📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.创建数据库
- ✨ 1.1 语法格式
- ✨ 1.2 案例示例
- 📣 2.创建表
- ✨ 2.1 语法格式
- ✨ 2.2 案例示例
- 📣 3.DML语句
- ✨ 3.1 INSERT
- ✨ 3.2 UPDATE
- ✨ 3.3 DELETE
- 📣 4.SELECT语句
- ✨ 4.1 语法格式
- ✨ 4.2 案例示范
- 📣 5.WHERE子句
- ✨ 5.1 语法格式
- ✨ 5.2 案例示范
- 📣 6.ORDER BY子句
- ✨ 6.1 语法格式
- ✨ 6.2 案例示范
- 📣 7.DISTINCT
- ✨ 7.1 语法格式
- ✨ 7.2 案例示范
- 📣 8.GROUP BY子句
- ✨ 8.1 语法格式
- ✨ 8.2 案例示范
- 📣 9.HAVING子句
- ✨ 9.1 语法格式
- ✨ 9.2 案例示范
前言
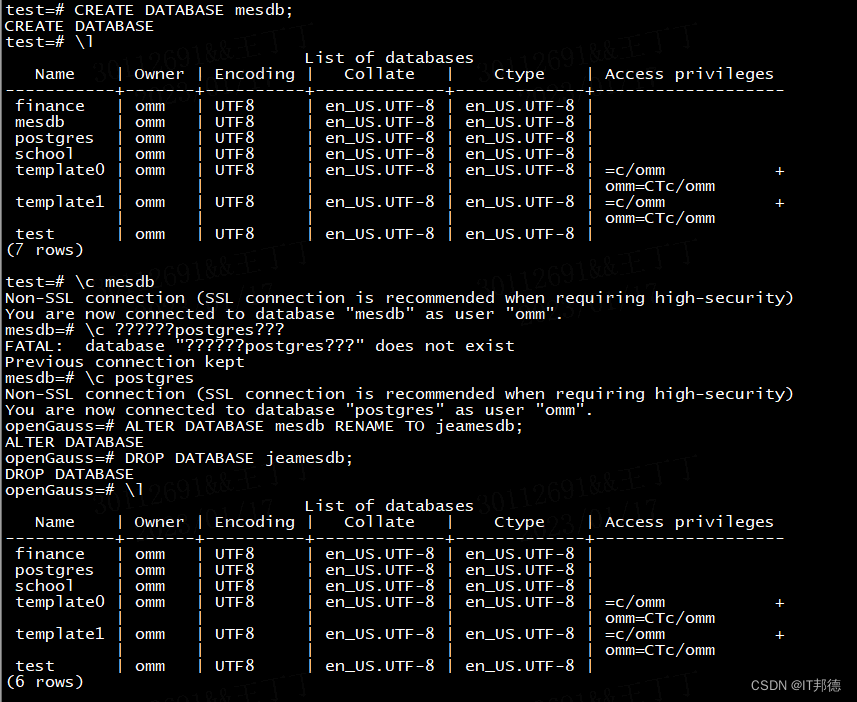
本篇介绍了openGauss数据库初级管理,包括创建数据库、DML语句及常用的SQL检索等📣 1.创建数据库
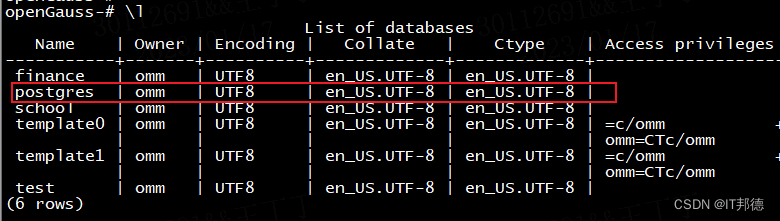
数据库安装完成后,默认生成名称为postgres的数据库。您需要自己创建一个新的数据库。
✨ 1.1 语法格式
##创建数据库
CREATE DATABASE database_name;
##查看数据库
使用“\l”用于查看已经存在的数据库。
openGauss-# \l
使用 “\c + 数据库名” 进入已存在数据库。
openGauss-# \c test
##修改数据库
ALTER DATABASE database_name RENAME TO new_name;
##删除数据库
DROP DATABASE database_name ;
📢📢📢 参数说明
database_name:要创建、修改或者删除的数据库名称
new_name:数据库的新名称
✨ 1.2 案例示例
1)创建一个新的数据库mesdb
test=# CREATE DATABASE mesdb;
2)使用“\l”用于查看已经存在的数据库。
test=# \l
3)使用 “\c + 数据库名” 来进入mesdb数据库。
test=# \c mesdb
4)切换数据库为postgres数据库
mesdb=# \c postgres
5)将mesdb数据库名称修改为jeamesdb。
openGauss=# ALTER DATABASE mesdb RENAME TO jeamesdb;
6)删除数据库jeamesdb。
openGauss=# DROP DATABASE jeamesdb;
📣 2.创建表
在不同的数据库中可以存放相同的表。您可以使用CREATE TABLE语句创建表,该表由命令执行者所有
✨ 2.1 语法格式
CREATE TABLE table_name (column_name data_type [, ... ]);
📢📢📢 参数说明:
table_name:要创建的表名。
column_name:新表中要创建的字段名。
data_type:字段的数据类型。
✨ 2.2 案例示例
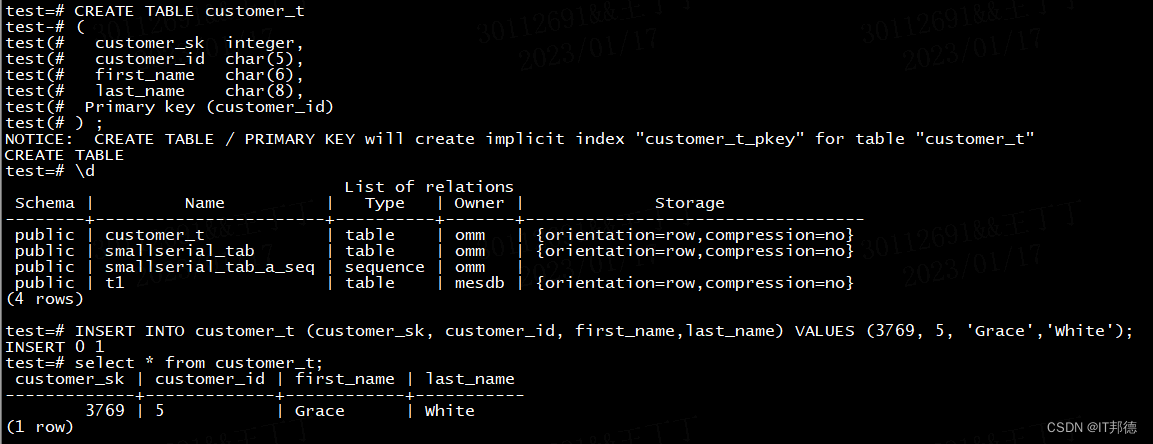
##创建表
test=# CREATE TABLE customer_t
(
customer_sk integer,
customer_id char(5),
first_name char(6),
last_name char(8),
Primary key (customer_id)
) ;
##查看表
test=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+-----------------------+----------+-------+----------------------------------
public | customer_t | table | omm | {orientation=row,compression=no}
public | smallserial_tab | table | omm | {orientation=row,compression=no}
public | smallserial_tab_a_seq | sequence | omm |
public | t1 | table | mesdb | {orientation=row,compression=no}
(4 rows)
## 查看表的结构
test=# \d customer_t
Table "public.customer_t"
