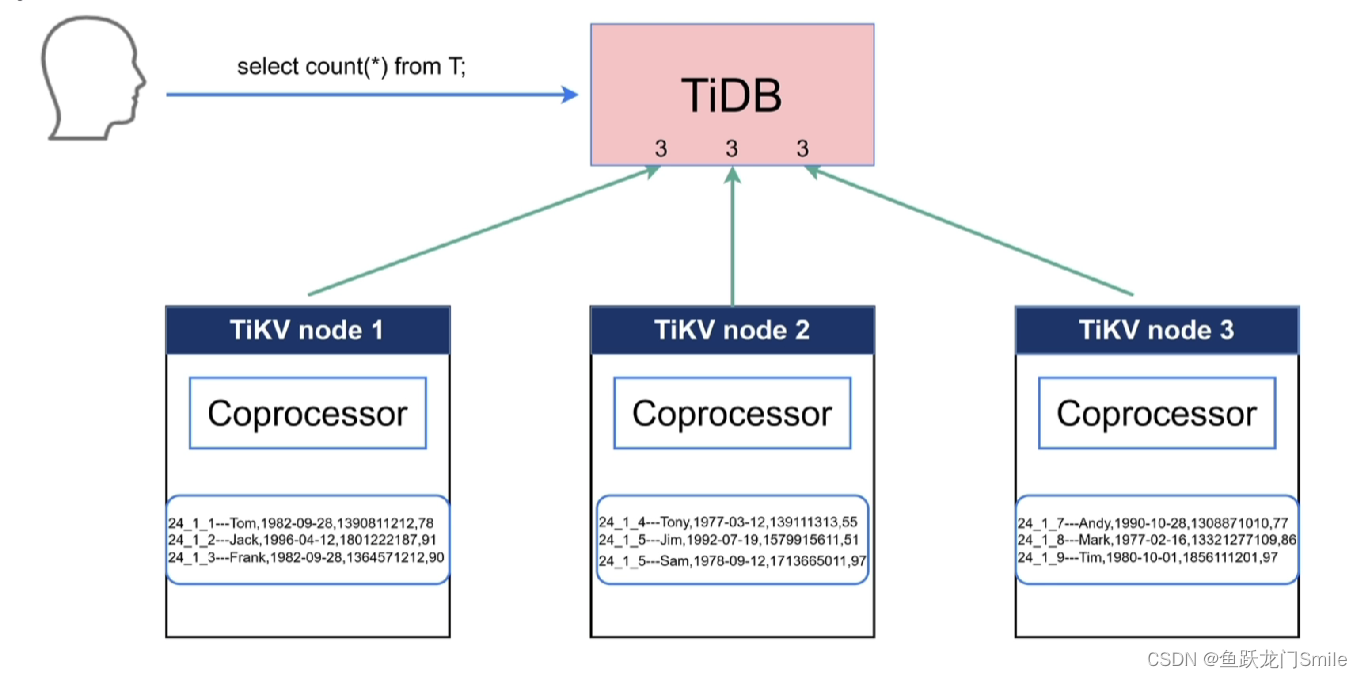
本文将探讨大语言模型(LLMs)与网络抓取的集成,以及如何利用LLMs高效地将复杂的HTML转换为结构化的JSON。
作为一名数据工程师,我的职业生涯可以追溯到2016年。那时,我的主要职责是利用自动化工具从不同网站上获取海量数据,这个过程被称为“网络抓取”。网络抓取通常是从网站的HTML代码中提取所需数据。
在构建相关应用程序时,我不得不深入研究HTML代码,努力寻找最佳的抓取解决方案。我所面临的主要挑战之一是应对网站的频繁变化:例如,我所抓取的亚马逊页面每一到两周就会发生结构上的变化。
当我开始阅读有关大语言模型(LLMs)的文献,我突然意识到:能否利用LLMs来规避我之前在网页结构化数据方面所遇到的种种问题?让我们探讨一下,看看是否能够实现这一目标。
网络抓取工具和技术
在网络抓取领域,工具和技术的选择至关重要,当时,我主要使用的工具包括Requests、BeautifulSoup和Selenium。每种工具都有不同的用途,各自针对不同类型的网络环境。
- Requests 是一个基于Python的HTTP库,旨在简化HTTP请求的发送和响应的接收,通常被用于获取可由BeautifulSoup解析的HTML内容。
- BeautifulSoup 则是一款基于Python的HTML/XML解析库,它能够构建解析树,方便开发者访问页面中的各种元素。通常情况下,BeautifulSoup会与其他库(如Requests或Selenium)结合使用,对从这些库获取的HTML源代码进行解析。
- Selenium 主要应用于包含大量JavaScript的网站。与BeautifulSoup不同的是,Selenium除了能分析HTML代码外,还能通过模拟用户操作(如点击和滚动)与网站进行交互。这有助于从动态网站中获取数据。
在网络抓取过程中,这三种工具是必不可少的利器。然而,它们也带来了一定的挑战:由于网站布局和结构的变化,开发者不得不定期更新代码、标签和元素,这无疑增加了长期维护的复杂性。
什么是大语言模型(LLMs)?
