前言
我们现在开始C++STL的学习,从这时开始我们就要锻炼自己查看英文文档的能力,每种数据结构都有上百个接口函数,我们把他们全部记下来是不可能的,所以我们只记最常见的20几个接口,其他的大概熟悉有什么功能,用的时候去查看文档。
对于string来说,实际上它就是一个管理字符数组的顺序表,因为字符数组使用的比较广泛,所以C++就专门写了一个string类,而string类最主要包含的有三个成员-----char* _str,size_t size,size_t capacity,具体的解释我们会在后面模拟实现的时候具体讲解。
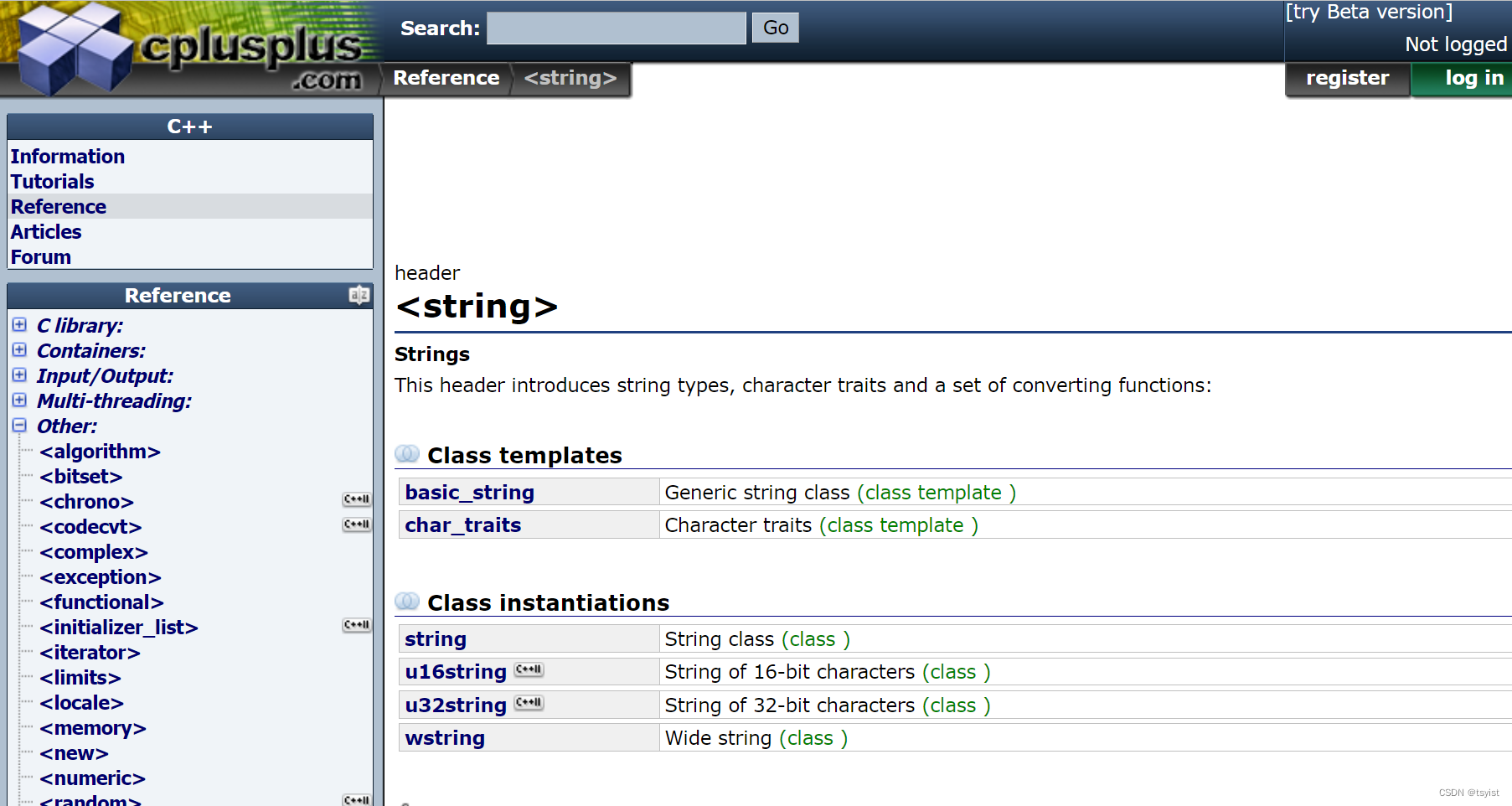
上面就是string的文档解释,我们平时查阅文档使用的是cplusplus网站,这个网站现在有新的界面,但是我比较习惯使用老界面,所以我这里使用的老界面,两者本质上没有差别。
cplusplus官网:https://cplusplus.com/
我们为什么学习string类?
C语言的字符串:
C语言中,字符串是以‘\0’为结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数和字符串是分离开的,不符合OOP的思想,而且底层空间需要用户自己管理,稍不留神就容易出现访问越界的问题。
而且在OJ中,有关字符串的题目基本都会以string的形式出现,在平时工作中,为了简单方便,基本上也都使用string类,很少有人使用C库中的字符串操作函数。
标准库中的字符串
- string是表示字符串的字符串类
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedef basic_string<char,char_traits,allocator> string
- 不能操作多字节或变长字符的序列,因为string类独立于所使用的编码来处理字节,如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际的字符)来操作。
- 使用string类时,必须包含string头文件以及using namespace std;


