文章目录
- 1 决策树模型
- 1.1 决策树模型简介
- 1.2 决策树模型核心问题
- 1.2.1 分类划分标准
- 1.2.1.1 信息增益
- 1.2.1.2 增益率
- 1.2.1.3 基尼系数
- 1.2.2 停止生长策略
- 1.2.3 剪枝策略
- 1.3 决策树 - python代码
- 1.3.1 结果解读
- 1.3.2 决策树可视化
- 1.3.3 CV - 留一法
- 2 集成学习
- 2.1 Boosting
- 2.1.1 AdaBoost
- 2.2 AdaBoost - python代码
- 2.3 Bagging
- 3 随机森林
- 3.1 GBDT
- 3.2 XGboost
- 3.3 XGBoost - python 代码
1 决策树模型
1.1 决策树模型简介
决策树模型本质上一类有监督学习模型,与传统统计学模式背景下的一般线性模型、广义线性模型甚至是判别分析不同,决策树在工作过程中通过一系列推理规则从根结点出发生成一棵二叉或者是多叉树,这棵树最后的叶子结点将会对应最终的各个分类项、或是回归值。
从决策树的工作模式出发,我们不难看出他不受到传统统计学分类模型中对数据分布的强要求;与此同时,树生成过程中的每一次分叉实际上都是在样本的多维属性空间中划分出一个超平面,特别的,该超平面一定是垂直于该层推理规则所涉及属性的系列坐标轴(二元假设推断或多元假设推断)或与该系列坐标轴呈一定夹角(线性划分标准),因此决策树的分类平面将会是多个超平面的叠加组合,这也从一定程度上超越了线性分类器的分类性能,使其能够解决诸如异或不可分的难题而不用使用降维或者是核函数等数学变换手段
决策树在树生成过程中,每一个中间节点内的数据量是不断减少的,而根节点将会包含全部数据;中间节点中的数据实质上是符合从根结点到该中间节点路径上所有推理|判别规则的集合,即便他们的标签可能不是同质的。
与诸多机器学习模型一样,决策树模型能够解决分类和回归的问题。在解决分类问题时,叶子节点的预测值是该叶子节点中所有数据标签的众数,预测的置信度即为节点中众数标签数据所占全部数据的百分比;在解决回归问题时,叶子节点的预测值是该叶子节点中所有数据输出变量的平均数
1.2 决策树模型核心问题
当我们尝试生成一棵决策树时,我们需要思考两个关键流程
- 决策树的生长 - 分类划分标准以及停止生长策略
- 决策树的剪枝 - 防止过拟合的发生
1.2.1 分类划分标准
1.2.1.1 信息增益
能够让计算机读懂的划分标准一定是一个能够进行比较的数值,因此我们在设计划分标准时需要将属于决策树中上一层的数据集根据其聚集特征产出一系列能够进行比较的数值,通过比较后寻找最优值对应的划分标准
由于我们的任务是寻找能够在最大程度上区分数据集的判断标准,因此我们不妨分属性进行寻找。根据信息论的观点,每个属性将向决策树上一层的数据集中引入新的信息量(模型中可以理解为条件概率),因此我们可以通过计算引入这个属性的分类信息后产生的互信息来衡量该属性对于减少上一层数据集信息熵的有效程度.某个属性引入后产生的互信息越大,说明引入该属性的信息后原数据集的数据熵越小,数据更趋于分类有序,这便意味着该属性将数据集分类的效果就越好
首先,我们引入互信息的概念
互信息的计算公式为:
I
(
X
;
Y
)
=
E
(
X
)
−
E
(
X
∣
Y
)
=
∑
p
(
x
)
l
o
g
p
(
x
)
−
∑
∑
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
p
(
y
)
\begin{array}{ll} I(X;Y) & = & E(X) - E(X|Y) \\ & = & \sum p(x)log p(x) - \sum\sum p(x,y)log \frac{p(x,y)}{p(x)p(y)} \end{array}
I(X;Y)==E(X)−E(X∣Y)∑p(x)logp(x)−∑∑p(x,y)logp(x)p(y)p(x,y)
其中
E
(
X
)
E(X)
E(X)代表随机变量
X
X
X的信息熵,
I
(
X
;
Y
)
I(X;Y)
