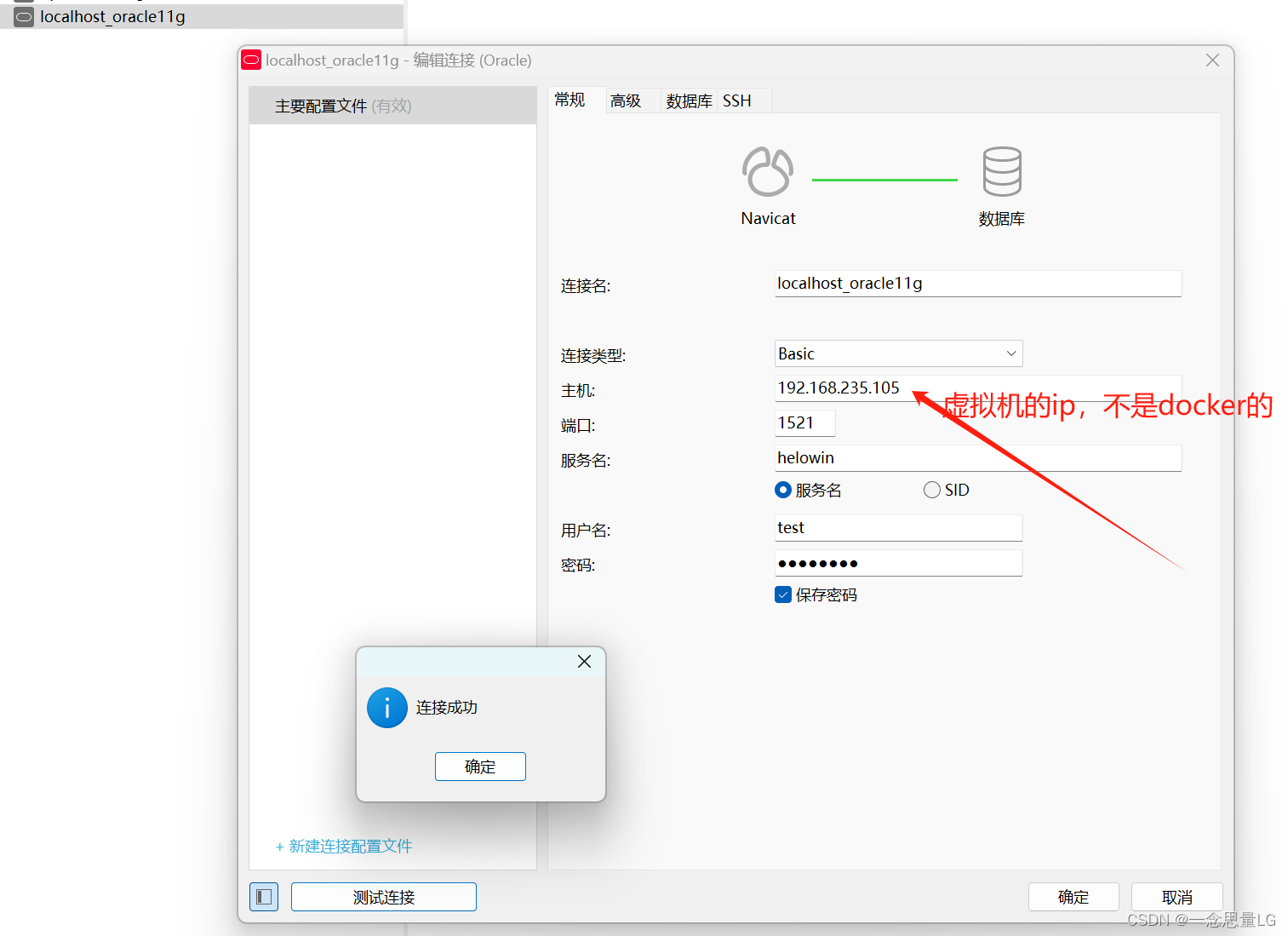
VGG-16 和 Inception V3 两种模型
第一个是使用预训练模型作为特征提取器,第二个是微调预训练模型。
1. 介绍
乳腺癌是女性最常见的癌症,癌症筛查是通过乳房超声 (BUS) 成像和乳房 X 光检查进行的。
目前的问题是需要 依赖大型且带注释的BUS数据集进行CNN训练。缓解这个问题的一个可能的解决方案是利用迁移学习和微调。
2. 乳腺超声图像分析中的深度学习
在[8]中,作者提出使用不同的 CNN 来定位与病变相对应的感兴趣区域 (ROI)。在[9]中,CNN被用作特征提取器,并且使用支持向量机(SVM)对获得的特征进行分类。[10]中提出了一种基于 AlexNet 的架构,并使用小型定制数据集将其性能与一些预训练模型进行了比较。[11]中,提出了一种基于使用生成对抗网络(GAN)进行数据增强的方法。
[13]中提出了对GoogLeNet架构的修改,该网络是Inception V3的早期版本,由一个主分支和两个辅助分类器组成,具体来说,他们建议从网络的主分支中删除辅助分类器。
[14]中,比较了不同的预训练模型,但仅使用微调。比较了 CNN ResNet50、InceptionV3 和 Xception。
3. 提出的方法
研究了两种不同的迁移学习技术:(i) 微调和 (ii) 使用预训练的 CNN 作为特征提取器。这些方法中的每一种都使用两种不同的 CNN 架构进行了测试。
3.1 CNN 架构
VGG-16 是一个 16 层 CNN 模型,具有由 13 个卷积层和 5 个最大池层组成的顺序架构[15]。该架构从具有 64 个内核的卷积层开始。每次池化操作后,这个数字都会加倍,直到达到 512。池化层放置在选定的卷积层之后,以减少激活映射的维度,从而减少后续卷积层的维度。这通常会减少 CNN 需要学习的参数数量。该模型中所有卷积层的卷积核大小均为3x3。该模型以三个全连接 (FC) 层结束,每个层有 64 个神经元,用于执行分类。
Inception V3 [16] 使用一种称为 inception 模块的架构块,它由不同大小(1x1、3x3 和 5x5)的卷积核组成,这些卷积核并联连接。使用不同的内核大小可以识别不同尺度的图像特征。此外,Inception V3 不仅使用一个分类器,而是使用两个分类器,第二个分类器是辅助分类器,用作正则化器。该模型的主要优势之一是,即使它有 42 层,它也由大约 2300 万个参数组成,因此训练该网络的计算成本也低于重新训练 VGG-16 所需的计算成本。
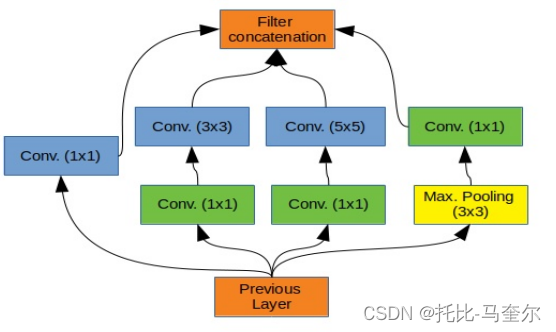
