多线程(C++)
文章目录
- 多线程(C++)
- 前言
- 一、std::thread类
- 1.线程的创建
- 1.1构造函数
- 1.2代码演示
- 2.公共成员函数
- 2.1 get_id()
- 2.2 join()
- 2.3 detach()
- 2.4 joinable()
- 2.5 operator=
- 3.静态函数
- 4.类的成员函数作为子线程的任务函数
- 二、call_once函数
- 1.原理和介绍
- 2.应用-懒汉模式
- 三、线程同步之互斥锁(互斥量)
- 1.std::mutex类
- 1.1 成员函数
- 1.2 线程同步
- 2.std::lock_guard类
- 3.std::recursive_mutex类
- 4.std::timed_mutex类
- 四、线程同步之条件变量
- 1.生产者-消费者模型
- 2.条件变量
- 2.1 成员函数
- 总结
前言
C++11之前,C++语言没有对并发编程提供语言级别的支持,这使得我们在编写可移植的并发程序时,存在诸多的不便。现在C++11中增加了线程以及线程相关的类,很方便地支持了并发编程,使得编写的多线程程序的可移植性得到了很大的提高。
一、std::thread类
1.线程的创建
1.1构造函数
//1. 默认构造函数,构造一个线程对象,在这个线程中不执行任何处理动作
thread() nonexcept;
//2. 移动构造函数,将other的线程所有权转移给新的thread对象,之后的other不再表示执行线程
thread(thread&& other) nonexcept;
//3. 创建线程对象,并在该线程中执行函数f的业务逻辑,args是要传递给函数f的参数(使用最多的,最有用的)
//此处使用右值引用的好处:可以延长临时变量的寿命,等到使用完成后再进行释放
template<class Function,class... Args>
explicit thread(Function&& f,Args&&... args);
/*备注:
任务函数f的类型可以是如下:
1.普通函数、类成员函数、匿名函数、仿函数(这些都是可调用对象类型)
2.可以是可调用对象包装器类型,也可以是使用绑定器绑定之后得到的类型(仿函数)
*/
//4.使用delet显示删除拷贝构造,不允许线程对象之间的拷贝
thread(const thread&)=delete;
1.2代码演示
#include <iostream>
#include <thread>
void func()
{
std::cout << "children worker:" <<"xiaodu ,id:"<< std::this_thread::get_id() << std::endl;
}
void func1(std::string name,int id)
{
std::cout << "children worker:" << name << ",id:" << std::this_thread::get_id() << std::endl;
}
int main()
{
std::cout << "主线程id:" << std::this_thread::get_id() << std::endl;
//1. 创建空的线程对象
std::thread t1;
//2. 创建一个可用的子线程
std::thread t2(func);
std::thread t3(func1, "xiaoliu", 20);
std::thread t4([=](int id)
{
std::cout << "arg id :" << id << ",id:" << std::this_thread::get_id() << std::endl;
}, 18);
std::thread&& t5 = std::move(t4);
return 0;
}

报错原因分析:程序启动之后,执行main()函数,进程里就有一个主线程(父线程),然后接下来打印主线程id,再接下来创建线程t1、t2、t3、t4、t5,但是子线程创建后就会变成就绪态,和主线程一起抢cpu时间片,谁抢到cpu时间片谁就执行对应的任务函数,主线程大概率抢到cpu时间片,主线程执行完就退出了,随之退出的还有虚拟地址空间,因此,子线程就算抢到cpu时间片但是对应的虚拟地址空间已经没了,所以报错。
报错的解决思路:让主线程等待子线程执行完任务函数再退出。
2.公共成员函数
2.1 get_id()
应用程序启动后默认只有一个线程,这个线程一般称为主线程或父线程,通过线程类创建出来的线程一般称为子线程,每个线程创建出来都对应一个线程ID,这个ID是唯一的,可以通过这个ID来区分和识别各个已经存在的线程实例,这个函数就是get_id(),函数原型如下:
// std::thread::id--长整型数
std::thread::id get_id() const noexcept;
示例程序:
#include <iostream>
#include <thread>
void func(int num,std::string str)
{
for (int i = 0; i < 10; i++)
{
std::cout << "子线程:i=" << i << " num : " << num << ",str: " << str << std::endl;
}
}
void func1()
{
for (int i = 0; i < 10; i++)
{
std::cout << "子线程:i=" << i << std::endl;
}
}
int main()
{
// 获得线程ID的两种方法:
// 方法1--在子线程或者主线程函数中调用std::this_thread::get_id()函数,会得到当前线程ID
std::cout << "主线程id:" << std::this_thread::get_id() << std::endl;
std::thread t(func,520,"i love you");
std::thread t1(func1);
// 方法2--调用thread类的成员函数get_id()
std::cout << "线程t的线程ID:" << t.get_id()<<std::endl;
std::cout << "线程t1的线程ID:" << t1.get_id() << std::endl;
return 0;
}
2.2 join()
join()字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。在某个线程A中通过子线程对象B调用join()函数,调用这个函数的线程A被阻塞,但是子线程对象B中的任务函数会继续执行,当任务执行完毕之后join()会清理当前子线程B中的相关资源然后返回,同时,调用该函数的线程A解除阻塞继续向下执行。
// 如果要阻塞主线程的执行,只需要在主线程中通过子线程对象调用这个方法即可,