I(X;Y)表示引入随机变量
Y
Y
Y后
X
X
X的信息增益
依据互信息计算公式,我们能够定义信息增益:
G
a
i
n
(
D
,
a
)
=
E
(
D
)
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
(
D
v
)
Gain(D,a) = E(D) - \displaystyle{\sum_{v=1}^{V}\frac{|D^v|}{|D|}E(D^v)}
Gain(D,a)=E(D)−v=1∑V∣D∣∣Dv∣E(Dv)
在公式中,
D
D
D表示决策树上一层数据集,
∣
D
∣
|D|
∣D∣即为该数据集中样本数量,我们采用属性
a
a
a对该数据集进行划分,
已知属性
a
a
a有
V
V
V个可能的取值
{
a
1
,
a
2
,
⋯
,
a
V
}
\{a^1,a^2,\cdots,a^V\}
{a1,a2,⋯,aV},在决策树中,每一个可能的取值将会对应该层的一个中间节点,
因此每一个分类取值
a
v
a^v
av下的样本集将被定义为
D
v
D^v
Dv,该样本集所含样本总数量即为
∣
D
v
∣
|D^v|
∣Dv∣
公式中
∣
D
v
∣
∣
D
∣
\frac{|D^v|}{|D|}
∣D∣∣Dv∣对应互信息中的
p
(
x
,
y
)
p(x,y)
p(x,y)项,
E
(
D
v
)
E(D^v)
E(Dv)对应互信息中
∑
p
(
x
,
y
)
p
(
x
)
p
(
y
)
\sum\frac{p(x,y)}{p(x)p(y)}
∑p(x)p(y)p(x,y)项
在实际操作中,以上信息增益公式将会更好理解:
∣
D
v
∣
∣
D
∣
\frac{|D^v|}{|D|}
∣D∣∣Dv∣代表属性
a
a
a的
a
v
a^v
av分类下样本数量占全部样本数量的比值;
E
(
D
v
)
E(D^v)
E(Dv)的计算对应
∑
p
(
x
,
y
)
p
(
x
)
p
(
y
)
\sum\frac{p(x,y)}{p(x)p(y)}
∑p(x)p(y)p(x,y)项的计算,实际上就是在
a
v
a^v
av分类下的数据集中不同标签的二项分布或V项分布的信息熵
1.2.1.2 增益率
通过计算公式我们可以发现,信息增益更倾向于选择分类较多的属性,因此为了能够避免在此表现上出现过拟合的现象,我们引入信息增益率
信息增益率是一个双因子变量,其分母的作用即为抵消由于某一属性分类类别过多而造成数值过大的影响:
G
a
i
n
_
r
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
l
o
g
2
∣
D
v
∣
∣
D
∣
\begin{array}{ll} & Gain\_ratio(D,a) = \displaystyle{\frac{Gain(D,a)}{IV(a)}} \\ & IV(a) = \displaystyle{-\sum_{v=1}^{V}\frac{|D^v|}{|D|}log_2 \frac{|D^v|}{|D|}} \\ \end{array}
Gain_ratio(D,a)=IV(a)Gain(D,a)IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
I
V
(
a
)
IV(a)
IV(a)的计算类似于熵的计算,当一个属性类别过多时,该值会变大
对待信息增益和信息增益率,我们的最优化问题是一个最大值问题:
a
∗
=
arg
max
a
∈
A
G
a
i
n
(
D
,
a
)
a_* = \mathop{\arg \max}\limits_{a \in A} Gain(D,a)
a∗=a∈AargmaxGain(D,a)
1.2.1.3 基尼系数
由于信息熵的计算过于繁琐,在一般机器学习算法中,默认的分类指标是基尼系数
基尼系数从每个属性的不同类别整体出发,对不同类别中数据量占整体数量的百分比进行相乘运算。如果该属性划分数据集后每个类别内部数据纯净,那么基尼系数将为0;因此,基尼系数越小,数据集纯度越高
基尼值的定义如下:
G
i
n
i
(
