🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5关联规则
4.6推荐菜肴
5.总结
源代码
1.项目背景
在数字化时代,随着人们对个性化服务的需求不断增长,推荐系统已成为各类应用中的关键组成部分。特别是在美食领域,用户常常面临从众多选择中挑选合适菜肴的难题。印度美食以其丰富的口味和独特的烹饪方式而著称,但用户往往难以从海量的印度美食中挑选出符合自己口味的菜品。因此,开发一个能够准确推荐印度美食的个性化推荐系统具有重要的现实意义和应用价值。
传统的推荐方法往往基于用户的历史行为数据或评分数据进行相似度计算,但这些方法可能受到数据稀疏性和冷启动问题的限制。余弦相似度作为一种衡量向量间相似性的有效方法,具有不受向量长度影响、对方向敏感等特点,使其在推荐系统中具有广泛的应用前景。通过将印度美食的特征表示为向量,并利用余弦相似度计算用户与菜品之间的相似度,可以更准确地捕捉用户的口味偏好,从而为用户提供个性化的美食推荐。
此外,印度美食文化具有深厚的历史底蕴和地域特色,不同地区和民族的美食风格各异。因此,一个有效的印度美食推荐系统需要能够充分考虑这些文化因素,为用户提供符合其口味和文化背景的推荐结果。基于余弦相似度的推荐方法可以通过灵活调整向量表示和相似度计算方式,更好地融入这些文化因素,提高推荐的准确性和用户满意度。
综上所述,基于余弦相似度的印度美食推荐系统实验的研究背景涵盖了个性化服务需求、印度美食文化的丰富性、传统推荐方法的局限性以及余弦相似度在推荐系统中的优势等多个方面。通过对这些方面进行深入研究和探索,有望为印度美食推荐系统的发展提供新的思路和方法。
2.数据集介绍
印度美食由印度次大陆本土的各种地区和传统美食组成。由于土壤、气候、文化、种族和职业的多样性,这些菜肴差异很大,并使用当地可用的香料、香草、蔬菜和水果。印度食物也深受宗教(特别是印度教)、文化选择和传统的影响。
本数据集来源于Kaggle,原始数据集共有255条,8个变量,各变量含义解释如下:
name : 菜肴名称
ingredients:主要使用成分
diet:饮食类型 - 素食或非素食
prep_time : 准备时间
Cook_time : 烹饪时间
flavor_profile : 风味特征包括菜品是否辣、甜、苦等
course : 餐点 - 开胃菜、主菜、甜点等
state : 该菜肴著名或起源的州
Region : 国家所属地区
任何列中出现 -1 表示 NaN 值。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载数据集


查看数据大小

查看数据基本信息
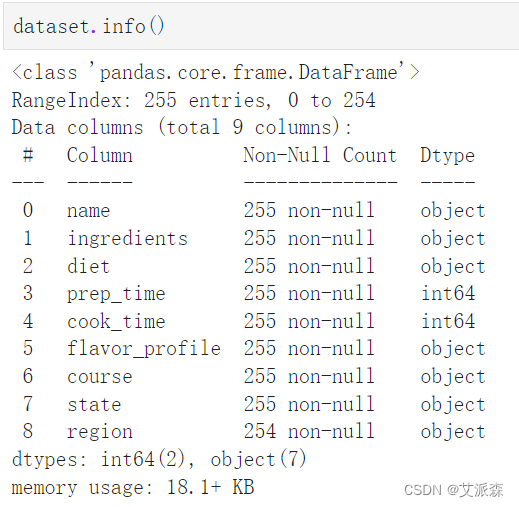
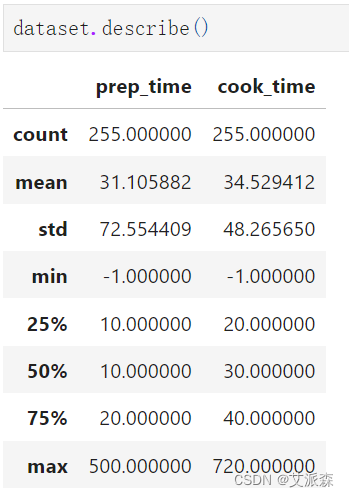
查看数值型变量的描述性统计
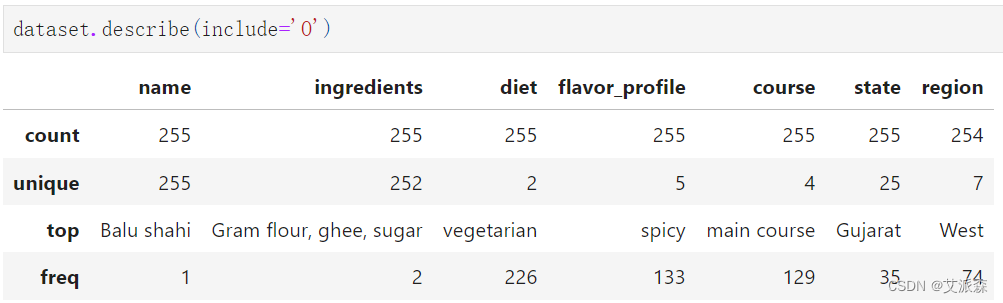
查看非数值型变量的描述性统计
4.2数据预处理
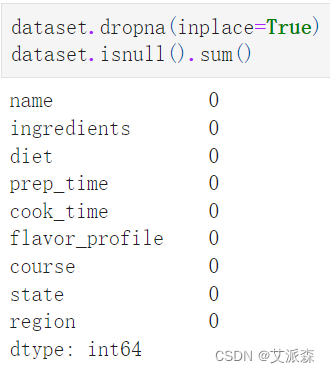
统计缺失值情况
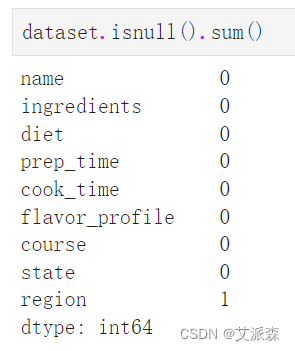
可以发现region列有一个缺失值需要处理
统计重复值情况
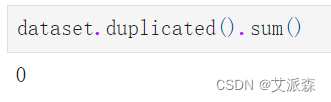
可以发现数据中不存在重复值
删除缺失值
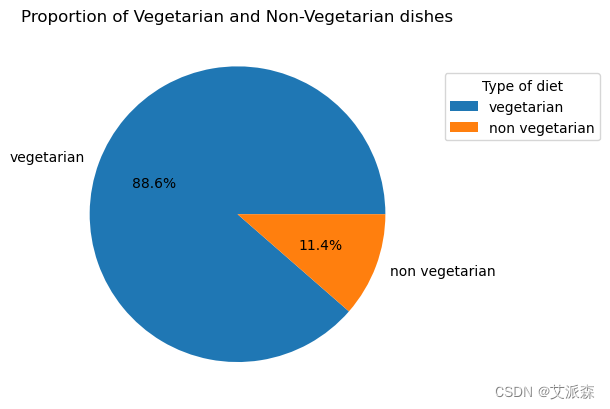
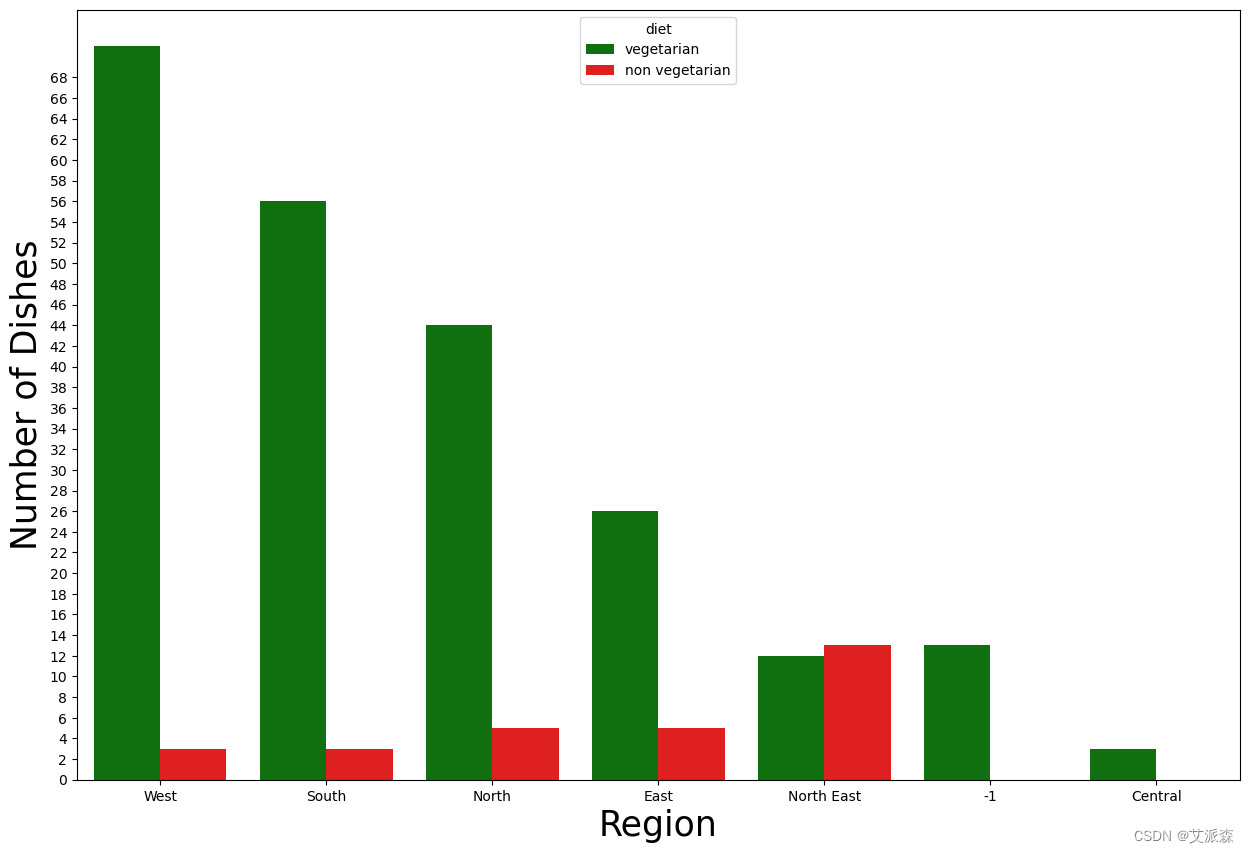
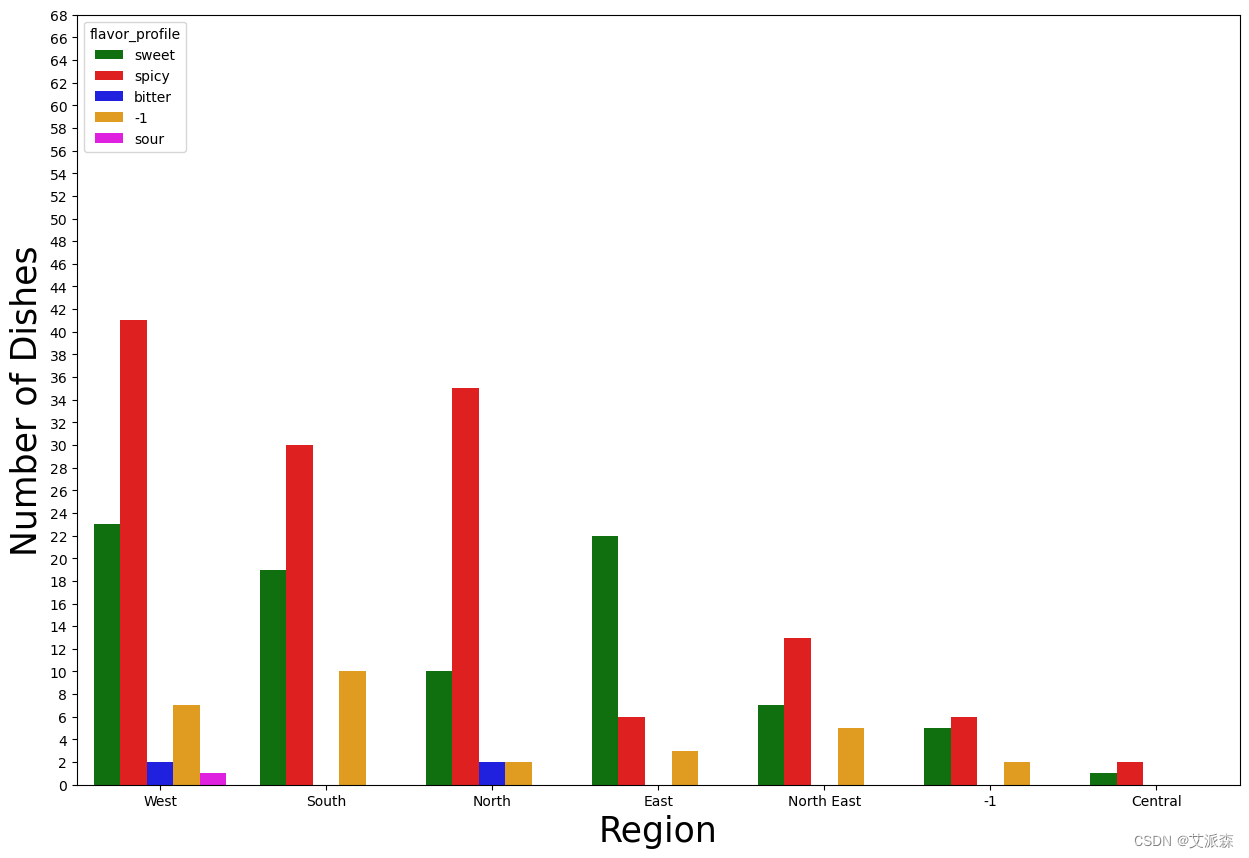
4.3数据可视化



4.4特征工程
筛选特征

编码处理

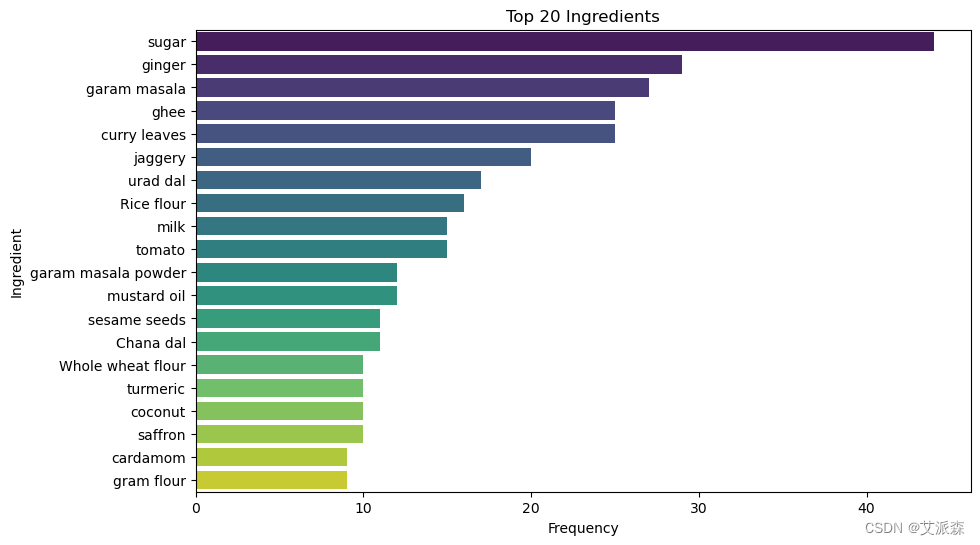
统计前20名菜肴成分

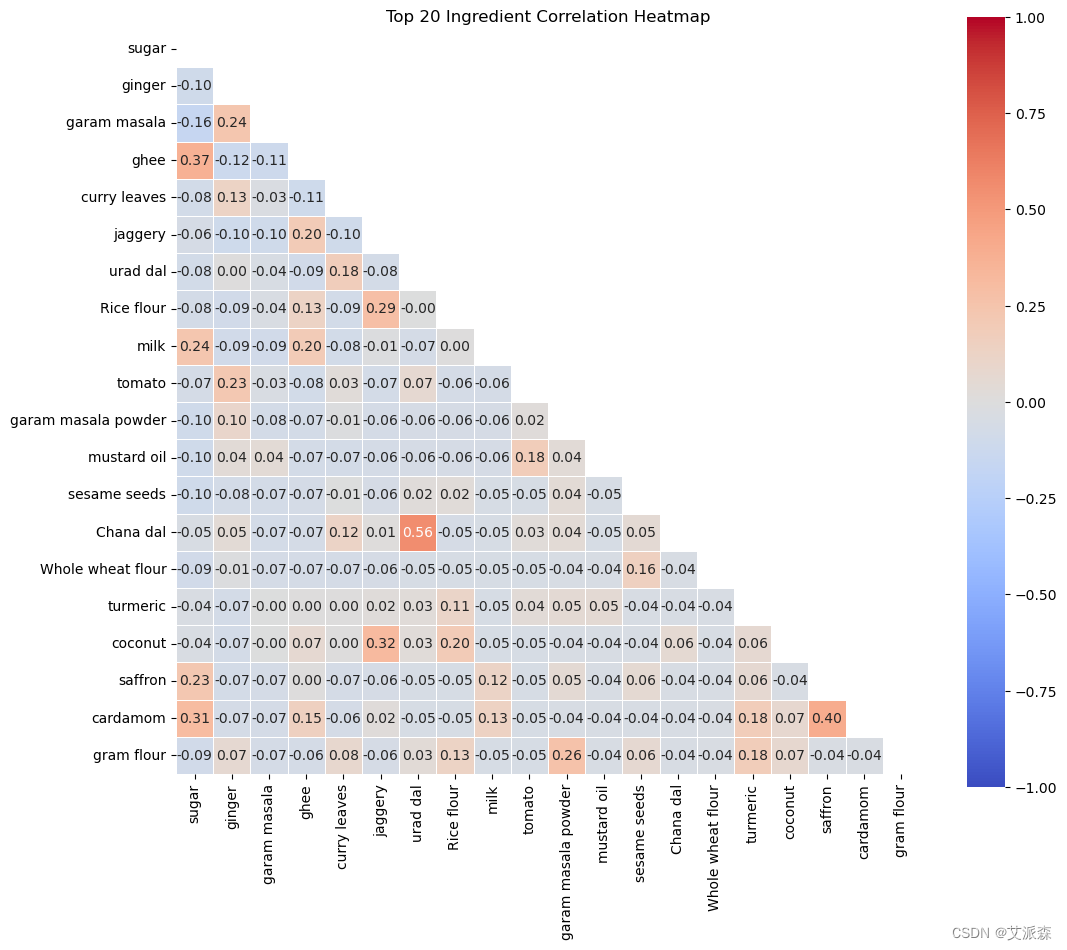