// 当调用这个方法的子线程对象中的任务函数执行完毕之后,主线程的阻塞也就随之解除了
void std::thread::join();
示例程序1:
#include <iostream>
#include <thread>
void func()
{
std::cout << "children worker:" <<"xiaodu ,id:"<< std::this_thread::get_id() << std::endl;
}
void func1(std::string name,int id)
{
std::cout << "children worker:" << name << ",id:" << std::this_thread::get_id() << std::endl;
}
int main()
{
std::cout << "主线程id:" << std::this_thread::get_id() << std::endl;
//1. 创建空的线程对象
std::thread t1;
//2. 创建一个可用的子线程
std::thread t2(func);
std::thread t3(func1, "xiaoliu", 20);
std::thread t4([=](int id)
{
std::cout << "arg id :" << id << ",id:" << std::this_thread::get_id() << std::endl;
}, 18);
std::thread&& t5 = std::move(t4);
t2.join();
t3.join();
t5.join(); // t4线程的所有权转交给t5,t4对象失效
return 0;
}
当程序运行到thread::join()时存在两种情况:
- 如果任务函数func()还没执行完毕,主线程阻塞,知道任务执行完毕,主线程解除阻塞,继续向下运行
- 如果任务函数func()已经执行完毕,主线程不会阻塞,继续向下执行
上述的bug通过join()函数成功解决。
示例程序2:
需求:程序中一共有三个线程,其中两个子线程负责分段下载同一个文件,下载完毕之后,由主线程对这个文件进行下一步处理
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
void download1()
{
// 模拟下载, 总共耗时500ms,阻塞线程500ms
this_thread::sleep_for(chrono::milliseconds(500));
cout << "子线程1: " << this_thread::get_id() << ", 下载1....完成" << endl;
}
void download2()
{
// 模拟下载, 总共耗时300ms,阻塞线程300ms
this_thread::sleep_for(chrono::milliseconds(300));
cout << "子线程2: " << this_thread::get_id() << ", 下载2....完成" << endl;
}
void doSomething()
{
cout << "完成...." << endl;
}
int main()
{
thread t1(download1);
thread t2(download2);
// 阻塞主线程,等待所有子线程任务执行完毕再继续向下执行
t1.join();
t2.join();
doSomething();
}
最核心的处理是在主线程调用doSomething();之前在第35、36行通过子线程对象调用了join()方法,这样就能够保证两个子线程的任务都执行完毕了,也就是文件内容已经全部下载完成,主线程再对文件进行后续处理,如果子线程的文件没有下载完毕,主线程就去处理文件,很显然从逻辑上讲是有问题的。
2.3 detach()
detach()函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,它可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。(唯一好处)(比如孩子(子线程)翅膀硬了,和家里(父线程)断绝关系(detach),自己外出闯荡(脱离主线程执行任务函数),死了家里也不会给买棺材(执行完毕后,自己释放系统资源),如果家里被诛九族(主线程退出)还是会受到牵连(子线程还是会退出))。
示例程序:
#include <iostream>
#include <thread>
void func()
{
std::cout << "children worker:" << "xiaodu ,id:" << std::this_thread::get_id() << std::endl;
}
void func1(std::string name, int id)
{
std::cout << "children worker:" << name << ",id:" << std::this_thread::get_id() << std::endl;
}
int main()
{
std::cout << "主线程id:" << std::this_thread::get_id() << std::endl;
//1. 创建空的线程对象
std::thread t1;
//2. 创建一个可用的子线程
std::thread t2(func);
std::thread t3(func1, "xiaoliu", 20);
std::thread t4([=](int id)
{
std::cout << "arg id :" << id << ",id:" << std::this_thread::get_id() << std::endl;
}, 18);
std::thread&& t5 = std::move(t4);
t2.join();
t3.join();
// 子线程t5在主线程中调用detach()函数,子线程和主线程分离,
//从此再也不能在主线程中子线程调用成员函数进行任何有效操作,否则会报错
t5.detach();
// 不能得到真正的线程ID
t5.get_id();
// 失效,报错
//t5.join();
return 0;
}
注意事项:线程分离函数detach()不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了,比如:通过join()阻塞主线程等待子线程中的任务执行完毕,或者调用get_id()获取子线程的线程ID。有利就有弊,鱼和熊掌不可兼得,建议使用join(),一般不用detach()。
2.4 joinable()
joinable()函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型:
- 返回值为true:主线程和子线程之间有关联(连接)关系