D
)
=
∑
k
=
1
∣
V
∣
∑
k
′
≠
k
p
k
p
k
′
=
1
−
∑
k
=
1
∣
V
∣
p
k
2
\begin{array}{ll} Gini(D) & = & \displaystyle{\sum_{k=1}^{|V|}\sum_{k^\prime \ne k}p_k{p_k}^\prime} \\ & = & 1- \displaystyle{\sum_{k=1}^{|V|}{p_k}^2} \\ \end{array}
Gini(D)==k=1∑∣V∣k′=k∑pkpk′1−k=1∑∣V∣pk2
其中,
∣
V
∣
|V|
∣V∣代表某个属性下所有分类的数量,我们计算的是
p
k
=
∣
D
v
∣
∣
D
∣
p_k = \frac{|D^v|}{|D|}
pk=∣D∣∣Dv∣
因此,我们可以定义基尼系数:
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
Gini\_index(D,a) = \displaystyle{\sum_{v=1}^{V} \frac{|D^v|}{|D|} Gini(D^v)}
Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
对待基尼系数,我们的最优化问题是一个最小值问题:
a
∗
=
arg
min
a
∈
A
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
a_* = \mathop{\arg \min}\limits_{a \in A} Gini\_index(D,a)
a∗=a∈AargminGini_index(D,a)
1.2.2 停止生长策略
由于编程过程中我们能够确定决策树的生长是一个递归的过程,因此算法中的三个流程将会导致递归返回:
- 当前节点包含所有样本属于同一个类别
- 当前的属性集为空
- 当前节点包含的样本集合为空
1.2.3 剪枝策略
决策树的剪枝包括两种不同的策略,分别是预剪枝和后剪枝
- 预剪枝过程发生在决策树生成的过程之中,这也是我们在调用决策树算法时需要定义的超参数;
- 后剪枝过程发生在决策树生成之后,我们从叶子节点出发,合并判断误差高于设定值的叶子节点,提升模型的泛化能力
1.3 决策树 - python代码
python sklearn.tree DecisionTreeClassifier 包含决策树模型
在这里我们需要介绍几个关键的超参数,这些超参数无一例外都是剪枝策略相关的参数
criterioin - 分类决策函数类型,默认是 Gini index
max_depth - 控制决策树的深度
min_samples_leaf - 控制每个叶子节点中样本的数量
import numpy as np
import pandas as pd
import warnings
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
warnings.filterwarnings("ignore")
iris_X, iris_y = load_iris(return_X_y=True)
df_clf = DecisionTreeClassifier(random_state=42,max_depth=5,min_samples_leaf=0.1)
x_train, x_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.2,random_state=42)
df_clf.fit(x_train, y_train)
y_pred = df_clf.predict(x_test)
print("test acc:{}".format(accuracy_score(y_pred,y_test)))
$ test acc:0.9666666666666667
df_clf.feature_importances_
$array([0.00158406, 0., 0.99841594, 0.])