计算前20种成分的相关性

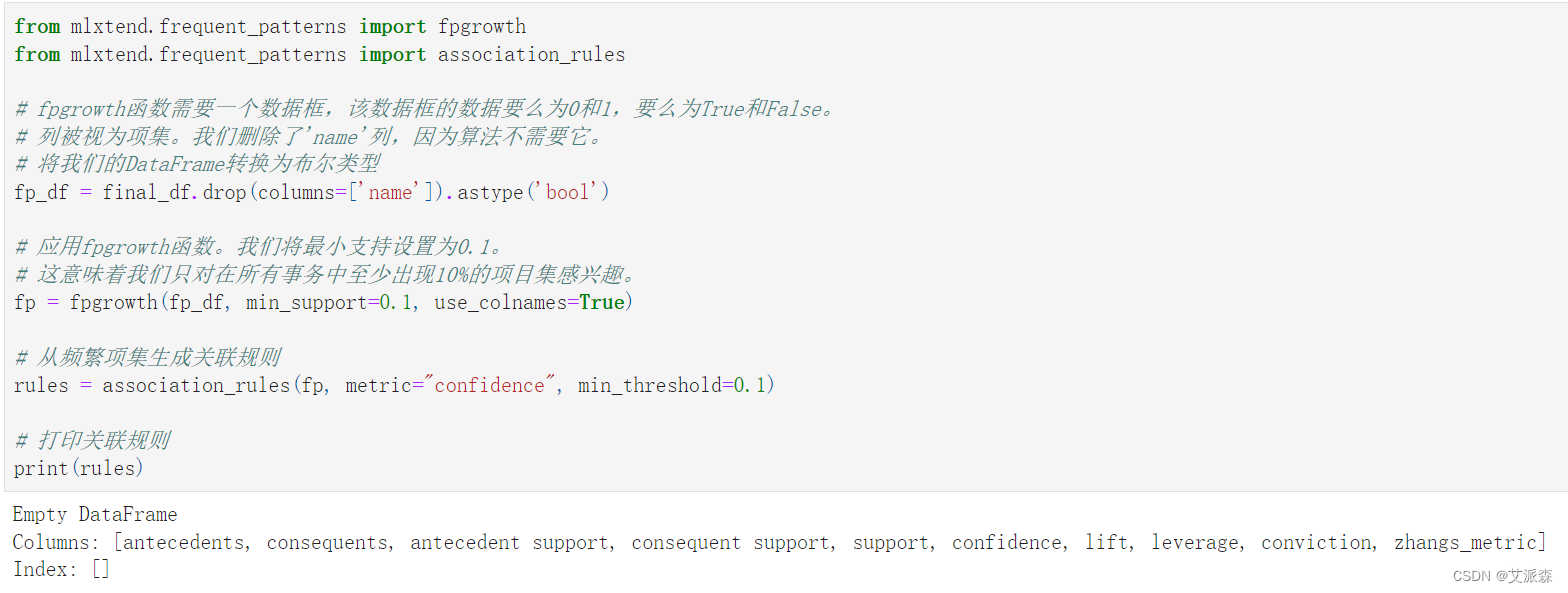
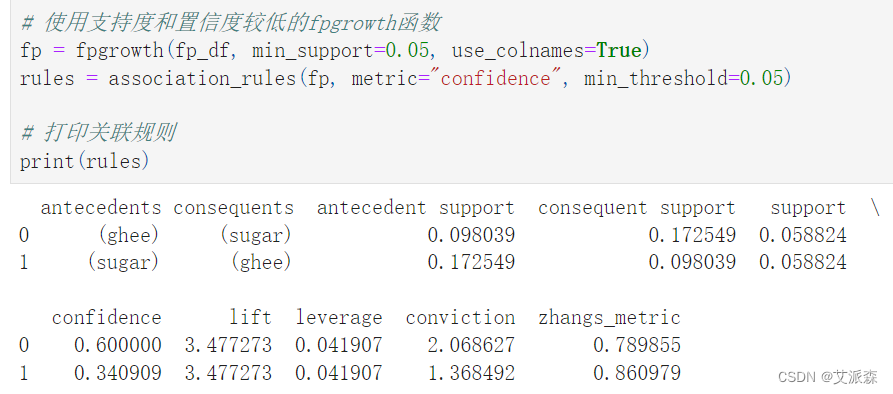
4.5关联规则
4.6推荐菜肴
计算余弦相似矩阵并自定义一个推荐菜肴的函数

让我们推荐一道菜

5.总结
通过采用余弦相似度作为核心相似度度量方法,本实验成功构建了一个个性化印度美食推荐系统。实验结果表明,该系统能够有效地捕捉用户的口味偏好,并根据用户的个性化需求提供准确的美食推荐。与传统的推荐方法相比,基于余弦相似度的推荐方法在处理印度美食推荐问题时表现出了更高的准确性和稳定性。此外,该系统还具有一定的灵活性和可扩展性,能够适应不同用户群体和美食文化背景的需求。综上所述,基于余弦相似度的印度美食推荐系统为用户提供了更加便捷、个性化的美食选择体验,具有广阔的应用前景和进一步优化的潜力。
源代码
name : 菜肴名称
ingredients:主要使用成分
diet:饮食类型 - 素食或非素食
prep_time : 准备时间
Cook_time : 烹饪时间
flavor_profile : 风味特征包括菜品是否辣、甜、苦等
course : 餐点 - 开胃菜、主菜、甜点等
state : 该菜肴著名或起源的州
Region : 国家所属地区
任何列中出现 -1 表示 NaN 值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
dataset = pd.read_csv('indian_food.csv')
dataset.head()
dataset.shape
dataset.info()
dataset.describe()
dataset.describe(include='O')
dataset.isnull().sum()
dataset.duplicated().sum()
dataset.dropna(inplace=True)