Column | Type | Modifiers
-------------+--------------+-----------
customer_sk | integer |
customer_id | character(5) | not null
first_name | character(6) |
last_name | character(8) |
Indexes:
"customer_t_pkey" PRIMARY KEY, btree (customer_id) TABLESPACE pg_default
##插入数据
test=# INSERT INTO customer_t (customer_sk, customer_id, first_name,last_name)
VALUES (3769, 5, 'Grace','White');
📣 3.DML语句
✨ 3.1 INSERT
INSERT INTO语句用于向表中插入新记录。该语句可以插入一行数据也可以同时插入多行数据
📢📢📢 语法格式
INSERT INTO table_name [ ( column_name [, …] ) ]
{ DEFAULT VALUES
| VALUES {( { expression | DEFAULT } [, …] ) }[, …] };
参数说明:
table_name:要插入数据的目标表名。
column_name:目标表中的字段名
1)字段名可以有子字段名或者数组下标修饰。
2)没有在字段列表中出现的每个字段,将由系统默认值,或者声明时的默认值填充,若都没有则用NULL填充。例如,向一个复合类型中的某些字段插入数据的话,其他字段将是NULL。
3)目标字段(column_name)可以按顺序排列。如果没有列出任何字段,则默认全部字段,且顺序为表声明时的顺序。
4)如果value子句只提供了N个字段,则目标字段为前N个字段。
5)value子句提供的值在表中从左到右关联到对应列。
expression:赋予对应column的一个有效表达式或值
1)向表中字段插入单引号 " ’ “时需要使用单引号自身进行转义。
2)如果插入行的表达式不是正确的数据类型,系统试图进行类型转换,若转换不成功,则插入数据失败,系统返回错误信息。
DEFAULT:对应字段名的缺省值。如果没有缺省值,则为NULL
📢📢📢 案例示范
1)数据值是按照这些字段在表中出现的顺序列出的,并且用逗号分隔。通常数据值是文本(常量),但也允许使用标量表达式。
test=# INSERT INTO customer_t(customer_sk, customer_id, first_name) VALUES (3769, 'hello', 'Grace');
2)已经知道表中字段的顺序,也可无需列出表中的字段
test=# INSERT INTO customer_t VALUES (3770, 'it', 'Grace',DEFAULT);
3)字段可以忽略其中的一些,没有数值的字段将被填充为字段的缺省值
test=# INSERT INTO customer_t (customer_sk, customer_id,first_name) VALUES (3771, 'jem','Grace');
4)表中插入多行,请使用以下命令
test=# INSERT INTO customer_t (customer_sk, customer_id, first_name) VALUES
(6885, 'maps', 'Joes'),
(4321, 'tpcds', 'Lily'),
(9527, 'world', 'James');
test=# select * from customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3769 | 5 | Grace | White
3769 | hello | Grace |
3770 | it | Grace |
3771 | jem | Grace |
6885 | maps | Joes |
4321 | tpcds | Lily |
9527 | world | James |
✨ 3.2 UPDATE
UPDATE修改满足条件的所有行中指定的字段值,WHERE子句声明条件,SET子句指定的字段会被修改,没有出现的字段保持它们的原值。
📢📢📢 语法格式
UPDATE table_name
SET column_name = { expression | DEFAULT }
[WHERE condition ];
参数说明:
table_name:要更新的表名,可以使用模式修饰,例如myshcema.table
expression:赋给字段的值或表达式
column_name:要修改的字段名
