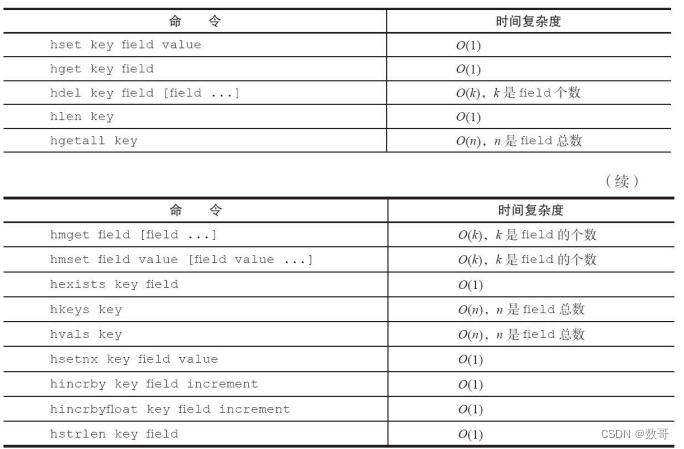
引入部分:通常我们在IDEA中写spark代码中如果设置了loacl参数,基本都是在IDEA本地运行,不会提交到 standalone或yarn上运行,在前几篇文章中写的大多数都是该种形式的spark代码,但也写到了如何将spark代码提交到standalone或yarn上运行,但是提交的代码都是spark-core形式的代码,今天我们谈一谈使用Spark Sql写代码的几种方式,并在yarn上执行。
一、IDEA里面将代码编写好打包上传并提交打到yarn上运行
提交命令:
spark-submit --master yarn --deploy-mode client/cluster --class 主类名 --conf spark.sql.shuffle.partitions=1 jar包名
注意:--conf spark.sql.shuffle.partitions=1该参数为指定分区数
参数的优先级(从高到低):代码的参数 > 命令行设置的参数 > 配置文件设置的参数
这种方式在前面文章中写过,在此不再赘述,文章链接:http://t.csdnimg.cn/gN6tj
二、Spark Shell(repl)
repl:read-eval-print loop
简介:类似于写python代码的jupyter notebook,spark shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序。spark-shell的本质是在后台调用了spark-submit脚本来启动应用程序的,启动命令为