1.3.1 结果解读
以上代码中,我们采用旁置法首先训练了一个决策树分类器,其次使用测试集对分类效果进行测试,结果显示对于测试集的预测准确率在96.67%
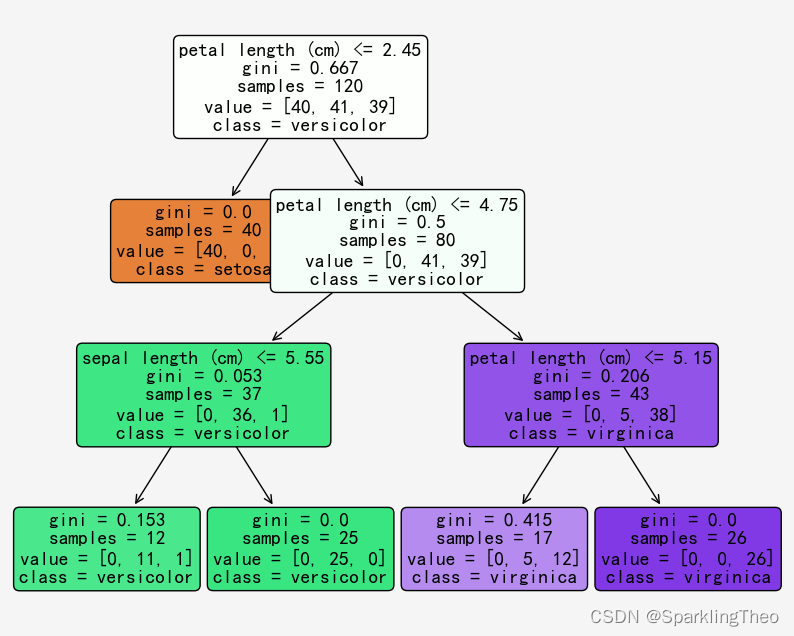
1.3.2 决策树可视化
sklearn同时支持决策树模型的可视化,我们通过tree.plot_tree函数进行可视化操作
import matplotlib as mpl
from matplotlib import pyplot as plt
import sklearn.tree as tree
%matplotlib inline
plt.rcParams["axes.unicode_minus"] = False
plt.rcParams["font.sans-serif"] = "SimHei"
feature_names = load_iris()["feature_names"]
target_names = load_iris()["target_names"]
plt.figure(figsize=(10,8), facecolor= 'whitesmoke')
a = tree.plot_tree(df_clf,
feature_names = feature_names,
class_names= target_names,
rounded=True,
filled= True,
fontsize=14)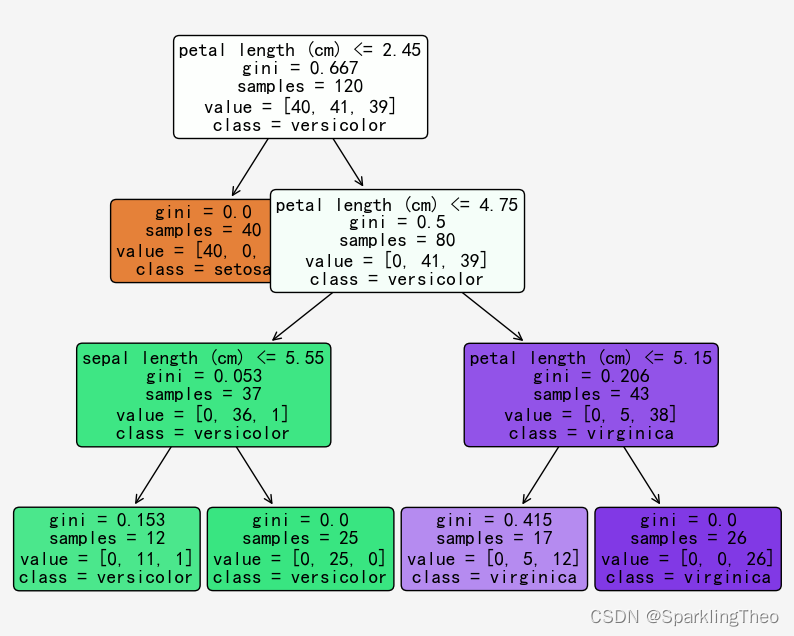
1.3.3 CV - 留一法
对于决策树的训练我们也可以采用留一法,也就是交叉检验的方法CV进行超参数的调参
对于cross_validate函数,我们能够选择的scoring函数可以通过以下指令进行查询:
sorted(sklearn.metrics.SCORERS.keys())
from sklearn.model_selection import cross_validate
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, accuracy_score
# first test decisiontree classifier
dt_clf = DecisionTreeClassifier(random_state=42, max_depth=5, min_samples_leaf=0.1)
cv_clf_score = cross_validate(dt_clf, X=iris_X, y=iris_y, cv=5, scoring=["accuracy"])
cv_clf_score
${'fit_time': array([0.00399494, 0.00113511, 0.00104785, 0.00084186, 0.0013411 ]),
$ 'score_time': array([0.00071907, 0.00030994, 0.0003109 , 0.00051308, 0.00033712]),
$ 'test_accuracy': array([0.93333333, 0.96666667, 0.9 , 0.86666667, 1. ])}
# then test decisiontree regressor
dt_reg = DecisionTreeRegressor(random_state=42, max_depth=5, min_samples_leaf=0.1)
cv_reg_score = cross_val_score(dt_reg,iris_X,iris_y,scoring="neg_mean_squared_error")
-cv_reg_score
$ array([0., 0.01800412, 0.14856771, 0.05398313, 0.17422525])
2 集成学习
集成学习通过构建并结合多个学习器来完成学习任务。简单来说,集成学习首先产生一组个体学习器,然后通过某种策略将这些个体学习器结合起来,最后通过对每一个个体学习器的输出结果进行整合,得出集成学习器的最终输出。
在这里我们需要明确几个概念,如果集成学习器中仅包含一种个体学习器,那么这些个体学习器被称为基学习器,如果是多个不同类型的个体学习器,那么他们被称为组件学习器
