一.自定义类型不初始化直接就赋值,比如string类会怎么样

vectr<string>里已经给每个string对象已经分配好空间,为什么不初始化再赋值会报错
在C++中,std::string类是一个动态字符串类,它内部管理着一个字符数组,用于存储字符串内容。当你创建一个std::string对象时,如果没有指定初始长度,编译器默认会给它分配足够的内存来容纳后续可能添加的字符。如果你已经为std::string对象分配了空间,但没有初始化就直接赋值,这通常不会导致编译错误,因为std::string内部会自动处理这种情况。
然而,不初始化就赋值可能会带来一些潜在的问题:
-
未定义行为:尽管编译器可能允许你这样做,但这可能导致未定义的行为。因为你没有明确地初始化字符串,其内部状态是不确定的,这意味着它的长度、容量以及所指向的内存可能是随机的。在这种情况下,对字符串的操作(例如,尝试访问其中的字符)可能会产生不可预知的结果。
-
效率问题:虽然
std::string会根据需要自动调整大小,但频繁的动态调整可能会降低程序性能。每次调用push_back、assign等方法时,如果当前的内部缓冲区不足以容纳新的字符,std::string可能需要重新分配更大的内存区域,并复制旧的数据到新位置,这是一个相对耗时的过程。 -
内存泄漏的风险:如果你手动分配了一个字符数组(比如使用
new char[size]),然后试图将这个数组与std::string关联起来,而没有正确地初始化std::string,那么可能会导致内存泄漏。因为std::string会在析构时释放其管理的内存,但如果它不知道内存是在哪里分配的,就不能正确地执行这一操作。
为了避免这些问题,推荐的做法始终是初始化std::string对象,即使你不提供初始值,也可以传递一个空字符串给构造函数:
std::string myString; // 初始化为空字符串
myString = "Hello, World!"; // 现在可以安全地赋值或者,如果你知道字符串的预期最大长度,可以显式指定:
std::string myString(100); // 分配100个字符的空间,但字符串长度仍为0
myString.assign("Hello, World!"); // 安全地赋值,不需要动态调整大小这样可以确保你的代码更稳定且高效。
自定义类型不初始化直接就赋值,比如string类会怎么样
如果自定义类型没有被初始化就直接赋值,那么其成员变量的值将是不确定的,也就是未定义行为。对于string类,如果没有被初始化就直接赋值,它的值将是随机的,可能是一些垃圾值,也可能是一个空字符串。这种行为是不可预测的,会导致程序出现不可预期的错误。
建议在使用自定义类型时,一定要先进行初始化,以保证程序的正确性和可靠性。
为什么没有被初始化就直接赋值,它的值将是随机的
计算机中,内存是由一系列的字节构成的,当变量在内存中被定义时,它会被分配一块内存空间。如果这个变量没有被显式初始化,那么这个内存空间中就会存在垃圾数据,这些数据是来自于此前使用这段内存空间的程序留下的信息,因此这个变量的值就是随机的,可能是任何值。所以在使用变量之前必须对其进行初始化操作,否则可能会导致程序出现不可预期的错误。
变量的声明和定义
(摘自)【C/C++面试必备】声明和定义的区别
声明
声明是用来告诉编译器变量的名称和类型,而不分配内存。
extern int var; // 声明
extern int ble =10; // 定义
typedef int INT; // 声明
struct Node; // 声明上面代码中,语句 extern int var;表示 var 在别的文件中已经定义,提示编译器遇到此变量时在其它模块中寻找其定义。语句 extern int ble = 10;表示定义了变量 ble,这一点需要注意。
注意:即使是 extern ,如果给变量赋值了,就是定义了。
定义
定义是为了给变量分配内存,可以为变量赋初值。
注意:全局变量或静态变量初始值为0,局部变量初始化为随机值。
在 C/C++ 中,变量的声明和定义区别并不大,定义和声明往往是同时发生,变量定义时,会根据变量类型分配空间,如下所示:
int value ; //声明 + 定义
struct Node { // 声明 + 定义
int left;
int right;
}; 变量的声明、定义、赋值和初始化都是在预处理阶段进行的吗
二.std::vector::iterator 为什么不重载运算符>>
std::vector::iterator 是一个迭代器,用于遍历 vector 中的元素。它不重载运算符>>,是因为这个运算符已经被用于输入流。如果重载运算符>>,会导致代码的可读性变差,同时也会带来潜在的歧义。
当我们使用输入流时,我们通常使用运算符>>从输入流中读取数据。如果 std::vector::iterator 也重载了这个运算符,那么就无法确定应该调用哪个运算符。这会导致代码的可读性变差,并且可能会出现难以调试的问题。
因此,std::vector::iterator 没有重载运算符>>。如果需要从输入流中读取 vector 中的元素,可以使用其他方式,例如循环遍历 vector 并逐个读取元素。
这些可以重载:++ *(前置) ==
三.iterator end() { return _finish; }可以写成 iterator& end() { return _finish; }吗?
