基于大型语言模型(LLMs)的聊天机器人可以通过检索增强生成(RAG)提供外部知识来改进。
这种外部知识可以减少错误答案(幻觉),并且使模型能够访问其训练数据中未包含的信息。
通过RAG,我们将信息,如PDF文档或维基百科文章,作为额外的上下文提供给我们的LLM。

然而,RAG聊天机器人遵循数据科学的老原则:输入垃圾,输出垃圾。如果文档检索失败,LLM模型就没有机会提供一个好的答案。
喜欢本文记得收藏、点赞、关注,希望大模型技术交流的加入我们。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
对基本RAG流程的改进是使用重新排序器。重新排序器将用户的问题和所有初始检索到的文档作为输入,并根据它们与问题的匹配程度对这些文档重新排序。
下图展示了使用双编码器模型进行初始候选检索和交叉编码器模型进行重新排序的高级两步检索RAG流程:

两步检索
使用双编码器进行初始检索
基本的RAG流程依赖于一个向量数据库,其中所有外部知识都存储为许多文本块的句子嵌入。
给定一个用户查询,我们将查询转换为一个嵌入向量,然后在查询嵌入和所有存储的文本块嵌入之间执行向量相似性搜索(通常通过计算点积)。
这种编码器模型也称为双编码器,它独立地将所有输入转换为嵌入向量。

由于我们的数据库中可能有成千上万的文档,并且每个文档由许多文本块组成,因此这个过程需要高效且快速。
另一方面,嵌入向量是文本的压缩表示,这最终会导致信息丢失。
使用嵌入进行相似性搜索速度快,但不是最可靠的检索技术。
使用交叉编码器进行重新排序
为什么我们不能只用双编码器检索,比如,k = 1000个文档,并将它们塞进我们的提示上下文中?
首先,上下文长度是有限的。例如,Llama 2的最大长度为4096个标记,GPT-4的最大长度为8192个标记。
其次,如果我们只是将文档塞进去,文档可能会在我们的上下文中“迷失”。因此,最匹配的文档应该放在上下文的最前面【1】。
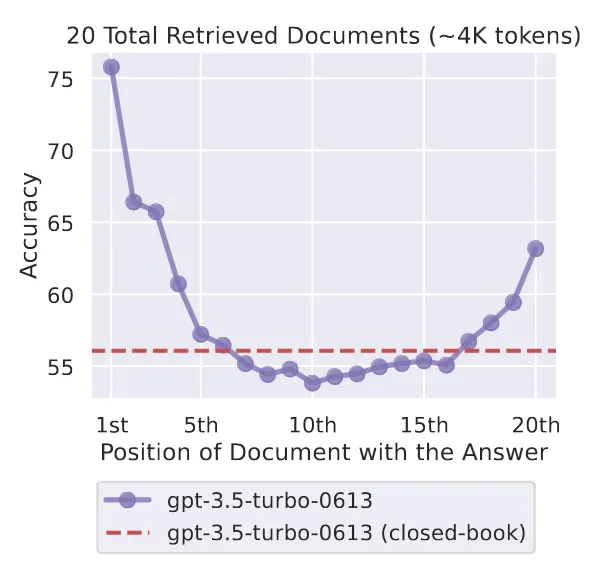
这就是重新排序的作用所在。
重新排序器的任务是评估每个候选文本与给定文本查询的相关性分数。与双编码器不同,交叉编码器同时处理两个输入文本对【2】。

这个思路是先使用双编码器和嵌入相似性搜索来检索候选文档,然后使用一个更慢但更准确的方法对这些文档进行重新排序。
例如,通过使用重新排序器,我们可以将前_k1 = 25个检索到的文档块缩小到最相关的前_k2 = 3个块。
实现两步检索
我将在这里重点介绍如何在Python中实现两步检索组件。
为了激发对RAG的兴趣,我向谷歌的LLM Gemma-2b-it 提了一个关于哈利·波特的问题,但没有提供任何背景信息:
哈利·波特系列的第一本书最初是在什么日期出版的?
LLM 给了我这个错误的答案,其中两个日期都不正确。
“哈利·波特”系列的第一本书《哈利·波特与魔法石》最初于1997年9月26日在英国由布卢姆斯伯里出版社出版,并于1997年11月26日在美国出版。’
让我们用RAG来修正这个答案吧!