通过思考我们可以不加证明的发现,个体学习器既要有一定的准确性,又要有一定的差异性,这样得出的集成学习器才能够有更好的效果
从数学角度而言,集成学习将多个学习器进行结合,其最终构成的集成学习器常常能够获得比单一学习器更优秀的泛化性能,下面我们简单以投票法集成的多个二分类器来证明以上理论。
考虑二分类问题 y ∈ { − 1 , + 1 } y \in \{-1,+1\} y∈{−1,+1}和真实函数 f \mathop{f} f,假定基分类器的错误率为 ϵ \epsilon ϵ,即对于每一个基分类器而言,有
P ( h i ( x ) ≠ f ( x ) ) = ϵ P(h_i(x) \ne \mathop{f}(x)) = \epsilon P(hi(x)=f(x))=ϵ
集成分类器 H \mathop{H} H将以投票法集成T个基分类器,这意味着只要有半数基分类器分类正确,集成分类正确:
H ( x ) = s i g n ( ∑ i = 1 T h i ( x ) ) \mathop{H}(x) = sign(\displaystyle\sum_{i=1}^{T}h_i(x)) H(x)=sign(i=1∑Thi(x))
以上,
s
i
g
n
(
)
sign()
sign()函数是示例函数,它将完成半数投票的工作
假设基分类器的错误率相互独立,则由Hoeffding不等式可知,
P ( h ( x ) ≠ f ( x ) ) = ∑ k = 0 [ T / 2 ] C k T 1 − ϵ k ϵ T − k ≤ e x p ( − 1 2 T ( 1 − 2 ϵ ) 2 ) \begin{array}{ll} P(h(x) \ne \mathop{f}(x)) & = & \displaystyle\sum_{k=0}^{[T/2]}C^{T}_{k}{1-\epsilon}^k\epsilon^{T-k} \\ & \le & exp(-\frac{1}{2}T(1-2\epsilon)^2) \end{array} P(h(x)=f(x))=≤k=0∑[T/2]CkT1−ϵkϵT−kexp(−21T(1−2ϵ)2)
从以上式子我们可以看出,随着基分类器数目 T T T的增大,集成分类器的分类错误率将会呈指数级别下降
2.1 Boosting
boosting的构建策略是:首先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得前一个基学习器分类错误的训练样本在后续的训练过程中拥有更高的加权;接下来基于调整后的样本分布训练下一个基学习器;重复此过程直到基学习器数量达到指定的T值,最终将这T个基学习器的输出加权结合作为集成学习器的输出
2.1.1 AdaBoost
AdaBoost是Boost算法思想最著名的代表
考虑二分类问题
y
∈
{
−
1
,
+
1
}
y \in \{-1,+1\}
y∈{−1,+1}和真实函数
f
\mathop{f}
f,AdaBoost的加性模型数学表达形式如下:
H ( x ) = ∑ i = 1 T α i h i ( x ) H(x) = \displaystyle\sum_{i=1}^{T}{\alpha_ih_i(x)} H(x)=i=1∑Tαihi(x)
训练模型的最优化问题是最小化指数损失函数,但是需要注意,由于boosting算法具有很强的步骤性,因此最小化问题的闭式表达式较难求解
l e x p ( H ∣ D ) = E x ∼ D [ e − f ( x ) H ( x ) ] l_{exp}(H|\mathbb{D}) = \mathbb{E}_{x \sim \mathbb{D}}[e^{-\mathop{f}(x)H(x)}] lexp(H∣D)=Ex∼D[e−f(x)H(x)]
2.2 AdaBoost - python代码
首先,adaboost较少在实际应用中使用,
sklearn.ensemble AdaBoostClassifier集成了AdaBoost算法
该算法中几个超参数需要我们进行调整:
base_estimator - 基学习器
n_estimators - 基学习器数量T
learning_rate - 初始学习器权值
注意,基于算法实现,每一个基学习器都需要满足计算每个分类概率的方法,即需要有proba_属性
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