大语言模型(LLMs)被视为下一代计算机程序,它们可以通过阅读和分析海量文本数据进行学习。在当今时代,LLMs具备了以人类般的叙述方式进行写作的惊人能力,使其成为处理语言和理解人类语言的高效工具。这种出色的能力在需要深入把握文本上下文的场景中表现尤为突出。
将LLMs集成入网络抓取
在网络抓取实施过程中,LLMs可以带来极大优化。我们只需将网页的HTML代码输入到LLM中,LLM即可提取出其中所涉及的对象。因此,这种策略有助于简化维护,原因在于即使标记结构发生了变化,内容本身通常也会固定不变。
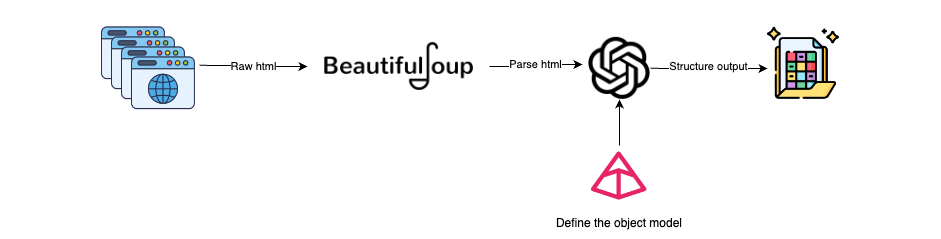
将大语言模型(LLMs)集成入网络抓取的工作流程大致如下:
获取HTML:使用Selenium或Requests等工具获取网页的HTML内容。其中,Selenium适用于处理包含JavaScript的动态页面内容,而Requests则更适合静态页面。
解析HTML:使用BeautifulSoup,我们可以将HTML解析为文本,从而去除HTML中的噪音数据(页脚、页眉等)。
创建Pydantic模型:定义需抓取数据对象的Pydantic模型。这一步确保了待抓取数据的类型和结构符合预定义的模式。
为LLMs生成提示:设计一个提示语,明确告知LLM应该提取哪些信息。
LLM处理:使用LLM模型读取HTML内容,理解其语义,并根据数据处理和结构化的指令进行操作。
结构化数据的输出:LLM将以Pydantic模型定义的结构化对象形式提供输出。
上述工作流程有助于利用LLMs将HTML(非结构化数据)转化为结构化数据,从而解决了网页源HTML设计不规范或动态修改所带来的问题。
LangChain与BeautifulSoup和Pydantic的集成
以下是我们选择的静态网页示例,目标是从中抓取所有列出的活动,并以结构化的方式呈现。
这种方法首先从静态网页中提取原始HTML,并在LLM处理之前对其进行清理。
from bs4 import BeautifulSoup
import requests
def extract_html_from_url(url):
try:
# Fetch HTML content from the URL using requests
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad responses (4xx and 5xx)
# Parse HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
excluded_tagNames = ["footer", "nav"]
# Exclude elements with tag names 'footer' and 'nav'
for tag_name in excluded_tagNames:
for unwanted_tag in soup.find_all(tag_name):
unwanted_tag.extract()
# Process the soup to maintain hrefs in anchor tags
for a_tag in soup.find_all("a"):
href = a_tag.get("href")
if href:
a_tag.string = f"{a_tag.get_text()} ({href})"
return ' '.join(soup.stripped_strings) # Return text content with preserved hrefs
except requests.exceptions.RequestException as e:
print(f"Error fetching data from {url}: {e}")
return None当我们从网页中进行数据抓取时,下一步是定义需要从网页中抓取的 Pydantic 对象。我们需要创建两个对象:
Activity:这是一个 Pydantic 对象,用于表示与活动相关的所有元数据,其中指定了属性和数据类型。我们已将某些字段标记为可选,以防它们在所有活动中均不可用。为属性提供描述、示例和任何元数据将有助于更好地定义。
ActivityScraper:这是基于 Activity 的 Pydantic 封装。该对象的目的是确保 LLM 理解需要从多个活动中抓取数据。
from pydantic import BaseModel, Field
from typing import Optional
class Activity(BaseModel):
title: str = Field(description="The title of the activity.")
rating: float = Field(description="The average user rating out of 10.")
reviews_count: int = Field(description="The total number of reviews received.")
travelers_count: Optional[int] = Field(description="The number of travelers who have participated.")
cancellation_policy: Optional[str] = Field(description="The cancellation policy for the activity.")
description: str = Field(description="A detailed description of what the activity entails.")
duration: str = Field(description="The duration of the activity, usually given in hours or days.")
language: Optional[str] = Field(description="The primary language in which the activity is conducted.")
category: str = Field(description="The category of the activity, such as 'Boat Trip', 'City Tours', etc.")
price: float = Field(description="The price of the activity.")
currency: str = Field(description="The currency in which the price is denominated, such as USD, EUR, GBP, etc.")
class ActivityScrapper(BaseModel):
Activities: list[Activity] = Field("List of all the activities listed in the text")最后,我们来看一下 LLM 的配置。我们将使用 LangChain 库,该库提供了一个出色的工具包,可帮助您入门。
其中一个关键组件是 PydanticOutputParser。它将把我们的对象转换为指令(如提示中所示),并解析 LLM 的输出,以获取相应的对象列表。
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(temperature=0)
output_parser = PydanticOutputParser(pydantic_object = ActivityScrapper)
prompt_template = """
You are an expert making web scrapping and analyzing HTML raw code.
