线性模型
- 一、模型介绍
- 二、用于回归的线性模型
- 2.1 线性回归(普通最小二乘法)
一、模型介绍
线性模型是在实践中广泛使用的一类模型,该模型利用输入特征的线性函数进行预测。
二、用于回归的线性模型
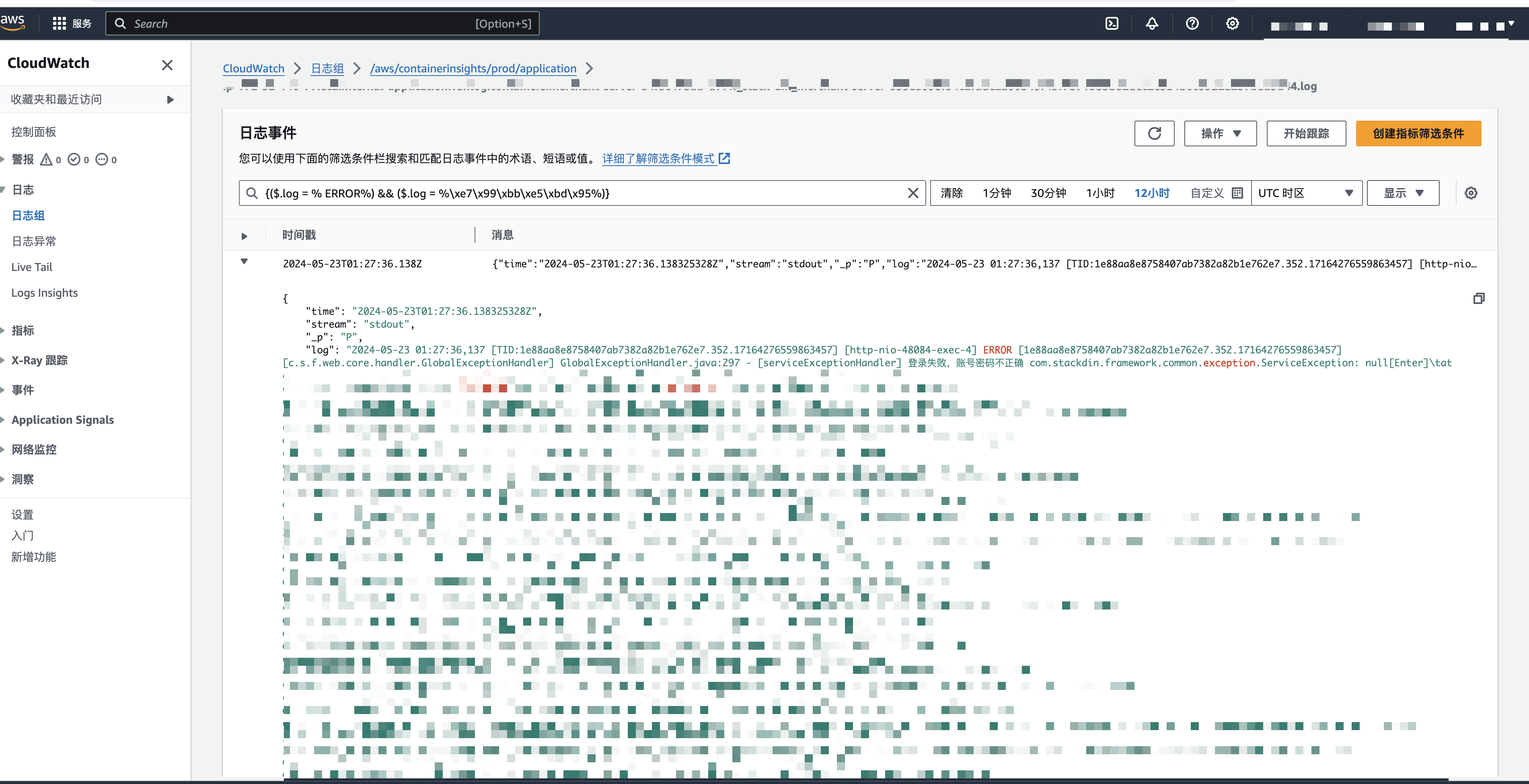
以下代码可以在一维wave数据集上学习参数w和b,w是斜率,b是截距。
import mglearn
mglearn.plots.plot_linear_regression_wave()

我们在图中添加了坐标网格,便于理解直线的含义。w的值是0.39,b的值是-0.03。
用于回归的线性模型可以表示为这样的回归模型:对单一特征的预测结果是一条直线,两个特征时是一个平面,或者在更高维度(即更多特征)时是一个超平面。
对于有多个特征的数据集而言,线性模型可以非常强大。特别地,如果特征数量大于训练数据点的数量,任何目标y都可以(在训练集上)用线性函数完美拟合。
有许多不同的线性回归模型。这些模型之间的区别在于如何从训练数据中学习参数w和b,以及如何控制模型复杂度。下面介绍最常见的线性回归模型。
2.1 线性回归(普通最小二乘法)
线性回归,或者普通最小二乘法(ordinary least squares, OLS),是回归问题最简单也最经典的线性方法。线性回归寻找参数w和b,使得对训练集的预测值与真实的回归目标值y之间的均方误差最小。均方误差是预测值与真实值之差的平方和除以样本数。线性回归没有参数,这是一个优点,但也因此无法控制模型的复杂度。
以下代码可以生成一个简单的线性回归模型:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
“斜率”参数(w,也叫做权重或系数)被保存在coef_属性中,英文单词coef就是属性的意思,而截距(b)或偏移被保存在intercept_属性中,英文单词intercept的意思是拦截、阻截的意思。

intercept_属性是一个浮点数,而coef_属性是一个NumPy数组,每个元素对应一个输入特征。由于wave数据集中只有一个输入特征,所以model.coef_中只有一个元素。
再来看一下训练集和测试集的性能:

R²约为0.66,这个结果不是很好,但我们可以看到,训练集和测试集上的分数非常接近。这说明可能存在欠拟合,而不是过拟合。对于这个一维数据集来说,过拟合的风险很小,因为模型非常简单(或受限)。然而,对于更高维的数据集(即有大量特征的数据集),线性模型将变得更加强大,过拟合的可能性也会变大。我们来看一下LinearRegression在更复杂的数据集上的表现,比如波士顿房价数据集,这个数据集有506个样本和105个导出特征,代码如下:
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = LinearRegression().fit(X_train, y_train)

线性回归模型在训练集上的预测非常准确,但测试集上的R²明显低一些。训练集和测试集之间的性能差异是过拟合的明显标志,因此我们应该试图找到一个可以控制复杂度的模型。标准线性回归最常用的替代方法之一就是岭回归,下篇博客中将详细介绍岭回归。