spark-shell --master xxx
注意:
--master用来设置context将要连接并使用的资源主节点,master的值是standalone模式中spark的集群地址、或yarn、或mesos集群的URL,或是一个local地址
例如指定本地核数为2:spark-shell --master local[2]
如果需要指定jar包路径,也可以在后面加参数 --jars jar包路径
回归正题,我们现在使用以下命令与yarn交互:
spark-shell --master yarn --deploy-mode client
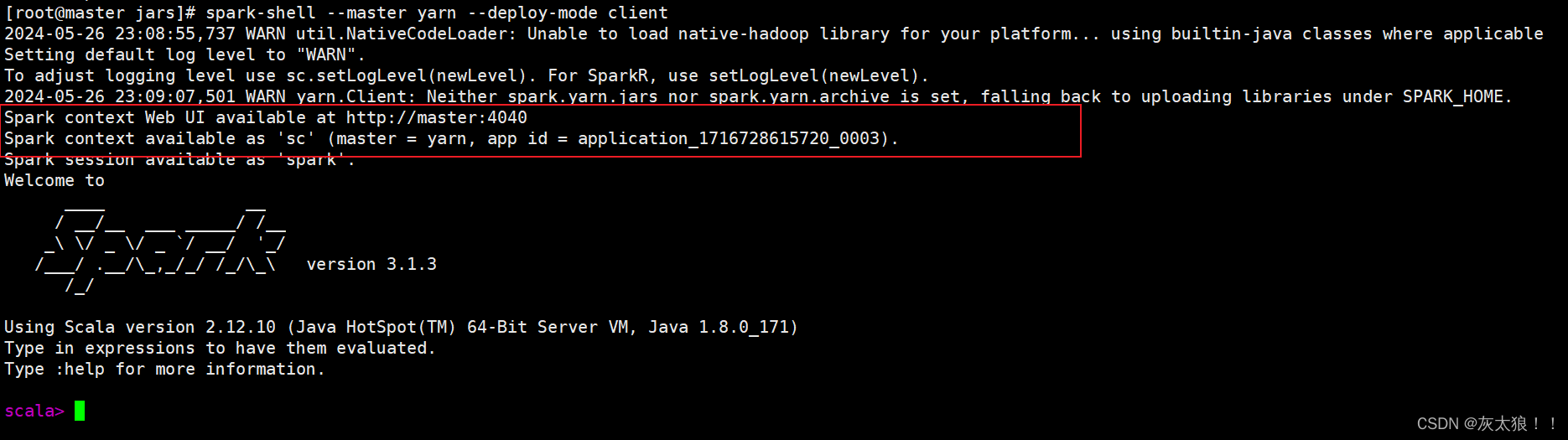
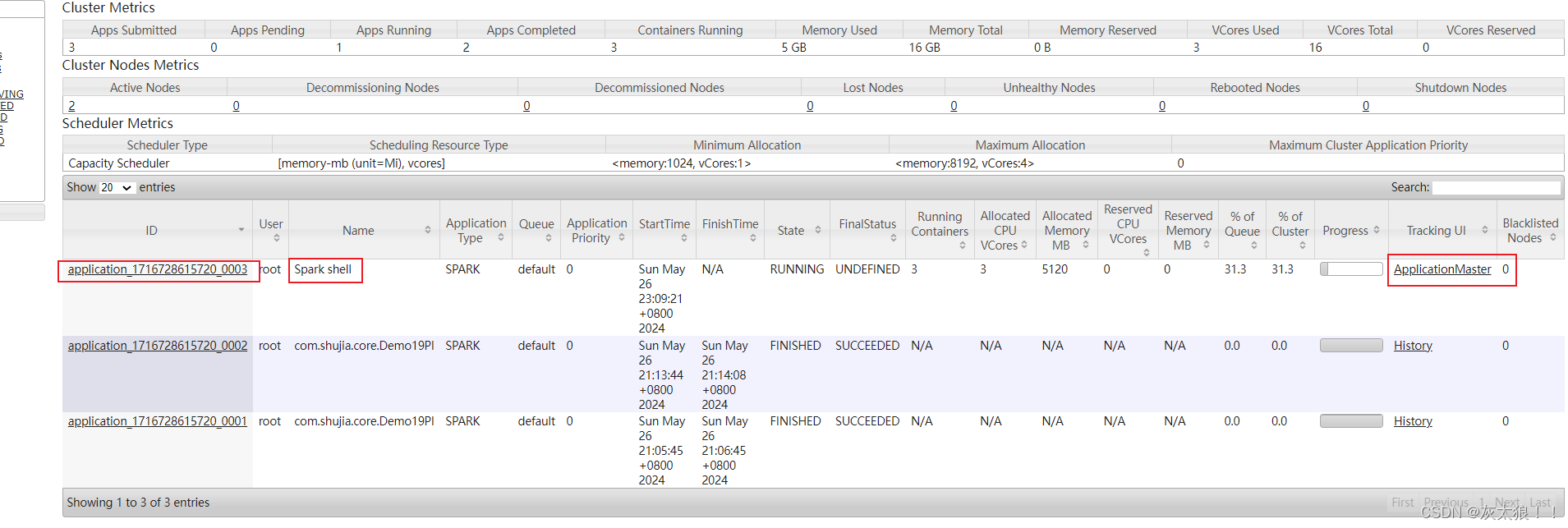
可以看到yarn已经开了一个任务供使用,可以在yarn上查看
此时我们就可以在spark shell中写代码了
注意:
1、spark-shell中可以写scala, python(启动pyspark服务),spark-core,spark sql,spark streaming等形式的代码
2、spark-shell不支持yarn-cluster,如果我们的启动命令是spark-shell --master yarn --deploy-mode cluster,那么会报错,spark-shell启动不了
三、Spark SQL 命令行界面(CLI)
