1.前言
在学习这篇文章之前,请大家先学习堆这一数据结构中堆的概念,向下调整算法,向下调整建堆。
有关堆的实现方式请参考:堆的实现
堆排序就是利用堆里面学习过的知识点进行排序,如何进行排序呢?
2.堆排序原理剖析
现在我们要对一个无序的数组升序排列,那么我们应该利用大堆还是小堆进行排序呢?
这时我们大家就会想,既然是升序排列,那么我们建一个小堆不就可以了吗,刚好小堆的第一个元素是最小的元素。
- 建小堆可行性分析
好,那么我们现在来思考一下这种方法的可行性。
现在我们给出如下一个小堆。
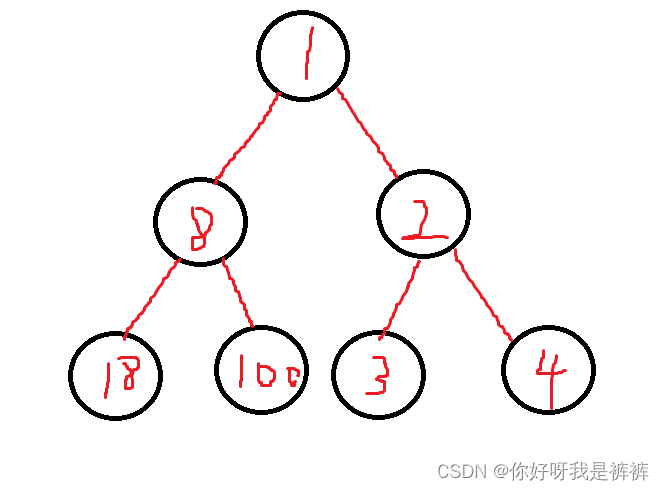
现在我们可以确保根节点是最小的了,下面我就就要从第二层选最小的数了,这里我们选到了右子树2,但是根结点的左右两棵子树之间是没有联系的,我们应该如何判决左子树8和右子树2的子树们的关系呢?这时就需要我们遍历才能确定大小关系了,而后续的每一次比较都需要这么一个过程。时间复杂度就变的相当高了。若如此建堆,堆排序就是一个理解起来困难而时间复杂度又高的离谱的排序方法了。
- 建大堆可行性分析
既然建小堆不可以,那么,建大堆应该如何排序呢?又有没有优势呢?
首先,我们可以确定的一点是,大堆的堆顶一定是一整个堆中最大的元素。
但是我们排的是升序,最大的一个应该在堆的最后面才对,那么我们直接交换堆顶元素和堆尾元素的位置不就可以让堆的最后一个元素是最大的了嘛。
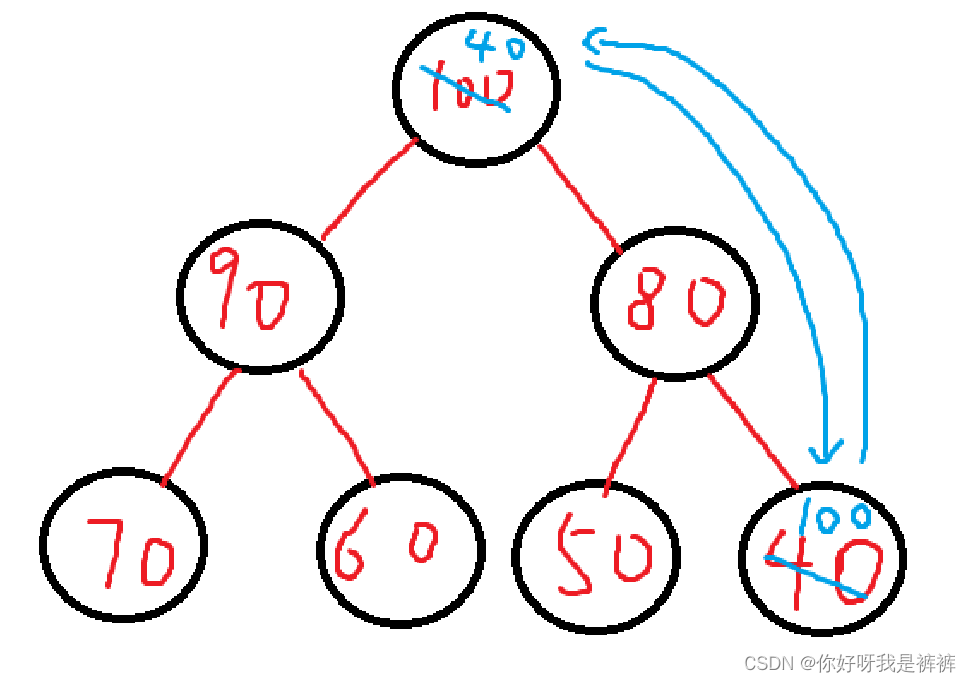
这时,新的问题是,我们的交换破坏了堆原来的结构,那么这时我们需要做的工作则是恢复堆原来的结构。这不就是我们的向下调整算法所能做的事嘛,因此我们每次交换了之后用一个向下调整算法即可。
3.堆排序代码详细阐述
我们首先完成第一次交换和向下调整:
int end=n-1;//n是数组长度
swap(&arr[0], &arr[end]);
AdjustDown(a, end, 0);下面我们要做的事情即将数组内所有的元素都按照这种方式进行排序,这就需要我们将上述代码嵌套进一个循环内,而由于此时最后一个元素已经是最大的了,因此我们需要剔除掉这个元素,在这里我们直接让end-1即可。
