改的效率
7、索引的失效
给表tb_seller的name,status,address字段创建联合索引:

索引失效的场景:
1)违反最左前缀法则
最左前缀法则,即select后面的字段,必须从索引的最左前列开始,并且不跳过索引中的列。以下为索引不失效的写法:

以下写法索引失效:

以下写法,中途跳过了联合索引的某一列,只有最左侧字段索引生效,从key_len的大小可以看出,其只命中了一个字段:

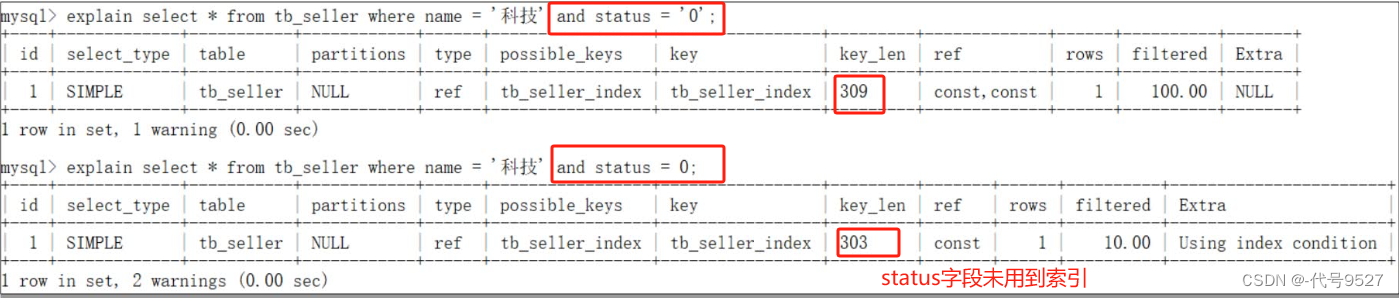
2)对status范围查询,则status右边的列address没有用到索引,但name,status还是走了索引了

3)在索引所在的列上进行运算,索引会失效
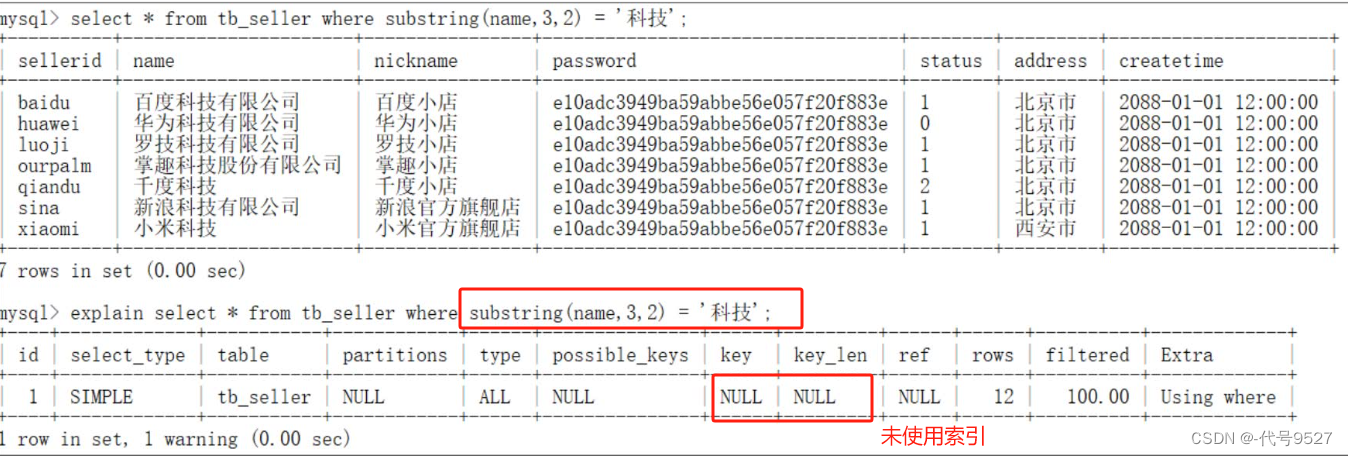
4)字符串不加单引号,索引失效
因为不对字符串类型加单引号,MySQL优化器会自动进行类型转换,造成索引失效
5)以%开头的Like模糊查询,索引失效
注意:如果仅仅是末尾进行模糊查询,索引不会失效