iris_X, iris_y = load_iris(return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(iris_X,iris_y,test_size=0.2,random_state=42)
base_clf = DecisionTreeClassifier(max_depth=2,min_samples_leaf=0.3,random_state=42)
ada_clf = AdaBoostClassifier(base_estimator=base_clf,n_estimators=50,random_state=42)
ada_clf.fit(x_train,y_train)
y_pred = ada_clf.predict(x_test)
print(accuracy_score(y_pred,y_test))
$ 0.9666666666666667
2.3 Bagging
相比Boosting,Bagging(Boostrap aggregation)在训练过程中使用的数据集将是不同的,这样能够从数据集的角度保证不同基分类器之间的独立性
为了达到不同基分类器的训练数据做到最大程度上的独立,Bagging算法采用自助采样法(bootstrap sampling)对数据集进行采样,简单来说就是从整体样本集中有放回的抽取固定数量的样本集
在基分类器集成的策略上Bagging通常在分类问题上采取简单投票法,在回归问题上采取简单平均法
Bagging算法中应用最为广泛的模型即为决策树模型组合而成的随机森林模型,下面我们将单独重点介绍随机森林模型
3 随机森林
本文采用最简单的方式描述随机森林模型
随机森林可以通过哥基分类器的简单加合作为集成分类器的整体结构,在数学公式中,我们可以简单地将最后模型的预测输出表示为
y ^ = ∑ t = 1 T f t ( x ) \hat y = \displaystyle{\sum_{t=1}^{T}\mathop{f_t}(x)} y^=t=1∑Tft(x)
其中,T如前文一样表示基分类器数量,
f
t
\mathop{f_t}
ft表示第t个基学习器模型
接下来,对于模型在每一次迭代更新时的更新方式便造就了GBDT和XGBoost的不同之处
从相同之处出发,两种随机森林算法都是通过计算上一轮预测值与实际值的残差,并将该残差作为新的数据点进行下一轮基分类器进行拟合,二者最大的不同之处在于对待残差的处理和表示方式
3.1 GBDT
对于GBDT而言,我们采取损失函数的负梯度作为两论模型预测值之间的残差,大致的计算公式可以表示如下:
f
t
(
x
)
=
y
^
t
−
y
^
t
−
1
=
−
η
∂
l
(
y
,
y
^
)
∂
y
^
\mathop{f_t}(x) = \hat y_t - \hat y_{t-1} = - \eta \frac{\partial l(y,\hat y)}{\partial \hat y}
ft(x)=y^t−y^t−1=−η∂y^∂l(y,y^)
其中
η
\eta
η代表学习率,
y
^
t
\hat y_t
y^t代表第t轮标签值,
y
^
t
−
1
\hat y_{t-1}
y^t−1代表第(t-1)轮标签值
3.2 XGboost
在GXGBoost中,我们对损失函数进行二姐泰勒展开,同时将一阶导数和二阶导数作为残差带入下一轮的拟合过程进行学习,简单来说,其损失函数的数学表达式可以表示如下:
L ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f i ( x i ) ) + Ω ( f t ) Ω ( f t ) = γ J + λ 2 ∑ j = 1 J ω t j 2 \begin{array}{ll} L^{(t)} & = & \displaystyle{\sum_{i=1}^{n}l(y_i,{\hat y_i}^{(t-1)}+\mathop{f_i}(x_i))} + \Omega(\mathop{f_t}) \\ \Omega(\mathop{f_t}) & = & \gamma J + \frac{\lambda}{2} \displaystyle{}\sum_{j=1}^{J}{\omega_{tj}}^2 \\ \end{array} L(t)Ω(ft)==i=1∑nl(yi,y^i(t−1)+fi(xi))+Ω(ft)γJ+2λj=1∑Jωtj2
