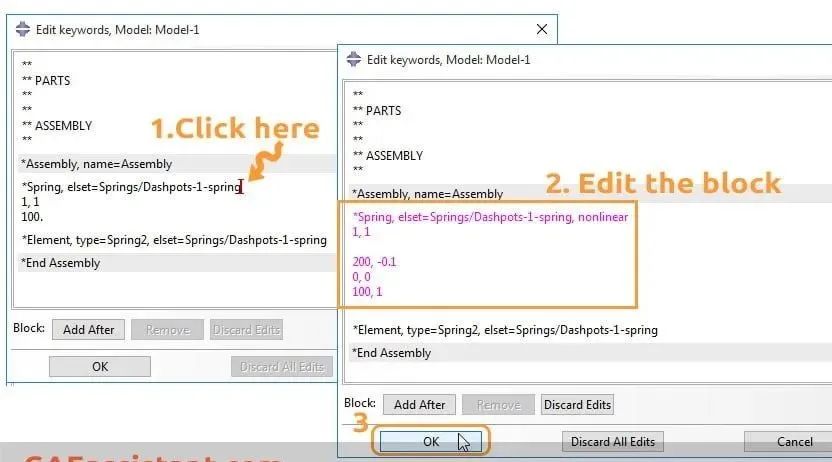
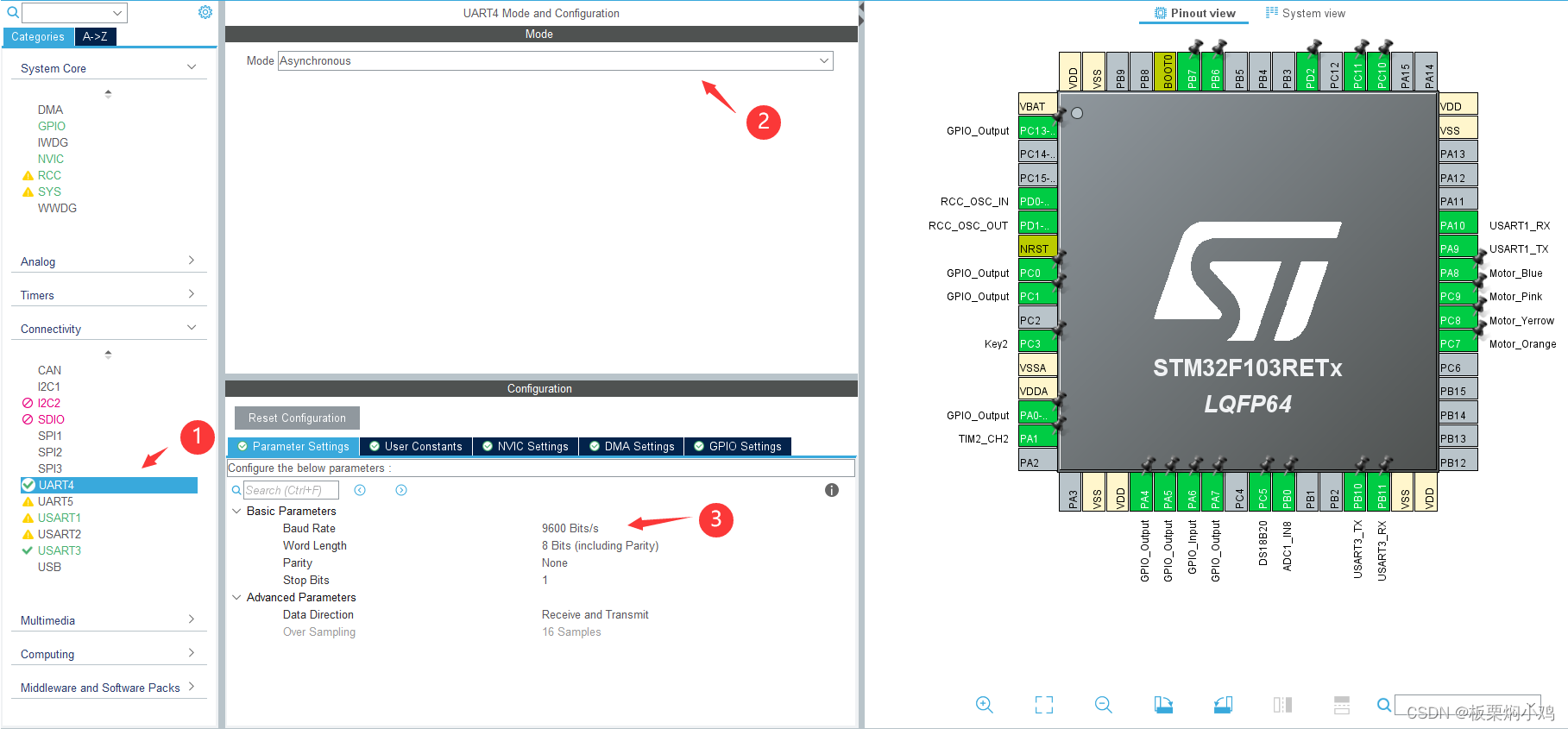
细粒度图像分类论文阅读笔记
- 摘要
- Abstract
- 1. 用于细粒度图像分类的聚合注意力模块
- 1.1 文献摘要
- 1.2 研究背景
- 1.3 本文创新点
- 1.4 计算机视觉中的注意力机制
- 1.5 模型方法
- 1.5.1 聚合注意力模块
- 1.5.2 通道注意力模块
- 通道注意力代码实现
- 1.5.3 空间注意力模块
- 空间注意力代码实现
- 1.5.4 CBAM注意力机制
- CBAM注意力代码实现
- 1.5.5 本文模型整体架构
- 1.6 实验
- 1.6.1 数据集
- 1.6.1 实施细节
- 1.6.2 实验结果
- 1.7 结论
- 总结
摘要
本周阅读了SCI二区的文章 Aggregate attention module for fine‑grained image classification,该论文解决了以往网络中的参数过多、计算过多的问题,提出了一种名为聚合注意力模块的注意力机制,可以用更少的参数对细粒度图像进行准确分类。所提出的注意力模块将通道注意力与空间注意力并行结合,有效地学习关键特征,并且可以轻松扩展到其他神经模型。本文将详细介绍该模型。
Abstract
This week I read the SCI Region 2 article Aggregate attention module for fine-grained image classification, which solves the problem of too many parameters and too much computation in the previous network by proposing an attention mechanism