condition:一个返回Boolean类型结果的表达式,只有这个表达式返回true的行才会被更新。
📢📢📢 案例示范
1)将表customer_t中customer_sk为9527的地域重新定义为9876。
test=# UPDATE customer_t SET customer_sk = 9876 WHERE customer_sk = 9527;
test=# select * from customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3769 | 5 | Grace | White
3769 | hello | Grace |
3770 | it | Grace |
3771 | jem | Grace |
6885 | maps | Joes |
4321 | tpcds | Lily |
9876 | world | James |
2)把表customer_t所有customer_sk的值增加100:
test=# UPDATE customer_t SET customer_sk = customer_sk + 100;
test=# select * from customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
4421 | tpcds | Lily |
9976 | world | James |
3)可以在一个UPDATE命令中更新更多的字段,方法是在SET子句中列出更多赋值
test=# UPDATE customer_t SET customer_id = 'Admin', first_name = 'Local' WHERE customer_sk = 4421;
test=# select * from customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
9976 | world | James |
4421 | Admin | Local |
✨ 3.3 DELETE
DELETE语句可以从指定的表里删除满足WHERE子句的行。如果WHERE子句不存在,将删除表中所有行,只保留表结构。
📢📢📢 语法格式
DELETE FROM table_name [WHERE condition];
参数说明:
table_name:目标表的名称(可以有模式修饰)
condition:一个返回Boolean值的表达式,用于判断哪些行需要被删除
📢📢📢 案例示范
1)创建表customer_t_bak,表的结构、数据与customer_t一致
test=# CREATE TABLE customer_t_bak AS TABLE customer_t;
--创建的表customer_t_bak,数据如下:
test=# select * from customer_t_bak;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
9976 | world | James |
4421 | Admin | Local |
2)删除customer_t_bak中c_customer_sk等于3869的职员
test=# DELETE FROM customer_t_bak WHERE customer_sk = 3869;
--可以看到customer_sk等于3869的行已经被删除。
test=# select * from customer_t_bak;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
9976 | world | James |
4421 | Admin | Local |
3)默认删除整张表的数据,仅保留表结构
test=# DELETE FROM customer_t_bak;
test=# select * from customer_t_bak;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
(0 rows)
📣 4.SELECT语句
SELECT语句用于从表或视图中取出数据,结果被存储在一个结果表中,称为结果集。
SELECT语句就像叠加在数据库表上的过滤器,利用SQL关键字从数据表中过滤出用户需要的数据。
✨ 4.1 语法格式
SELECT
{ * | [column, …] }
[ FROM from_item [, …] ];
参数说明:
1)指定查询表中列名,可以是部分列或者是全部,通配符*表示全部列。
列名可以用下面两种形式表达:
A.手动输入列名,多个列之间用英文逗号(,)分隔。
B.可以是FROM子句里面计算出来的字段。
2)FROM子句
为SELECT声明一个或者多个源表。FROM子句涉及多个元素,常见元素如下
