目录
写在前面
一、克隆或下载项目
二、下载预训练模型
三、创建环境
四、安装依赖
五、启动项目
六、解决报错
1.预训练模型下不来
2.TiffWriter.write() got an unexpected keyword argument 'fps'
3.安装ffmpeg
4.No module named 'scripts'
七、测试
写在前面
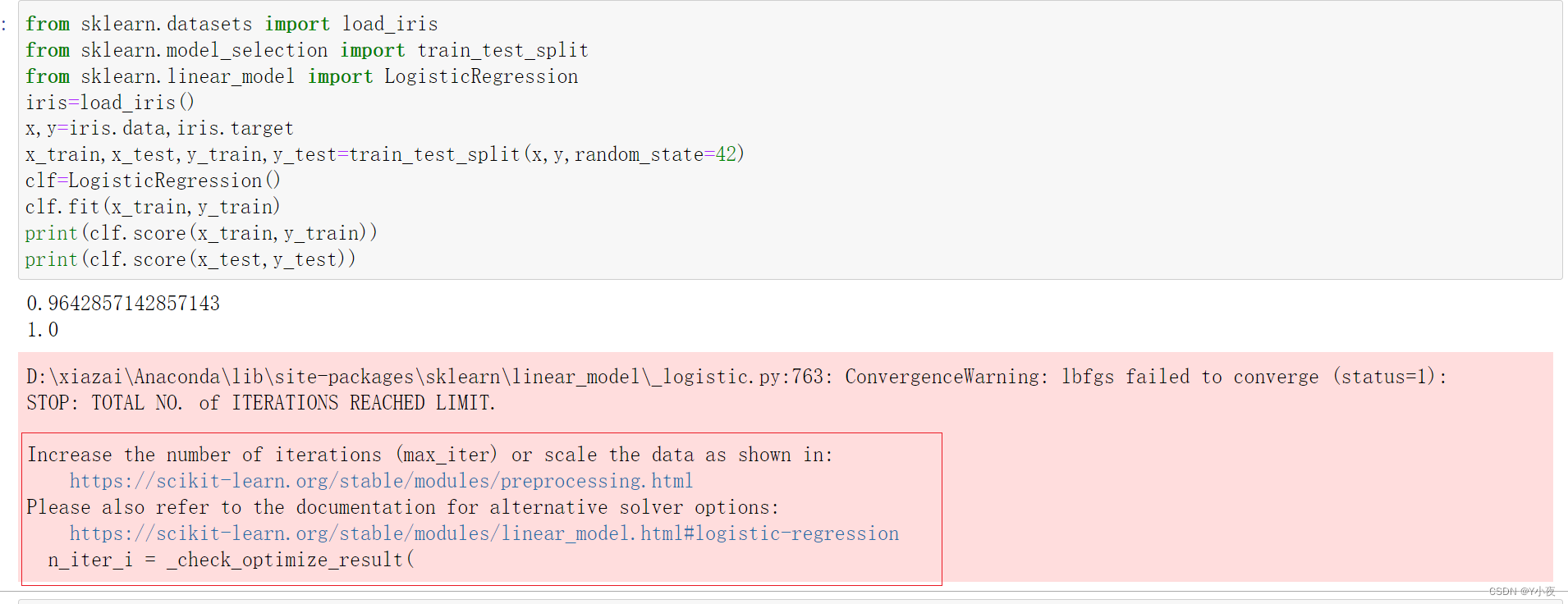
Stable Video Diffusion可以将图片变成几秒的视频,从名字就能看出来它使用了Stable Diffusion。现在这个项目还处在早期实验阶段,预训练模型也是效果感人,不过可以试着自己训练。这里先只介绍SVD的安装,目标是项目跑起来,能把一张图片变成3秒左右的视频,下面开始。

一、克隆或下载项目
比如项目被放在/mnt/generative-models-mian/目录中,项目地址如下:
https://github.com/Stability-AI/generative-models二、下载预训练模型
可用的有如下四个:
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/blob/main/svd.safetensors
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/blob/main/svd_image_decoder.safetensors
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/svd_xt.safetensors
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/svd_xt_image_decoder.safetensors
网盘地址:
https://pan.baidu.com/s/1vdBDgPl254FOxZP2LBsHGg?pwd=iyme
放在checkpoints/目录下:

三、创建环境
创建一个独立的环境,比如叫img2video:
conda create --name img2video python=3.10四、安装依赖
conda activate img2video
cd /mnt/generative-models-main
pip3 install -r requirements/pt2.txt如果因为网络原因安装clip报错,就需要删掉pt2.txt中的clip这一行。
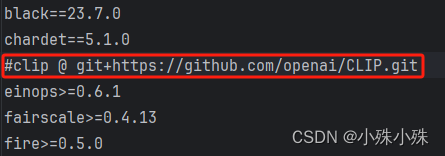
手动下载CLIP项目,然后在CLIP中执行命令安装clip:
python setup.py install五、启动项目
conda activate img2video
cd generative-models-main
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 7862然后访问地址http://[ip]:7862/就可以访问项目了,接下来选一个模型并点击Load Model,就会加载模型了。

六、解决报错
如果没有报错,恭喜你可以跳过这步。常见报错有下面几个:
1.预训练模型下不来

如果因为网络问题模型下载不下来,报上面这个错,就需要我们手动下载模型了,模型文件有两个:
(1)ViT-L-14.pt
官方地址:https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt
网盘地址:https://pan.baidu.com/s/10bSIsPEpC2SFqSxH87unIg?pwd=jsv9
放在:/root/.cache/clip/ViT-L-14.pt
(2)open_clip_pytorch_model.bin