我们通过文档可以看到两个类型,我们现在接触的是第一个。
如果我们用sizeof(char)和sizeof(wchar_t)来进行编译的话,会发现sizeof(char)为1,sizeof(wchar_t)为2。这种现象跟编码有关。
编码是什么?
计算机中只存储二进制0和1,那么我们如何表示文字呢?
对应的历史上出现很多编码表:
1.ASCII字符集
ASCII 码是最早出现的字符集,其全称为 American Standard Code for Information Interchange(美国标准信息交换代码)。它使用 7 位二进制数(一个字节的低 7 位)表示一个字符,最多能够表示 128 个不同的字符。它只能够表示英文。
2.GBK字符集
中国国家标准总局于 1980 年发布了 GB2312 字符集,其收录了 6763 个汉字,基本满足了汉字的计算机处理需要。GBK 字符集是在 GB2312 的基础上扩展得到的,它共收录了 21886 个汉字。在 GBK 的编码方案中,ASCII 字符使用一个字节表示,汉字使用两个字节表示。
3.Unicode字符集
这是一个足够完整的字符集,理论上能容纳100多万个字符,它致力于将全球范围内的语言和符号都收录其中,就可以解决跨语言环境和乱码问题了。在Unicode中,常用的字符占用两字节,有些生僻的字符占3字节甚至4字节。Unicode 是一种通用字符集,本质上是给每个字符分配一个编号(称为“码点”),但是Unicode并没有规定计算机怎么存储字符码点,那么多种长度的unicode码点同时出现在一个文本中时系统如何解析字符呢?一种直接的解决方案是将所有字符存储为等长的编码:例如,对于"hello世界"这个字符串来说,“hello”每个字符占用1字节,“世界”每个字符占用2字节,我们就可以将“hello”的每个字符的高位都填上0,这样每个字符的长度就都是两字节了,但是这样的话,会非常浪费内存空间。
4.UTF-8编码
他是一种可变长度的编码,使用1到4字节表示一个字符,根据字符的复杂性而变。ASCII 字符只需 1 字节,拉丁字母和希腊字母需要 2 字节,常用的中文字符需要 3 字节,其他的一些生僻字符需要 4 字节。
UTF-8 的编码规则并不复杂,分为以下两种情况:
- 对于长度为 1 字节的字符,将最高位设置为 0 ,其余 7 位设置为 Unicode 码点。值得注意的是,ASCII 字符在 Unicode 字符集中占据了前 128 个码点。也就是说,UTF-8 编码可以向下兼容 ASCII 码。这意味着我们可以使用 UTF-8 来解析年代久远的 ASCII 码文本。
- 对于长度为 n 字节的字符(其中 n>1),将首个字节的高 n 位都设置为 1 ,第 n+1 位设置为 0 ;从第二个字节开始,将每个字节的高 2 位都设置为 10 ;其余所有位用于填充字符的 Unicode 码点。
string常见接口说明
1.string类对象构造接口
| (constructor)函数名称 | 功能说明 |
| string()---重要 | 构造空的string类对象,即空字符串 |
| string(const char* s)---重要 | 用C_str来构造string类对象 |
| string(size_t n,char c) | string类对象中包含n个字符c |
| string(const string& s)---重要 | 拷贝构造函数 |
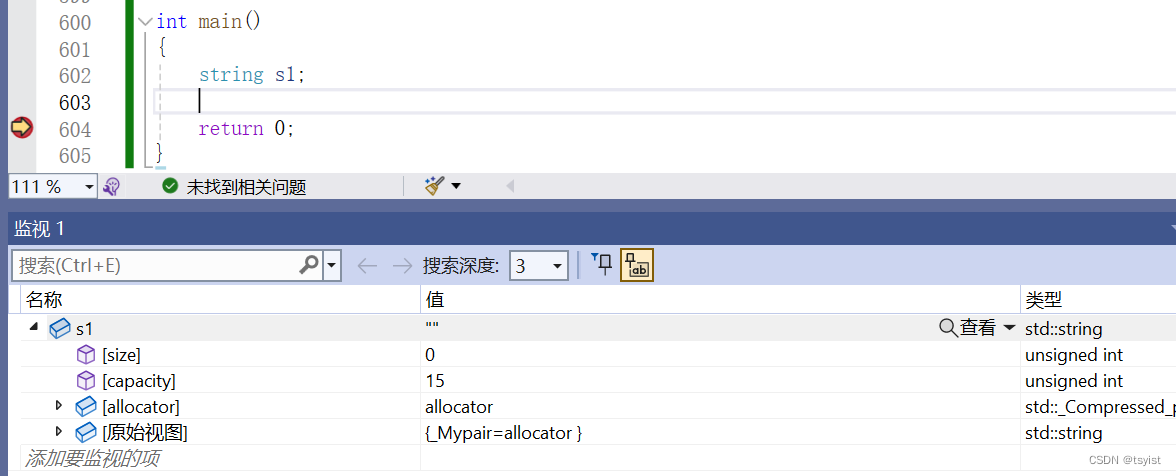
需要说明的是:我们构造空的string类对象时,并不是什么都没有,会在第一个位置放\0:
2.string类对象的容量操作
| 函数名称 | 功能说明 |
| size | 返回字符串有效长度 |
| length | 返回字符串有效长度 |
| capacity | 返回空间总大小 |
| empty | 检测字符串是否为空串, 若是返回true,不是返回false |
| clear | 清空有效字符 |
| reserve | 为字符串预留空间 |
| resize | 将有效字符改为n个, 若有多出的空间用字符c填充 |
说明:
其中size和length的功能相同,我们比较常用size()。
对于string是在STL这个规范前被设计出来的,因此containers下并没有string:
早期要算字符串的长度,提供的接口为length,至于后面要加size接口的原因是后面增加了map,set这样的树,所以后面用length去表示他的数据个数就不合适了。
max_size

