目录
引言
一、List-Watch机制概述
(一)基本概念
(二)工作机制
1.List操作
2.Watch操作
(三)数据流向
1.按模块划分
2.按整体总结
二、Pod生命周期
(一)生命周期
1.创建
2.调度
3.初始化容器启动
4.镜像拉取
5.容器创建与运行
6.健康检查与就绪检测
7.重启策略
8.清理
9.终止
(二)生命周期状态
1.Pending
2.Running
3.Succeeded
4.Failed
5.Unknown
引言
在Kubernetes(K8s)这个庞大的分布式系统中,资源的实时更新和响应对于维持集群的稳定性和高效性至关重要。而List-Watch机制正是Kubernetes实现这一目标的核心手段。本文将详细介绍Kubernetes中的List-Watch机制,与容器的生命周期。包括其工作原理、应用场景以及性能优化等方面。
一、List-Watch机制概述
(一)基本概念
List-Watch是Kubernetes API Server提供的一种资源监控机制。它允许客户端通过API Server获取资源对象的列表(List),并通过建立长连接(Watch)来实时监控资源对象的变化。当资源对象发生创建、更新或删除等操作时,API Server会向订阅了相关资源的客户端发送事件通知,实现资源的实时同步和响应
(二)工作机制
List-Watch机制的工作原理可以简单概括为以下两个步骤
1.List操作
客户端向Kubernetes API Server发送List请求,指定要获取的资源类型和筛选条件。API Server根据请求返回符合条件的资源对象列表。客户端可以根据这个列表来初始化自己的状态或进行其他操作。
2.Watch操作
客户端在获取到资源对象列表后,可以继续向API Server发送Watch请求,建立与API Server的长连接。API Server会持续监控指定资源的变化,并将变化事件以流的形式发送给客户端。客户端可以解析这些事件通知,并触发相应的处理逻辑。
(三)数据流向
1.按模块划分
初始化阶段:Kubernetes的各种组件(如Controller Manager、Scheduler、kubelet等)在启动时,会与APIServer建立连接,并初始化List-Watch机制。
List操作:组件向APIServer发送List请求,获取当前集群中指定资源类型的所有资源对象列表。例如,Controller Manager可能会请求获取所有Pod的列表。APIServer处理List请求,查询etcd存储系统,并将结果返回给组件。
Watch操作:组件向APIServer发送Watch请求,建立一个长连接,用于监听指定资源类型的变化。APIServer处理Watch请求,并在内部与etcd建立Watch连接,以监听etcd中对应资源的变化。
事件触发:当etcd中的资源发生变化(如Pod的创建、更新或删除)时,etcd会发送一个事件通知给APIServer。APIServer接收到事件通知后,会将事件封装成HTTP响应,并通过之前建立的长连接发送给对应的组件。
组件处理:组件接收到APIServer发送的事件通知后,会解析通知中的信息,并根据事件的类型(如ADD、UPDATE、DELETE)执行相应的操作。例如,如果Controller Manager接收到Pod被创建的事件,它可能会触发相应的控制器逻辑,如ReplicaSet控制器会根据Pod的创建来调整副本集的状态。