简介:Spark SQL 命令行界面(CLI)是一个交互式工具,允许用户直接通过 SQL 语句来查询和分析存储在 Spark 集群中的数据。它提供了一个方便的方式来查询各种数据源,如 Hive、Parquet、JSON、CSV 等,并返回结果给用户。当启动 Spark SQL CLI 时,它会连接到 Spark 集群,并为你提供一个类似于传统 SQL 数据库管理系统的命令行界面。在这个界面中,你可以输入 SQL 语句,然后 Spark SQL 会将这些语句转换为 Spark 作业,在集群上执行,并将结果返回。
启动命令:
spark-sql --master yarn --deploy-mode client
注意:与Spark Shell中类似,spark-sql --master yarn --deploy-mode cluster 命令是不能启动一个交互式的 Spark SQL 命令行界面(CLI)。
使用流程:
1、首先在linux环境中创建一个文件夹
mkdir spark-sql-master
2、进入该文件夹中并启动CLI
spark-sql --master yarn --deploy-mode client

在此界面我们可以只能写纯sql语法,就像使用传统的SQL 数据库一样。
现在进入spark-sql-master文件夹下,发现多出了一些文件,这些文件存储的就是刚刚在命令行创建数据库、数据表的信息数据,元数据信息,以及日志信息。如果我们将此文件夹删除,那么在就意味着创建的数据库、数据表等信息也将不存在。

这种启动方式的数据库是以文件的形式存储在本地的,但观察启动时的日志发现,其实默认应该是在hive中的,只是我们没有指定,所以就在本地存储了。
现在,我们开始使用spark sql去整合hive,hive底层默认是使用MapReduce框架进行计算的,因此速度很慢,现在使用spark框架结合hive,能使速度大大提升。