A.table_name
表名或视图名,名称前可加上模式名,如:schema_name.table_name。表名为最常见的元素。
B.subquery
FROM子句中可以出现子查询,创建一个临时表保存子查询的输出
C.alias
给表或复杂的表引用起一个临时的表别名,以便被其余的查询引用
D.join_type
在openGauss中,JOIN有五种连接类型:
CROSS JOIN :交叉连接
INNER JOIN:内连接
LEFT OUTER JOIN:左外连接
RIGHT OUTER JOIN:右外连接
FULL OUTER JOIN:全外连接
✨ 4.2 案例示范
1.读取表customer_t中所有的数据
test=# SELECT * FROM customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
9976 | world | James |
4421 | Admin | Local |
2.读取表customer_t中指定字段customer_sk、customer_id。
test=# SELECT customer_sk,customer_id FROM customer_t;
customer_sk | customer_id
-------------+-------------
3869 | 5
3869 | hello
3870 | it
3871 | jem
6985 | maps
9976 | world
4421 | Admin
📣 5.WHERE子句
WHERE子句构成一个行选择表达式,用于指定条件而获取的数据,如果给定的条件满足,才返回从表中的具体数值.
✨ 5.1 语法格式
SELECT
{ * | [column, …] }
[ FROM from_item [, …] ]
[ WHERE condition ];
参数说明:
WHERE子句:在WHERE子句中可以使用比较运算符或逻辑运算符,例如 >, <, =, LIKE, NOT 等等。
condition:condition是返回值为布尔型的任意表达式,任何不满足该条件的行都不会被检索。
✨ 5.2 案例示范
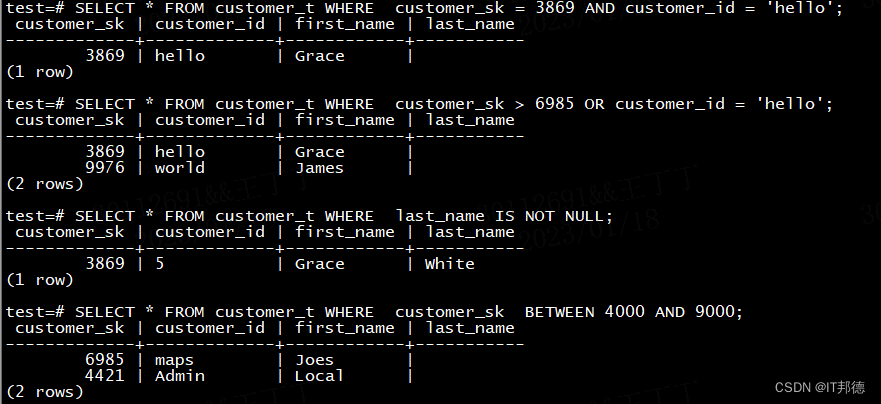
1.找到customer_id为hello且customer_sk为3869的行。
test=# SELECT * FROM customer_t WHERE customer_sk = 3869 AND customer_id = 'hello';
2.找到customer_sk大于6985或者customer_id为hello的行。
test=# SELECT * FROM customer_t WHERE customer_sk > 6985 OR customer_id = 'hello';
3.找到customer_t中last_name字段不为空的行。
test=# SELECT * FROM customer_t WHERE last_name IS NOT NULL;
4.找到customer_sk在4000和9000之间的行。
test=# SELECT * FROM customer_t WHERE customer_sk BETWEEN 4000 AND 9000;
📣 6.ORDER BY子句
ORDER BY对对SELECT语句检索得到的一列或者多列数据进行升序(ASC)或者降序(DESC)排列。
✨ 6.1 语法格式
SELECT
{ * | [column, …] }
[ FROM from_item [, …] ]
[ ORDER BY {expression [ ASC | DESC ] }];
参数说明:
对SELECT语句检索得到的数据进行升序或降序排序,对于ORDER BY表达式中包含多列的情况:
1)首先根据最左边的列进行排序,如果这一列的值相同,则根据下一个表达式进行比较,依此类推。
2)如果对于所有声明的表达式都相同,则按随机顺序返回。
✨ 6.2 案例示范
1.对结果根据customer_sk字段值进行升序排列。
test=# SELECT * FROM customer_t ORDER BY customer_sk ASC;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
4421 | Admin | Local |
6985 | maps | Joes |
9976 | world | James |
2.对结果根据customer_sk字段值进行降序,first_name升序排列。
test=# SELECT * FROM customer_t ORDER BY customer_sk DESC,first_name ;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