called aggregated attention module that can accurately classify fine-grained images with fewer parameters. The proposed attention module combines channel attention and spatial attention in parallel to learn key features efficiently and can be easily extended to other neural models. In this paper, the model is described in detail.
文献出处:Aggregate attention module for fine‑grained image classification
1. 用于细粒度图像分类的聚合注意力模块
1.1 文献摘要
注意力机制对于聚合特征和发现有区别的局部细节非常有用。网络中参数的增加会导致不必要的计算。本文提出了一种名为聚合注意力模块的注意力机制,可以用更少的参数对细粒度图像进行准确分类。 具体来说,为了平衡性能和复杂性之间的权衡,所提出的注意力模块将通道注意力与空间注意力并行结合,有效地学习关键特征,并且可以轻松扩展到其他神经模型。 与最先进的模型相比,实验表明,作者提出的模型可以使用不同的细粒度图像基准(CUB-200-2011、FGVC Aircraft 和Stanford Cars)实现卓越的精度。
1.2 研究背景
细粒度图像分类就是将同一物种进行细分,比如将猫的种类细分,同一类别的图像之间的差异就比较小,由于特定细粒度子类别之间的类间差异较小,以及类内差异较大,因此它不同于传统的图像分析问题。由于细粒度图像具有标记粒度细的特点,因此直接利用整个图像级别的所有特征来识别细粒度图像是很不合理的,如下图所示:

上图每行的三张图片属于同一鸟类。 可以观察到,同一物种的鸟类受拍摄角度和环境的影响也有很大差异。我们很容易看出,即使属于同一子类别的图像本身在形态、姿势、背景等方面也存在巨大差异,基于这个研究背景,我们需要有效解决类别内差异问题。
针对这个问题,本文作者提出一种 利用注意力机制的细粒度图像分类 方法。 该方法在提取图像的细粒度特征的同时,消除了有害特征对分类性能的影响。 训练时尽量少使用细粒度的标记数据,以提高细粒度图像分类的效果。
1.3 本文创新点
- 提出了聚合注意力模块来平衡细粒度图像分类任务的性能和复杂性之间的权衡,该模块可广泛应用于神经网络中。
- 设计并在整个网络中使用跨通道损失函数,以提高深度卷积神经网络的特征学习和表达能力。
- 在四个不同的公共基准数据集上针对细粒度图像分类任务进行了广泛的实验,模型的性能优秀。
1.4 计算机视觉中的注意力机制
注意力思想已被应用于计算机视觉任务,包括图像标记、目标检测等,特别是图像分类。 2019年,注意力网络模型CBAM被开发出来,其中 Convolutional block attention module 和 Attention-based label consistency for semi-supervised deep learning based image classification 将通道注意力与空间注意力相结合,下周将详细介绍这两篇论文。视觉注意机制通过通道或空间尺度操作来探索图像关键部分的特征。 但对于类内差异而言,一般的视觉注意机制并不能表现出突出的效果。
本文作者提出了一种简单有效的注意力单元,称为聚合注意力模块,具有跨通道损失函数。 创新的注意力模块擅长发现细微差异,并且优于其他注意力机制。
1.5 模型方法
SENet专注于通道维度的注意力计算,对通道之间的相互依赖关系进行建模,并通过网络的全局损失函数自适应地重新校正通道之间特征的相应强度。 它的目的是有选择地增强有用的特征并抑制不太有用的特征。 尽管SE块表现良好,但整个模型的成本增加了,这体现在参数数量以及额外的训练周期上。
ECA-Net是一种超通道注意力模块,仅涉及k(k≤9)个参数,但却带来了显着的性能提升,ECA-Net一味追求减少通道注意力中的参数数量,而忽略了空间注意力的有效性,这在一定程度上影响了模型的准确性。
作者提出的模型综合解决了上述两个网络模型的缺陷,将通道注意力和空间注意力的有效使用结合起来。 在保证优异性能的同时最大限度地减少参数数量。 对于细粒度的图像分类任务,具有出色的学习能力和泛化能力。
1.5.1 聚合注意力模块
作者将 ResNet 修改为深度神经网络架构中的骨干网络。 给定中间生成的特征矩阵 F ∈
R
C
×
H
×
W
R^{C×H×W}
RC×H×W 作为模块输入,所提出的 AAM 并行生成 1D 通道注意力图
M
c
∈
R
C
×
1
×
1
M_c ∈ R^{C×1×1}
Mc∈RC×1×1 和 2D 空间注意力图
M
s
∈
R
1
×
H
×
W
M_s ∈ R^{1×H×W}
Ms∈R1×H×W 。 整个注意力过程表示为:![]()
1.5.2 通道注意力模块
为了平衡通道注意力的额外计算成本和提高的模型精度,当我们利用特征通道之间的相关性生成通道注意力特征图时,本文仅提取k个通道的相关信息。 k 个通道与当前通道相邻。 此外,全局最大池化可以提取有效的空间特征。输入特征图矩阵通过通道全局最大池化进行操作,并通过 sigmoid 函数在 0 和 1 之间生成。
因此,对输入的原始特征图进行全局最大池化,提取并学习相邻k通道信息。 生成的通道注意力张量按元素相加。 通过sigmoid函数并通过复制路径进行相应的广播,最终与原始输入特征图矩阵逐个相乘。 这是通道注意力模块的输出。 图4展示了通道注意力模块的结构。 简而言之,通道注意力表示为:
下图为通道注意力模块的结构。 给定输入特征图,该模块通过大小为 k 的全局最大池化操作生成通道权重,其中 k 由经验确定

