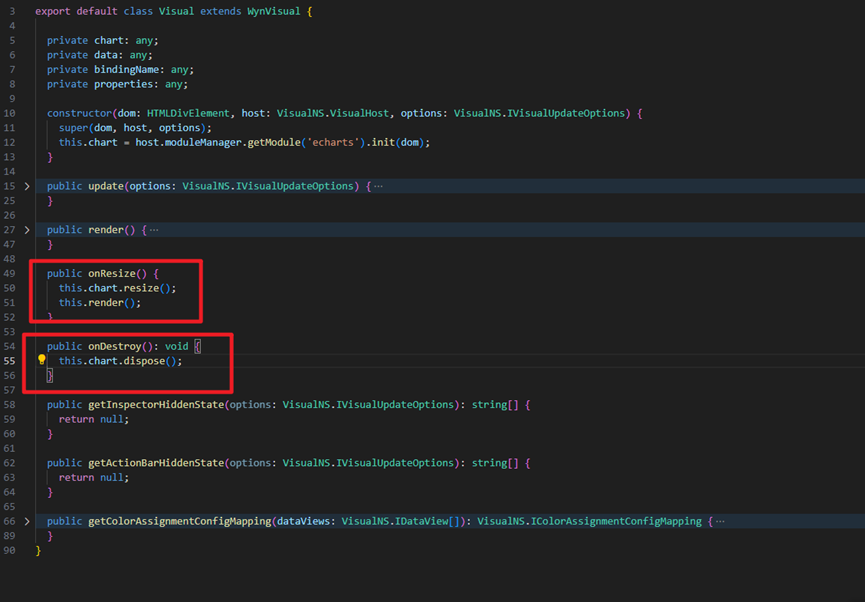
当我们在设计系统对象关系时,有时候会碰到这样一种场景,一个对象中包含了另一组对象,两者构成一种”部分-整体”的关联关系。
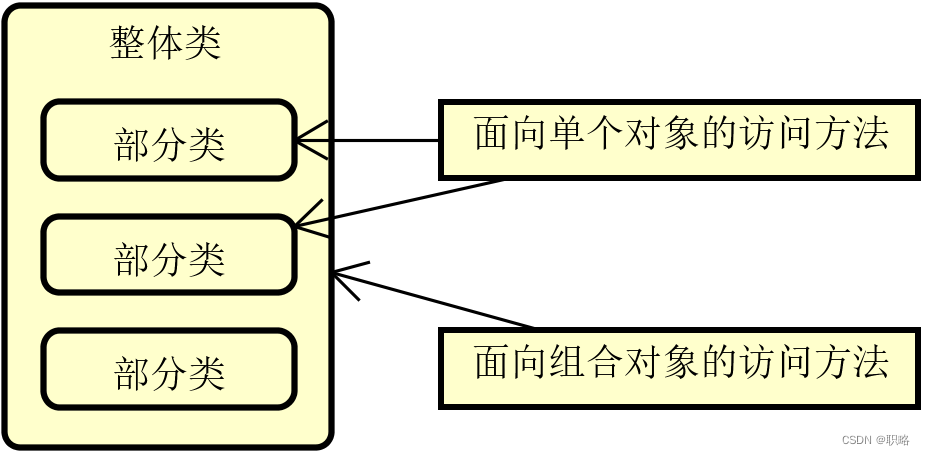
正如上图中所展示的,当我们面对这样一种对象关系时,通常都需要分别构建单独的访问方式,一种面向单个对象,另一种则面向组合对象。显然,这样的实现方法存在一些缺陷,如果从部分到整体的关联关系发生了变化,那么我们可能需要同时调整这两种访问方式,从而对系统的代码结构造成比较大的影响。那么,有没有更好的处理方式呢?今天要介绍的组合设计模式就是专门用来应对这种场景的。
组合设计模式的概念和简单示例
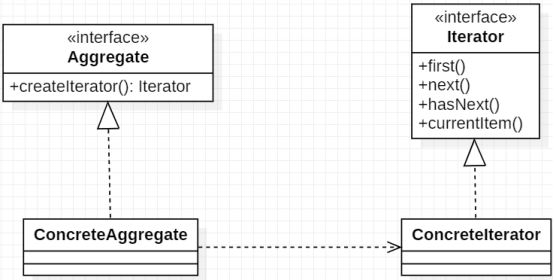
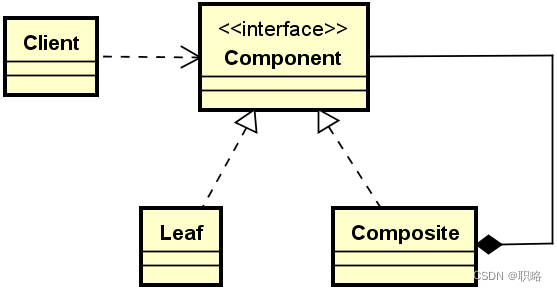
简单来讲,组合设计模式的核心思想是只提供一种访问方式,这种访问方式可以同时用来完成对上图中单个对象和组合对象的有效处理。在具体实现方法上,组合模式将代表“部分”组织结构和“整体”组织结构的所有对象都组合到一种树形结构中,其基本的组成结构如下所示。
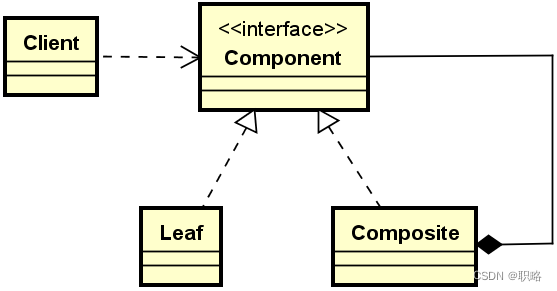
可以看到,在组合模式中首先存在一个Component接口,所有的对象都必须实现这个接口。同时,该接口也面向Client暴露了统一访问入口。因此,Client只需要实现一种访问方式即可。然后,这里的Leaf代表“部分”,而“Component”代表“整体”,它们都实现了Component接口。而Composite中还管理了一组子Component,所以具备一种树状结构。
明白了组合模式的基本结构,接下来我们来给出对应的案例代码。我们知道任何一个语句(Sentence)都有单词(Word)组成,而单词又由字母(Letter)组成。这三者之间就是一种典型的”部分-整体”的关联关系。
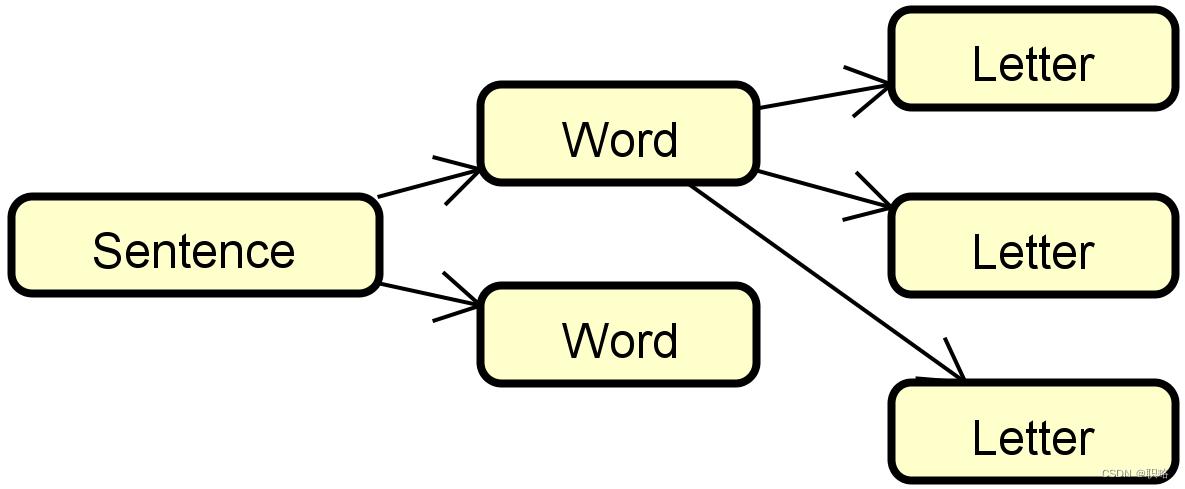
现在,让我们来定义一个组合类,我们直接将该类命名为Composite。
public abstract class Composite {
private final List<Composite> children = new ArrayList<>();
public void add(Composite composite) {
children.add(composite);
}
public int count() {
return children.size();
}
protected void printThisBefore() {
}
protected void printThisAfter() {
}
public void print() {