- 返回值为false:主线程和子线程之间没有关联(连接)关系
bool joinable() const noexcept;
示例程序:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
void foo()
{
std::this_thread::sleep_for(chrono::seconds(1));
}
int main()
{
// 创建一个空的线程对象,如果子线程未关联任务函数,则二者也是未关联
thread t;
cout << "before starting,joinable:" << t.joinable() << endl; //false
// 匿名对象作为临时变量,使用右值引用拷贝构造函数
t = thread(foo);
cout << "after starting,joinable:" << t.joinable() << endl; //true
// 线程t调用jion函数,阻塞主线程,执行任务函数完成后,退出子线程
t.join();
cout << "after starting,joinable:" << t.joinable() << endl; //false
// 创建线程t1
thread t1(foo);
cout << "after starting,joinable:" << t1.joinable() << endl; //true
// 线程分离
t1.detach();
cout << "after starting,joinable:" << t1.joinable() << endl; //false
return 0;
}
2.5 operator=
线程中的资源是不能被复制的,因此通过=操作符进行赋值操作最终并不会得到两个完全的对象。
// move(1)
thread& operator=(thread&& other) noexcept;
// copy[deleted](2)
thread& operator=(thread& other) noexcept;
通过以上=操作符的重载声明可以得知:
- 如果other是一个右值,会将资源所有权进行转移
- 如果other不是一个右值,禁止拷贝,该函数显示被删除(delete),不可用
3.静态函数
thread线程类还提供了一个静态方法,用于获取当前计算机的CPU核心数,根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的(并行)。
static unsigned hardware_concurrency() noexcept;
示例代码:
#include <iostream>
#include <thread>
using namespace std;
int main()
{
unsigned int num = thread::hardware_concurrency();
cout << "hardware_concurrency = " << num << endl;
return 0;
}
4.类的成员函数作为子线程的任务函数
待学TODO
二、call_once函数
1.原理和介绍
在某些特定情况下,某些函数只能在多线程环境下调用一次,比如:要初始化某个对象,而这个对象只能被初始化一次,就可以使用std::call_once()来保证函数在多线程环境下只能被调用一次。使用call_once()的时候,需要一个once_flag作为call_once()的传入参数,该函数的原型如下:
// 定义位于<mutex>
#include <mutex>
void call_once(std::once_flag& flag,Callable&& f,Args&&... args)
- flag:once_flag类型的对象,要保证这个对象能够被多个线程同时访问到
- f:回调函数,可以传递一个有名函数地址,也可以指定一个匿名函数
- args:作为实参传递给回调函数
多线程操作过程中,std::call_once()内部的回调函数只会被执行一次,示例代码如下:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 全局变量
once_flag flag;
void do_once()
{
cout << "do once function" << endl;
}
void do_something()
{
static int num = 1;
// call_once注意事项:flag要能被多个线程同时访问;传入实参参数的形式类似thread函数;无返回值,void
// 使用场景:在多线程中,只需要初始化一次对象(new 一个对象)
call_once(flag, do_once);
cout << "do something function: " << num++ << endl;
}
int main()
{
thread t1(do_something);
thread t2(do_something);
thread t3(do_something);
t1.join();
t2.join();
t3.join();
return 0;
}

2.应用-懒汉模式
单例模式分类:
- 懒汉式
系统运行中,实例并不存在,只有当需要使用该实例时,才会去创建并使用实例。这种方式要考虑线程安全。 - 饿汉式
系统一运行,就初始化创建实例,当需要时,直接调用即可。这种方式本身就线程安全,没有多线程的线程安全问题。
编写一个单例模式(分为懒汉式和饿汉式)的类–懒汉模式。
示例程序:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 单例模式--懒汉模式
// 全局变量,保证被多个线程访问
once_flag g_flag;
// 单例类
class Base
{
public:
// 实现单例模式首先将拷贝构造和赋值操作显示删除
Base(const Base& obj) = delete;
Base& operator=(const Base& obj) = delete;
// 静态成员函数
static Base* getInstance()
{
// 调用call_once函数保证多个线程访问时只有一个对象创建
call_once(g_flag, [&]() {
ptr = new Base;
cout << "单例创建" << endl;
});
return ptr;
}
void release()
{
delete ptr;
ptr = nullptr;
}
string getName()
{
return name;
}
void setName(string Name)
{
this->name = Name;
}
private:
// 构造函数设为private,不能被外界直接访问
Base() { }
~Base() { }