8、SQL优化的经验
1)表设计优化:
- 设置合适的数值类型:tinyint、int、bigint
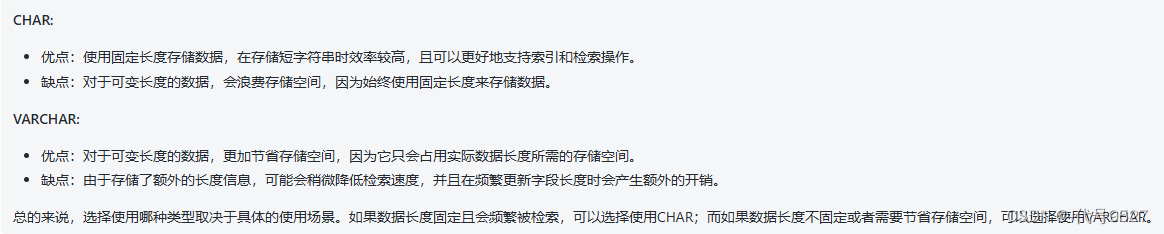
- 字符串类型,char和varchar,char定长、效率高,varchar长度灵活可变,根据字符串实际长度来,但效率稍低
2)SQL语句优化
- 避免select *
- 避免索引失效的写法
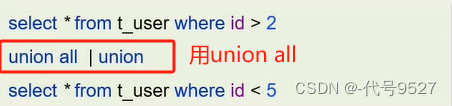
- 使用union all代替union,union会把两个查询的结果再做个去重
- 避免where中对字段进行计算操作
- join表时,能用inner join,不left join或者right join,业务必须要用时,可将小表(行数少的表)放外面。原因参考for循环嵌套,如下写法,MySQL进行三次连接,每次连接进行1000次操作,反之就是进行1000次连接,每次连接进行3次操作(inner join 就会自动优化,把小表放外面。left join或right join就不会把小表放外面)

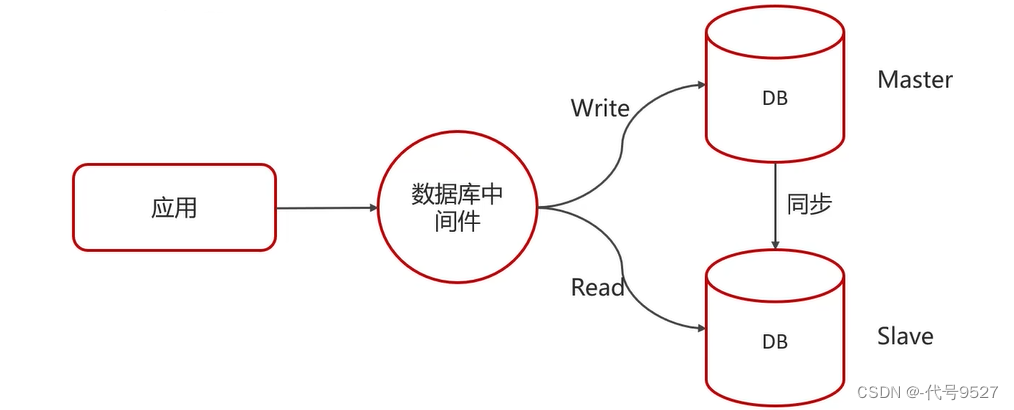
3)读写分离,主从复制
- 用于避免写操作影响查询效率
- 主库写,从库读
4)索引的创建和失效
5)分库分表(见下篇)
9、面试