printThisBefore();
children.forEach(Composite::print);
printThisAfter();
}
}
有了Composite类,接下来就可以构建各种子Composite类,例如如下所示的代表字母的Letter类。
public class Letter extends Composite {
private final char character;
public Letter(char character) {
super();
this.character = character;
}
@Override
protected void printThisBefore() {
System.out.print(character);
}
}
在Letter类的基础上,我们可以进一步构建代表单词的Word类。
public class Word extends Composite {
public Word(List<Letter> letters) {
letters.forEach(this::add);
}
public Word(char... letters) {
for (char letter : letters) {
this.add(new Letter(letter));
}
}
@Override
protected void printThisBefore() {
System.out.print(" ");
}
}
基于Word类,代表语句的Sentence类实现也非常简单。
public class Sentence extends Composite {
public Sentence(List<Word> words) {
words.forEach(this::add);
}
@Override
protected void printThisAfter() {
System.out.print(".\n");
}
}
最后,我们可以通过如下方式构建一个Sentence,并调用它的print方法来实现对语句的打印。
var words = List.of(
new Word('H', 'e', 'l', 'l', 'o'),
new Word('G', 'e', 'e', 'k', 'e'),
new Word('T', 'i', 'm', 'e')
);
Sentence sentence = new Sentence(words);
Sentence.print();
上述代码的执行结果就是下面这句话。
Hello Geek Time
组合设计模式在Mybatis中的应用
接下来,我们来分析组合设计模式的在主流开源框架中的应用。相信使用过Mybatis的同学都知道我们可以使用它所提供的各种标签对SQL语句进行动态组合,这些标签常见的包含if、choose、when、otherwise、trim、where、set、foreach等。虽然并不建议在SQL级别添加过于复杂的逻辑判断,但面对一些特定场景时,Mybatis的动态SQL机制确实能够提高开发效率。