官方地址:https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/blob/main/open_clip_pytorch_model.bin
网盘地址:https://pan.baidu.com/s/1_DDLVjbUnYxFTrrJaRQGCA?pwd=mqfl
放在:/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K/open_clip_pytorch_model.bin
如果还报上面的超时错误,就需要改改代码了。因为open_clip每次都会重新下载open_clip_pytorch_model.bin文件。根据报错,修改/root/anaconda3/envs/img2video/lib/python3.10/site-packages/open_clip/factory.py文件的create_model方法,把模型文件地址写死,虽然不优雅,但是能work:

if pretrained:
checkpoint_path = ''
pretrained_cfg = get_pretrained_cfg(model_name, pretrained)
if pretrained_cfg:
# TODO 解决模型下载不下来的问题
# checkpoint_path = download_pretrained(pretrained_cfg, cache_dir=cache_dir)
checkpoint_path = "/root/.cache/huggingface/hub/models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K/open_clip_pytorch_model.bin"
preprocess_cfg = merge_preprocess_dict(preprocess_cfg, pretrained_cfg)
elif os.path.exists(pretrained):
checkpoint_path = pretrained2.TiffWriter.write() got an unexpected keyword argument 'fps'
这是因为imageio版本问题:
pip install imageio==2.19.33.安装ffmpeg
报找不到imageio-ffmpeg
pip install imageio-ffmpeg==0.4.74.No module named 'scripts'
报ModuleNotFoundError: No module named 'scripts',需要添加环境变量
RUN echo 'export PYTHONPATH=/mnt/generative-models-main:$PYTHONPATH' >> /root/.bashrc
source /root/.bashrc
七、测试
如果看到这个页面就证明成功了,下面的报错不用过管它,这是因为没上传图片
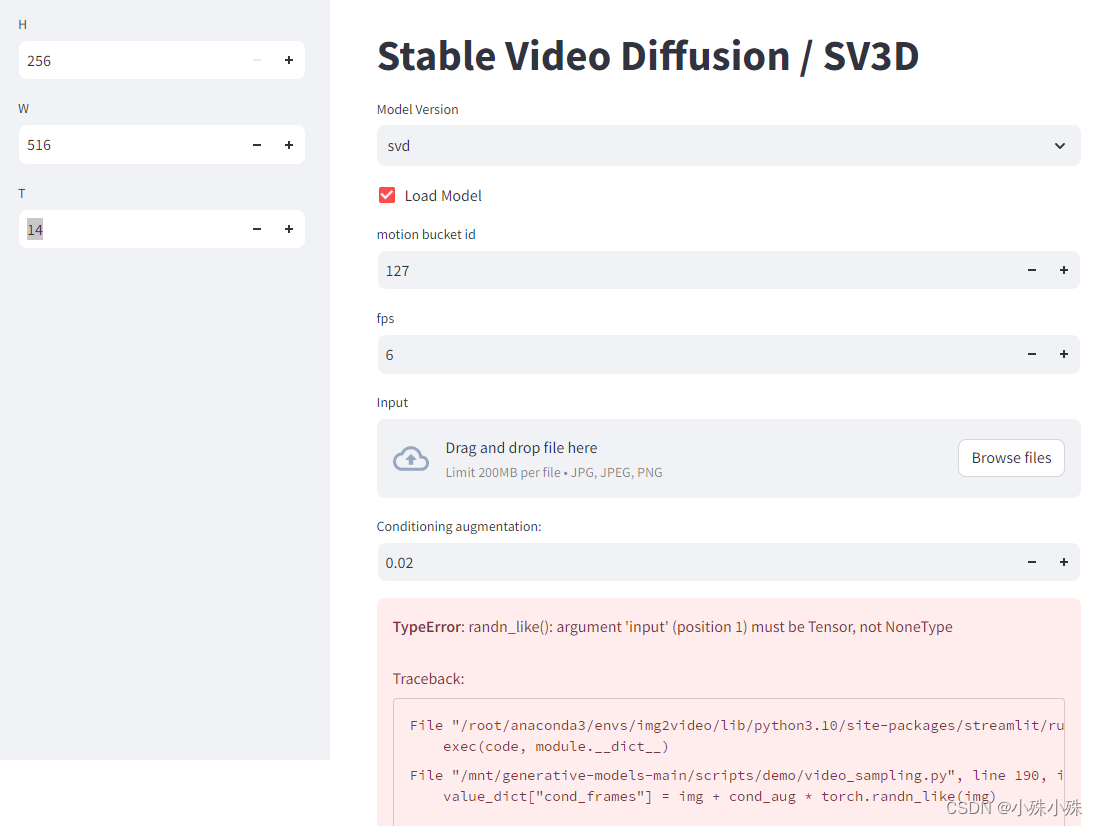
上传图片后,调整参数,下面三个红框分别为视频的高、宽、要生成的总帧数和一次处理多少帧,如果显存小的话可以改小这些参数。点“sample”等待就可以看到结果了。
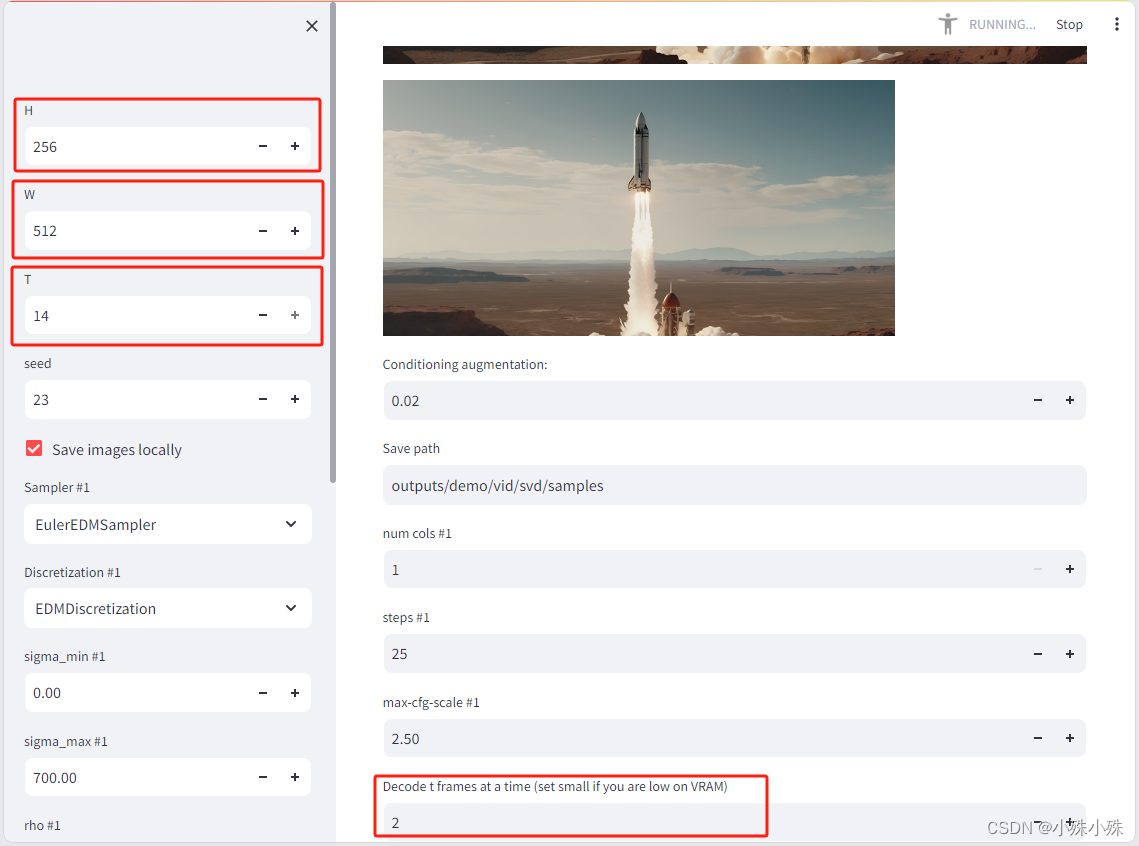
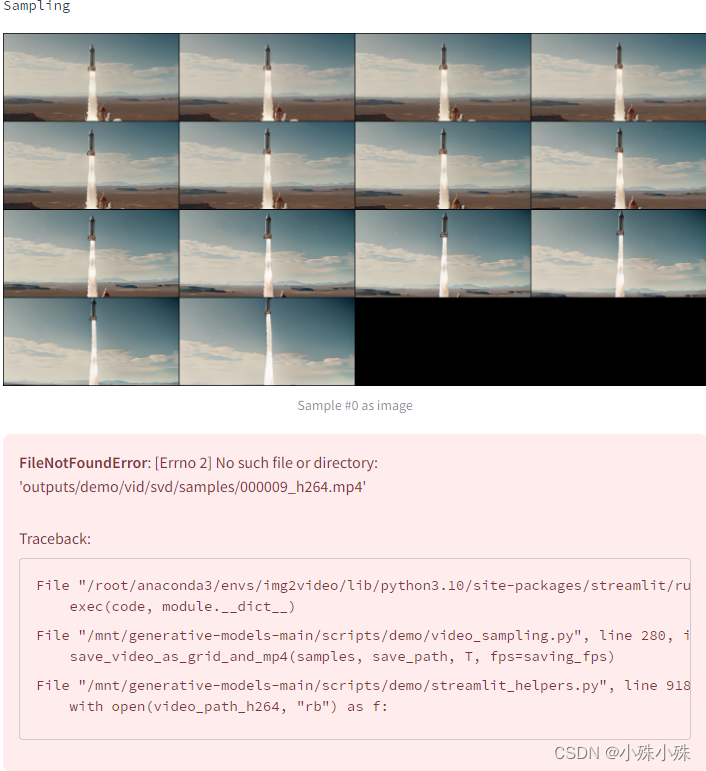
下面的报错其实也不用管,结果是outputs/demo/vid/svd/samples/000009.mp4文件。
ubuntu安装Stable Video Diffusion(SVD)就介绍到这里,关注不迷路(#^.^#)
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信