9976 | world | James |
6985 | maps | Joes |
4421 | Admin | Local |
3871 | jem | Grace |
3870 | it | Grace |
3869 | 5 | Grace | White
3869 | hello | Grace |
📣 7.DISTINCT
DISTINCT关键字与SELECT语句一起使用,用于去除重复记录,只获取唯一的记录。
✨ 7.1 语法格式
SELECT DISTINCT [ ON ( expression [, …] ) ] ]
{ * | [column, …] }
[ FROM from_item [, …] ];
参数说明:
ON ( expression [, …] ) 只保留那些在给出的表达式上运算出相同结果的行集合中的第一行。
✨ 7.2 案例示范
在表customer_t中插入两条数据:
test=# INSERT INTO customer_t (customer_sk, customer_id, first_name) VALUES
(6881, 'test', 'Lily'),
(4320, 'tpcds', 'Lily');
test=# select * from customer_t;
customer_sk | customer_id | first_name | last_name
-------------+-------------+------------+-----------
3869 | 5 | Grace | White
3869 | hello | Grace |
3870 | it | Grace |
3871 | jem | Grace |
6985 | maps | Joes |
9976 | world | James |
4421 | Admin | Local |
6881 | test | Lily |
4320 | tpcds | Lily |
在SELECT语句中使用DISTINCT关键字,对first_name字段去重
test=# select distinct first_name from customer_t;
first_name
------------
James
Grace
Local
Joes
Lily
📣 8.GROUP BY子句
GROUP BY语句和SELECT语句一起使用,用来对相同的数据进行分组。您可以对一列或者多列进行分组,但是被分组的列必须存在。
✨ 8.1 语法格式
SELECT
{ * | [column, ...] }
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ ORDER BY {expression [ ASC | DESC ] }];
参数说明:
1)将查询结果按某一列或多列的值分组,值相等的为一组。
2)GROUP BY在一个SELECT语句中,放在WHRER子句的后面,ORDER BY 句的前面。
✨ 8.2 案例示范
1.表customer_t中存在重复的first_name,根据first_name字段分组,并计数。
test=# SELECT first_name, count(*) FROM customer_t GROUP BY first_name;
first_name | count
------------+-------
James | 1
Grace | 4
Local | 1
Joes | 1
Lily | 2
📣 9.HAVING子句
WHERE子句在所选列上设置条件,而HAVING子句则在由GROUP BY子句创建的分组上设置条件。
✨ 9.1 语法格式
SELECT
{ * | [column, …] }
[ FROM from_item [, …] ]
[ WHERE condition ]
[ GROUP BY grouping_element [, …] ]
[ HAVING condition [, …] ]
[ ORDER BY {expression [ ASC | DESC ] }];
参数说明:
HAVING子句将组的一些属性与一个常数值比较,只有满足HAVING子句中的逻辑表达式的组才会被提取出来
✨ 9.2 案例示范
找出根据first_name字段值进行分组,并且first_name字段的计数少于 2 数据
test=# SELECT first_name FROM customer_t GROUP BY first_name HAVING count(first_name) < 2;
first_name
------------
James
Local
Joes
(3 rows)