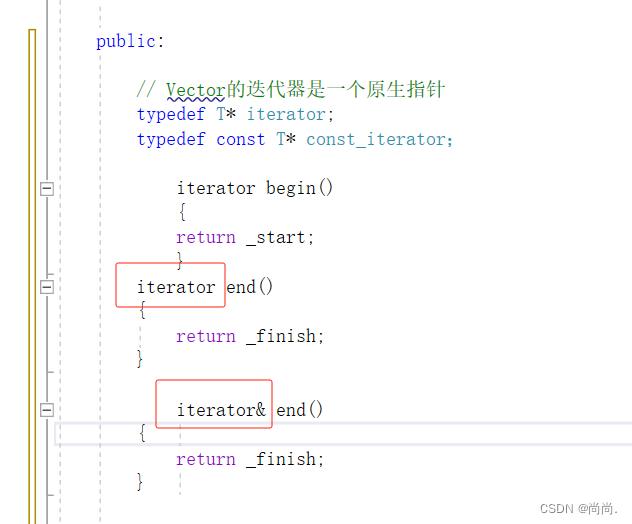
引用返回的话,你改变这个迭代器的指向,那么容器中的迭代器指向也会跟着改变,就会让容器损坏,所以需要的是一个拷贝行为。
iterator beign 和iterator _start是两个不同的哦。
四.不能给初始化列表动态开辟空间
在 C++ 中,初始化列表用于初始化类的成员变量。如果一个类的成员变量需要动态分配内存,那么在初始化列表中是不能进行动态内存分配的。因为初始化列表是在构造函数执行之前执行的,而动态内存分配必须在程序运行时才能完成,所以无法在初始化列表中进行动态内存分配。
举个例子,假设一个类的成员变量包含一个指向 int 类型数组的指针,如果要在构造函数中动态分配内存给这个数组,可以使用 new 操作符来实现。但是,由于初始化列表是在构造函数之前执行的,所以在初始化列表中不能使用 new 操作符来分配内存。
五.具有常性的变量不能引用
具有常性的变量(const variable)是指其值不能被修改的变量。由于其值不可更改,因此不能将其引用给一个非常量变量,因为这样做就会打破 const 变量的常性。而将一个 const 变量引用给一个常量变量是可以的,因为常量变量的值也不会被修改。
例如,以下代码是不合法的:
const int a = 5;
int &b = a; // 错误!不能将 const 变量引用给非常量变量而以下代码是合法的:
const int a = 5;
const int &b = a; // 正确!可以将 const 变量引用给常量变量六.模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
C++ 中的模板函数(函数模板)可以被用于多种不同类型的参数,但是这些参数必须在编译时确定,因此模板函数不允许自动类型转换。相反,普通函数可以在参数和返回值之间进行自动类型转换。
例如,以下是一个模板函数和一个普通函数的示例:
// 模板函数
template <typename T>
T getMax(T a, T b) {
return (a > b) ? a : b;
}
// 普通函数
int getMax(int a, int b) {
return (a > b) ? a : b;
}当你调用 getMax(3, 5) 时,编译器会自动推断出使用普通函数,因为参数是整数类型。但是,当你调用 getMax(3.5, 2.8) 时,编译器将无法确定使用哪个函数,因为参数既可以是 int 类型也可以是 double 类型。在这种情况下,你必须显式地指定类型来调用模板函数。
七.模板满树的声明和定义必须放在一起(比如:vector<T>)
(不同于一般c++函数,声明可以在头文件,定义可以在cpp文件。
模板函数的声明和定义必须放在一起,否则编译链接会报错。
非要分开写的话,需要在cpp文件中进行模板的显式实例化,但这需要把所有用到的T都列出来。或者在头文件末尾include 这个cpp文件,但这本质和写在一个头文件没有区别,而且由于cpp文件往往没有防止重复include的机制,链接时容易报错重复定义。
参考:
类模板的定义和实现必须在一个文件吗_c++ 接口类 实现和定义不在同一个文件
/* a.hpp */
template <typename T>
T func(T input);
/* 必须也放在a.hpp */
template <typename T>
T func(T input)
{
return input;
}汉诺塔问题,青蛙跳台,斐波那契数列
汉诺塔问题和青蛙跳台阶问题/汉诺塔和斐波那契数列的递归算法实现