目录
导入相关Java库
Java读取PDF表格数据并保存到TXT
Java读取PDF表格数据并保存到Excel
在日常工作中,我们经常需要处理来自各种来源的数据。其中,PDF 文件是常见的数据来源之一。这类文件通常包含丰富的信息,其中可能包含重要的表格数据。如何快速高效地提取这些表格数据并保存到常用的文件格式, 已成为一个常见的需求。本文将探讨如何通过Java编程方式实现读取PDF表格数据并保存到TXT和Excel。
- Java读取PDF表格数据并保存到TXT
- Java读取PDF表格数据并保存到Excel
导入相关Java库
要在Java应用程序中读取PDF表格数据并保存到TXT和Excel,首先要选择合适的库。Spire.PDF for Java库提供了PDF解析功能,Spire.XLS for Java库提供了生成Excel文件的功能。在编写代码前,确保你的Java开发环境中已经导入了这两个库。
Spire.PDF for Java依赖:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.4.9</version>
</dependency>
</dependencies>
Spire.XLS for Java依赖:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>14.5.1</version>
</dependency>
</dependencies>
Java读取PDF表格数据并保存到TXT
从PDF文档中读取表格数据,主要用到Spire.PDF中的两个方法:PdfTableExtractor.extractTable(pageIndex)和PdfTable.getText(rowIndex, columnIndex)。前者用于检索并提取PDF页面上的表格,后者用于获取表格单元格中的数据。
主要步骤如下:
- 创建 PdfDocument 类的对象,然后使用 PdfDocument.loadFromFile() 方法加载 PDF 文档。
- 创建 StringBuilder类的对象,用于存储提取的表格数据。
- 创建PdfTableExtractor 类的对象。
- 循环遍历 PDF 页面,使用PdfTableExtractor.extractTable()方法获取页面中的表格。
- 循环遍历获取的表格。
- 获取表格的行数和列数,然后通过 PdfTable.getText() 方法获取表格单元格中的文本并将其添加到StringBuilder。
- 将StringBuilder的内容写入 txt 文件。
完整代码:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTableDataToTxt {
public static void main(String[] args) throws IOException {
//实例化PdfDocument类的对象
PdfDocument pdf = new PdfDocument();
//加载PDF文档
pdf.loadFromFile("表格1.pdf");
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//创建PdfTableExtractor类的对象
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//遍历PDF每一页
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
//提取页面中的表格存入PdfTable[]数组
PdfTable[] tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
//遍历表格
for (PdfTable table : tableLists)
{
int row = table.getRowCount();//获取表格行数
int column = table.getColumnCount();//获取表格列数
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//获取表格单元格中的文本内容
String text = table.getText(i, j);
//将获取的文本写入StringBuilder容器
builder.append(text + " ");
}
builder.append("\r\n");
}
builder.append("\r\n");
}
}
}
//将StringBuilder的内容写入txt文档
FileWriter fileWriter = new FileWriter("表格.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