这个接口是早期设计的,属于一个没用的接口,从操作系统中获取最大的长度。本意是想告诉使用者这个字符串最大能定义多长,但这个接口在设计的时候其实不好实现,它没有办法标准的去定义这个接口,因为它有很多不确定的因素,所以这里结果是直接给2^32,也就是4G。没有什么实际价值。
capacity
对于string对象而言,若capacity是15,意味着它有16个字节的空间,因为最后有一个位置是\0。capacity会随着字符串的增大而增容。
resize

resize这里是有两个重载形式,若n小于当前字符串长度,它就会缩减到n个字符,从n开始以后的字符会被删掉。
若n大于当前字符串长度size,小于容量capacity的时候,他会在后面加上(n-size)个c字符,若n大于了capacity的话,字符串会扩容后在尾上加上(n-size)个c字符。
reserve

reserve的作用是开辟空间,即请求capacity。注意,他并不是你给多少capacity他就会给多少capacity,他在增容的时候会对照着不同编译器下自己的增容规则,最终容量不一定等于字符串长度,他可能是相等的,也可能是更大的。
当n大于字符串的capacity的时候,使用reserve会扩容。
当n小于或等于字符串的capacity的时候,使用reserve的话有可能它会缩容(开一块新空间,将数据拷贝,释放原有空间),也有可能不对当前的空间进行影响,只是改变capacity的值。经过证实:在VS下和Linux在不会缩容,STL的标准也是这样规定的,这时实现STL的人决定的。
对于s.reserve(10)这样的操作,s[9]是无效位置,因为对于operator[]来说,他会提前判断pos<_size。
我们如何使用resize和reserve函数呢?
对于resize来说,既要开空间,又要对这些空间进行初始化,就可以用resize;
对于reserve来说,如果我们明确知道我们需要多大空间,就可以提前把空间开好,以此减少增容所带来的代价,因为每次增容都是要付出代价的。
clear(清空字符串)&&empty(判断字符串是否为空)
不做过多解释,很简单
3.string类对象的访问和遍历操作
| 函数名称 | 功能说明 |
| operator[] | 返回pos位置的字符 |
| begin,end | begin获取第一个字符的迭代器, end获取最后一个字符下一个位置的迭代器(即\0的迭代器) |
| rbegin,rend | rbegin获取最后一个字符的迭代器, rend获取第一个字符上一个位置的迭代器 |
| 范围for | C++11支持的更加便利的遍历方式 |
operator[]&&at
operator和at的结果是一样的,唯一不同的就是在越界的时候:operator[]本质上是用断言判断,如果越界了,会直接崩掉;而at若越界了则会抛异常。
范围for
这是C++11中的语法,只要支持迭代器的STL容器都可以使用范围for,我们后面会模拟它。
我们在使用范围for时,一般会使用auto类型自动判断元素类型,若我们对元素既想读又想写,就使用引用传参auto& e : s3,若只想读就使用传值传参auto e : s3。建议如果不是不能更改的情况,就使用引用传参。
迭代器
迭代器是STL中六大组件中的核心组件。
我们上面表格中介绍的begin()和end()函数,begin返回的是第一个字符的迭代器,end返回的是最后一个字符下一个位置的迭代器(即\0的迭代器)。