dataset.isnull().sum()
plt.pie(dataset['diet'].value_counts(), labels = dataset.diet.unique(), autopct='%1.1f%%')
plt.title('Proportion of Vegetarian and Non-Vegetarian dishes')
plt.legend(title='Type of diet', loc = 'upper right', bbox_to_anchor=(1.50, 0.90))
plt.show()
plt.figure(figsize=(15,10))
sns.countplot(x="region", data=dataset,palette =['green','red'], hue ="diet", order = dataset.region.value_counts().index)
plt.yticks(np.arange(0,70, step=2))
plt.xlabel("Region", fontsize = 25)
plt.ylabel("Number of Dishes", fontsize=25)
plt.title("")
plt.show()
plt.figure(figsize=(15,10))
sns.countplot(x="region", data=dataset,palette =['green','red','blue','orange','magenta'], hue ="flavor_profile", order = dataset.region.value_counts().index)
plt.yticks(np.arange(0,70, step=2))
plt.xlabel("Region", fontsize = 25)
plt.ylabel("Number of Dishes", fontsize=25)
plt.title("")
plt.show()
# 从数据集中提取一些特征来工作
new_df = dataset[['name','ingredients']]
new_df.head()
# 用逗号分隔成分,并去掉空白
new_df['ingredients'] = new_df['ingredients'].str.split(',').apply(lambda x: [i.strip() for i in x])
from sklearn.preprocessing import MultiLabelBinarizer
# 初始化MultiLabelBinarizer
mlb = MultiLabelBinarizer()
# 拟合和变换配料列
one_hot = mlb.fit_transform(new_df['ingredients'])
# 将单热编码结果转换为DataFrame并设置列名
one_hot_df = pd.DataFrame(one_hot, columns=mlb.classes_)
# 将原始DataFrame与单热编码的DataFrame连接起来
final_df = pd.concat([new_df['name'], one_hot_df], axis=1)
import matplotlib.pyplot as plt
import seaborn as sns
# 对每一行求和得到每个成分的频率
ingredient_freq = final_df.drop(columns='name').sum()
# 排序并选出前20名
top_ingredients = ingredient_freq.sort_values(ascending=False)[:20]
plt.figure(figsize=(10, 6))
sns.barplot(x=top_ingredients.values, y=top_ingredients.index, palette='viridis')
