前言
前面我们主要围绕pyObject和pyTypeObject聊完了python的内建对象部分,现在我们将开启新的篇章—python虚拟机,将聚焦在python的执行部分,搞懂从“代码”到“执行”的过程。开启新的篇章之前,你也许会有一个疑惑:我们写的代码是如何执行的?从表面看,我只要按照python的正确语法书写一段代码,然后“剩下的”交给python解释器,代码就能被执行了!这也许就是大部分人能够给出的解释了,在没有学习此篇章之前,我也是这么认为的,因为我也没有探究过“剩下的部分”python解释器是如何去操作的。因此,从这一篇博客开始,让我们一起带着这个问题,“钻进”python的解释器中,看看它到底做了个啥!🔍🔍🔍
开始
作为python开发者,我相信大家对pyc文件应该并不陌生,它虽然经常“藏”在我们看不到的地方,但有时作用可不小,你也许为了提速,将整个项目的py文件转成pyc文件,然后再去执行;或者你为了加密,将py文件转成pyc文件再发给别人…等等这些,都和pyc文件的特性有关系,这样看来,pyc文件似乎比py文件更“抢手”?这其中似乎有什么蹊跷?还是python解释器对pyc文件有偏心?因此,在开启“python执行过程”的探索,pyc文件似乎比py文件更有研究价值🧐?
什么是pyc文件?
细心的小伙伴应该早就发现了:我们写的py文件夹中,有时候会多一个额外的文件夹:__pychache_,点开这个文件夹,你可能还会发现,这里面会有一些以.pyc结尾的文件,同时,你还会发现它们的文件名和上级目录中的py文件名是有一些对应关系的。
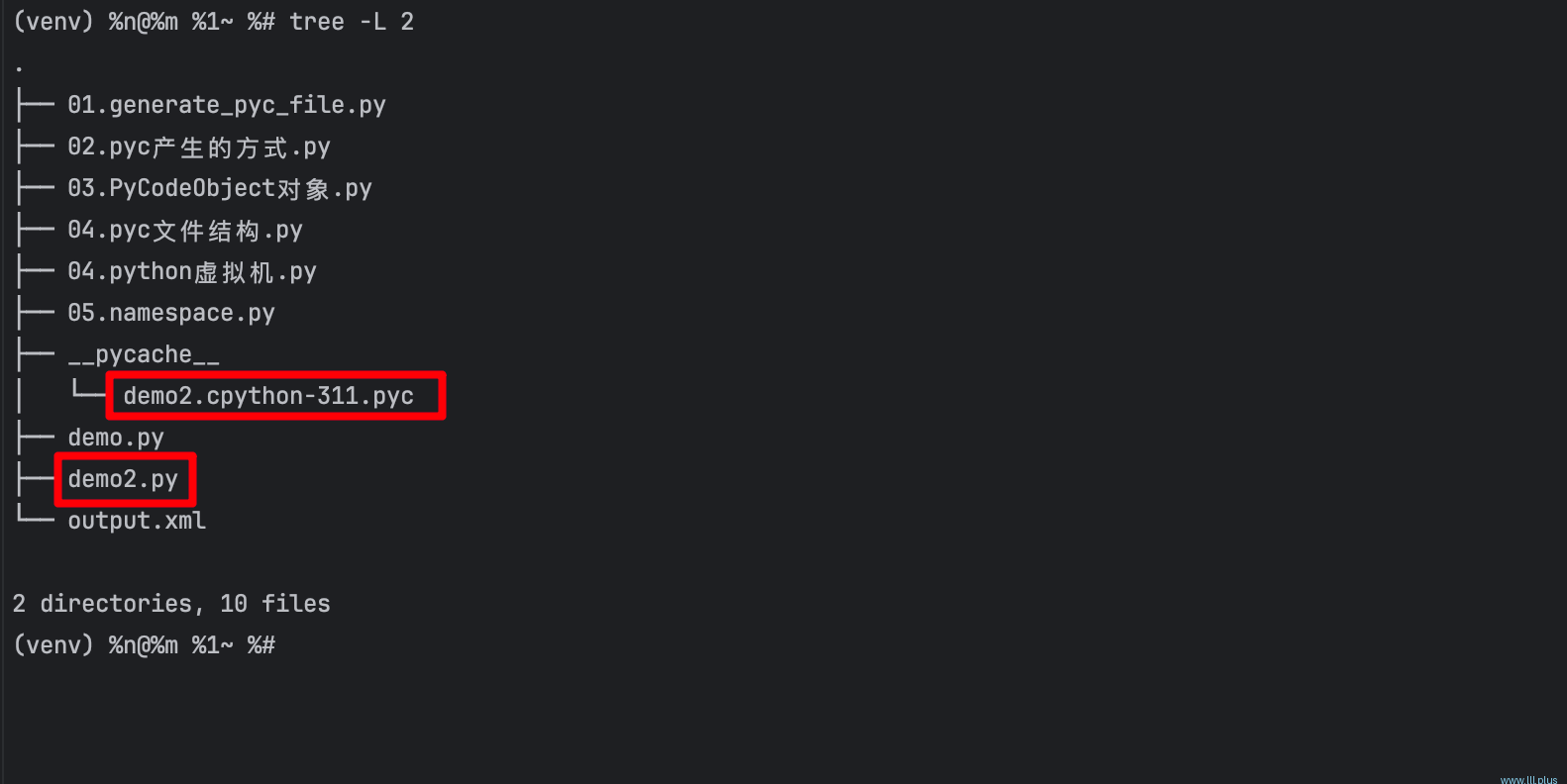
这里的以.pyc结尾的文件就是我们常说的pyc文件,看看它的目录名:__pycache_,根据目录名,我想大家应该猜到它的作用是什么了,没错,我们就可以把它当作是对py文件的一个缓存文件,缓存的主要目的:就是为了提(加载)速!
pyc文件是怎么产生的?
看上面👆的那个截图发现,__pycache__中似乎只有一个.pyc文件,为什么其他的py文件没有对应的pyc文件呢?这也许从侧面说明了一点:pyc文件不是必须的,应该只在特定情况下才能触发生成。(如果你还是有点怀疑,可以查看自己的py文件目录)
是和我们写的代码有关系吗?答案是肯定的!