迭代器的用法类似于指针,不仅string有迭代器,其他容器也有迭代器,有的本质上是指针,有的不是指针,每种容器的迭代器的本质都不一样。
迭代器的好处就是我们可以使用类似的方式访问不同的支持迭代器的容器,也就是我们学习会了一种容器的迭代器就相当于也会使用了其他容器的迭代器。
对于string这类连续性的容器,我们有三种访问方式:
string s1("123456");
第一种:
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << *it1;
it1++;
}
cout << endl;
第二种:
int i = 0;
while (i < s1.size())
{
cout << s1[i];
i++;
}
cout << endl;
第三种:
for (auto& e : s1)
{
cout << e;
}
cout << endl;其实本质上只提供了两种,因为范围for本质也是迭代器,也就是说一个容器支持迭代器才会支持范围for。
operator[]可以像数组一样去访问,这种方式对于string,vector这样的数据结构是支持的,但是不支持list这样不连续的结构。
迭代器的分类
迭代器实际上可以看成两种大的区分方法:1.是否为const 2.是否为反向
void print(string& s)//正向打印普通对象
{
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it;
it++;
}
cout << endl;
}
void print_const(const string& s)正向打印const对象
{
string::const_iterator cit = s.cbegin();
while (cit != s.cend())
{
cout << *cit;
cit++;
}
cout << endl;
}
void print_reverse(string& s)//逆向打印普通对象
{
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit;
rit++;
}
cout << endl;
}
void print_const_reverse(const string& s)//逆向打印const对象
{
string::const_reverse_iterator crit = s.crbegin();
while (crit != s.crend())
{
cout << *crit;
crit++;
}
cout << endl;
}我们需要注意的是:无论是使用正向迭代器,还是反向迭代器,我们便利容器都是对迭代器进行++,而不是--。
4.string类对象的修改操作
push_back && append && operator+=


这三个操作符都是有关尾插的操作符,push_back是尾插一个字符,append是尾插一个字符串(但是它重载的太复杂了),前面这俩实际中都没有operator+=好用,因为operator+=可以追加一个字符,也可以追加一个字符串。
insert (插入数据)&& erase(删除数据)
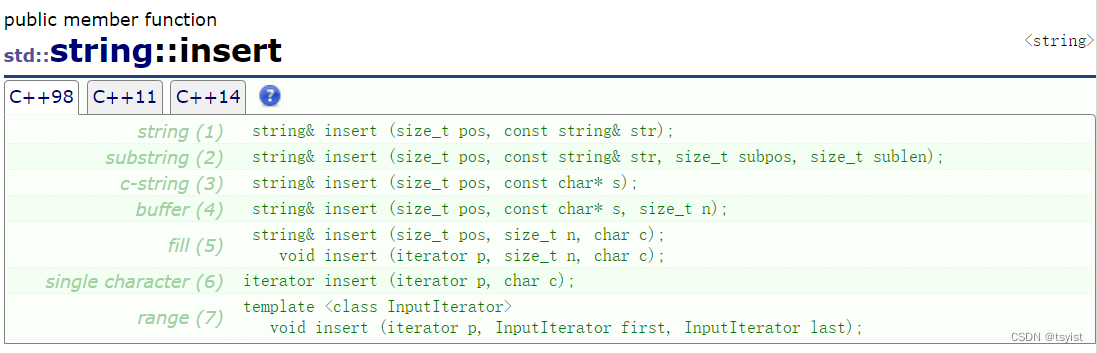

