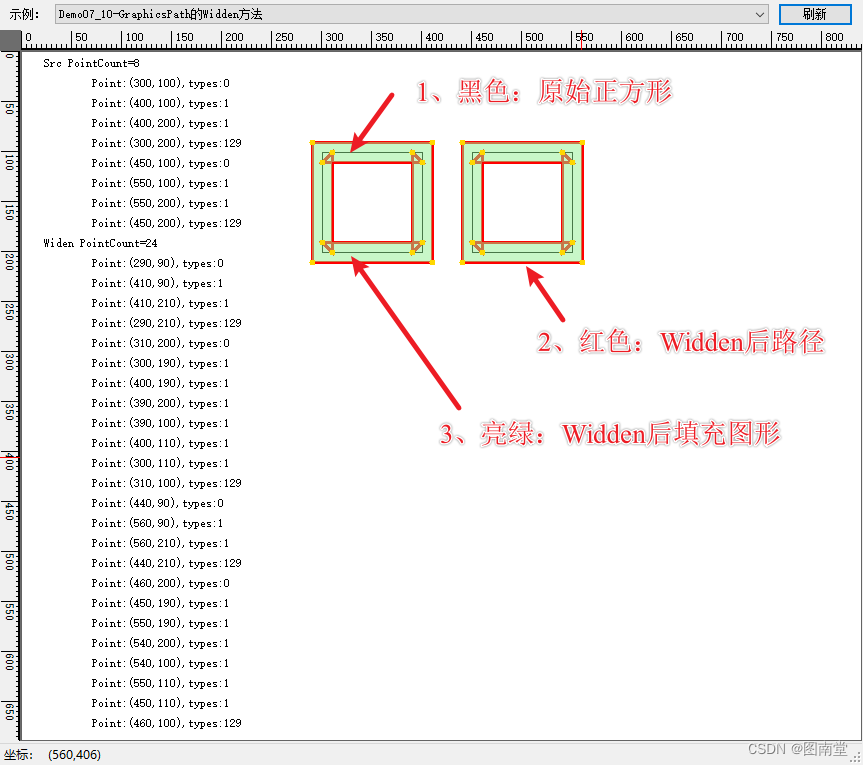
1.最佳分类个数
# 辅助确定最佳聚类数 4.7*2.6
factoextra::fviz_nbclust( t(DPAU_2), kmeans, method = "silhouette")

在2有下降拐点,但是样本较多时分成2类一般意义不大。
在7时也有下降拐点。
2.查看每个分类的轮廓系数
(1) pam k=5
library(cluster)
set.seed(101)
pamclu=cluster::pam(t(DPAU_2), k=5)
{
pdf( paste0(outputRoot, keyword, "_01_2.K_means.silhouette.pdf"), width=6, height=5)
df1=silhouette(pamclu)
plot(silhouette(pamclu),
col = (1+ head(df1, n=nrow(df1)) |> as.data.frame() |> pull("cluster")),
main=NULL)
dev.off()
}

Fig1. Silhouette plot displaying the composition (n = number of samples) and stability (average width) of clustering.
(2) pam k=6
library(cluster)
set.seed(101)
pamclu=cluster::pam(t(DPAU_2), k=6)
{
pdf( paste0(outputRoot, keyword, "_01_2.K_means.6.silhouette.pdf"), width=6, height=5)
df1=silhouette(pamclu)
plot(silhouette(pamclu),
col = (1+ head(df1, n=nrow(df1)) |> as.data.frame() |> pull("cluster")),
main=NULL)
dev.off()
}

(3) pam k=7
library(cluster)
set.seed(101)
pamclu=cluster::pam(t(DPAU_2), k=7)
{
pdf( paste0(outputRoot, keyword, "_01_2.K_means.7.silhouette.pdf"), width=6, height=5)
df1=silhouette(pamclu)
df1=head(df1, n=nrow(df1)) |> as.data.frame()
plot(silhouette(pamclu),
col = df1$cluster +1,
#xlim=c(min(df1$sil_width)-0.2, max(df1$sil_width))+0.2,
main=NULL)
dev.off()
}

(4) kmeans k=5
dat=DPAU_2
kclu=kmeans(t(dat), centers=5)
#kclu$clustering=kclu$cluster #add this list element: clustering
distance=dist( t(dat) ) #10min
kclu.sil=sortSilhouette( silhouette(kclu$cluster, dist = distance ) )
#rownames(kclu.sil)=colnames(dat)
head(kclu.sil)
# cluster neighbor sil_width
#1226 1 2 0.1124117
#991 1 2 0.1113240
pdf( paste0(outputRoot, keyword, "_01_2.K_means.5.silhouette.pdf"), width=6, height=5)
df1=kclu.sil
df1=head(df1, n=nrow(df1)) |> as.data.frame()
plot(kclu.sil,
col = rev(df1$cluster+1),
do.col.sort=F,
main=NULL)
factoextra::fviz_silhouette(kclu.sil)
dev.off()


(5) hclust, k=4
dat=DPAU_2
distance=dist( t(dat) )
out.hclust=hclust(distance, method = "ward.D2")
# visual
pdf( paste0(outputRoot, keyword, "_01_2.hclust.4.silhouette.pdf"), width=6, height=5)
plot(out.hclust,
#hang = -1,
#hang=0.1,
hang=0,
ann=F, axes=F,
labels = F, #no labels
cex = 0.7,
col = "grey20")
rect.hclust( out.hclust, k=4, border = c("#FF6B6B", "#4ECDC4", "#556270", "deeppink") )
# sil plot
out.hclust.D2=cutree(out.hclust, k=4)
sil_hclust=sortSilhouette(silhouette(out.hclust.D2, distance))
rownames(sil_hclust) = rownames(as.matrix(distance))[attr(sil_hclust, 'iOrd')]
#
plot(sil_hclust,
col=out.hclust.D2[rownames( head(sil_hclust, n=nrow(sil_hclust)) )]+1,
main=attr(sil_hclust, "call") |> deparse() )
dev.off()


3. 轮廓系数的解释
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。 它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
- 内聚度可以理解为反映一个样本点与类内元素的紧密程度。
- 分离度可以理解为反映一个样本点与类外元素的紧密程度。
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
- 当a(i)<b(i)时,即类内的距离小于类间距离,则聚类结果更紧凑。S的值会趋近于1。越趋近于1代表轮廓越明显。
- 相反,当a(i)>b(i)时,类内的距离大于类间距离,说明聚类的结果很松散。S的值会趋近于-1,越趋近于-1则聚类的效果越差。
- 轮廓系数S的取值范围为[-1, 1],轮廓系数越大聚类效果越好。
Ref:
- https://baike.baidu.com/item/轮廓系数/17361607
- https://pubmed.ncbi.nlm.nih.gov/32929364/