实际上,当我们每次通过import导入一个py文件时,都可能会触发这个“生成pyc文件”的开关。
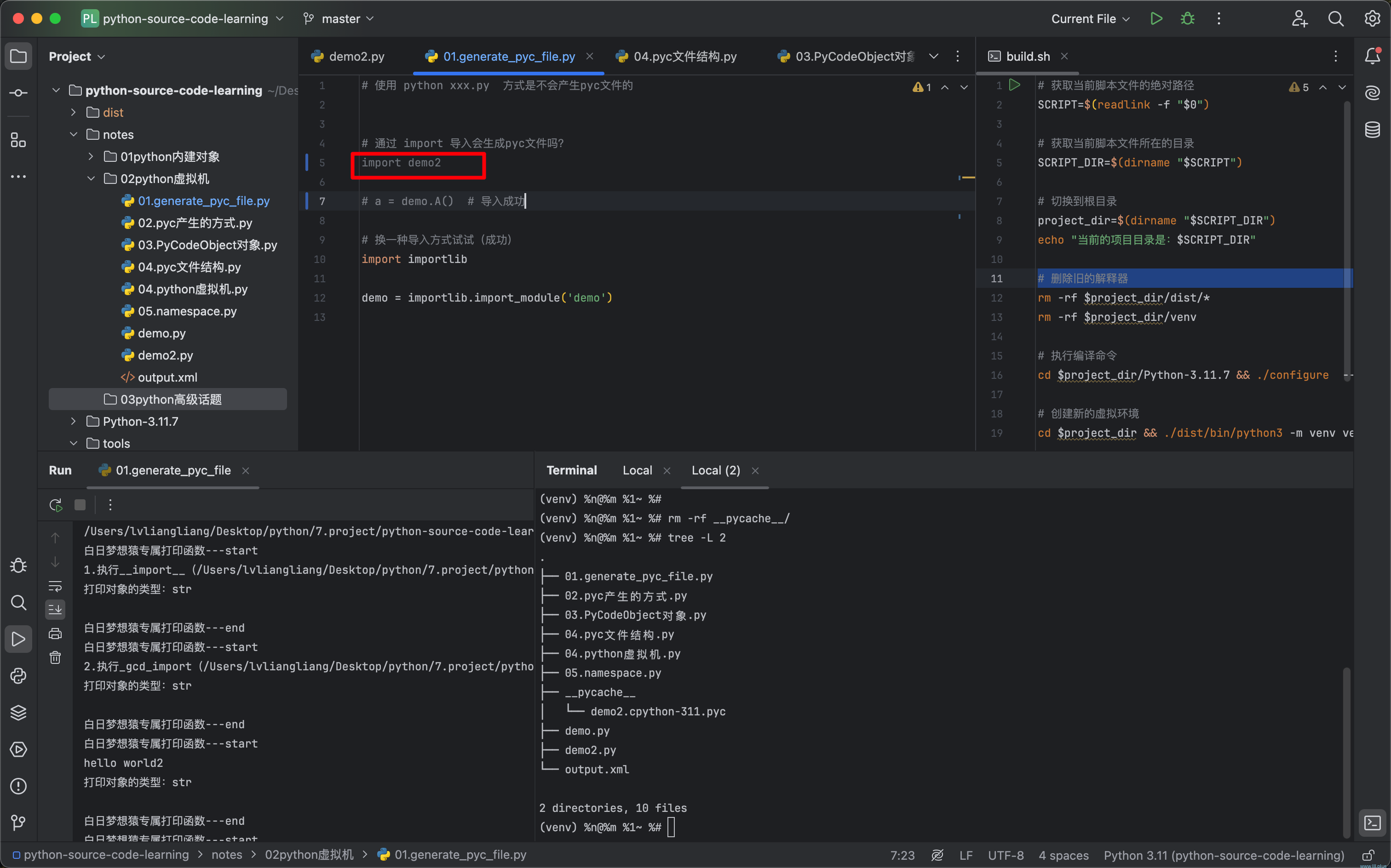
在当前目录所有的py文件中,我只对demo2.py文件进行了导入操作,没有对其他的py文件执行导入操作,因此实际上就是import机制触发了pyc文件的产生。当然,如果你想手动生成,也是可以的,下面是通过代码生成pyc文件的一个方法:
import py_compile
# 将py文件编译成pyc文件(编译成PyCodeObject存放在pyc文件中)
# PyCodeObject是编译真正的结果,pyc文件只是它存放的位置
pyc_path = py_compile.compile(file='demo.py')
# 读取pyc文件的内容
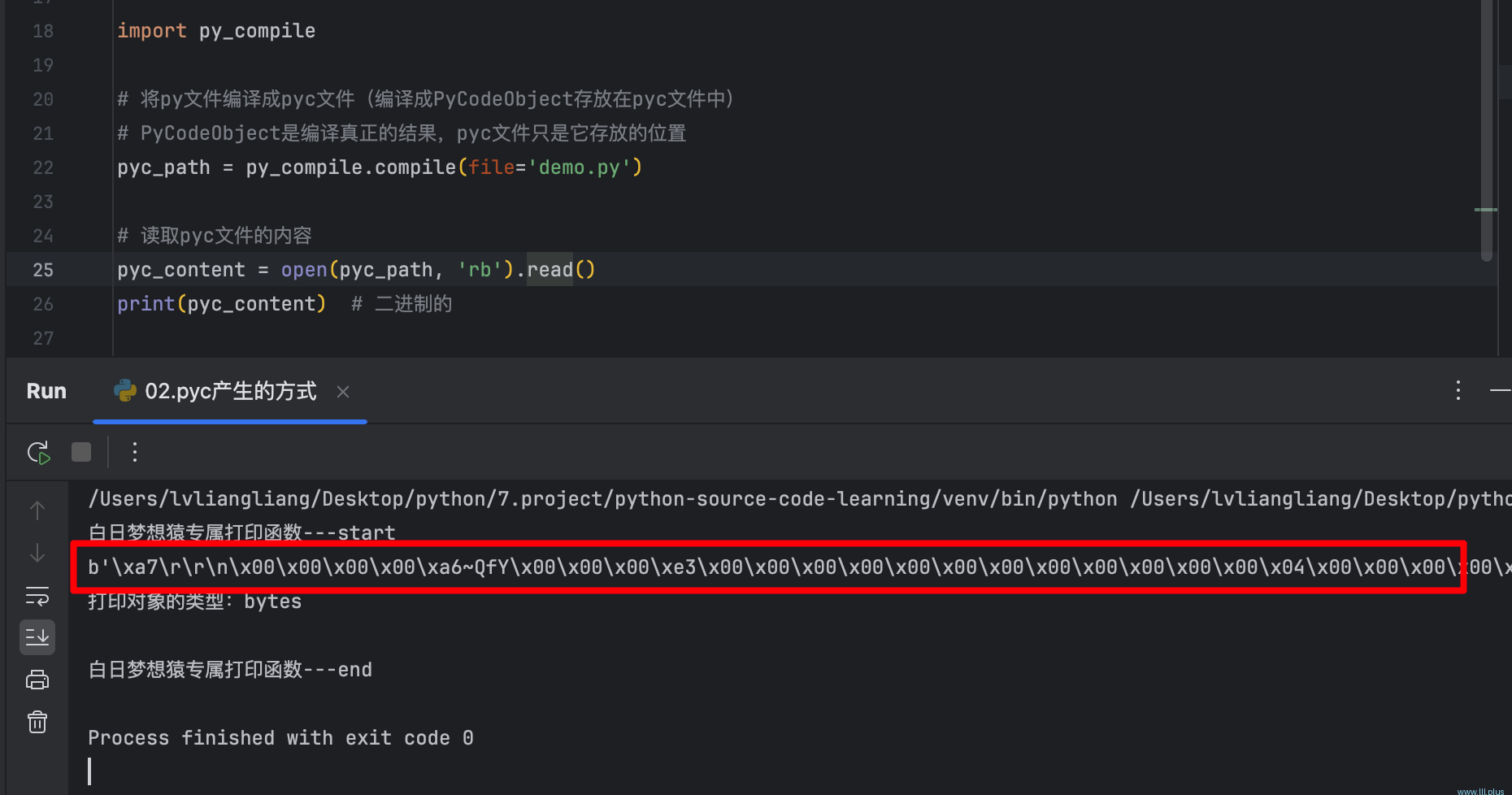
pyc_content = open(pyc_path, 'rb').read()
print(pyc_content) # 二进制的
通过读取pyc文件的内容可以发现,它实际上是一个二进制文件。
pyc文件的结构
到目前为止,我们已经知道pyc文件是一个二进制文件,用于缓存py文件,那么它的结构是怎样的呢?它里面包含了哪些东西?你是不是不知道该何从下手了?别担心!你是否还记得它是可以通过import机制生成的?那么就说明import机制中一定包含了它生成的逻辑!所以那就让我们一起顺藤摸瓜吧!