static Base* ptr;
string name;
};
// 懒汉模式是运行时才会创建对象,所以ptr先设置为nullptr
Base* Base::ptr = nullptr;
void func(string name)
{
Base::getInstance()->setName(name);
std::cout<<"name:"<< Base::getInstance()->getName()<<endl;
}
int main()
{
thread t1(func,"路飞");
thread t2(func,"埃斯");
thread t3(func,"萨博");
t1.join();
t2.join();
t3.join();
Base::getInstance()->release();
return 0;
}

此处,很大概率会出现打印信息不对,因为三个线程同时对一块内存进行了读写操作,所以为了让多线程线性访问,需要加锁。
加锁后的代码程序:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 单例模式--懒汉模式
// 全局变量,保证被多个线程访问
once_flag g_flag;
// 单例类
class Base
{
public:
// 实现单例模式首先将拷贝构造和赋值操作显示删除
Base(const Base& obj) = delete;
Base& operator=(const Base& obj) = delete;
// 静态成员函数
static Base* getInstance()
{
// 调用call_once函数保证多个线程访问时只有一个对象创建
call_once(g_flag, [&]() {
ptr = new Base;
cout << "单例创建" << endl;
});
return ptr;
}
void release()
{
delete ptr;
ptr = nullptr;
}
string getName()
{
return name;
}
void setName(string Name)
{
this->name = Name;
}
private:
// 构造函数设为private,不能被外界直接访问
Base() { }
~Base() { }
static Base* ptr;
string name;
};
// 懒汉模式是运行时才会创建对象,所以ptr先设置为nullptr
Base* Base::ptr = nullptr;
mutex mx;
void func(string name)
{
// 多个线程的共享资源是Base::getInstance()
mx.lock();
Base::getInstance()->setName(name);
std::cout<<"name:"<< Base::getInstance()->getName()<<endl;
mx.unlock();
}
int main()
{
thread t1(func,"路飞");
thread t2(func,"埃斯");
thread t3(func,"萨博");
t1.join();
t2.join();
t3.join();
Base::getInstance()->release();
return 0;
}
三、线程同步之互斥锁(互斥量)
进行多线程编程,如果多个线程需要对同一块内存进行操作,比如:同时读、同时写、同时读写对于后两种情况来说,如果不做任何的人为干涉就会出现各种各样的错误数据。这是因为线程在运行的时候需要先得到CPU时间片,时间片用完之后需要放弃已获得的CPU资源,就这样线程频繁地在就绪态和运行态之间切换,更复杂一点还可以在就绪态、运行态、挂起态之间切换,这样就会导致线程的执行顺序并不是有序的,而是随机的混乱的。

注意概念:线程同步是指让多线程进行线性有序的进行,而不是同时对一块内存操作。
解决多线程数据混乱的方案就是进行线程同步,最常用的就是互斥锁,在C++11中一共提供了四种互斥锁:
- std::mutex:独占的互斥锁,不能递归使用 (最常用)
- std::timed_mutex:带超时的独占互斥锁,不能递归使用
- std::recursive_mutex:递归互斥锁,不带超时功能
- std::recursive_timed_mutex:带超时的递归互斥锁
注意事项: - 内存可能涉及到多个线程的同时访问(写、读写),此时需要通过互斥锁对内存进行保护
- 使用互斥锁锁住的是和共享数据相关的一个代码块(临界区)
- 在程序中一个共享数据对应多个代码块,在锁住这些代码块的时候要用同一把锁,并且程序运行期间不能销毁这把互斥锁
1.std::mutex类
1.1 成员函数
lock()函数用于给临界区加锁,并且只能有一个线程获得锁的所有权,它有阻塞其他线程的作用,函数原型如下:
//
void lock();
独占互斥锁对象有两种状态:锁定和未锁定。如果互斥锁是打开的,调用lock()函数的线程会得到互斥锁的所有权,并将其上锁,其它线程再调用该函数的时候由于得不到互斥锁的所有权,就会被lock()函数阻塞。当拥有互斥锁所有权的线程将互斥锁解锁,此时被lock()阻塞的线程解除阻塞,抢到互斥锁所有权的线程加锁并继续运行,没抢到互斥锁所有权的线程继续阻塞。
除了使用lock()还可以使用try_lock()获取互斥锁的所有权并对互斥锁加锁,函数原型如下:
bool try_lock();
二者的区别在于try_lock()不会阻塞线程,lock()会阻塞线程:
- 如果互斥锁是未锁定状态,得到了互斥锁所有权并加锁成功,函数返回true
- 如果互斥锁是锁定状态,无法得到互斥锁所有权加锁失败,函数返回false
**当互斥锁被锁定之后可以通过unlock()进行解锁,但是需要注意的是只有拥有互斥锁所有权的线程也就是对互斥锁上锁的线程才能将其解锁,其它线程是没有权限做这件事情的。**该函数的函数原型如下:
void unlock();
通过介绍以上三个函数,使用互斥锁进行线程同步的大致思路差不多就能搞清楚了,主要分为以下几步:
- 找到多个线程操作的共享资源(全局变量、堆内存、类成员变量等),也可以称之为临界资源
- 找到和共享资源有关的上下文代码,也就是临界区(下图中的黄色代码部分)
- 在临界区的上边调用互斥锁类的lock()方法
- 在临界区的下边调用互斥锁的unlock()方法

线程同步的目的是让多线程按照顺序依次执行临界区代码,这样做线程对共享资源的访问就从并行访问变为了线性访问,访问效率降低了,但是保证了数据的正确性。
注意:
当线程对互斥锁对象加锁,并且执行完临界区代码之后,一定要使用这个线程对互斥锁解锁,否则最终会造成线程的死锁。死锁之后当前应用程序中的所有线程都会被阻塞,并且阻塞无法解除,应用程序也无法继续运行。
1.2 线程同步
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 互斥锁