四、spark sql整合hive
1、vim hive-site.xml
在hive的hive-site.xml修改以下配置,增加了这一行配置之后,以后在使用hive之前都需要先启动元数据服务。其实这个配置我们在hive启动beline模式时就已经配置过,否则beline模式是开启不了的。
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2、将hive-site.xml 复制到spark conf目录下
使spark jars共用hive的元数据信息
cp /usr/local/soft/hive-3.1.2/conf/hive-site.xml /usr/local/soft/spark-3.1.3/conf/
3、将mysql 驱动包复制到spark jars目录下
cp /usr/local/soft/hive-3.1.2/lib/mysql-connector-java-8.0.29.jar /usr/local/soft/spark-3.1.3/jars/
4、整合好之后在spark-sql里面就可以使用hive的表了
4.1启动hive元数据服务与hiveserver2服务
nohup hive --service metastore &
nohup hiveserver2 &
4.2 进入Spark SQL 命令行界面
spark-sql --master yarn --deploy-mode client
如果测试的资源不够,也可以指定参数进入:
spark-sql --master yarn --deploy-mode client --conf spark.sql.shuffer.partitions=1 --executor-memory 512m --total-executor-cores 1
此时,我们查询的数据库或表就是hive中的了:

4.3 spark sql 与 hive sql 查询速度对比
执行以下sql语句,对比查询速度:
SELECT clazz, COUNT(1) AS stu_num FROM datax_students GROUP BY clazz ORDER BY stu_num DESC;
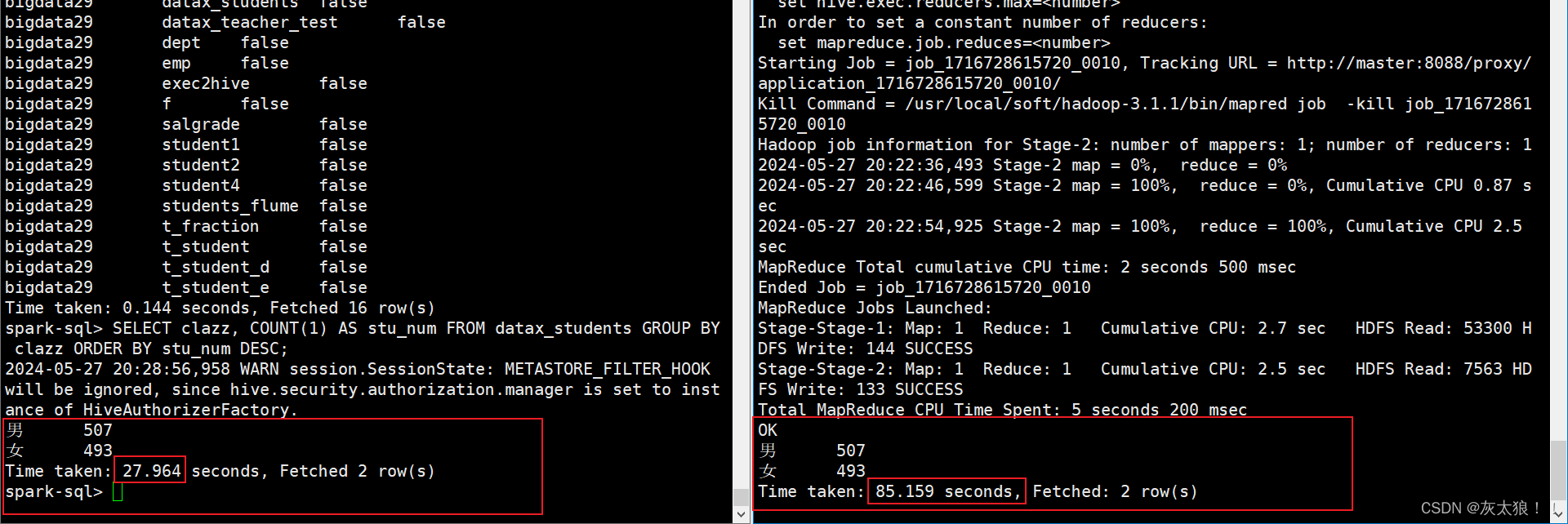
经过测试使用spark差不多速度比hive要快10倍左右(spark官网写的是100倍 ^_^)
五、在IDEA使用代码操作spark整合的hive
1、添加以下依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
</dependency><dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency><dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</dependency><dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.0</version>
<dependency>
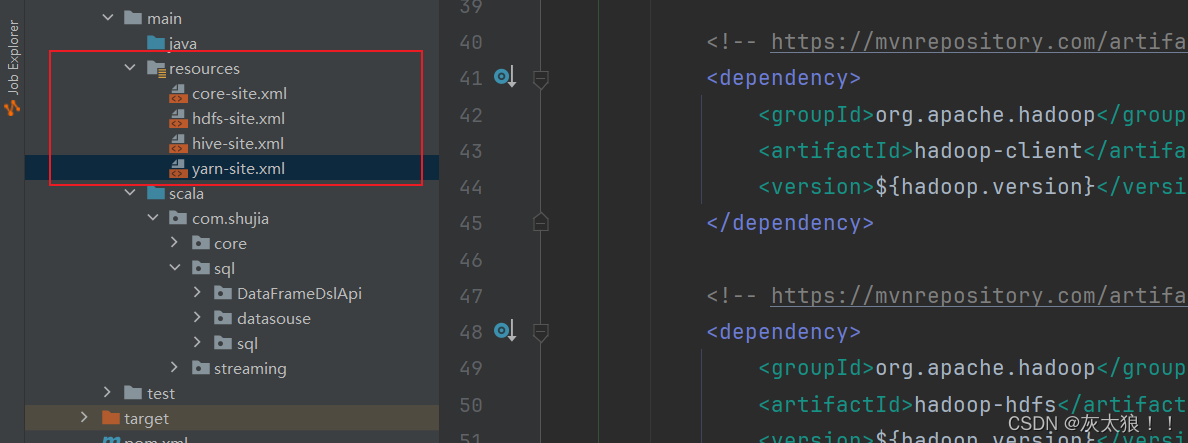
2、将以下四个配置文件加入到资源文件夹下