”顺着import摸瓜“
当我在阅读《python源码剖析》时,书中介绍的创建pyc的过程是在import.c这个文件中产生的,但我找了很长时间都没有找到相应的逻辑,最后通过查阅各种资料和AI发现这个逻辑已经放在标准库importlib中实现了(这里可能是版本的关系导致的,或许有出入,但问题不大)。

该说不说,python中有一个非常好用的东西,那就是它的异常栈,当一个函数有多处实现,不知道具体是哪个地方的时候,我们在每一个地方“埋雷”,当python解释器不小心踩到我们的雷,它的执行路线就会像多米洛骨牌连续翻倒一样,清晰的展现在我们面前:
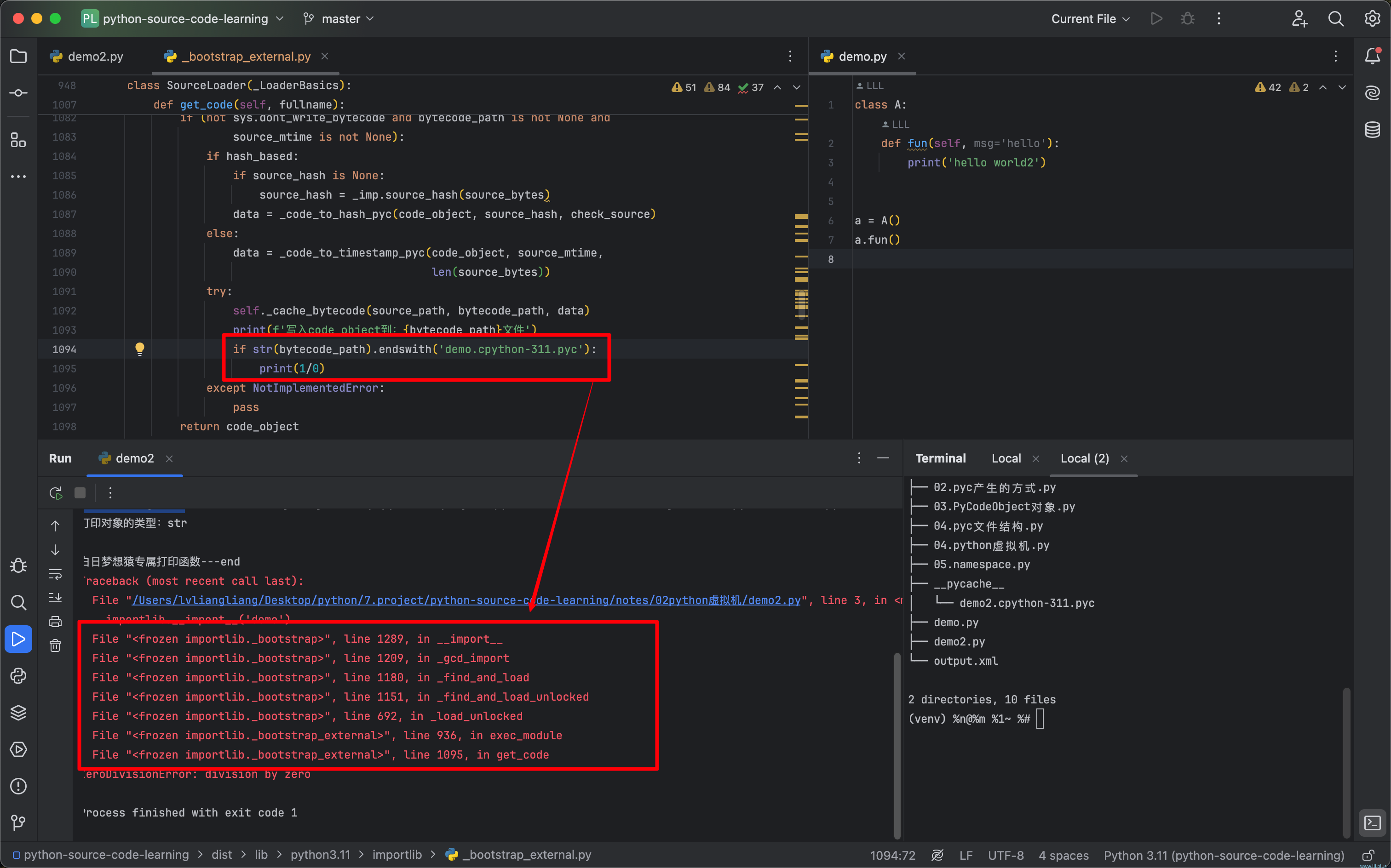
可以看到,import一个模块时,它会走到一个名为get_code的函数中,在此函数中,就包含了pyc文件生成的逻辑,这段代码的大概逻辑就是:
找到模块对应的py路径,根据py路径找到它对应的pyc路径;尝试从pyc中读取,如果读取成功,校验它和py文件中的内容是否一致(这里有两种校验方式:基于hash和基于时间戳),如果是一致的就直接返回;如果发生了变化,就从py中读取得到code obejct,并写入到对应的pyc文件,之后再返回;最后调用exec方法执行返回的code obejct。
def get_code(self, fullname):
"""Concrete implementation of InspectLoader.get_code.
Reading of bytecode requires path_stats to be implemented. To write
bytecode, set_data must also be implemented.