class Base
{
public:
// count表示打印的个数
void increment(int count)
{
for (int i = 0; i < count; i++)
{
mx.lock();
++num;
cout << "++current number: " << num << endl;
mx.unlock();
this_thread::sleep_for(chrono::milliseconds(100));
}
}
// count表示打印的个数
void decrement(int count)
{
for (int i = 0; i < count; i++)
{
mx.lock();
--num;
cout << "--current number: " << num << endl;
mx.unlock();
this_thread::yield();
}
}
private:
// 此处为共享资源
int num=999;
mutex mx;
};
int main()
{
Base b;
thread t1(&Base::increment,&b,10);
thread t2(&Base::decrement, &b, 10);
t1.join();
t2.join();
return 0;
}

2.std::lock_guard类
lock_guard是C++11新增的一个模板类,使用这个类,可以简化互斥锁lock()和unlock()的写法,同时也更安全。这个模板类的定义和常用的构造函数原型如下:
// 类的定义,定义于头文件 <mutex>
template< class Mutex >
class lock_guard;
// 常用构造函数
explicit lock_guard( mutex_type& m );
lock_guard在使用上面提供的这个构造函数构造对象时,会自动锁定互斥量,而在退出作用域后进行析构时就会自动解锁,从而保证了互斥量的正确操作,避免忘记unlock()操作而导致线程死锁。lock_guard使用了RAII技术,就是在类构造函数中分配资源,在析构函数中释放资源,保证资源出了作用域就释放。
使用lock_guard对上面的例子进行修改,代码如下:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 互斥锁
class Base
{
public:
// count表示打印的个数
void increment(int count)
{
for (int i = 0; i < count; i++)
{
{
lock_guard<mutex> lock(mx);
++num;
cout << "++current number: " << num << endl;
}
this_thread::sleep_for(chrono::milliseconds(100));
}
}
// count表示打印的个数
void decrement(int count)
{
for (int i = 0; i < count; i++)
{
{
lock_guard<mutex> lock(mx);
--num;
cout << "--current number: " << num << endl;
}
this_thread::yield();
}
}
private:
// 此处为共享资源
int num=999;
mutex mx;
};
int main()
{
Base b;
thread t1(&Base::increment,&b,10);
thread t2(&Base::decrement, &b, 10);
t1.join();
t2.join();
return 0;
}
 通过修改发现代码被精简了,而且不用担心因为忘记解锁而造成程序的死锁,需要根据实际情况选择最优的解决方案。
通过修改发现代码被精简了,而且不用担心因为忘记解锁而造成程序的死锁,需要根据实际情况选择最优的解决方案。
3.std::recursive_mutex类
递归互斥锁std::recursive_mutex允许同一线程多次获得互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题,在下面的例子中使用独占非递归互斥量会发生死锁:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 互斥锁
class Base
{
public:
// count表示打印的个数
void increment(int count)
{
for (int i = 0; i < count; i++)
{
mx.lock();
++num;
cout << "++current number: " << num << endl;
mx.unlock();
this_thread::sleep_for(chrono::milliseconds(100));
}
}
// count表示打印的个数
void decrement(int count)
{
for (int i = 0; i < count; i++)
{
{
lock_guard<mutex> lock(mx);
// 发生死锁
increment(2);
--num;
cout << "--current number: " << num << endl;
}
this_thread::yield();
}
}
private:
// 此处为共享资源
int num = 999;
mutex mx; //递归互斥锁
};
int main()
{
Base b;
thread t1(&Base::increment, &b, 10);
thread t2(&Base::decrement, &b, 10);
t1.join();
t2.join();
return 0;
}

上面的程序中执行了decrement( )中对incremen( )调用之后,程序就会发生死锁,在decrement( )中已经对互斥锁加锁了,继续调用incremen( )函数,已经得到互斥锁所有权的线程再次获取这个互斥锁的所有权就会造成死锁(在C++中程序会异常退出,使用C库函数会导致这个互斥锁永远无法被解锁,最终阻塞所有的线程)。要解决这个死锁的问题,一个简单的办法就是使用递归互斥锁std::recursive_mutex,它允许一个线程多次获得互斥锁的所有权。修改之后的代码如下:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 互斥锁
class Base
{
public:
// count表示打印的个数
void increment(int count)
{
for (int i = 0; i < count; i++)
{
mx.lock();
++num;