首先,使用pip安装所有必要的库。我使用的是Python 3.10。
!pip install pypdf~=4.2.0
!pip install tiktoken~=0.6.0
!pip install wikipedia~=1.4.0
!pip install langchain~=0.1.16
!pip install torch~=2.2.2
!pip install transformers~=4.40.0
!pip install sentence-transformers~=2.7.0
!pip install faiss-cpu~=1.8.0
在向量数据库中存储维基百科文章
截至目前,英文维基百科拥有近700万篇文章,包含超过45亿个单词。
让我们从在向量数据库中存储一些维基百科的知识开始。
使用LangChain的WikipediaLoader,我们可以查询多个维基百科文章并将它们存储在变量pages中。
from langchain_community.document_loaders import WikipediaLoader
pages = WikipediaLoader(query="Harry Potter", load_max_docs=3, lang="en").load()
pages 包含一个检索到的文档列表。属性page_content包含维基百科文章的全文,属性source包含维基百科文章的URL。
[Document(page_content="Harry Potter is a series of seven fantasy novels ...", 'source': 'https://en.wikipedia.org/wiki/Harry_Potter'}),
Document(page_content="Harry Potter is a film series ...", 'source': 'https://en.wikipedia.org/wiki/Harry_Potter_(film_series)'}),
Document(page_content="Harry Potter and the Philosopher\'s Stone ...", 'source': 'https://en.wikipedia.org/wiki/Harry_Potter_and_the_Philosopher%27s_Stone'})]
文章全文太长,所以我们需要使用LangChain的文本分割器将它们分成更小的块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import AutoTokenizer
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
tokenizer=AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L12-v2"),
chunk_size=256,
chunk_overlap=16,
strip_whitespace=True,
)
docs = text_splitter.split_documents(pages)
这将我们的3个文档列表pages减少到18个更小的文档块的列表docs。
现在,让我们加载我们的双编码器模型,用它来将所有18个文本文档块嵌入到384维的稠密向量中。
from langchain_community.embeddings import HuggingFaceEmbeddings
bi_encoder = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L12-v2", model_kwargs={"device": "cpu"}
)
我们可以测试编码器模型看看它是如何工作的:
import numpy as np
embedding1 = bi_encoder.embed_query("Harry Potter")
embedding2 = bi_encoder.embed_query(docs[0].page_content)
print(len(embedding1))
# >> 384
print(np.dot(embedding1, embedding2))
# >> 0.6636567339217812
接下来,我们创建一个向量数据库来存储所有的嵌入。Faiss是一个用于稠密向量高效相似性搜索和聚类的库,由Facebook研究开发。
from langchain.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
faiss_db = FAISS.from_documents(
docs, bi_encoder, distance_strategy=DistanceStrategy.DOT_PRODUCT
)
现在我们已经将维基百科文章块存储在Faiss数据库中,我们可以搜索新查询:
question = (
"On what date was the first book in the Harry Potter series originally published?"
)
retrieved_docs = faiss_db.similarity_search(question, k=25)
这将给我们前k个嵌入。
重新排序
我们可以使用sentence_transformers库中的CrossEncoder类从Hugging Face加载一个交叉编码器模型。这里是一些基于MS MARCO数据集训练的交叉编码器的列表。
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder(
"cross-encoder/ms-marco-TinyBERT-L-2-v2", max_length=512, device="cpu"
)
使用交叉编码器,我们可以对多个文档进行查询评分。分数越高,匹配度越好。以下是一个示例:
cross_encoder.rank(
query="Do I like cats?",
documents=["I like cats", "I like horses", "I like dogs"],
return_documents=True,
)
# >>[{'corpus_id': 0, 'score': 9.002287, 'text': 'I like cats'},
# >> {'corpus_id': 2, 'score': -6.411062, 'text': 'I like dogs'},
# >> {'corpus_id': 1, 'score': -9.557424, 'text': 'I like horses'}]
以下是如何结合Faiss向量数据库中检索到的文档与rank函数获取前k个文档:
reranked_docs = cross_encoder.rank(
question,
[doc.page_content for doc in retrieved_docs],
top_k=3,
return_documents=True,
)
要提取LLM提示的上下文,我们需要结合每个文档中的文本键:
context = "".join(doc["text"] + "\n" for doc in reranked_docs)
print(context)
# >> "Harry Potter and the Philosopher's Stone is a fantasy novel written by British author J. K. Rowling. The first novel in the Harry Potter series and Rowling's debut novel, it follows Harry Potter, a young wizard who discovers his magical heritage on his eleventh birthday, when he receives a letter of acceptance to Hogwarts School of Witchcraft and Wizardry. Harry makes close friends and a few enemies during his first year at the school and with the help of his friends, Ron Weasley and Hermione Granger, he faces an attempted comeback by the dark wizard Lord Voldemort, who killed Harry's parents, but failed to kill Harry when he was just 15 months old.