一个采用Mybatis动态SQL的示例如下所示,可以看到这里使用了<where>和<if>这两个标签,同时在<if>标签中使用test断言进行非空校验。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
我们可以想象一下如何实现对这段SQL的解析,显然,解析过程并不简单。如果对每个标签都进行硬编码处理,那边处理流程和代码逻辑会很混乱且不易维护。为此,Mybatis就引入了组合设计模式。针对前面所展示的各个动态SQL节点配置,Mybatis专门设计了一个SqlNode接口,通过这个接口我们可以构建一种树形结构,该接口定义如下。
public interface SqlNode {
boolean apply(DynamicContext context);
}
可以看到,在SqlNode接口中只定义了一个apply方法,而该方法中传入的是一个DynamicContext对象。从命名上讲,DynamicContext代表一种动态上下文组件,保存着所有动态SQL的解析结果。当apply方法被调用时,它会根据该SQLNode中所持有的动态SQL节点配置信息进行递归解析。当这些动态SQL节点被解析完毕之后,我们就可以从DynamicContext中获取一条动态生成的目标SQL语句。
作为抽象组件,SqlNode拥有丰富的类层结构。
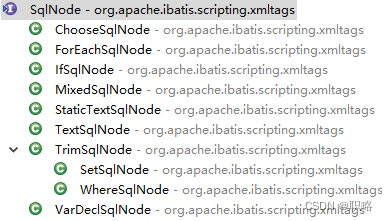
上图中,我们先来看一下MixedSqlNode类的代码。
public class MixedSqlNode implements SqlNode {
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
contents.forEach(node -> node.apply(context));
return true;
}
}
可以看到,在MixedSqlNode中保存着一个SqlNode列表,所以它是一种Composite组件。在MixedSqlNode的apply方法中,通过一个for循环对SqlNode列表中的所有节点信息进行遍历,并依次调用它们的apply方法。显然,这是一种递归操作。
然后我们再来找一个典型的SqlNode实现,这里选择IfSqlNode。
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator;
private final String test;
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
@Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