对于insert,我们能不用就不用,因为string本质上是个保存字符的数组,所以中间插入删除数据就需要挪动数据,代价很大。
对于erase,我们会注意他有一个缺省参数npos,npos是string这个类里的静态成员变量,他的值是-1。但是它是size_t类型,是无符号的,所以通过补码转换,他就是long long int能表示的最大正整数2^64。
find && rfind
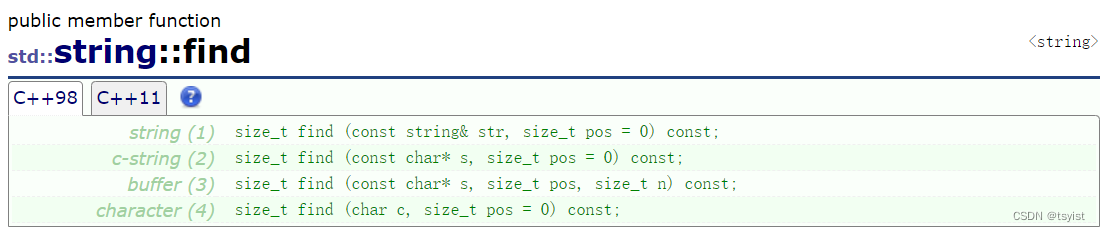
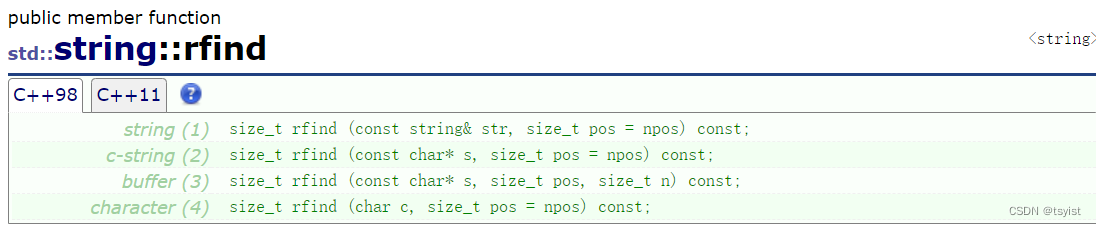
find和rfind都是查找函数,除了查找单个字符外还可以查找子字符串,返回值是查找的元素的下标,一般是int,若找不到则返回npos即一个极大的整数。
其中参数pos则是调用查找函数时开始查找的位置,find函数默认pos为0,rfind函数默认pos为npos。find是从前向后查找第一个字符或字符串;rfind则是从右往左查找,相当于查找最后一个字符或字符串的位置,返回值也是该字符或子字符串在字符串中的位置。
substr

生成子字符串。
c_str

返回string对象中的C数组,用于和C语言合用。
5.string类非成员函数
| 函数 | 功能说明 |
| operator+ | 最好少用,这是传值返回,深拷贝效率低 |
| operator>> | 输入运算符重载 |
| operator<< | 输出运算符重载 |
| getline | 获取一行字符串 |
| relational operators | 比较大小 |
operator+ && operator+=
这两个的作用都是尾插,但是+不会改变当前字符串,而+=会改变当前字符串。