"""
source_path = self.get_filename(fullname)
source_mtime = None
source_bytes = None
source_hash = None
hash_based = False
check_source = True
try:
# 获取py文件对应的pyc文件的路径
bytecode_path = cache_from_source(source_path)
except NotImplementedError:
bytecode_path = None
else:
try:
"""
- 'mtime' (mandatory) is the numeric timestamp of last source
code modification;
- 'size' (optional) is the size in bytes of the source code."""
st = self.path_stats(source_path)
except OSError:
pass
else:
# py文件最后的修改时间
source_mtime = int(st['mtime'])
try:
data = self.get_data(bytecode_path)
except OSError:
pass
else:
exc_details = {
'name': fullname,
'path': bytecode_path,
}
try:
flags = _classify_pyc(data, fullname, exc_details)
bytes_data = memoryview(data)[16:]
hash_based = flags & 0b1 != 0
if hash_based:
check_source = flags & 0b10 != 0
if (_imp.check_hash_based_pycs != 'never' and
(check_source or
_imp.check_hash_based_pycs == 'always')):
source_bytes = self.get_data(source_path)
source_hash = _imp.source_hash(
_RAW_MAGIC_NUMBER,
source_bytes,
)
_validate_hash_pyc(data, source_hash, fullname,
exc_details)
else:
_validate_timestamp_pyc(
data,
source_mtime,
st['size'],
fullname,
exc_details,
)
except (ImportError, EOFError):
pass
else:
_bootstrap._verbose_message('{} matches {}', bytecode_path,
source_path)
return _compile_bytecode(bytes_data, name=fullname,
bytecode_path=bytecode_path,
source_path=source_path)
if source_bytes is None:
source_bytes = self.get_data(source_path)
code_object = self.source_to_code(source_bytes, source_path)
_bootstrap._verbose_message('code object from {}', source_path)
if (not sys.dont_write_bytecode and bytecode_path is not None and
source_mtime is not None):
if hash_based:
if source_hash is None:
source_hash = _imp.source_hash(source_bytes)
data = _code_to_hash_pyc(code_object, source_hash, check_source)
else:
data = _code_to_timestamp_pyc(code_object, source_mtime,
len(source_bytes))
try:
self._cache_bytecode(source_path, bytecode_path, data)
print(f'写入code object到:{bytecode_path}文件')
if str(bytecode_path).endswith('demo.cpython-311.pyc'):
print(1/0)
except NotImplementedError:
pass
return code_object
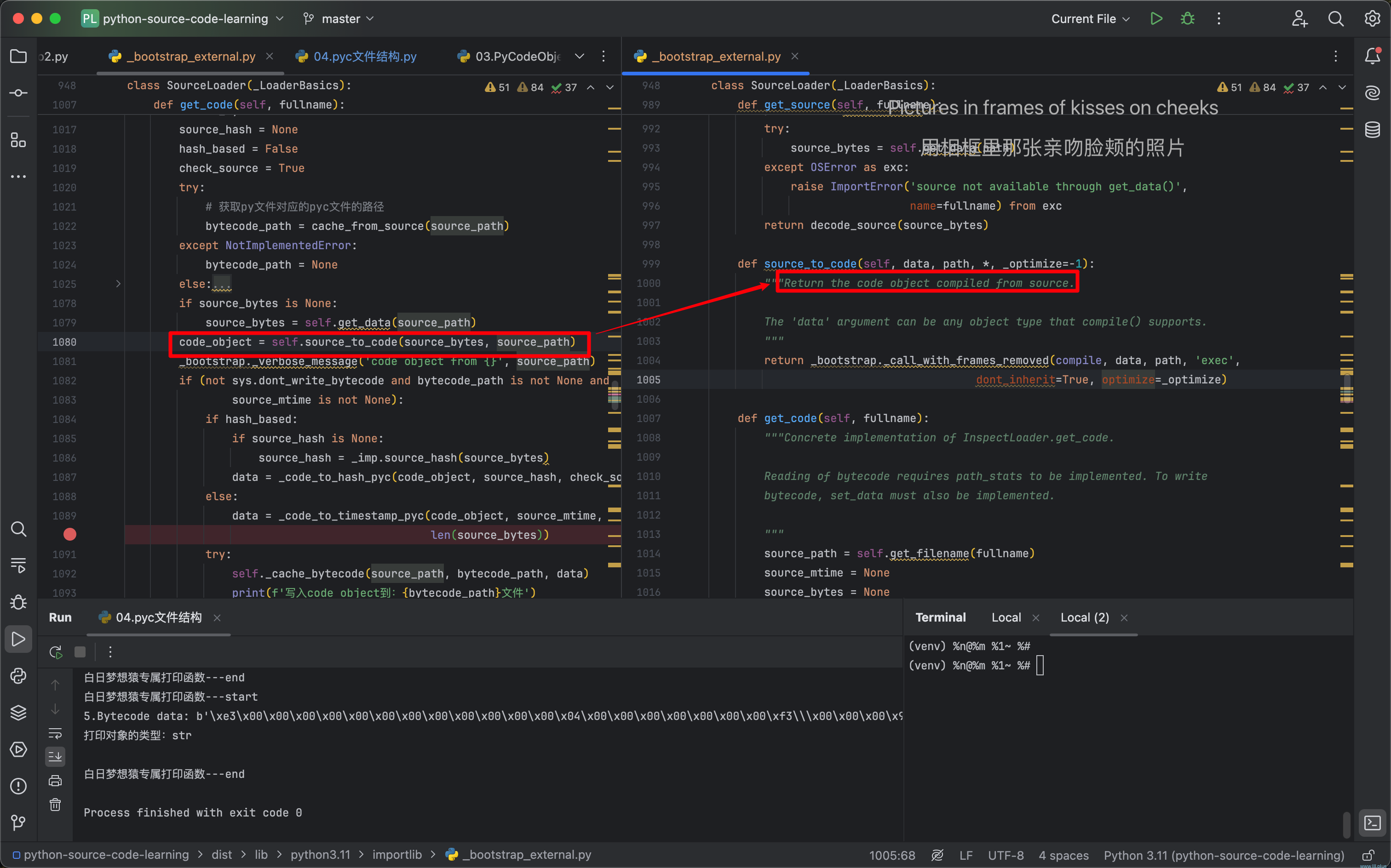
直白一点就是:如果有现成的,判断一下是不是最新的,如果是就用现成的(pyc);如果没有(或者不是最新的),就现场生成一个。所以,这里就是pyc能够提升加载速度的逻辑,在加载一个模块时,python解释器会先把我们写的代码进行“编译”,然后将“编译”好的代码再拿去执行,同时会将编译的结果写到pyc文件中,当再次需要导入这个模块时,如果已经有编译好的pyc文件,并且是最新的,就直接使用它就好,这样就省去了“编译”的时间。其实就是一个缓存的逻辑!