# The book was first published in the United Kingdom on 26 June 1997 by Bloomsbury. It was published in the United States the following year by Scholastic Corporation under the title Harry Potter and the Sorcerer's Stone. It won most of the British book awards that were judged by children and other awards in the US. The book reached the top of the New York Times list of best-selling fiction in August 1999, and stayed near the top of that list for much of 1999 and 2000. It has been translated into at least 73 other languages, and has been made into a feature-length film of the same name, as have all six of its sequels. The novel has sold in excess of 120 million copies, making it the fourth best-selling book of all time.
# Since the release of the first novel, Harry Potter and the Philosopher's Stone, on 26 June 1997, the books have found immense popularity, positive reviews, and commercial success worldwide. They have attracted a wide adult audience as well as younger readers, and are widely considered cornerstones of modern literature. As of February 2023, the books have sold more than 600 million copies worldwide, making them the best-selling book series in history, and have been available in 85 languages. The last four books consecutively set records as the fastest-selling books in history, with the final instalment selling roughly 2.7 million copies in the United Kingdom and 8.3 million copies in the United States within twenty-four hours of its release.
# The original seven books were adapted into an eight-part namesake film series by Warner Bros. Pictures. In 2016, the total value of the Harry Potter franchise was estimated at $25 billion, making Harry Potter one of the highest-grossing media franchises of all time. Harry Potter and the Cursed Child is a play based on a story co-written by Rowling."
最后,我们可以在提示中包含额外的维基百科RAG上下文,然后问Gemma-2b-it这个问题。现在我们得到了正确的答案:
“哈利·波特”系列的第一本书《哈利·波特与魔法石》最初于1997年6月26日由布卢姆斯伯里出版社出版。
为了更好地追踪,我们可以访问前k个重新排序的文档的元数据:
print("For this answer I used the following documents:")
for doc in reranked_docs:
corpus_id = doc["corpus_id"]
print(
f"Chunk {corpus_id} from '{retrieved_docs[corpus_id].metadata['title']}' (URL: {retrieved_docs[corpus_id].metadata['source']})"
)
# >> "For this answer I used the following documents:
# Chunk 4 from 'Harry Potter and the Philosopher's Stone' (URL: https://en.wikipedia.org/wiki/Harry_Potter_and_the_Philosopher%27s_Stone)
# Chunk 3 from 'Harry Potter and the Philosopher's Stone' (URL: https://en.wikipedia.org/wiki/Harry_Potter_and_the_Philosopher%27s_Stone)
# Chunk 0 from 'Harry Potter' (URL
: https://en.wikipedia.org/wiki/Harry_Potter)"
使用第一个URL,我们可以检查我们的LLM并确认1997年6月26日是正确的日期。
对于本文顶部的聊天机器人图像,我只是将WikipediaLoader和交叉编码器模型添加到我现有的RAG LLM聊天机器人中,以获取重新排序的文档。
结论
基本的RAG系统使用嵌入向量数据库来检索与用户查询相似的文本文档。
向量相似性搜索非常快,但由于将文本嵌入到稠密向量中最终会导致信息丢失,所以它不是最准确的方法。
使用交叉编码器模型重新排序检索到的文档的两步检索流程增加了找到最佳匹配的机会。
在本文中,我演示了如何在Python中使用维基百科的外部知识来回答一个问题,并实现了一个本地的两步检索RAG系统。
参考文献
[1] N. F. Liu et al. (2023), Lost in the Middle: How Language Models Use Long Contexts, arXiv:2307.03172
[2] R. Nogueira and K. Cho (2019), Passage Re-ranking with BERT, arXiv:1901.04085