💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 算法原理
- 🍞三. 核心逻辑
- 🍞四.效果演示
- 🍞五.使用方式
- 🫓总结
💡本章重点
- 自监督高效图像去噪
🍞一. 概述
本文复现论文 Zero-Shot Noise2Noise: Efficient Image Denoising without any Data[1] 提出的图像去噪方法。
随着深度学习的发展,各种图像去噪方法的性能不断提升。然而,目前的工作大多需要高昂的计算成本或对噪声模型的假设。为解决这个问题,该论文提出了一种自监督学习方法。该方法使用一个简单的两层卷积神经网络和噪声到噪声损失(Noise to Noise Loss),在只使用一张测试图像作为训练样本的情况下,实现了低成本高质量的图像去噪。
🍞二. 算法原理
💡方法
-
成对下采样
-
残差损失
-
一致性损失
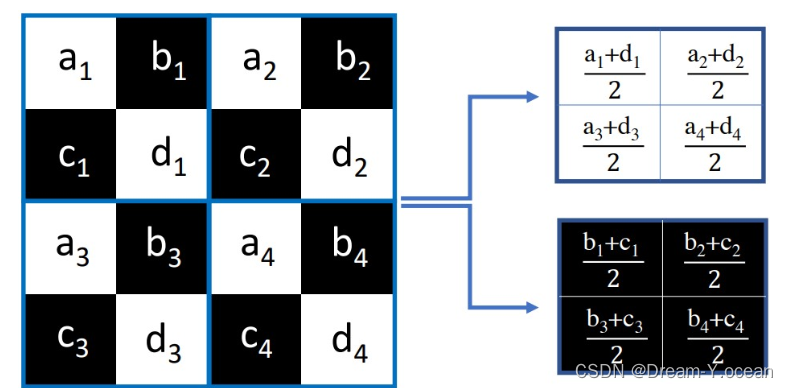
💡成对下采样:
该成对下采样器将原始图像下采样为长宽只有原先一半的子图。具体地,其通过将图像分割为大小为 2 × 2 的非重叠补丁,并将每个补丁的对角线像素取平均值并分配给第一个子图,然后将反对角线像素取平均值并分配给第二个子图像。该成对下采样器的示意图如下所示:
💡残差损失:
在非自监督的情况下,损失函数一般采用噪声图像与干净图像之间平方差的形式:
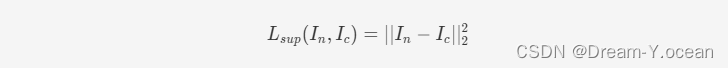
在自监督的情况下,没有干净图像作为训练目标,则可以将两张噪声图像子图互为训练目标,即噪声到噪声损失:
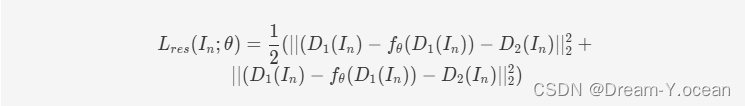
基于噪声独立性假设,可以证明这两种损失的期望值相同。
💡一致性损失:
考虑到残差损失只使用了噪声图像子图训练模型,而测试时需要整张噪声图像作为输入,为了使网络对子图的噪声估计与对原图的噪声估计保持一致,作者还引入了一个一致性损失函数:
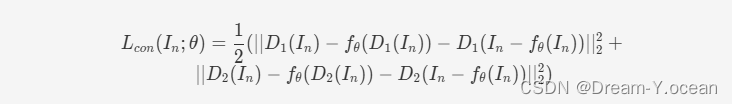
总的损失如下所示:
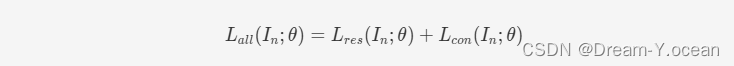
🍞三. 核心逻辑
上述方法的核心逻辑如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def diag_sample(image):
'''下采样函数,输入图像,输出两张长宽只有原先一半的子图'''
# 分割成2x2的补丁
height = int(image.shape[2] / 2)
width = int(image.shape[3] / 2)
image_patch = image[:, :, 0: height * 2, 0: width * 2].view(image.shape[0], image.shape[1], height, 2, width, 2).permute(0, 1, 2, 4, 3, 5)
# 对角线元素取平均作为第一个子图
image_sub1 = (image_patch[:, :, :, :, 0, 0] +image_patch[:, :, :, :, 1, 1]) / 2
# 反对角线元素取平均作为第二个子图
image_sub2 = (image_patch[:, :, :, :, 0, 1] +image_patch[:, :, :, :, 1, 0]) / 2
return image_sub1, image_sub2
class NoisePredictor(nn.Module):
'''噪声估计网络,输入图像,输出估计的图像噪声'''
def __init__(self, channels=3):
super(NoisePredictor, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(channels, 52, 3, padding=1),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(52, 52, 3, padding = 1),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(52, channels, 1)
)
def forward(self, x):
return self.net(x)
def train_once(image_noise, model, optimizer):
'''对模型进行一轮训练'''
# 用于计算差方和
mse_loss = nn.MSELoss(reduction='sum')
model.train()
optimizer.zero_grad()
# 生成噪声的子图
image_noise_s1, image_noise_s2 = diag_sample(image_noise)
# 估计噪声图像子图的干净图像
image_s1_clean = image_noise_s1 - model(image_noise_s1)
image_s2_clean = image_noise_s2 - model(image_noise_s2)
# 估计噪声图像的干净图像
image_clean = image_noise - model(image_noise)
# 生成噪声图像的干净图像的子图
image_clean_s1, image_clean_s2 = diag_sample(image_clean)
# 残差损失
loss_res = (mse_loss(image_s1_clean, image_noise_s2) + mse_loss(image_s2_clean, image_noise_s1)) / 2
# 一致性损失
loss_con = (mse_loss(image_s1_clean, image_clean_s1) + mse_loss(image_s2_clean, image_clean_s2)) / 2
# 总损失
loss = loss_res + loss_con
# 梯度反向传播
loss.backward()
# 更新模型参数
optimizer.step()
def add_noise(image, degree):
'''输入图像和噪声程度(0~1),输出加入噪声的图像'''
noise = np.random.normal(0, degree, image.shape)
noisy_image = np.clip(image + noise, 0, 1)
return noisy_image
🍞四.效果演示
配置环境并运行main.py脚本,效果如下:

🍞五.使用方式
- 解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip Image_Denoising.zip
cd Image_Denoising
- 代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt
- 如果希望在本地运行程序,请运行如下命令:
python main.py
- 如果希望在线部署,请运行如下命令:
python main-flask.py
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】