其中,
Ω
(
f
t
)
\Omega(\mathop{f_t})
Ω(ft)是正则项,能够惩罚叶子节点较多的决策树模型,
J
J
J为某个模型叶子节点的数量,
ω
t
j
\omega_{tj}
ωtj是第j个叶子节点的输出,
γ
\gamma
γ和
λ
\lambda
λ均为与模型无关的学习速率
以上公式中我们可以明显看出,第t轮模型所拟合的是(t-1)轮模型输出的值与实际值的残差
y
^
i
(
t
−
1
)
−
y
i
{\hat y_i}^{(t-1)} - y_i
y^i(t−1)−yi
将以上公式进行二阶泰勒展开,我们可以得到:
{ L ( t ) ≈ ∑ i = 1 n [ l ( y i , y ^ i ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) g i = ∂ y ^ ( t − 1 ) l ( y i , y ^ i ( t − 1 ) ) h i = ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ i ( t − 1 ) ) \left\{ \begin{array}{ll} L^{(t)} & \approx & \displaystyle{\sum_{i=1}^{n}[l(y_i,{\hat y_i}^{(t-1)}) + g_i\mathop{f_t}(x_i) + \frac{1}{2}h_i\mathop{{f_t}^2}(x_i)]} + \Omega(\mathop{f_t}) \\ g_i & = & \partial_{\hat y^{(t-1)}}l(y_i,{\hat y_i}^{(t-1)}) \\ h_i & = & \partial^2_{\hat y^{(t-1)}}l(y_i,{\hat y_i}^{(t-1)}) \\ \end{array} \right . ⎩ ⎨ ⎧L(t)gihi≈==i=1∑n[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)∂y^(t−1)l(yi,y^i(t−1))∂y^(t−1)2l(yi,y^i(t−1))
通过使得
∂
L
(
t
)
∂
y
^
(
t
−
1
)
=
0
\frac{\partial L^{(t)} }{ \partial \hat y^{(t-1)}} = 0
∂y^(t−1)∂L(t)=0 我们可以求得t轮决策树相关的权值
{
ω
t
j
}
\{\omega_{tj}\}
{ωtj},该轮训练结束
XGBoost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了XGBoost的适用性, 使得它按需选取损失函数, 可以用于分类, 也可以用于回归
3.3 XGBoost - python 代码
XGBoost 是sklearn.ensemble RandomForestClassifier的默认使用算法,其重要的超参数与RandomForest类似:
n_estimators - 基分类器数量
criterioin - 分类决策函数类型,默认是 Gini index
max_depth - 控制决策树的深度
min_samples_leaf - 控制每个叶子节点中样本的数量
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
iris_x, iris_y = load_iris(return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.2, random_state=42)
rf_clf = RandomForestClassifier(n_estimators=50, max_depth=2, min_samples_leaf=0.25,random_state=42)
rf_clf.fit(x_train,y_train)
y_pred = rf_clf.predict(x_test)
print(accuracy_score(y_pred,y_test))
$ 0.8333333333333334