while (end>0)
{
swap(&arr[0], &arr[end]);
AdjustDown(a, end, 0);
end--;
}上述代码即可完成一次堆排序。
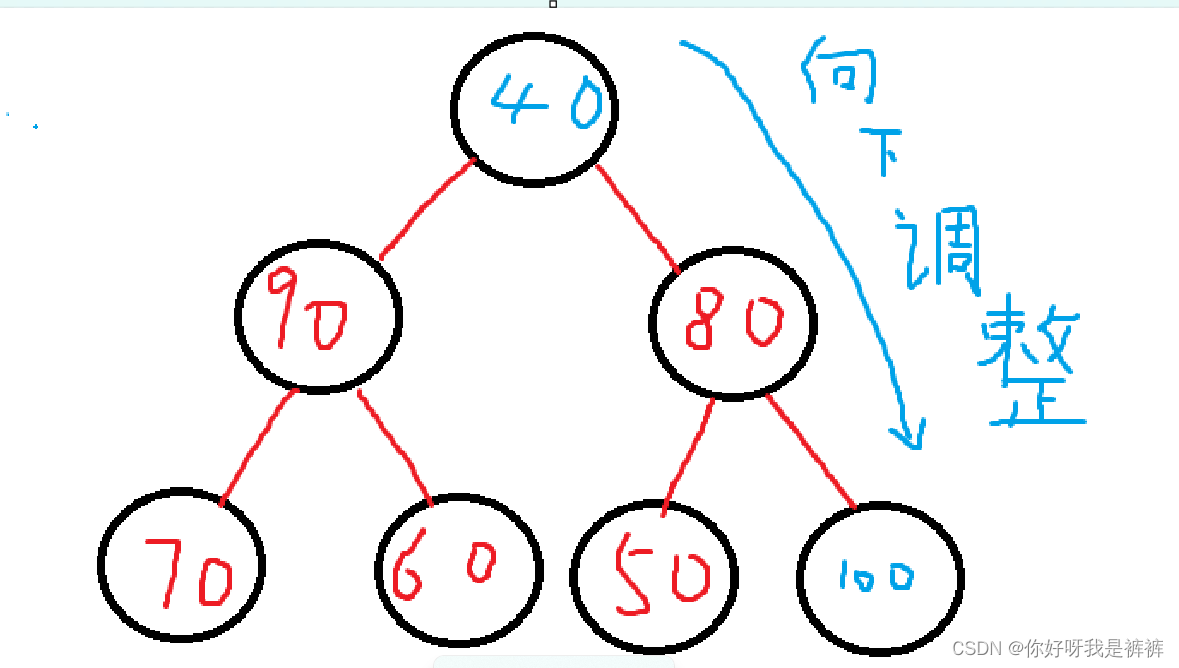
而由于我们传进来的数组的元素是无序的,因此我们首先需要将其调整为堆,之后再进行上述操作即可完成堆排序。
void AdjustDown(HPDataType * a, int n, int parent)
{
// 先假设左孩子大
int child = parent * 2 + 1;
while (child < n)// 当child>=n时就说明child已经到达叶子节点了
{
// 先找出左右孩子节点中大的那个
if (child + 1 < n && a[child + 1] > a[child])// 说明假设错误,交换小的那个子节点
{
child++;
}
// 和父亲节点进行比较
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
// 降序,建小堆
// 升序,建大堆
for (int parent = (n - 1 - 1) / 2; parent > 0; parent--)
{
AdjustDown(a, n, parent);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}4.堆排序时间复杂度分析
初始化堆的时间复杂度为O(n)
n-1次删除操作的时间复杂度为O(nlogn)
所以总操作时间复杂度为O(nlogn)
由于每删除一个元素,总元素减一。
共有n-1次删除操作,操作时间应该为log(n)+log(n-1)+…+log(3)+log(2) = log(n!)。
又由于(n/2)^(n/2) ≤ n!≤ n ^ n,即 1/4*nlog(n) ≤ n! ≤ nlogn。常数可舍去,时间复杂度为O(nlogn)