plt.title('Top 20 Ingredients')
plt.xlabel('Frequency')
plt.ylabel('Ingredient')
plt.show()
# 计算前20种成分的相关性
correlations = final_df[top_ingredients.index.to_list()].corr()
# Mask以消除重复/自相关性
mask = np.triu(np.ones_like(correlations, dtype=bool))
# 用Mask绘制热图
plt.figure(figsize=(12, 10))
sns.heatmap(correlations, mask=mask, cmap='coolwarm', vmax=1, vmin=-1, square=True, linewidths=.5, annot=True, fmt=".2f")
plt.title('Top 20 Ingredient Correlation Heatmap')
plt.show()
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.frequent_patterns import association_rules
# fpgrowth函数需要一个数据框,该数据框的数据要么为0和1,要么为True和False。
# 列被视为项集。我们删除了'name'列,因为算法不需要它。
# 将我们的DataFrame转换为布尔类型
fp_df = final_df.drop(columns=['name']).astype('bool')
# 应用fpgrowth函数。我们将最小支持设置为0.1。
# 这意味着我们只对在所有事务中至少出现10%的项目集感兴趣。
fp = fpgrowth(fp_df, min_support=0.1, use_colnames=True)
# 从频繁项集生成关联规则
rules = association_rules(fp, metric="confidence", min_threshold=0.1)
# 打印关联规则
print(rules)
# 使用支持度和置信度较低的fpgrowth函数
fp = fpgrowth(fp_df, min_support=0.05, use_colnames=True)
rules = association_rules(fp, metric="confidence", min_threshold=0.05)
# 打印关联规则
print(rules)
from sklearn.metrics.pairwise import cosine_similarity
# 计算余弦相似矩阵
cosine_sim = cosine_similarity(final_df.drop(columns=['name']))
def get_recommendations(name, cosine_sim=cosine_sim):
# 获取与该名称匹配的菜的索引
idx = final_df.index[final_df['name'] == name][0]
# 得到所有菜品与这道菜的两两相似度
sim_scores = list(enumerate(cosine_sim[idx]))
# 根据相似度评分对菜肴进行排序
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 得到10个最相似的菜的分数
sim_scores = sim_scores[1:11]
# 获取菜肴指数
dish_indices = [i[0] for i in sim_scores]
# 返回10个最相似的菜肴
return final_df['name'].iloc[dish_indices]
# 让我们推荐一道菜
print(get_recommendations('Balu shahi'))
资料获取,更多粉丝福利,关注下方公众号获取