数据同步:通过List-Watch机制,Kubernetes的各个组件能够实时感知集群中资源的变化,并据此进行相应的操作,从而保持数据的同步和一致性。
2.按整体总结
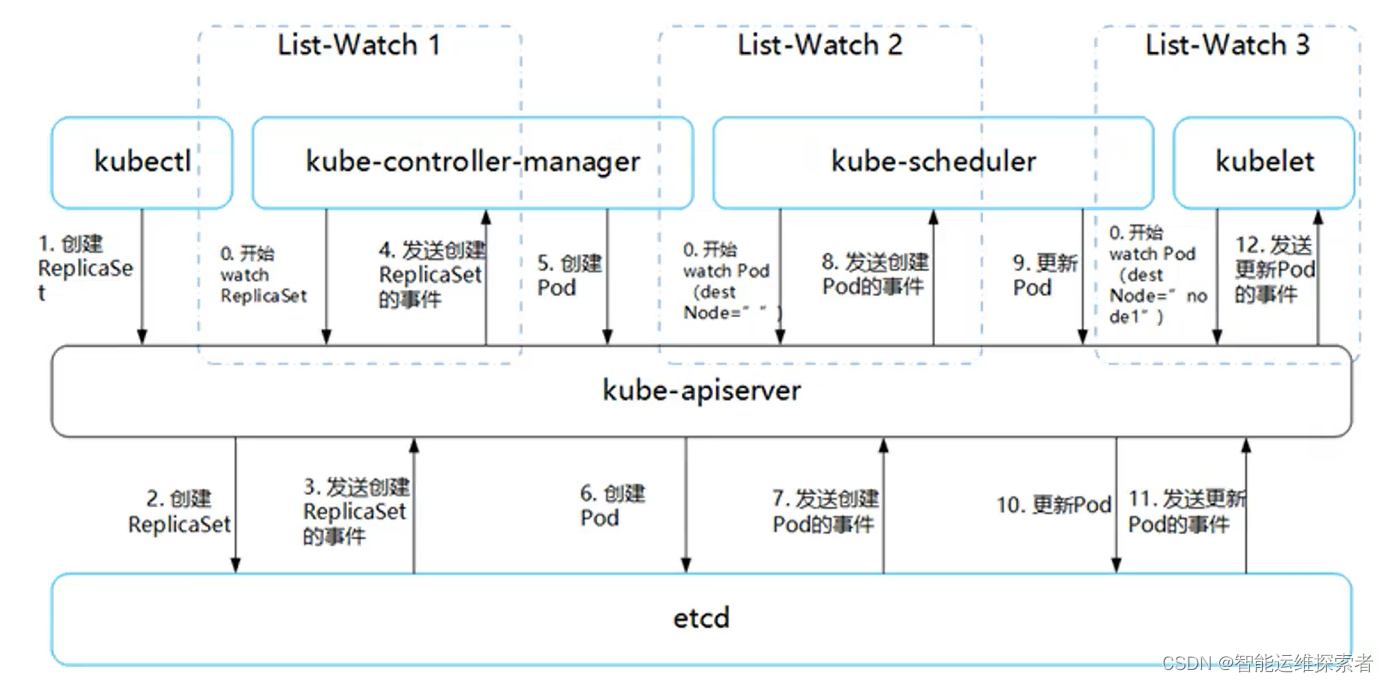
1)这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。 它们在进程已启动就会监听(Watch)APIServer 发出来的事件
2)用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
3)APIServer将Pod对象的元数据信息存入ETCD当中,待存储完毕后,APIServer会将确认信息返回给客户端,同时ETCD会将创建Pod副本的事件发送给APIServer
4)由于Controller-Manager 一直在监听(Watch,通过https的6443端口)APIServer 中的事件。此时 APIServer 接受到了Create(创建Pod副本)事件,又会发送给Controller Manager
5)Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证 Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的 Controller(PS:扩容缩容的担当)
6)在Controller-Manager创建Pod副本以后,APIServer会在ETCD中记录这个Pod的详细信息。例如Pod的副本数,Container的内容是什么
7)同样的ETCD会将创建Pod的信息通过事件发送给APIServer
8)由于Scheduler在监听(Watch)APIServer,APIServer会将Create事件发送到Scheduler,Scheduler接收到事件后,会根据预选与优选策略,为该事件选择合适的node节点,
9)Scheduler 调度完毕以后会更新Pod的信息,此时的信息更加丰富了。除了知道Pod的副本数量,副本内容。还知道部署到哪个Node上面了。并将上面的Pod信息更新至API Server,
10) APIServer更新至ETCD中,保存起来
11)ETCD将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果
12)kubelet是在Node上面运行的进程,它也通过List-Watch的方式监听(Watch,通过https的6443端口)APIServer发送的Pod更新的事件。kubelet会尝试在当前节点上调用Docker启动容器,并将Pod以及容器的结果状态回送至APIServer,同时kubelet会负责Pod的整个生命周期
13)最后,APIServer将Pod状态信息存入ETCD中。在ETCD确认写入操作成功完成后,APIServer将确认信息发送至相关的kubelet,事件将通过它被接受
注释:kubelet持续监控Pod状态,当kubectl发送删除、扩容、缩容等指令时,会将以上流程重复一遍,而后根据最新的情况,在node节点中调整部署资源
二、Pod生命周期