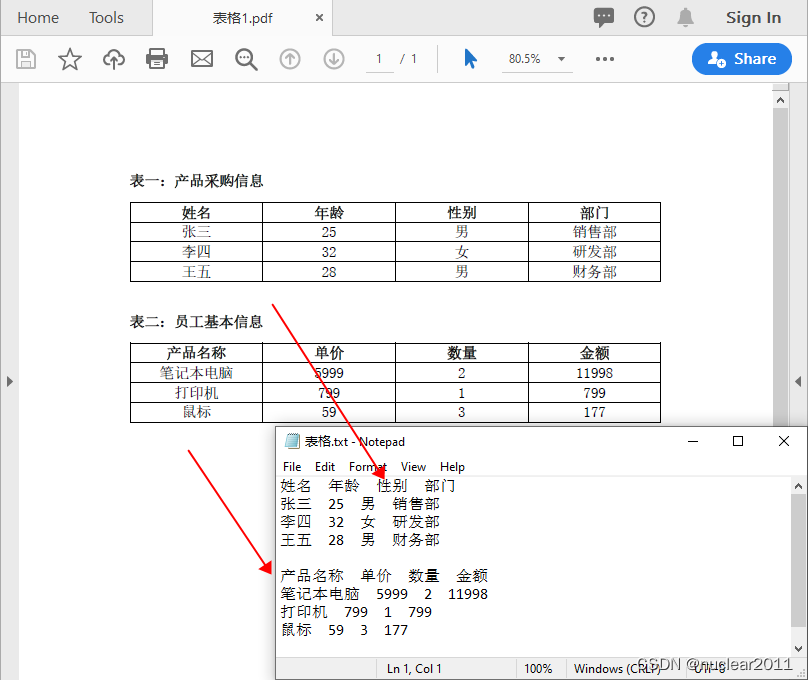
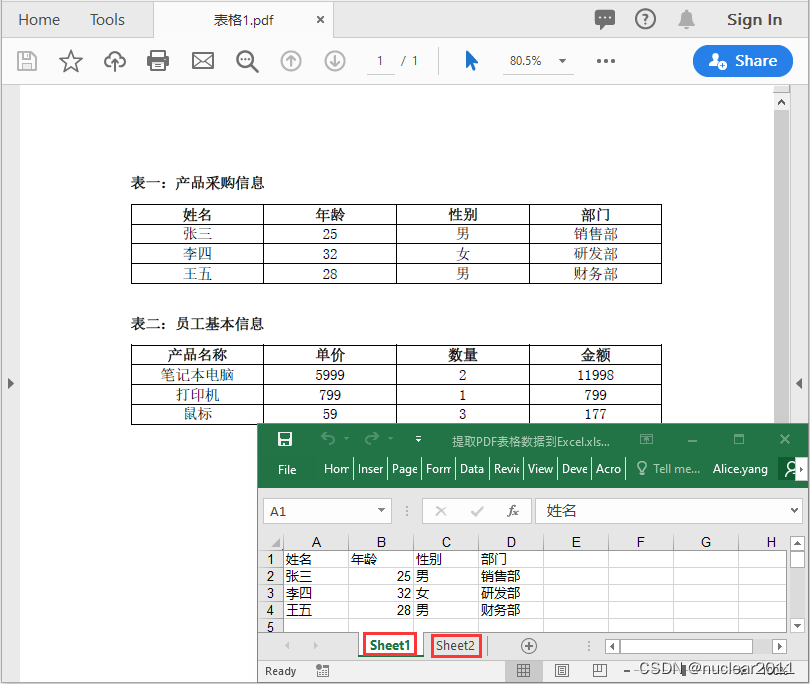
Java读取PDF表格数据并保存到Excel
获取PDF表格单元格中的数据后,可以使用Spire.XLS提供的Worksheet.get(rowIndex, columnIndex).setValue()方法将它们逐一写入到Excel表格的单元格中,然后使用Worbook.saveToFile(fileName, fileFormat)方法将结果保存为Excel文件。
主要步骤如下:
- 创建 PdfDocument 类的对象,然后使用 PdfDocument.loadFromFile() 方法加载 PDF 文档。
- 创建Workbook类的对象,然后使用Workbook.getWorksheets().clear()方法清除默认的工作表。
- 创建PdfTableExtractor 类的对象。
- 循环遍历 PDF 页面,使用PdfTableExtractor.extractTable(pageIndex)方法获取页面中的表格。
- 循环遍历获取的表格。
- 使用Workbook.getWorksheets().add()方法向Workbook对象添加一个工作表。
- 获取表格的行数和列数,然后通过 PdfTable.getText() 方法获取表格单元格中的文本。
- 使用Worksheet.get(rowIndex, columnIndex).setValue()方法将获取的文本写入工作表的单元格。
- 使用Worbook.saveToFile(fileName, fileFormat)方法将结果Workbook保存为Excel文件。
完整代码:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractTableDataToExcel {
public static void main(String[] args) {
//实例化PdfDocument类的对象
PdfDocument doc = new PdfDocument();
//加载PDF文档
doc.loadFromFile("表格1.pdf");
//实例化Workbook类的对象
Workbook workbook = new Workbook();
//清除默认工作表
workbook.getWorksheets().clear();
//实例化PdfTableExtractor类的对象
PdfTableExtractor extractor = new PdfTableExtractor(doc);
int sheetNumber = 1;
//遍历PDF页面
for (int pageIndex = 0; pageIndex < doc.getPages().getCount(); pageIndex++) {
//提取页面中的表格存入PdfTable[]数组
PdfTable[] tableList = extractor.extractTable(pageIndex);
if (tableList != null && tableList.length > 0) {
//遍历表格
for (PdfTable table : tableList) {
//添加工作表
Worksheet sheet = workbook.getWorksheets().add("Sheet" + sheetNumber);
//获取表格的行数和列数
int row = table.getRowCount();
int column = table.getColumnCount();
//遍历行和列
for (int i = 0; i < row; i++) {
for (int j = 0; j < column; j++) {
//获取表格单元格中的文本内容
String text = table.getText(i, j);
//将获取的文本写入Excel工作表
sheet.get(i + 1, j + 1).setValue(text);
}
}
sheetNumber++;
}
}
}
//将工作簿保存为Excel文件
workbook.saveToFile("提取PDF表格数据到Excel.xlsx", FileFormat.Version2013);
}
}
本文介绍了如何使用Java获取PDF表格数据并保存到TXT和Excel文件。你可以根据实际场景将获取的数据写入到其他文件格式,如CSV,Word表格等。如需了解Spire.PDF for Java和Spire.XLS for Java的更多功能,请自行查看Spire.PDF for Java文档和Spire.XLS for Java文档。