pyc文件的内容
还是在get_code这个函数中,我们可以找到两种生成pyc文件的方式:
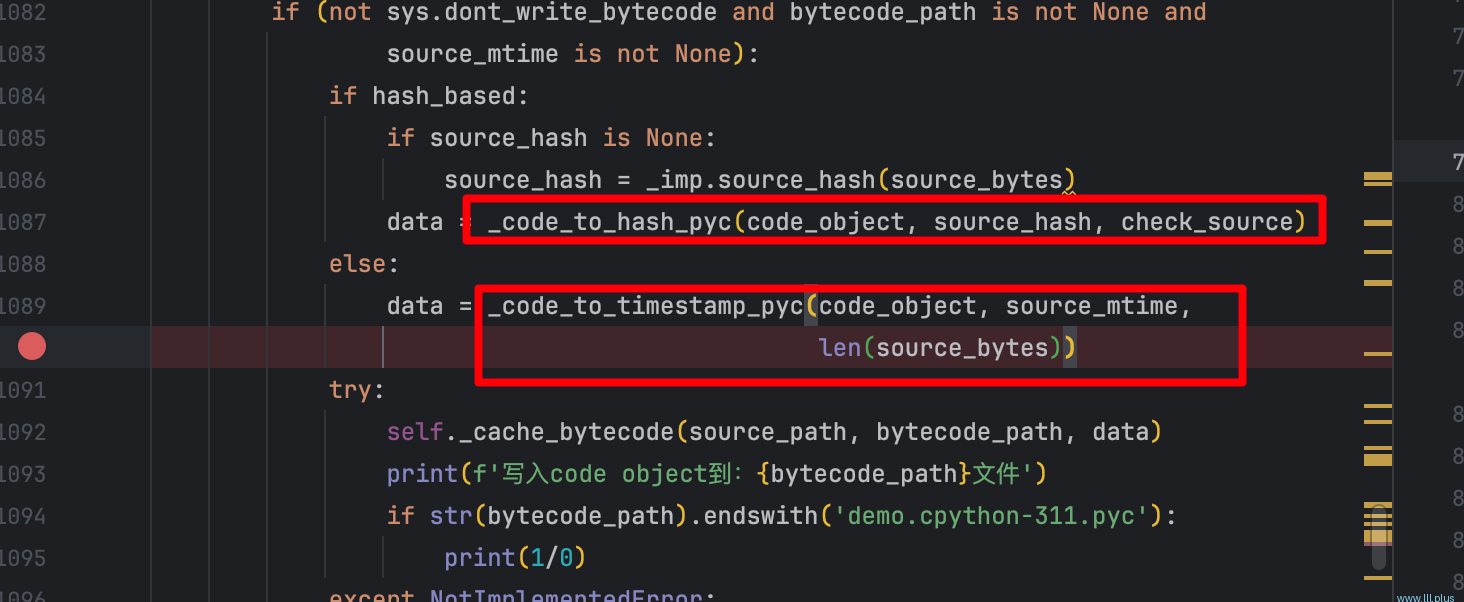
分别是基于时间戳和hash值的两种方式,以基于时间戳的方式为例,它的具体逻辑如下:
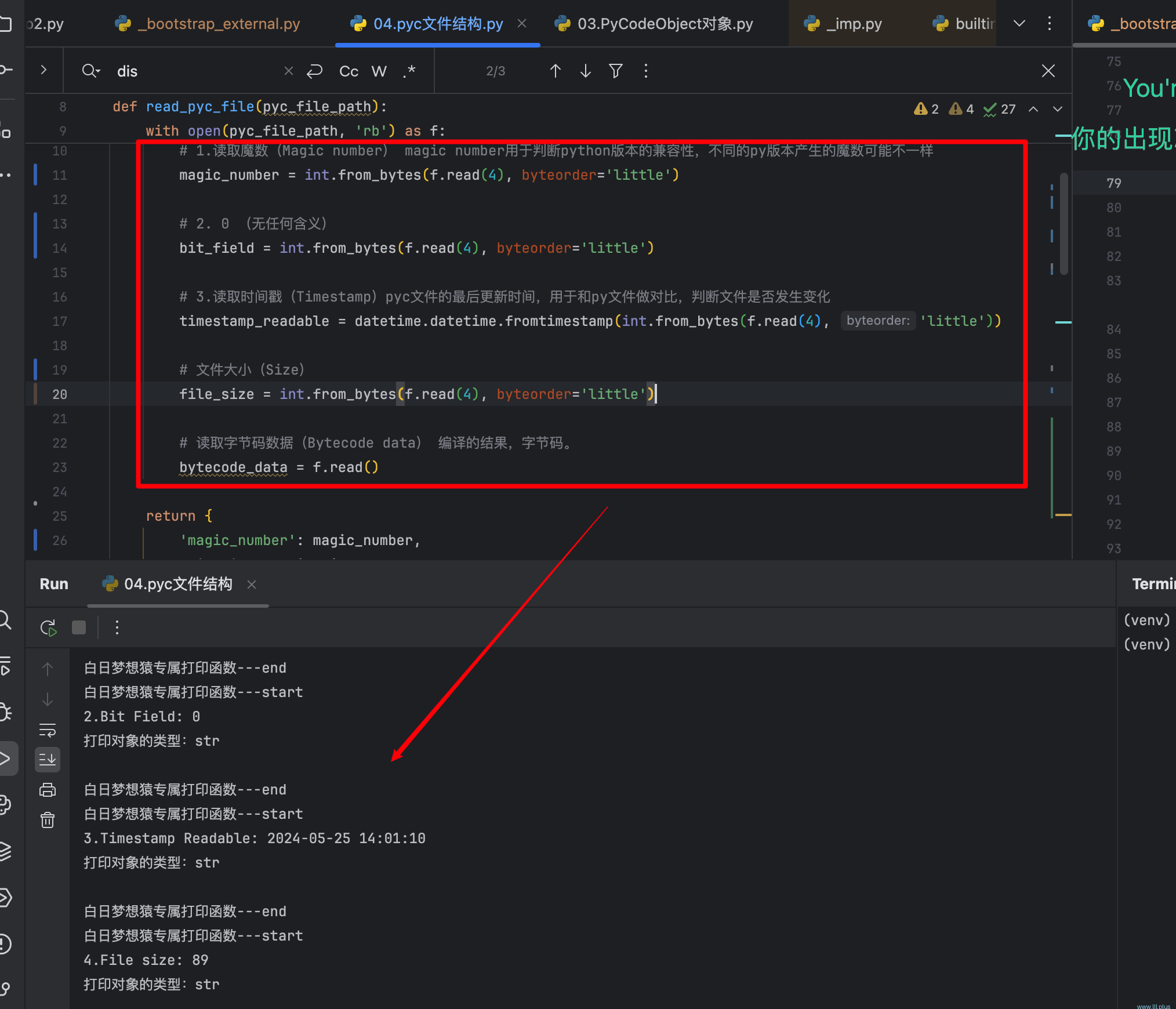
基于当前的python解释器的版本MAGIC_NUMBER生成一个字节数组,之后在添加其他的一些数据:mtime(源文件最后的编辑时间),source_size(源文件的大小),code(源码编译后的结果)以及一个无任何含义的0(可能是官方预留的),注意:除了code以外,其他数据的长度都是4,这就是pyc文件的所有内容,它们分别是:magic_number,mtine,0,source_size,code(不同的python版本内容可能有出入,我这里是py3-11-7)。
tips:magic_number主要用于判断解释器和当前要执行的python代码是否兼容,你可以尝试用py3-7编译一个pyc文件,然后用py3-11去执行,它会抛出一个magic_number不兼容的错误。
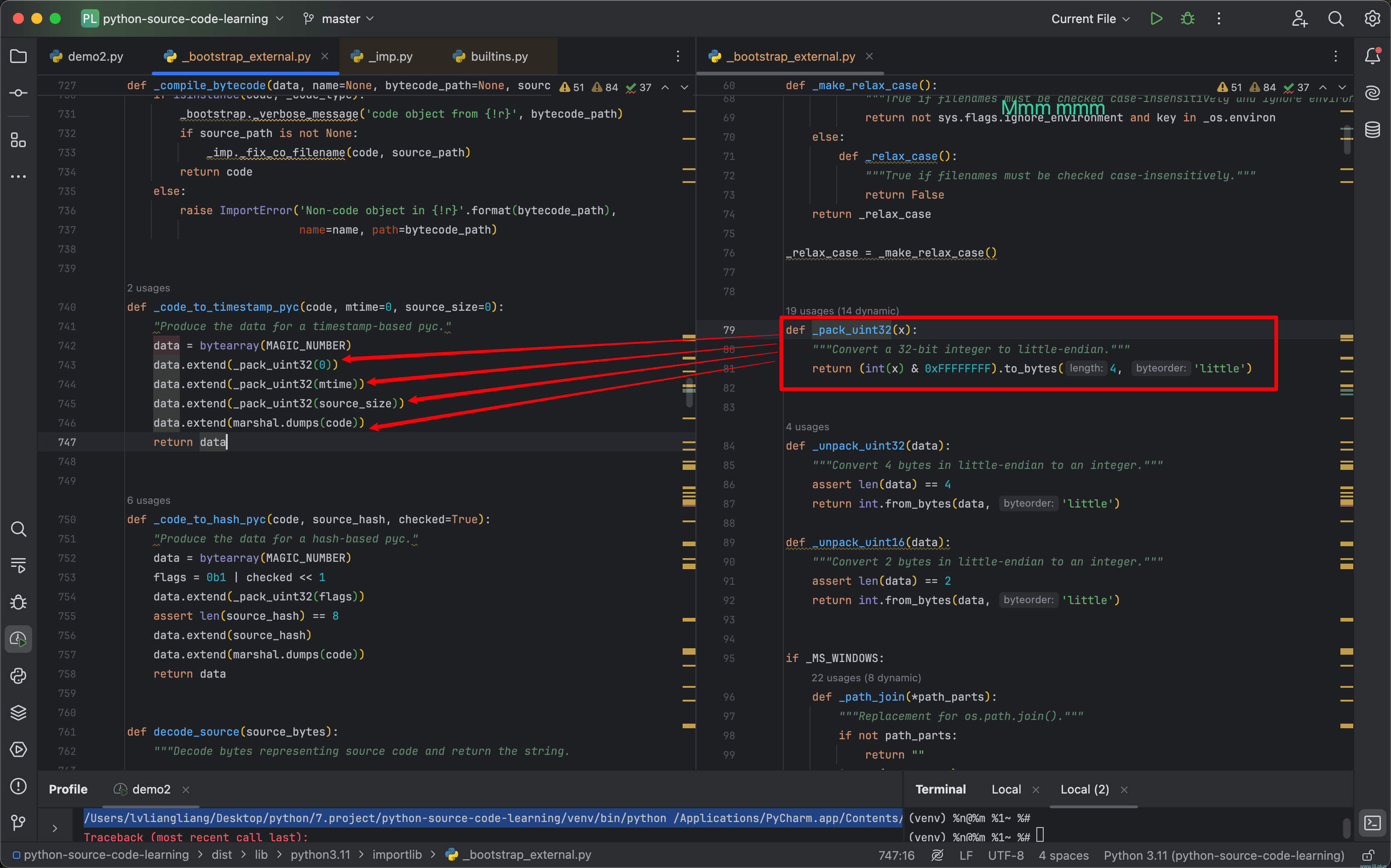
为了证实pyc真的就是如上那些内容,我们可以试着解析一个pyc文件试试!