cout << "++current number: " << num << endl;
mx.unlock();
this_thread::sleep_for(chrono::milliseconds(100));
}
}
// count表示打印的个数
void decrement(int count)
{
for (int i = 0; i < count; i++)
{
{
lock_guard<recursive_mutex> lock(mx);
increment(2);
--num;
cout << "--current number: " << num << endl;
}
this_thread::yield();
}
}
private:
// 此处为共享资源
int num = 999;
recursive_mutex mx; //递归互斥锁
};
int main()
{
Base b;
thread t1(&Base::increment, &b, 10);
thread t2(&Base::decrement, &b, 10);
t1.join();
t2.join();
return 0;
}

虽然递归互斥锁可以解决同一个互斥锁频繁获取互斥锁资源的问题,但是还是建议少用,主要原因如下:
- 使用递归互斥锁的场景往往都是可以简化的,使用递归互斥锁很容易放纵复杂逻辑的产生,从而导致bug的产生
- 递归互斥锁比非递归互斥锁效率要低一些。
- 递归互斥锁虽然允许同一个线程多次获得同一个互斥锁的所有权,但最大次数并未具体说明,一旦超过一定的次数,就会抛出std::system错误。
4.std::timed_mutex类
std::timed_mutex是超时独占互斥锁,主要是在获取互斥锁资源时增加了超时等待功能,因为不知道获取锁资源需要等待多长时间,为了保证不一直等待下去,设置了一个超时时长,超时后线程就可以解除阻塞去做其他事情了。
std::timed_mutex比std::_mutex多了两个成员函数:try_lock_for()和try_lock_until():
void lock();
bool try_lock();
void unlock();
// std::timed_mutex比std::_mutex多出的两个成员函数
template <class Rep, class Period>
bool try_lock_for (const chrono::duration<Rep,Period>& rel_time);
template <class Clock, class Duration>
bool try_lock_until (const chrono::time_point<Clock,Duration>& abs_time);
- try_lock_for函数是当线程获取不到互斥锁资源的时候,让线程阻塞一定的时间长度
- try_lock_until函数是当线程获取不到互斥锁资源的时候,让线程阻塞到某一个指定的时间点
- 关于两个函数的返回值:当得到互斥锁的所有权之后,函数会马上解除阻塞,返回true,如果阻塞的时长用完或者到达指定的时间点之后,函数也会解除阻塞,返回false
下面的示例程序中为大家演示了std::timed_mutex的使用:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
// 互斥锁
class Base
{
public:
void work()
{
while (true) {
// 锁未锁定--返回值为true
if (mx.try_lock_for(chrono::milliseconds(100)))
{
cout << "count"<<++count<<" ok 线程ID=" << this_thread::get_id() << endl;
// 模拟任务使用的时长
this_thread::sleep_for(chrono::milliseconds(500));
cout << "count" << count << " ok 线程ID=" << this_thread::get_id()<<endl;
// 互斥锁解锁
mx.unlock();
break;
}
else // 阻塞时间超时--返回false
{
// 模拟任务使用的时长
this_thread::sleep_for(chrono::milliseconds(50));
cout << "not ok 线程ID=" << this_thread::get_id()<<endl;
}
}
}
private:
int count = 0; // 共享资源
timed_mutex mx; // 超时独占互斥锁
};
int main()
{
Base b;
thread t1(&Base::work, &b);
thread t2(&Base::work, &b);
t1.join();
t2.join();
return 0;
}
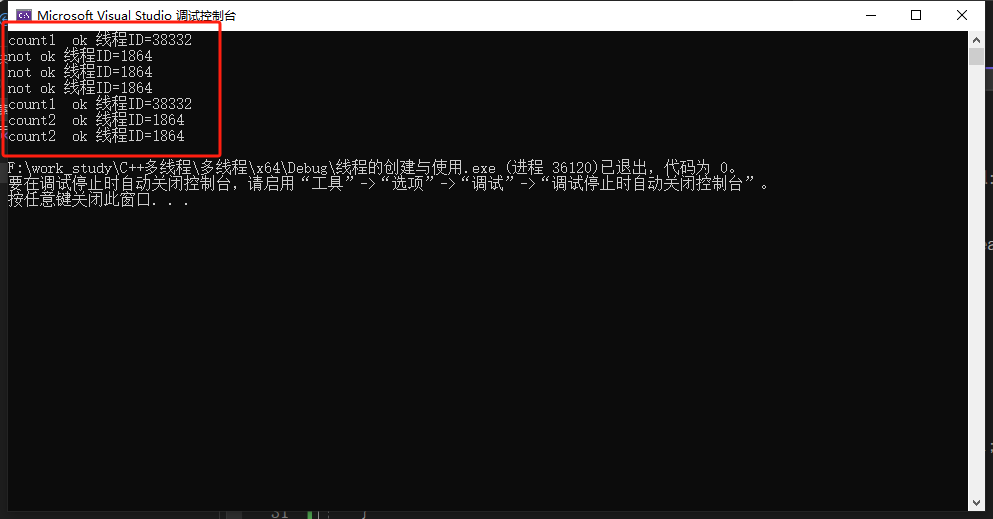
**注意:解除阻塞和解锁是两个不同的概念。**从上述的结果,我们可以看出线程38332获得互斥锁的所有权,try_lock_for函数超过阻塞时长,返回false,阻塞的另一个线程1864执行else中的任务,由于这个是while(true)该线程1864重新被阻塞,超过阻塞时长,又重新执行else,直到线程38332解除互斥锁的所有权,线程1864获得互斥锁的所有权,执行接下来的过程。
四、线程同步之条件变量
1.生产者-消费者模型
条件变量通常用于生产者和消费者模型。生产者和消费者模型主要应用的场景是生产者和消费者的速度不匹配。 条件变量能够帮助我们解决某一类线程(生产者或者消费者),互斥锁能够帮助我们解决某一类线程因为多个线程访问共享资源导致的数据混乱问题。
生产者和消费者模型的组成:
- 生产者线程->若干个
生产商品或者任务放入到任务队列中;
任务队列满了生产者线程就阻塞,不满就工作;
通过一个生产者的条件变量控制生产者线程阻塞和非阻塞。 - 消费者线程->若干个
读任务队列,将任务或者数据取出;
任务队列中有数据就有消费者,没有数据就阻塞;
通过一个消费者的条件变量控制消费者线程阻塞和非阻塞。 - 任务队列->存储数据或者任务,对应一块内存,为了读写访问可以通过一个数据结构维护这块内存
数据结构的类型可以分为数组、链表,也可以是STL容器(queue\stack\list\vector)
注意:推荐使用STL中的容器,方便增加删除以及动态扩展等。

生产者消费者模型任务队列类的代码演示:
#include <queue>
#include <iostream>
#include <thread>
using namespace std;
class WorkQueue
{
public:
// 添加数据
void put(const int& task)
{
workQueue.push(task); // 尾部添加数据