通道注意力机制的核心思想是让模型自动学习每个通道的重要性,并根据通道的贡献调整输入数据的表示。通过引入通道注意力机制,模型可以更加有效地利用每个通道的信息,提高模型对输入数据的表征能力,从而改善模型在各种任务中的性能。
如下图:先将输入特征图分别进行全局最大池化和全局平均池化(是在特征层的高和宽上进行池化),得到两张不同维度的特征描述。然后池化后的特征图共用一个多层感知器网络,先通过一个全连接层进行特征降维,再通过全连接层进行特征升维。将两张特征图在通道维度堆叠,经过 sigmoid 激活函数将特征图的每个通道的权重归一化到0-1之间。最后,将归一化后的权重和输入特征图相乘,得到处理好的特征图。

通道注意力代码实现
import torch.nn as nn
import torch
import torch.nn.functional as f
print("************************通道注意力机制*********************")
# 通道注意力机制
class ChannelAttention(nn.Module):
# 初始化,in_planes参数指定了输入特征图的通道数,ratio参数用于控制通道注意力机制中特征降维和升维过程中的压缩比率。默认值为8
def __init__(self, in_planes, ratio=8):
# 继承父类初始化方法
super().__init__()
# 全局最大池化 [b,c,h,w]==>[b,c,1,1]
self.avg_pool = nn.AdaptiveAvgPool3d((4, 1, 1)) # C*H*W
# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
self.max_pool = nn.AdaptiveMaxPool3d((4, 1, 1)) # C*H*W
# 使用1x1x1卷积核代替全连接层进行特征降维
self.fc1 = nn.Conv3d(in_planes, in_planes // ratio, 1, bias=False)
# 激活函数
self.relu1 = nn.ReLU()
# 使用1x1x1卷积核进行特征升维
self.fc2 = nn.Conv3d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通过平均池化和最大池化后的特征进行卷积、激活、再卷积操作
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) # 平均池化-->卷积-->RELu激活-->卷积
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) # 最大池化-->卷积-->RELu激活-->卷积
# 将两个输出相加
out = avg_out + max_out
# 应用Sigmoid函数
return self.sigmoid(out)
# 创建ChannelAttention模型的实例,输入通道数为256
model = ChannelAttention(256)
# 打印模型结构
print(model)
# 创建一个形状为[2, 256, 4, 8, 8]的输入张量,所有元素初始化为1
inputs = torch.ones([2, 256, 4, 8, 8]) # 2是批次大小(batch size),256是通道数,4、8、8分别是深度、高度和宽度的维度
# 将输入张量传递给模型,并获取输出
outputs = model(inputs)
# 打印输入张量的形状
print(inputs.shape) # [2, 256, 4, 8, 8]
# 打印输出张量的形状
print(outputs.shape) # [2, 256, 4, 1, 1]
输出结果

1.5.3 空间注意力模块
与通道注意力不同,空间注意力提供了更有用的信息,重点关注图像的不同位置。 由于基于空间尺度的全局最大池化操作,可以有效地提取特征图的关键特征。 就全局平均池化操作而言,一方面可以尽可能保存特征图的整体信息。 另一方面,同一类别差异可能较大,关键部位可能会受到光照、遮挡等因素的影响,可能导致学习效果不足。 全局平均池化操作可以在一定程度上缓解这一障碍。
本文将特征图的空间注意力分布逐个元素地传递、复制并与原始输入特征图矩阵相乘,即为空间注意力模块
M
s
(
F
)
∈
R
1
×
H
×
W
M_s(F) ∈ R^{1×H×W}
Ms(F)∈R1×H×W 的输出。 空间注意力模块的结构如下图所示。我们使用两次池化计算来合成当前特征矩阵的空间值,获得两个2D中间图
M
s
a
v
g
∈
R
1
×
H
×
W
M^{avg}_{s} ∈ R^{1×H×W}
Msavg∈R1×H×W和
M
s
m
a
x
∈
R
1
×
H
×
W
M^{max}_{s} ∈ R^{1×H×W}
Msmax∈R1×H×W。 每个特征图代表通道中的平均池化特征以及最大池化特征。 该模块通过标准卷积层将它们连接起来并进行卷积以生成2D空间注意力分布。 简而言之,空间注意力定义为:

空间注意力代码实现
import torch.nn as nn
import torch
import torch.nn.functional as f
print("************************空间注意力机制*********************")
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
# 断言法:kernel_size必须为3或7
assert kernel_size in (3, 7),'kernel size must be 3 or 7'
# 三元操作:如果kernel_size的值等于7,则padding被设置为3;否则(即kernel_size的值为3),padding被设置为1。
padding = 3 if kernel_size == 7 else 1
# 定义一个卷积层,输入通道数为2,输出通道数为1
self.conv1 = nn.Conv3d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# (N, C, H, W),dim=1沿着通道维度C,计算张量的平均值和最大值
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 将平均值和最大值在通道维度上拼接
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
model = SpatialAttention(kernel_size=7)
print(model)
inputs = torch.ones([2, 256, 4, 8, 8])
outputs = model(inputs)
print(inputs.shape)
print(outputs.shape)
输出结果

空间注意力机制(Spatial Attention Module)是一种用于处理空间信息的注意力机制,主要用于在深度学习模型中动态地调整输入数据的不同空间位置的重要性,以增强有用信息并抑制无用信息。在图像处理等领域,空间注意力机制可以帮助模型更好地关注图像中不同区域的特征,从而提高模型的表征能力和性能。
1.5.4 CBAM注意力机制
CBAM(Convolutional Block Attention Module)模块是一种结合了通道注意力和空间注意力机制的注意力模块,旨在提高卷积神经网络(CNN)对图像特征的表征能力。CBAM模块通过同时关注通道维度和空间维度的特征信息,实现了对图像特征的全局感知和重要性调整。
CBAM模块通常由两个子模块组成:通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)。这两个子模块分别用于对通道维度和空间维度的特征进行加权调整,从而提高特征表示的表征能力。(两个Attention进行串联,Channel 在前,Spatial在后)如下图:

模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征修饰。 由于CBAM是轻量级的通用模块,因此可以以可忽略的开销将其无缝集成到任何CNN架构中,并且可以与基础CNN一起进行端到端训练。
CBAM注意力代码实现
import torch.nn as nn
import torch
import torch.nn.functional as f
print("************************通道注意力机制*********************")
# 通道注意力机制
class ChannelAttention(nn.Module):
# 初始化,in_planes参数指定了输入特征图的通道数,ratio参数用于控制通道注意力机制中特征降维和升维过程中的压缩比率。默认值为8
def __init__(self, in_planes, ratio=8):
# 继承父类初始化方法
super().__init__()
# 全局最大池化 [b,c,h,w]==>[b,c,1,1]
self.avg_pool = nn.AdaptiveAvgPool3d((4, 1, 1)) # C*H*W
# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
self.max_pool = nn.AdaptiveMaxPool3d((4, 1, 1)) # C*H*W
# 使用1x1x1卷积核代替全连接层进行特征降维
self.fc1 = nn.Conv3d(in_planes, in_planes // ratio, 1, bias=False)
# 激活函数
self.relu1 = nn.ReLU()
# 使用1x1x1卷积核进行特征升维
self.fc2 = nn.Conv3d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通过平均池化和最大池化后的特征进行卷积、激活、再卷积操作
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) # 平均池化-->卷积-->RELu激活-->卷积
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) # 最大池化-->卷积-->RELu激活-->卷积
# 将两个输出相加
out = avg_out + max_out
# 应用Sigmoid函数
return self.sigmoid(out)
# 创建ChannelAttention模型的实例,输入通道数为256
model = ChannelAttention(256)
# 打印模型结构
print(model)
# 创建一个形状为[2, 256, 4, 8, 8]的输入张量,所有元素初始化为1
inputs = torch.ones([2, 256, 4, 8, 8]) # 2是批次大小(batch size),256是通道数,4、8、8分别是深度、高度和宽度的维度
# 将输入张量传递给模型,并获取输出
outputs = model(inputs)
# 打印输入张量的形状
print(inputs.shape) # [2, 256, 4, 8, 8]
# 打印输出张量的形状
print(outputs.shape) # [2, 256, 4, 1, 1]
print("************************空间注意力机制*********************")
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
# 断言法:kernel_size必须为3或7
assert kernel_size in (3, 7),'kernel size must be 3 or 7'
# 三元操作:如果kernel_size的值等于7,则padding被设置为3;否则(即kernel_size的值为3),padding被设置为1。
padding = 3 if kernel_size == 7 else 1
# 定义一个卷积层,输入通道数为2,输出通道数为1
self.conv1 = nn.Conv3d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# (N, C, H, W),dim=1沿着通道维度C,计算张量的平均值和最大值
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 将平均值和最大值在通道维度上拼接
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
model = SpatialAttention(kernel_size=7)
print(model)
inputs = torch.ones([2, 256, 4, 8, 8])
outputs = model(inputs)
print(inputs.shape)
print(outputs.shape)
print("************************CBAM模块*********************")
class CBAM_Block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=3):
super().__init__()
# 初始化通道注意力模块
self.channelAttention = ChannelAttention(channel, ratio=ratio)
# 初始化空间注意力模块
self.SpatialAttention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
# 应用通道注意力和空间注意力
x = x * self.channelAttention(x)
x = x * self.SpatialAttention(x)
return x
model = CBAM_Block(256)
print(model)
inputs = torch.ones([2, 256, 4, 8, 8])
outputs = model(inputs)
print(inputs.shape)
print(outputs.shape)
输出结果