code object
到目前为止,我们一直围绕着pyc文件在转,从它的生成逻辑到它结构内容,以及它的意义,对它的了解应该算是了如指掌了!但是我们似乎忽略了一个重要的环节—“编译”,源文件是如何被编译的,以及它的编译结果是什么?
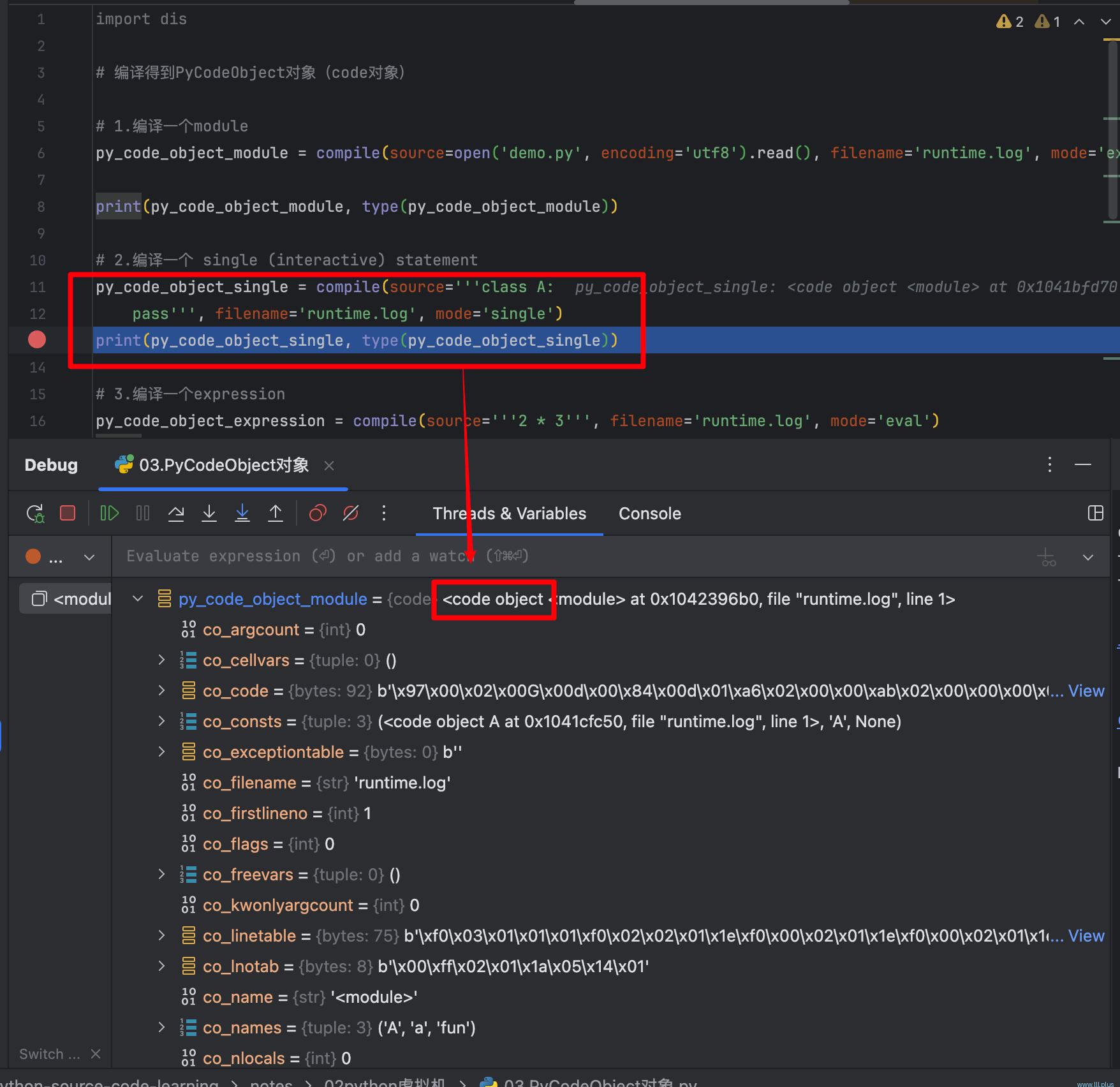
通过源代码可以发现,其实就是调用了内置的compile方法对源文件的内容进行了“编译”,编译的结果通过调用type方法可以知道是:code object。
tips:关于compile内部是如何执行的,可以参考python源文件中的Python/compile.c文件。
code object的结构
在探究code object的结构之前,我们可以先来看一下它所对应的源码的内容是怎样的,以demo.py文件为例,它的内容如下:
class A:
def fun(self, msg='hello'):
print('hello world2')
a = A()
a.fun()
可以看到:它包含了一个类A,类下面包含了一个方法fun,fun有两个参数,一个是self,另外一个是msg,fun中执行了一个打印字符串“hello world2”,同时在全局下,它还包含了一个变量a,a调用了方法fun,这就是所有的内容,如果你是python的开发者,你会如何将它“编译”成你需要的内容?