Pod的生命周期从创建开始,经历一系列阶段直至最终终止或被删除。
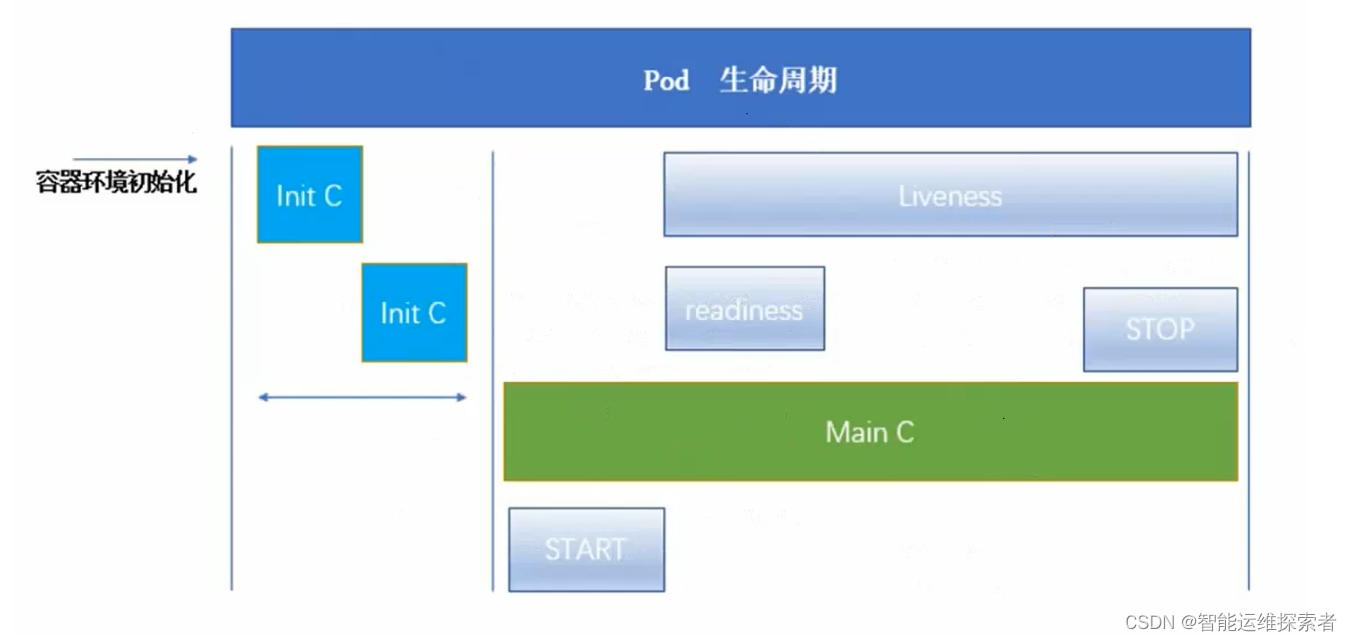
(一)生命周期
1.创建
用户通过创建一个新的Pod对象来请求Kubernetes调度器为Pod分配资源。
Kubernetes系统会赋予Pod一个唯一的ID(UID)。
2.调度
Pod被提交到集群后,调度器根据节点资源可用性和Pod的资源需求、亲和性/反亲和性规则等选择合适的节点,并将Pod绑定到该节点上。
3.初始化容器启动
若Pod定义中包含初始化容器(init containers),这些容器会在主容器启动前按顺序执行,用于设置运行主容器所需的条件或环境。
每个Init容器都必须在下一个Init容器启动之前成功完成。
如果Pod的Init容器失败,并且Pod的重启策略(restartPolicy)值为“Always”,则kubelet会不断地重启该Init容器直到该容器成功为止。但如果Pod的重启策略值为“Never”,则Kubernetes不会重新启动Pod。
4.镜像拉取
主容器对应的镜像如果没有在节点上,则kubelet负责从注册表中拉取镜像。
5.容器创建与运行
kubelet根据Pod Spec创建并启动主容器。
容器状态会经历从Pending(等待中)到Running(运行中)的变化。
6.健康检查与就绪检测
在容器运行期间,kubelet可以配置并执行健康检查(liveness probes)和就绪检查(readiness probes)以确保容器正常工作。
Liveness Probe用于判断容器是否存活,若失败则可能重启容器。
Readiness Probe用于决定容器是否准备好接收流量,只有当容器处于ready状态时,Service才会将其添加到服务端点列表中。
7.重启策略
根据Pod的重启策略(Always、OnFailure或Never),kubelet会决定在容器退出时应采取何种行动。
8.清理
当Pod被删除或者由于某种原因需要终止时,kubelet会按照预定义的优雅关闭策略通知容器停止服务,并等待一段时间让容器完成任何必要的清理操作。
清理完成后,kubelet会真正删除Pod及其相关的容器实例和其他资源。
9.终止
Pod完全从节点上移除。
此外,Pod生命周期中还包括容器启动后钩子(post-start hook)和停止前钩子(pre-stop hook),这些钩子允许在容器启动后和停止前执行特定的操作。
(二)生命周期状态
Pod的生命周期状态主要包括
1.Pending
Pod已经被Kubernetes系统接受,但是有一个或多个容器镜像尚未创建。
Pod等待被调度到一个节点上。可能涉及下载镜像、分配IP地址、执行初始化容器等操作。
如果Pod一直处于等待中,可能是由于资源不足、调度问题或其他原因导致。
2.Running
Pod已经被调度至某节点,所有容器都已经被kubelet创建完成,且至少有一个容器处于启动、重启或运行过程中。
3.Succeeded
Pod中的所有容器都已成功完成并退出。
通常适用于一次性或批处理作业。
4.Failed
Pod中的一个或多个容器由于某种原因失败。
这可能是由于容器的退出代码非零、初始化容器失败、依赖资源不可用等原因导致。
5.Unknown
由于某种原因,Pod的状态无法确定。
这可能是由于与API服务器的通信问题或其他异常情况导致。