}
IfSqlNode的作用就是解析动态SQL节点中的<if>标签,这里用到了一个工具类ExpressionEvaluator,通过该类的evaluateBoolean方法来对配置节点中的test表达式进行评估。如果test表达式返回的为true,那么就执行子节点的apply方法,完成对动态SQL的填充。
Mybatis中的其他SqlNode子类的结构与IfSqlNode类似,结合日常的使用方法,各自功能也比较明确。最后我们来看一下DynamicSqlSource类,在组合设计模式中,该类扮演了客户端的角色。
public class DynamicSqlSource implements SqlSource {
private final Configuration configuration;
private final SqlNode rootSqlNode;
public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) {
this.configuration = configuration;
this.rootSqlNode = rootSqlNode;
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
…
}
}
可以看到,DynamicSqlSource依赖于SqlNode,通过构建DynamicContext并应用SqlNode的apply方法完成动态SQL的解析过程。
关于Mybatis中组合设计模式的应用就介绍完了,我们来做一个总结。我们看到SqlNode 接口有多个实现类,每个实现类用来处理对应的一个动态SQL节点。结合组合设计模式的基本结构图,可以认为 SqlNode 相当于是Component接口,MixedSqlNode 相当于是Composite组件,而其它SqlNode的子类则是Leaf组件,最后DynamicSqlSource则是整个模式的Client。整个组合模式的类结构如下图所示。
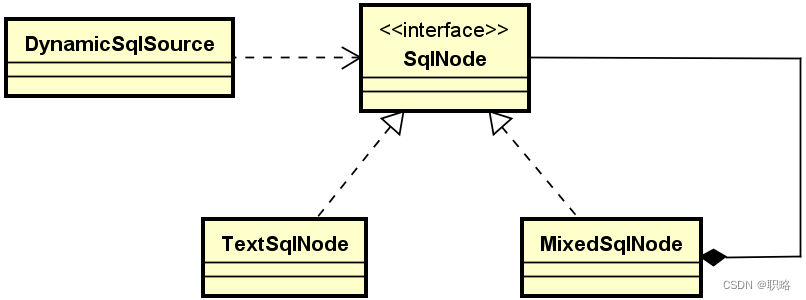
对于系统中具有“部分-整体”结构的场景而言,组合模式能够帮助我们构建优雅的递归操作。现实中有很多对象之间的复杂关联关系都可以通过组合模式来进行简化,从而实现统一的对象访问方式。
组合模式在主流的开源框架中应用也非常广泛,例如Mybatis在解析动态SQL语句时,就用到了组合模式来解析树状的SQL节点。在今天的内容中,我们对组合模式的基本概念以及在Mybatis中的应用方式进行了详细的展开。
实现组合模式的前提是需要我们合理梳理对象之间存在的“部分-整体”关联关系,有时候这种关联关系可能有很多层,所以表现为是一种递归结构。一旦构建了符合组合模式的代码框架结构,那么通过构建各种子Composite类,我们就可以为系统添加丰富的新功能。