想一想,这里面是不是一个嵌套关系:在全局下,它包含了一个类型A和一个实例a;在类型A中,它包含了一个方法fun;在方法fun中,它包含了一个位置参数self和一个关键字参数msg,且默认值是“hello”,同时它内部还包含了一个字符串“hello world2”;如何存储这些信息以及它们之间的关系呢?
实际上code object也是类似于这样的一个嵌套对象,每一个code object对象有它自己的属性,同时code object里面可以包含其他code object,每一个code object都可以看成是一个域(或者是一个code block(代码块)),而这个域就可以是上面说的哪些对象:可以是一个模块,可以是一个类,可以是一个函数,可以是一个方法…
demo.py编译得到的code object如下:
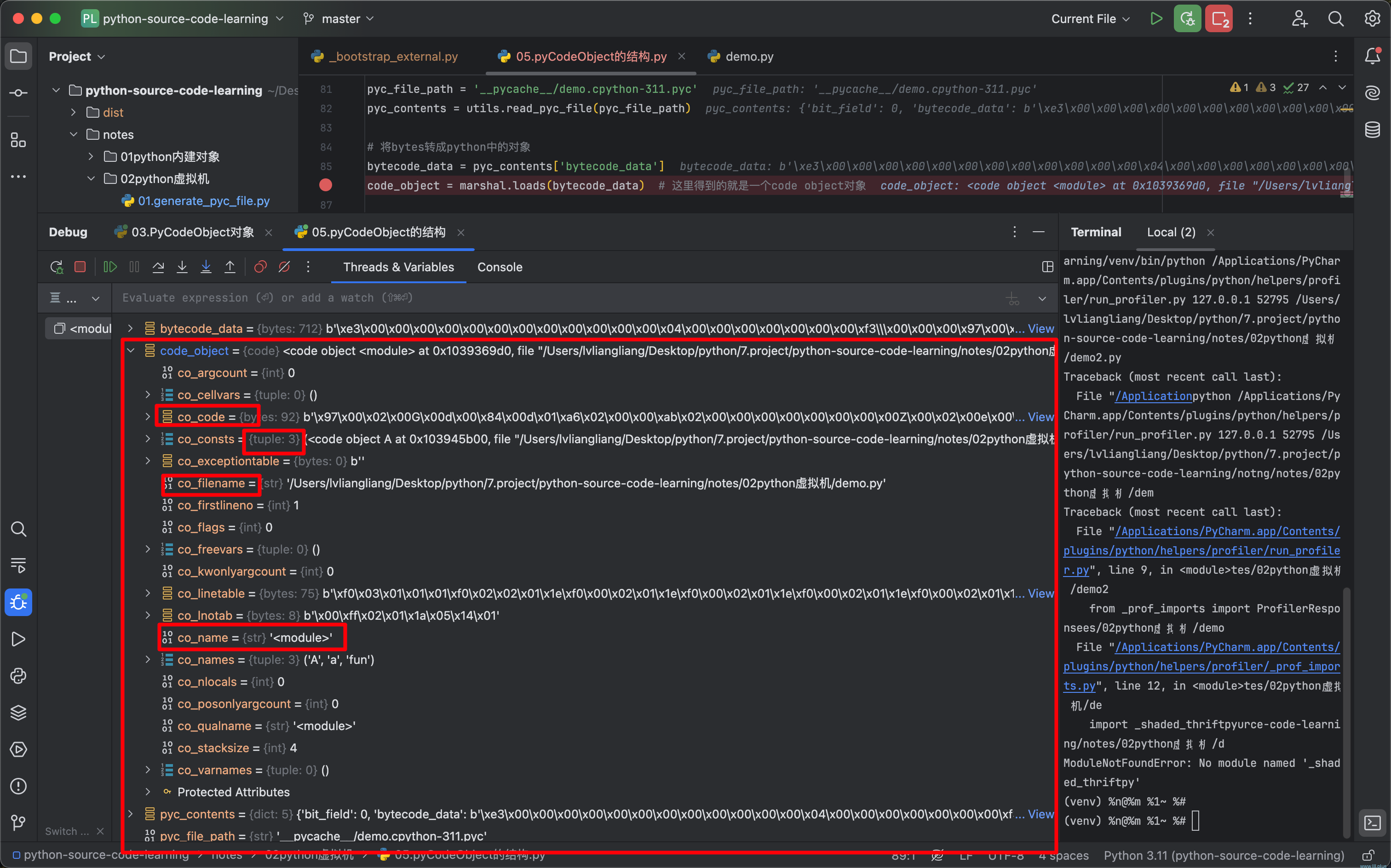
code object各属性含义如下:
| 属性名称 | 含义 |
|---|---|
| co_argcount | 位置参数的数量。 |
| co_kwonlyargcount | 关键字参数的数量。 |
| co_nlocals | 局部变量的数量。 |
| co_stacksize | 所需的栈大小。 |
| co_flags | 编译标志。 |
| co_code | 实际的字节码指令。 |
| co_consts | 常量池(字面量、元组等)。 |
| co_names | 在字节码中使用的名称列表。 |
| co_varnames | 局部变量名列表。 |
| co_filename | 源代码文件名。 |
| co_name | 代码对象的名称。 |
| co_firstlineno | 第一行的行号。 |
| co_lnotab | 行号表(字节码到源代码行号的映射)。 |
| co_freevars | 自由变量的名称(闭包中使用的变量)。 |
| co_cellvars | 闭包中绑定的局部变量的名称。 |
每一个code object中都有一个重要的属性,就是co_code,它存储了字节码指令,在实际执行的时候,会根据不同的字节码指令执行不同的操作;当前code object如果包含了其他的code object,它们都会被存储在co_consts这个属性中。
解析code object对象
为了更加清晰地看到code object的嵌套结构,我们可以使用json或者xml结构来展示它的结构:
import dis
import types
import xml.etree.ElementTree as ET
from notes.utils import utils
import marshal
import pprint
def parse_code_object(code_object, result={}):
"""将code对象转成json"""
# 反编译当前的code object对象,得到字节码指令
print(f'{code_object.co_name}')
dis.dis(code_object)
keys = ['co_name', 'co_names', 'co_consts', 'co_argcount', 'co_cellvars', 'co_code', 'co_exceptiontable',
'co_filename',
'co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lines', 'co_linetable', 'co_lnotab',
'co_nlocals', 'co_positions', 'co_posonlyargcount', 'co_qualname', 'co_stacksize', 'co_varnames', 'replace']
# 赋值
for key in keys:
result[key] = getattr(code_object, key)
result['co_consts'] = []
co_consts = code_object.co_consts
for co_const in co_consts:
if isinstance(co_const, types.CodeType):
_result = {}
parse_code_object(co_const, _result)
result['co_consts'].append(_result)
else:
result['co_consts'].append(co_const)
def code_object_to_xml(co, parent_element):
code_element = ET.SubElement(parent_element, 'code')
code_element.attrib['co_name'] = co.co_name
ET.SubElement(code_element, 'co_name').text = co.co_name
ET.SubElement(code_element, 'co_filename').text = co.co_filename
ET.SubElement(code_element, 'co_firstlineno').text = str(co.co_firstlineno)
ET.SubElement(code_element, 'co_argcount').text = str(co.co_argcount)
ET.SubElement(code_element, 'co_kwonlyargcount').text = str(co.co_kwonlyargcount)
ET.SubElement(code_element, 'co_nlocals').text = str(co.co_nlocals)
ET.SubElement(code_element, 'co_stacksize').text = str(co.co_stacksize)
ET.SubElement(code_element, 'co_flags').text = str(co.co_flags)
ET.SubElement(code_element, 'co_varnames').text = str(co.co_varnames)
ET.SubElement(code_element, 'co_names').text = str(co.co_names)
# ET.SubElement(code_element, 'co_consts').text = str(co.co_consts)
ET.SubElement(code_element, 'co_lnotab').text = co.co_lnotab.hex()
co_code_element = ET.SubElement(code_element, 'co_code')
co_code_element.text = co.co_code.hex()