cout << "添加任务:" << task << ",线程ID:" << this_thread::get_id() << endl;
}
// 删除数据
void take()
{
int node = workQueue.front(); // 取出头部数据
workQueue.pop();
cout << "删除任务:" << node << ",线程ID:" << this_thread::get_id() << endl;
}
// 判断任务队列是否满
bool isFull()
{
return workQueue.size() == maxSize;
}
// 判断任务队列是否空
bool isEmpty()
{
return workQueue.size() == 0;
}
// 当前任务队列的尺寸
int workSize()
{
return workQueue.size();
}
private:
int maxSize; //任务队列的容量
std::queue<int> workQueue; // 任务队列的数据结构
};
优点:线程阻塞相比较线程空循环或者线程的重新创建来说效率更高,资源消耗更少。
2.条件变量
condition_variable:需要配合std::unique_lockstd::mutex进行wait操作,也就是阻塞线程的操作。
condition_variable_any:可以和任意带有lock()、unlock()语义的mutex搭配使用,也就是说有四种:
- std::mutex:独占的非递归互斥锁
- std::timed_mutex:带超时的独占非递归互斥锁
- std::recursive_mutex:不带超时功能的递归互斥锁
- std::recursive_timed_mutex:带超时的递归互斥锁
条件变量通常用于生产者和消费者模型,大致使用过程如下:
- 拥有条件变量的线程获取互斥量
- 循环检查某个条件,如果条件不满足阻塞当前线程,否则线程继续向下执行
产品的数量达到上限,生产者阻塞,否则生产者一直生产。。。
产品的数量为零,消费者阻塞,否则消费者一直消费。。。 - 条件满足之后,可以调用notify_one()或者notify_all()唤醒一个或者所有被阻塞的线程
由消费者唤醒被阻塞的生产者,生产者解除阻塞继续生产。。。
由生产者唤醒被阻塞的消费者,消费者解除阻塞继续消费。。。
2.1 成员函数
condition_variable的成员函数主要分为两部分:线程等待(阻塞)函数 和线程通知(唤醒)函数,这些函数被定义于头文件 <condition_variable>
- 等待函数
调用wait()函数的线程会被阻塞
// ① 调用该函数的线程直接被阻塞
void wait (unique_lock<mutex>& lck);
// ② 该函数的第二个参数是一个判断条件,是一个返回值为布尔类型的函数
// 该参数可以传递一个有名函数的地址,也可以直接指定一个匿名函数
// 表达式返回false当前线程被阻塞,表达式返回true当前线程不会被阻塞,继续向下执行
template <class Predicate>
void wait (unique_lock<mutex>& lck, Predicate pred);
独占的互斥锁对象不能直接传递给wait()函数,需要通过模板类unique_lock进行二次处理,通过得到的对象仍然可以对独占的互斥锁对象做(lock、try_lock、try_lock_for、try_lock_until、unlock)操作,使用起来更灵活。
如果线程被该函数阻塞,这个线程会释放占有的互斥锁的所有权,当阻塞解除之后这个线程会重新得到互斥锁的所有权,继续向下执行。(wait函数内部实现,其目的是为了避免线程的死锁)
wait_for()函数和wait()的功能是一样的,只不过多了一个阻塞时长,假设阻塞的线程没有被其他线程唤醒,当阻塞时长用完之后,线程就会自动解除阻塞,继续向下执行。
template <class Rep, class Period>
cv_status wait_for (unique_lock<mutex>& lck,
const chrono::duration<Rep,Period>& rel_time);
template <class Rep, class Period, class Predicate>
bool wait_for(unique_lock<mutex>& lck,
const chrono::duration<Rep,Period>& rel_time, Predicate pred);
wait_until()函数和wait_for()的功能是一样的,它是指定让线程阻塞到某一个时间点,假设阻塞的线程没有被其他线程唤醒,当到达指定的时间点之后,线程就会自动解除阻塞,继续向下执行。
template <class Clock, class Duration>
cv_status wait_until (unique_lock<mutex>& lck,
const chrono::time_point<Clock,Duration>& abs_time);
template <class Clock, class Duration, class Predicate>
bool wait_until (unique_lock<mutex>& lck,
const chrono::time_point<Clock,Duration>& abs_time, Predicate pred);
- 通知函数
void notify_one() noexcept;
void notify_all() noexcept;
notify_one():唤醒一个被当前条件变量阻塞的线程
notify_all():唤醒全部被当前条件变量阻塞的线程
生产者线程:当任务队列满的时候,阻塞生产者线程;消费者线程:当任务队列空的时候,阻塞消费者线程。因此,需要两个条件变量控制生产者线程和消费者线程阻塞。
#include <queue>
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
using namespace std;
class WorkQueue
{
public:
// 添加数据
void put(const int& task)
{
unique_lock<mutex> locker(mx);
// 如果任务队列满了,就需要阻塞生产者线程
while(workQueue.size()==maxSize)
{
// unique_lock对象类似lock_guard,管理mutex的加锁和解锁,当线程访问到这个对象时,未加锁则加锁,反之阻塞
// 如果locker析构了,自动对mx管理的线程所有权进行解锁
// 假设现在有线程A,B,C,线程A获得了互斥锁资源,则线程B,C进行阻塞