If there is no explicit information don't make any assumption.
Extract all objects that matched the instructions from the following html
{html_text}
Provide them in a list, also if there is a next page link remember to add it to the object.
Please, follow carefulling the following instructions
{format_instructions}
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["html_text"],
partial_variables={"format_instructions": output_parser.get_format_instructions}
)
chain = prompt | llm | output_parser在这一步中,您需要调用链式模型并检索结果。
url = "https://www.civitatis.com/es/budapest/"
html_text_parsed = extract_html_from_url(url)
activites = chain.invoke(input={
"html_text": html_text_parsed
})
activites.Activities这就是抓取出来的数据,整个网页抓取耗时46 秒。
[Activity(title='Paseo en barco al anochecer', rating=8.4, reviews_count=9439, travelers_count=118389, cancellation_policy='Cancelación gratuita', description='En este crucero disfrutaréis de las mejores vistas de Budapest cuando se viste de gala, al anochecer. El barco es panorámico y tiene partes descubiertas.', duration='1 hora', language='Español', category='Paseos en barco', price=21.0, currency='€'),
Activity(title='Visita guiada por el Parlamento de Budapest', rating=8.8, reviews_count=2647, travelers_count=34872, cancellation_policy='Cancelación gratuita', description='El Parlamento de Budapest es uno de los edificios más bonitos de la capital húngara. Comprobadlo vosotros mismos en este tour en español que incluye la entrada.', duration='2 horas', language='Español', category='Visitas guiadas y free tours', price=27.0, currency='€')
...
]演示和完整代码库
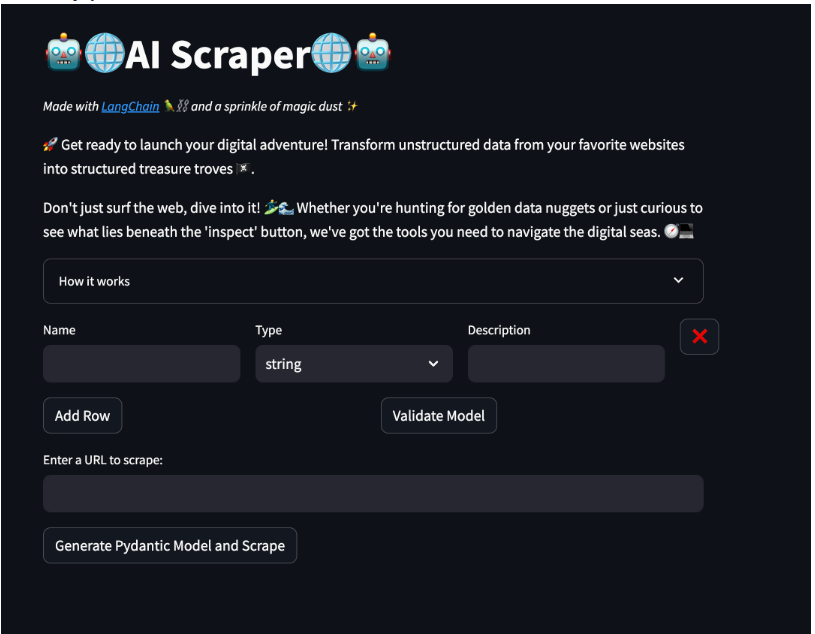
我创建了一个使用Streamlit的快速演示,可以在此处访问。
在这个演示中,您将了解有关模型的详细信息。您可以根据需要添加多行文本,并为每个属性指定名称、类型和描述。这将自动生成一个Pydantic模型,用于在网页抓取组件中使用。
接下来的部分允许您输入一个URL地址,并通过点击网页上的按钮来抓取所有数据。当抓取完成后,会出现一个下载按钮,允许您以JSON格式下载数据。
请随意尝试!
结论
当处理非结构化数据时,LLM确实为从非结构化数据(如网站、PDF等)中高效提取数据提供了新的可能性。自动化网络抓取不仅可以节省时间,还可以确保检索到的数据质量。
然而,将原始HTML发送给LLM可能会增加令牌成本并降低效率。这是因为HTML通常包含各种标签、属性和内容,导致成本迅速上升。
因此,在使用LLM作为网络数据提取器时,预处理和清理HTML是关键的一步。我们应该删除所有不必要的元数据和非实际使用的信息,以保持合理的成本。
总之,选择正确的工具对于正确的工作至关重要!