hive中的hive-site.xml和hadoop中的其他三个文件
3、编写代码测试
import org.apache.spark.sql.SparkSession
object SparkSqLOnHive {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("spark读取hive数据")
.enableHiveSupport()
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import sparkSession.implicits._
import org.apache.spark.sql.functions._
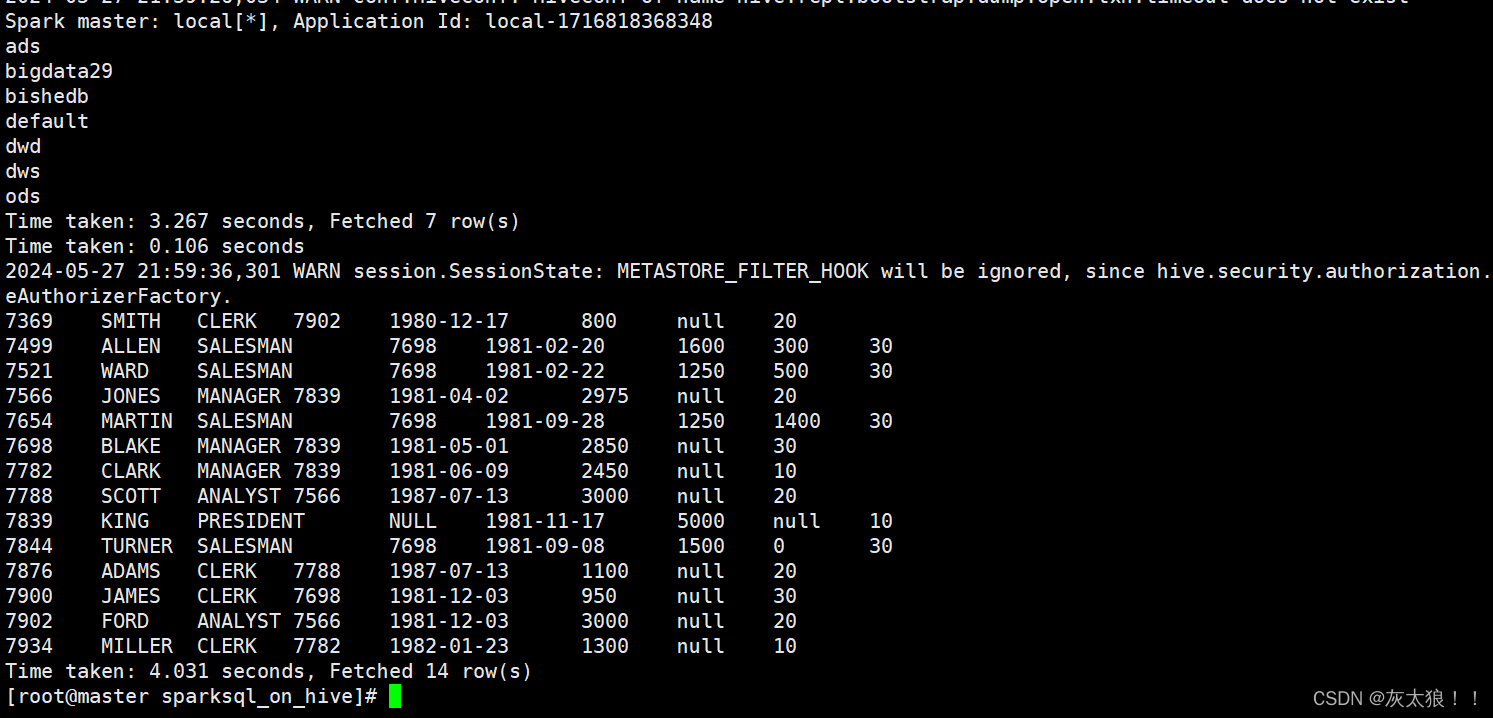
sparkSession.sql("show databases")
sparkSession.sql("select * from bigdata29.emp").show()
}
}结果: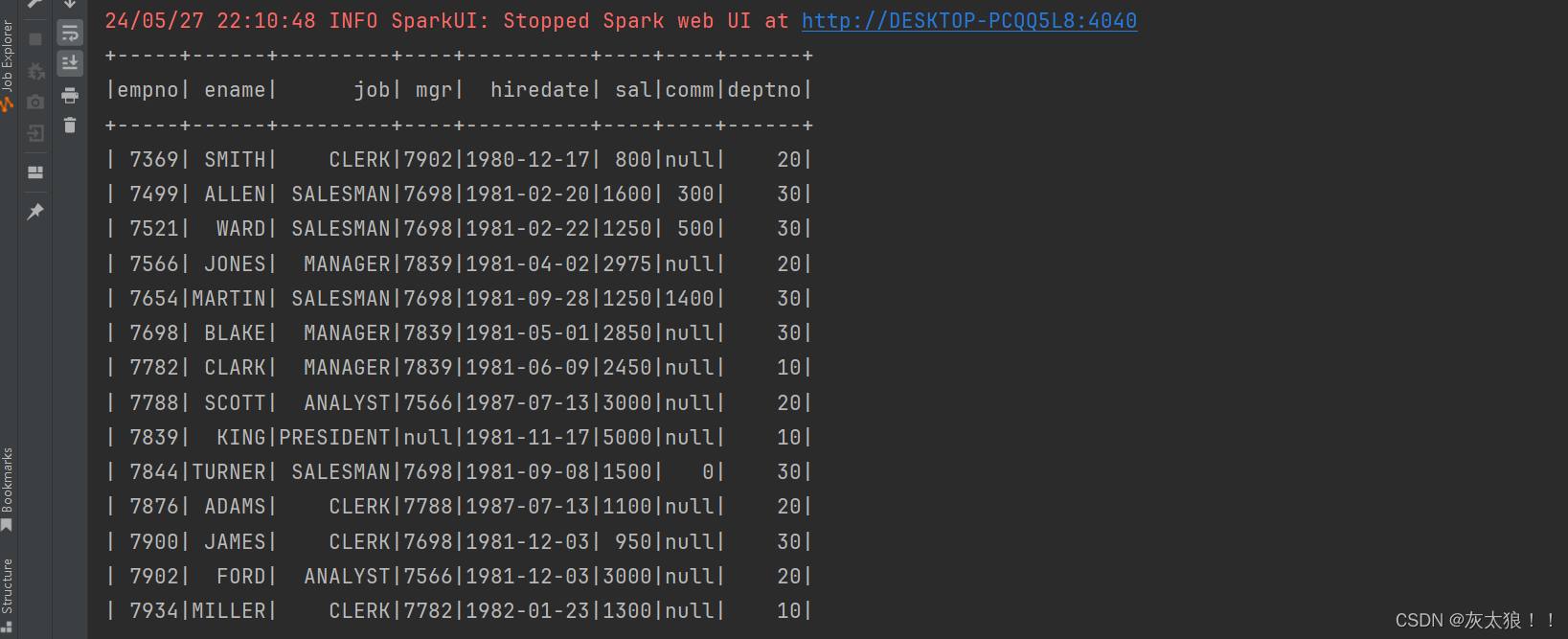
六、在linux命令行写spark-sql
1、方式一:spark-sql -e
-- 执行一条sql语句,执行完,自动退出
spark-sql -e "select * from bigdata29.emp"

2、方式二:spark-sql -f
2.1 创建比编写sql脚本文件
vim test.sql
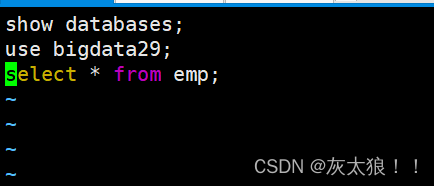
2.2 命令行执行该文件
spark-sql -f test.sql