目标
如何利用pytorch完成学习系统?
理解神经网络(neural networks)和深度学习(deep learning)基础。
需要了解线性代数和概率论数理统计等相关关系,和python编程语言。
讨论+理解
到底什么是human intelligence(人工智能)?
大家可以思考平时中午同学们去吃饭,去哪吃?吃什么?或者说今天穿什么衣服?
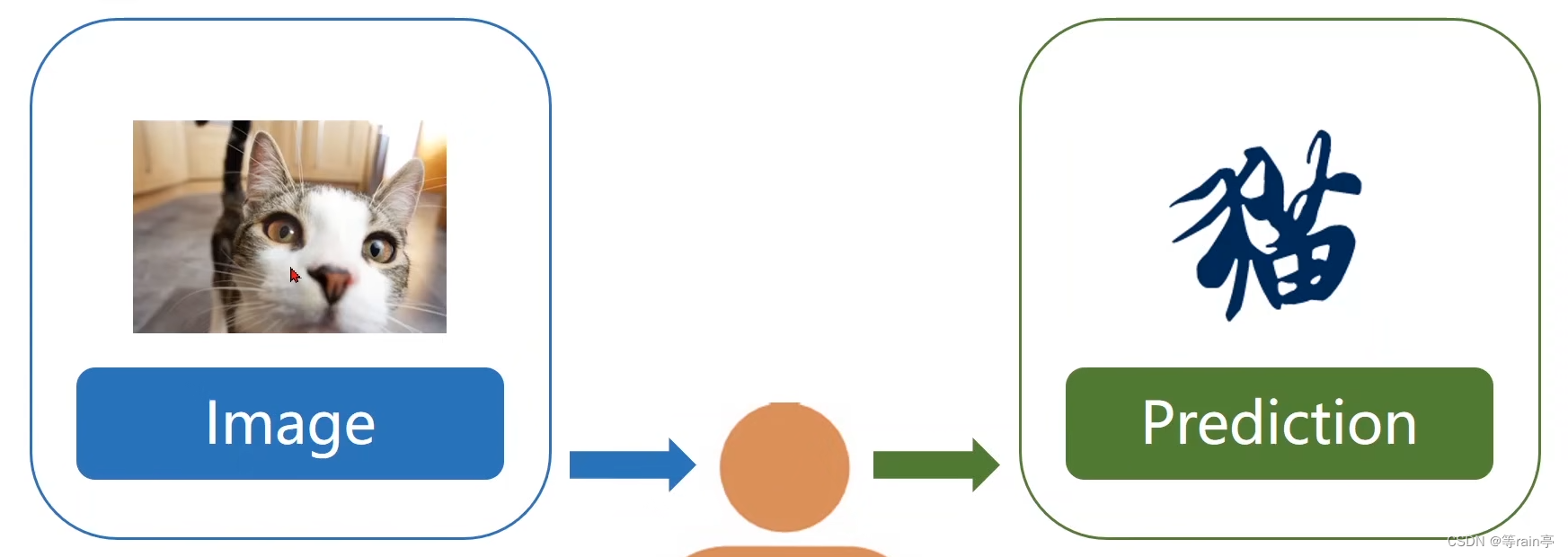
我们可能会考虑到时间问题(比如下午还有课),或者经济问题(月末可能就得在食堂将就将就了),也可能有很多其他干扰因素(不同菜的口味,或者最近身体状况等的影响),综合所有的问题,我们会最终选择一个答案。其实这个过程就是一个人工智能的算法,通过现有的条件,推理出最终的结果。大家看下面两张图,看见一张图,我们可以推测它是只猫,这就是把视觉信息转化为抽象的概念。或者把自然语言文本转化为抽象的概念(那关于为什么说数字是个抽象的概念,大家感兴趣可以自己去了解下)。那说了这么多,其实人工智能就是使用算法代替人脑里面进行处理的过程。
 那其实对于我们深度学习的内容基本使用的都是有监督(supervise)学习。有监督学习其实就是我们会有一些打了标签(label)的数据集,我们知道每一个图像的答案,之后通过这些数据对于模型进行训练,最后完成我们的算法。
那其实对于我们深度学习的内容基本使用的都是有监督(supervise)学习。有监督学习其实就是我们会有一些打了标签(label)的数据集,我们知道每一个图像的答案,之后通过这些数据对于模型进行训练,最后完成我们的算法。
此时我们说的machine learning与我们算法课中的算法不太相同。
算法课中的主要的思维想法:穷举法,贪心算法,分治算法,动态规划算法。我们需要对这几种思维方式人工去设计出一套计算过程。
此时我们也发现了,我们刚刚说我们的machine learning是先有了数据集(DataSet),之后从数据集中把我们想要的算法给找出来,但是我们算法课中是需要我们人工去设计一套计算。
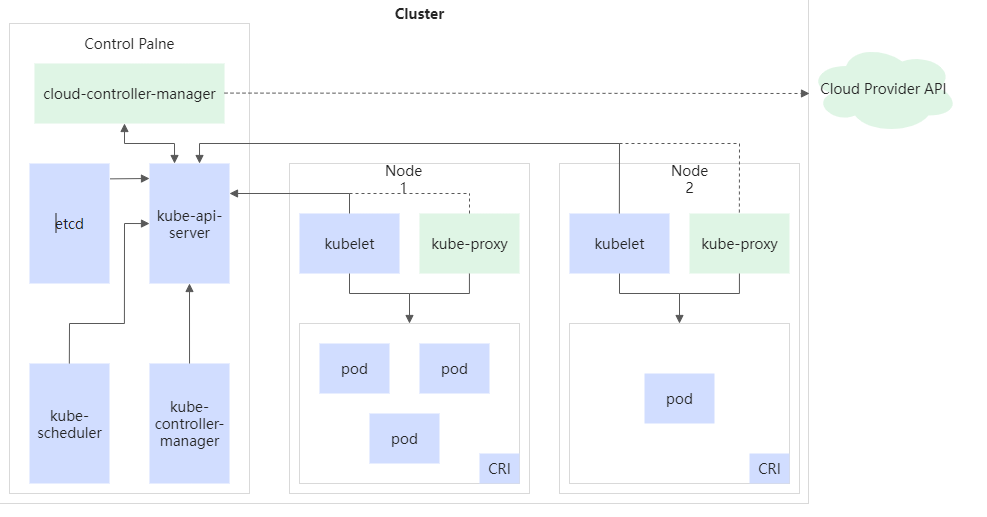
 我们可以看这个人工智能(Ai)其实包括了很多的内容。我们可以看见Machine learning中包含我们将要学习的Deep learnin,当然Deep learning中还包含着很多的不同架构。
我们可以看这个人工智能(Ai)其实包括了很多的内容。我们可以看见Machine learning中包含我们将要学习的Deep learnin,当然Deep learning中还包含着很多的不同架构。
历史的发展
Rule-Base syste
最先出现的是基于规则的的系统(rule-base)。如图就是,我们先得到一些输入,之后手工的去设计设计程序,最后输出结果。(那相信小伙伴也看出,其实设计一个合理且满足需求的程序其实有很大难度,并且为了满足越来越多的需求,会最终导致无法维护的情况)。
Classic Machine learning
经典机器学习,首先也是得到输入,接着需要手工去提取特征(比如说吃饭,我们发现价格和味道对最终的结果有影响,那我们就把这两个特征(feature)提取出来)把这些特征建立成向量或者张量,然后把这个向量和我们的输出之间建立出一个映射的函数。