# Recursively process nested code objects
for const in co.co_consts:
if isinstance(const, types.CodeType):
co_consts = ET.SubElement(code_element, 'co_consts')
code_object_to_xml(const, co_consts)
# code object它是可能是一个嵌套的对象,可以转成json或者xml进行可视化展示
pyc_file_path = '__pycache__/demo.cpython-311.pyc'
pyc_contents = utils.read_pyc_file(pyc_file_path)
# 将bytes转成python中的对象
bytecode_data = pyc_contents['bytecode_data']
code_object = marshal.loads(bytecode_data) # 这里得到的就是一个code object对象
# xml
root = ET.Element('root')
code_object_to_xml(code_object, root)
tree = ET.ElementTree(root)
file_path = 'output.xml'
tree.write(file_path, encoding='utf-8', xml_declaration=True)
# json
result = {}
parse_code_object(code_object, result)
pprint.pprint(result, sort_dicts=False)
解析的xml结构如下:
<?xml version='1.0' encoding='utf-8'?>
<root>
<code co_name="<module>">
<co_name><module></co_name>
<co_filename>
/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py
</co_filename>
<co_firstlineno>1</co_firstlineno>
<co_argcount>0</co_argcount>
<co_kwonlyargcount>0</co_kwonlyargcount>
<co_nlocals>0</co_nlocals>
<co_stacksize>4</co_stacksize>
<co_flags>0</co_flags>
<co_varnames>()</co_varnames>
<co_names>('A', 'a', 'fun')</co_names>
<co_lnotab>00ff02011a051401</co_lnotab>
<co_code>
970002004700640084006401a6020000ab0200000000000000005a0002006500a6000000ab0000000000000000005a016501a0020000000000000000000000000000000000000000a6000000ab000000000000000000010064025300
</co_code>
<co_consts>
<code co_name="A">
<co_name>A</co_name>
<co_filename>
/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py
</co_filename>
<co_firstlineno>1</co_firstlineno>
<co_argcount>0</co_argcount>
<co_kwonlyargcount>0</co_kwonlyargcount>
<co_nlocals>0</co_nlocals>
<co_stacksize>2</co_stacksize>
<co_flags>0</co_flags>
<co_varnames>()</co_varnames>
<co_names>('__name__', '__module__', '__qualname__', 'fun')</co_names>
<co_lnotab>0a01</co_lnotab>
<co_code>970065005a0164005a026404640284015a0364035300</co_code>
<co_consts>
<code co_name="fun">
<co_name>fun</co_name>
<co_filename>
/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py
</co_filename>
<co_firstlineno>2</co_firstlineno>
<co_argcount>2</co_argcount>
<co_kwonlyargcount>0</co_kwonlyargcount>
<co_nlocals>2</co_nlocals>
<co_stacksize>3</co_stacksize>
<co_flags>3</co_flags>
<co_varnames>('self', 'msg')</co_varnames>
<co_names>('print',)</co_names>
<co_lnotab>0201</co_lnotab>
<co_code>97007401000000000000000000006401a6010000ab010000000000000000010064005300</co_code>
</code>
</co_consts>
</code>
</co_consts>
</code>
</root>
我们写的代码是如何执行的?
还记得我们最开始的疑惑吗?—”我们写的代码是如何执行的?“,到现在为止,我们从pyc文件“下手”,搞懂了一个模块被加载时,它的源代码会被编译成code object对象,这是一个嵌套的对象,它包含了执行源代码需要的所有信息,为了提高加载速度,这个对象也会被缓存到对应的pyc文件中,所以,从这一点看,pyc文件只不过是一个载体,用于暂时存储code object罢了,code object才是我们后续研究的重点!想象一下,现在我们已经拿到包含字节码(虽然目前我们还不知道这是啥)的code object对象,虽然不知道它后续是什么样的,但是我们能够肯定的是:我们离python解释器已经更近一步了,离我们的代码被它执行的距离也越来越近了,这是一个好的开始!暂且记录我们的进度为50%吧,当我们的这个进度为100时,我们就能彻底搞清楚这个执行的过程啦!加油,后面我们再继续探索!🐢🐢🐢
更多内容可以关注博主的个人博客系统:《Python源码剖析》之pyc文件