notFull.wait(locker); // 线程A在运行到wait的位置会先释放拥有的互斥锁资源(解锁),此时,线程B,C从阻塞态变成就绪态,线程A再阻塞,所以不会出现死锁
// 等到线程A从wait位置解除阻塞,会跟其他线程再去抢互斥锁资源
}
workQueue.push(task); // 尾部添加数据
cout << "添加任务:" << task << ",线程ID:" << this_thread::get_id() << endl;
// 唤醒消费者
notEmpty.notify_one();
}
// 删除数据
void take()
{
unique_lock<mutex> locker(mx);
// 如果任务队列空了,就需要阻塞消费者线程
while(workQueue.size()==0)
{
notEmpty.wait(locker);
}
int node = workQueue.front(); // 取出头部数据
workQueue.pop();
cout << "删除任务:" << node << ",线程ID:" << this_thread::get_id() << endl;
// 唤醒生产者
notFull.notify_one();
}
// 判断任务队列是否满
bool isFull()
{
// 任务队列的访问所以加锁
std::lock_guard<std::mutex> locker(mx);
return workQueue.size() == maxSize;
}
// 判断任务队列是否空
bool isEmpty()
{
std::lock_guard<std::mutex> locker(mx);
return workQueue.size() == 0;
}
// 当前任务队列的尺寸
int workSize()
{
std::lock_guard<std::mutex> locker(mx);
return workQueue.size();
}
private:
int maxSize=100; //任务队列的容量
std::queue<int> workQueue; // 任务队列的数据结构
mutex mx; // 独占的互斥锁
condition_variable notFull; // 控制生产者线程
condition_variable notEmpty; // 控制消费者线程
};
int main()
{
thread t1[5];
thread t2[5];
WorkQueue workQ;
for (int i = 0; i < 5; i++)
{
t1[i] = thread(&WorkQueue::put, &workQ, 100 + i);
t2[i] = thread(&WorkQueue::take, &workQ);
}
for (int i = 0; i < 5; i++)
{
t1[i].join();
t2[i].join();
}
return 0;
}

条件变量condition_variable类的wait()还有一个重载的方法,可以接受一个条件,这个条件也可以是一个返回值为布尔类型的函数,条件变量会先检查判断这个条件是否满足,如果满足条件(布尔值为true),则当前线程重新获得互斥锁的所有权,结束阻塞,继续向下执行;如果不满足条件(布尔值为false),当前线程会释放互斥锁(解锁)同时被阻塞,等待被唤醒。
优化后的代码:
#include <queue>
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
using namespace std;
class WorkQueue
{
public:
// 添加数据
void put(const int& task)
{
unique_lock<mutex> locker(mx);
notFull.wait(locker, [&]() {
return !(workQueue.size() == maxSize);
});
workQueue.push(task); // 尾部添加数据
cout << "添加任务:" << task << ",线程ID:" << this_thread::get_id() << endl;
// 唤醒消费者
notEmpty.notify_one();
}
// 删除数据
void take()
{
unique_lock<mutex> locker(mx);
notEmpty.wait(locker, [&]() {
return !workQueue.size() == 0;
});
int node = workQueue.front(); // 取出头部数据
workQueue.pop();
cout << "删除任务:" << node << ",线程ID:" << this_thread::get_id() << endl;
// 唤醒生产者
notFull.notify_one();
}
// 判断任务队列是否满
bool isFull()
{
// 任务队列的访问所以加锁
std::lock_guard<std::mutex> locker(mx);
return workQueue.size() == maxSize;
}
// 判断任务队列是否空
bool isEmpty()
{
std::lock_guard<std::mutex> locker(mx);
return workQueue.size() == 0;
}
// 当前任务队列的尺寸
int workSize()
{
std::lock_guard<std::mutex> locker(mx);
return workQueue.size();
}
private:
int maxSize=100; //任务队列的容量
std::queue<int> workQueue; // 任务队列的数据结构
mutex mx; // 独占的互斥锁
condition_variable notFull; // 控制生产者线程
condition_variable notEmpty; // 控制消费者线程
};
int main()
{
thread t1[50];
thread t2[50];
WorkQueue workQ;
for (int i = 0; i < 50; i++)
{
t2[i] = thread(&WorkQueue::take, &workQ);
t1[i] = thread(&WorkQueue::put, &workQ, 100 + i);
}
for (int i = 0; i < 50; i++)
{
t1[i].join();
t2[i].join();
}
return 0;
}
总结
本文详细介绍了C++11多线程中thread线程类、mutex等互斥锁、以及线程同步和生产者消费者模型,并提供了对应的示例,本文主要是参考爱编程的大丙,欢迎大家阅读大丙老师的文章,本文作个人学习之用。