Representation learning
表示学习,与经典机器学习不同的就是,第二步的特征提取,我们现在不想手工提取了,希望中国feature也可以通过学习学会。

暂停一下下
为什么不管是在经典机器学习还是在表示学习中,都提到了feature这个概念。
我们思考一个问题,对于input中的feature如果越多,是不是就意味着input需要越多。(还是吃饭的例子,如果说价格,味道,时间,距离,心情。都会对我们选择吃什么产生影响,那是不是我们就需要更多的例子input提供作为参考,不然无法通过几次的output就可以训练出我们的模型,就无法准确判断去吃什么这样的output)(现在想,如果只有价格这一个单因素feature,那是不是我只需要几次的训练我就知道有钱的时候吃什么,没钱的时候吃什么。这样得到的结果是不是就很容易出来)。
现在我们会提到一个“维度诅咒”的概念
如果现在只有一个feature,那我就可以在一维的维度下进行采样,如果是10个样本就可以得到结果。那此时如果feature是两个,那就需要在二维下采样,就变成了10*10,100个样本。同理4个feature需要1000个样才能满足我们的大数定律。所以说当feature越多,需要的input也就越多,最终就无法承担(这个地方的input不是简单的一张图就可以,这个需要是我们大过标签的label,这个过程是非常耗时间的,大都会请其他的人来打标签,这样的成本就无法控制了(我们实验室正在面临这样的问题))。
所以此时我们希望feature比如是10维,压缩成3维。就需要用线性或非线性映射。此时就需要我们使用矩阵的知识。
继续
那此时从高维到低维这个过程就是我们的representation,也就是我们表示学习中的一步。其中有一个分支叫manifold(流行),我们称降维过程叫从高维分布中的低维流行。
Deep learning
之前在表示学习中需要训练特征提取器,而现在直接把原始特征拿进来,但是我们休要设计额外的一个层Additional layers来提取特征,然后进入学习器,最后输出。这个学习器通常就是我们说的多层的神经网路。

我们在representation learning中feature特征学习和mapping from feature是分开进行学习的,但是我们的deep learning中的所有训练过程都是统一的(end2end)
 这个是scikit-learn官方提供的流程,都是较为简单的英语,可以跟着他的条件选择合适的方法。
这个是scikit-learn官方提供的流程,都是较为简单的英语,可以跟着他的条件选择合适的方法。
神经网络发展一个重要的算法啊,反向传播
 反向传播的的核心是计算图,就是上面这个。
反向传播的的核心是计算图,就是上面这个。

总结
刚刚上面说的计算图算法,我们不需要自己去实现的。我们通常使用现成的deep learning framework 去进行实现(当然也可以自己去写framework,但是这个比我们写深度神经网络要难)
我们将会用到的deep learning frameworks是pytorch(facebook),当然还有其他的如TensorFlow(Google),还有一个就是已近和pytorch合并的Caffe(facebook),还有如MxNet。
感谢观看!欢迎大家一起学习Pytorch相关知识!!!