(对比一下,operator+返回的是string,operator+=返回的是string&)
relational operators
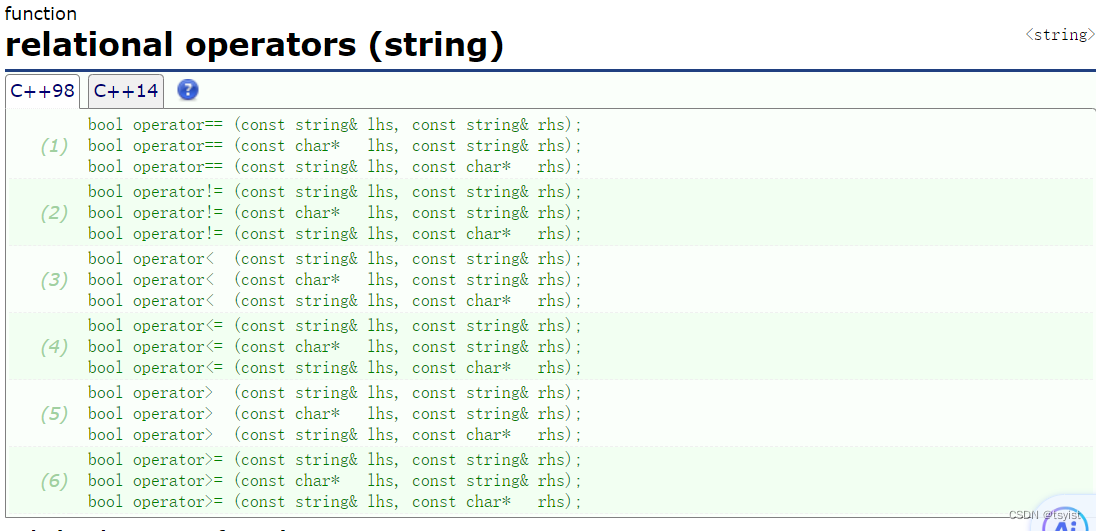
这并不是一个函数,而是一批函数。string提供的这批函数是用来比较字符串大小的,有很多的版本,例如:有string对象和string对象比的,还有C语言字符串和string对象比的等。实际上,这比较冗杂,因为C语言字符串是可以被隐式类型转换成string对象:
string s1("1111");
//正常写法,string支持单参数的构造函数
string s2 = "2222";
//隐式类型转换,早先是先将C语言字符串构造一个string,再将string拷贝构造s2。
//但现在编译器都已经优化成直接构造了
6.补充
to_string (数值转字符串)&& stoi(字符串转数值)
对于to_string,在C语言中有类似的itoa,但是它需要自己提供空间,且它并不是标准的C库,所以导致我们刷题的时候部分OJ是不支持的。

对于stoi:
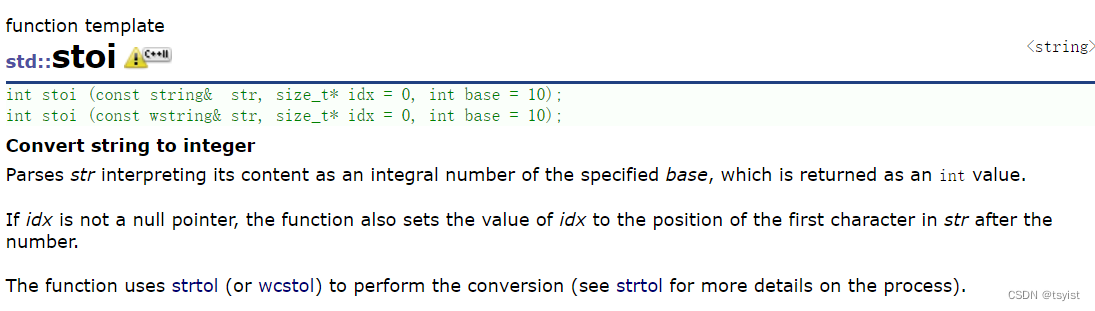
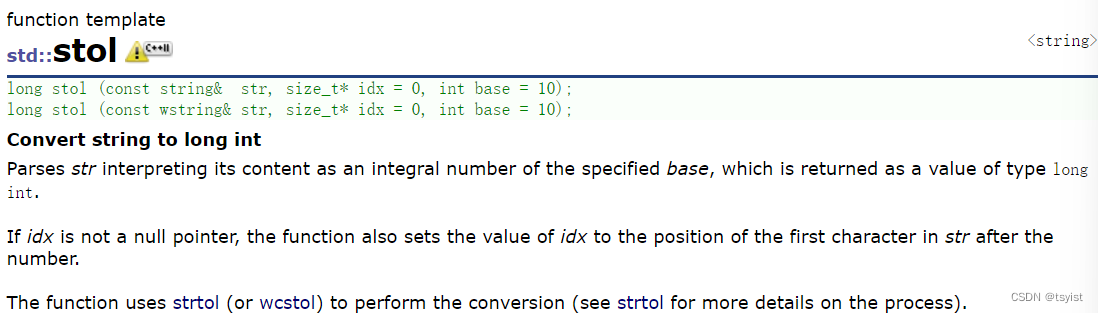
不仅有stoi用来将string对象转化为int类型,还有将string对象转化为long,或long long 等对象返回的函数:

这就是本章的全部内容,下篇文章我们将介绍string的模拟实现,文章有什么不足请大家指出,谢谢大家!!