1.5.5 本文模型整体架构
该方法的架构如下图所示。给定前面的卷积块获得的特征图,聚合注意力模块将通道注意力和空间注意力结合起来计算注意力分布。 生成的最终分布被输入到下一个卷积块。 网络的整体损失是通过提出的跨通道损失和交叉熵损失来计算的。

1.6 实验
1.6.1 数据集
作者在四个广泛采用的细粒度基准上验证了模型。 实验期间的基准数据是 Caltech-UCSD-Birds (CUB-200-2011)、FGVC-Aircraft (Maji et al. 2013)、Stanford Cars 和 Stanley Dogs (Khosla et al. 2011)。 数据集的详细介绍如下表所示。

1.6.1 实施细节
采用 PyTorch 框架来实现我们提出的方法。 随机梯度下降优化器与“poly”的学习率策略一起使用(动量参数设置为0.8,初始学习率设置为1e−4,终止学习率设置为1e−6,并且 权重衰减设置为 2.5e−4)。 我们在并行 Titan XP GPU 上训练我们提出的模型 200 个时期。 训练图像的批量大小设置为 16。所有原始图像都经过随机重新缩放、裁剪和翻转。 然后将输入训练图像的大小调整为 224 × 224,而用于验证和测试的图像根本不必改变。 经过实验验证,不同的 η 值以及数据集相应的训练效果如表 2 所示。请注意,我们从头开始训练我们的网络,这意味着除了官方提供的数据集中的标记图像之外,我们不需要使用任何额外的数据 。 此外,我们将超参数μ设置为0.01。
1.6.2 实验结果
如下表所示,AAM 方法比其他 SOTA 模型表现更好。 具体来说,我们提出的方法显示,CUB-200-2011 上的结果明显改善了 0.7%,FGVC-Aircraft 上改善了 1.5%,Stanford Cars 上改善了 0.2%,Stanford Dogs 上改善了 2.7%。 这项工作提供了图 7,将所提出的 CC-Loss 与中心损失(Wen et al. 2016)和交叉熵损失(CE 损失)进行比较。 在这个实验中,模型都是从头开始训练的。

1.7 结论
在本文中,作者提出了用于细粒度图像分类任务的 AAM。 在这个注意力模块中,作者并行地将通道注意力和空间注意力结合起来。 此外,作者还开发了 CC-Loss 来最大化细粒度图像类别之间的差异。 大量实验表明,无论骨干网络如何,所提出的 AAM 的性能都比其他最近使用的模型好得多。
总结
本周学习了AAM模型,聚合注意力模块、通道注意力、空间注意力模块,同时也进行了代码实践,下周将继续学习细粒度图像相关的文献模型。加油~