放置在 3x3 和 5x5 之前的 1x1 内核用于降低特征图的维数。
3.2 迁移学习
执行迁移学习有不同的方法:微调和特征提取技术。
第一个是重新调整新训练数据的新分布的权重,即通过在新数据集上以较低的学习率训练几个epoch来调整CNN的权重。通常,仅重新训练最后一层的权重。VGG 16 和 Inception V3 都在 ImageNet1 上进行了预训练,该数据集包含属于 1000 个类别的超过 1400 万张图像。
第二个是指使用整个网络作为特征标识符,然后在另一个分类器中利用从网络获得的高级特征。
微调策略是通过替换由2个神经元(一个用于良性类,另一个用于恶性类)组成的最后一个全连接层来执行,然后对网络中不同数量的层进行微调。选择进行微调的层是每个网络的最后一层到最后 3 层。
在特征提取方法中,添加并训练了一个额外的分类器,该分类器由全局平均池化层(具有修正线性单元(ReLU)激活函数的全连接层)组成。最后,一个具有 softmax 激活函数和 2 个神经元的全连接层。
4. 结果
4.1 数据集
第一个数据集由 250 个乳腺肿瘤图像(100 个良性和 150 个恶性)组成,平均大小为 100x75 像素。第二个由平均图像大小为 500x500 像素的 963 个图像组成,在该数据集中,487 个图像对应于良性肿瘤图像,210 个对应于恶性肿瘤图像,266 个图像对应于任何肿瘤。
本工作中使用的数据集分别包含 537 个良性肿瘤和 360 个恶性肿瘤。整个数据集被随机打乱,然后以分层方式分为两个子集,其中 630 个图像用于训练和验证,269 个图像用于测试。
在网络训练过程中,应用了小批量梯度下降法和Adam优化算法。在创建训练批次时,图像被“动态”重塑以匹配每个网络输入的大小,对于 VGG-16 为 224x224 像素,对于 Inception V3 为 299x299 像素。
4.2 训练设置
训练以 0.001 的初始学习率进行。对于 Inception V3 和 VGG-16,添加的全连接 (FC) 层的输出大小分别为 1024 和 512。使用的小批量大小为 50 张图像。
4.3 性能指标
为了评估所提出的 CNN,计算了受试者工作特征 (ROC) 曲线下的面积 (AUC)。
准确度 (ACC) 计算如下: 其中 TP 和 TN 分别为正确分类的恶性 BUS 图像的数量,FN 和 FP 为错误分类的恶性 BUS 图像的数量。

![[算法] 优先算法(三):滑动窗口(上)](https://img-blog.csdnimg.cn/direct/e0d3ec96d2184852a603e610ac17d3ca.jpeg#pic_center)