目录
一、物理存储结构
二、表空间
1.数据表空间介绍
2.数据表空间迁移
3.共享表空间
4.临时表空间
5.undo表空间
三、InnoDB内存结构
1.innodb_buffer_pool
2.innodb_log_buffer
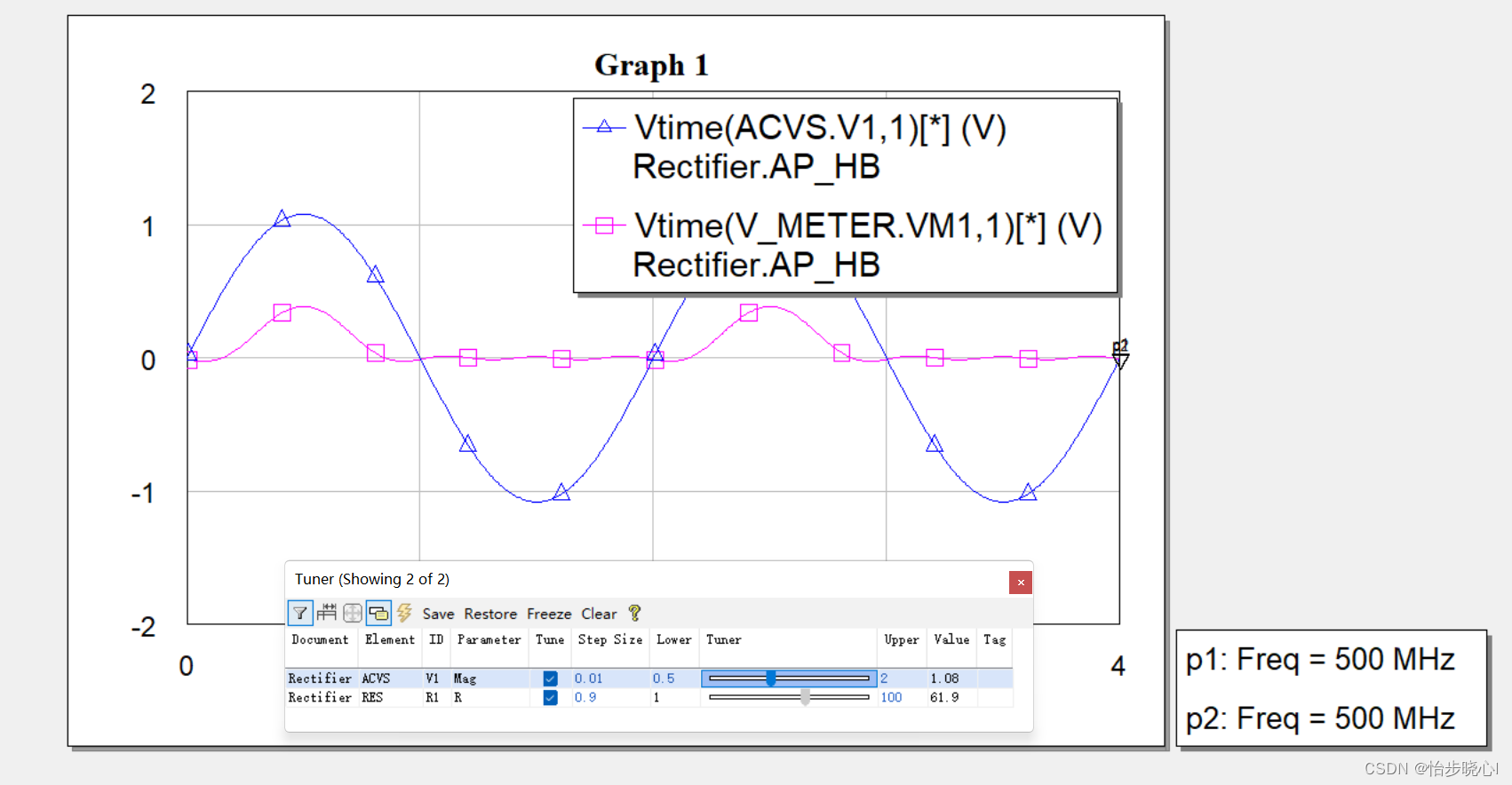
四、InnoDB 8.0结构图例
五、InnoDB重要参数
1.redo log刷新磁盘策略
2.刷盘方式,控制buffer pool和redo buffer数据和日志刷写到磁盘的方式
一、物理存储结构

| table.frm | 存储数据字典信息(列定义) |
| table.ibd | 表空间数据文件,存数据行和索引,有段-区-页的概念 |
| ibdata1 | 5.7版本-->系统表空间文件,存储 data dictionary:存所有表的数据字典,结构,属性,状态,参数... double write:自动故障恢复应用到的数据 change buffer:存储辅助索引的变更 undo:存储日志的回滚信息日志 ibtmp:临时表,存储SQL存储过程中的中间数据(groupby、having、join、union) 用户数据 5.6版本-->除了以上内容,还会放临时表 8.0版本-->ibdata中只放change buffer,其他的都被拆解成其他文件了 |
| ib_logfileN | redo log 用于重做日志,存储事务的前滚日志、内存数据页的变化 |
| ibtmp1 | 临时表,存储SQL存储过程中的中间数据(groupby、having、join、union) |
| ib_buffer_pool | 内存预热文件,用于在内存中存放热数据 |
二、表空间
1.数据表空间介绍
在数据库引擎层,加入的逻辑存储结构,来实现灵活的存储空间扩容
在5.6版本后默认采取独立表空间的模式,每张表都是独立的表空间t1.ibd
共享表空间ibdata1保留下来,只保存系统相关的数据
查询当前表空间:select @@innodb_file_per_table;

2.数据表空间迁移
1)停止相关业务 lock tables city read;
2)在目标库创建同样的表
3)将目标库新表的ibd删除 alter table city discard tablespace;
4)迁移ibd至目标库新表 cp /data/3306/data/world/city.ibd /data/3357/data/world
5)修改权限 chown -R mysql.mysql city.ibd
6)导入表空间 alter table city import tablespace;

7)解锁业务 unlock tables;
3.共享表空间
1)查询参数:select@@innodb_data_file_path
2)设置共享表空间:
第一步:修改配置文件vim /etc/my.cnf
初始化之前设置: innodb_data_file_path=ibdata1:1024M;ibdata2:1024M;ibdata3:1024M:autoextend;
初始化之后设置:
innodb_data_file_path=ibdata1:(当前文件)M;ibdata2:1024M;ibdata3:1024M:autoextend;
第二步:重启数据库
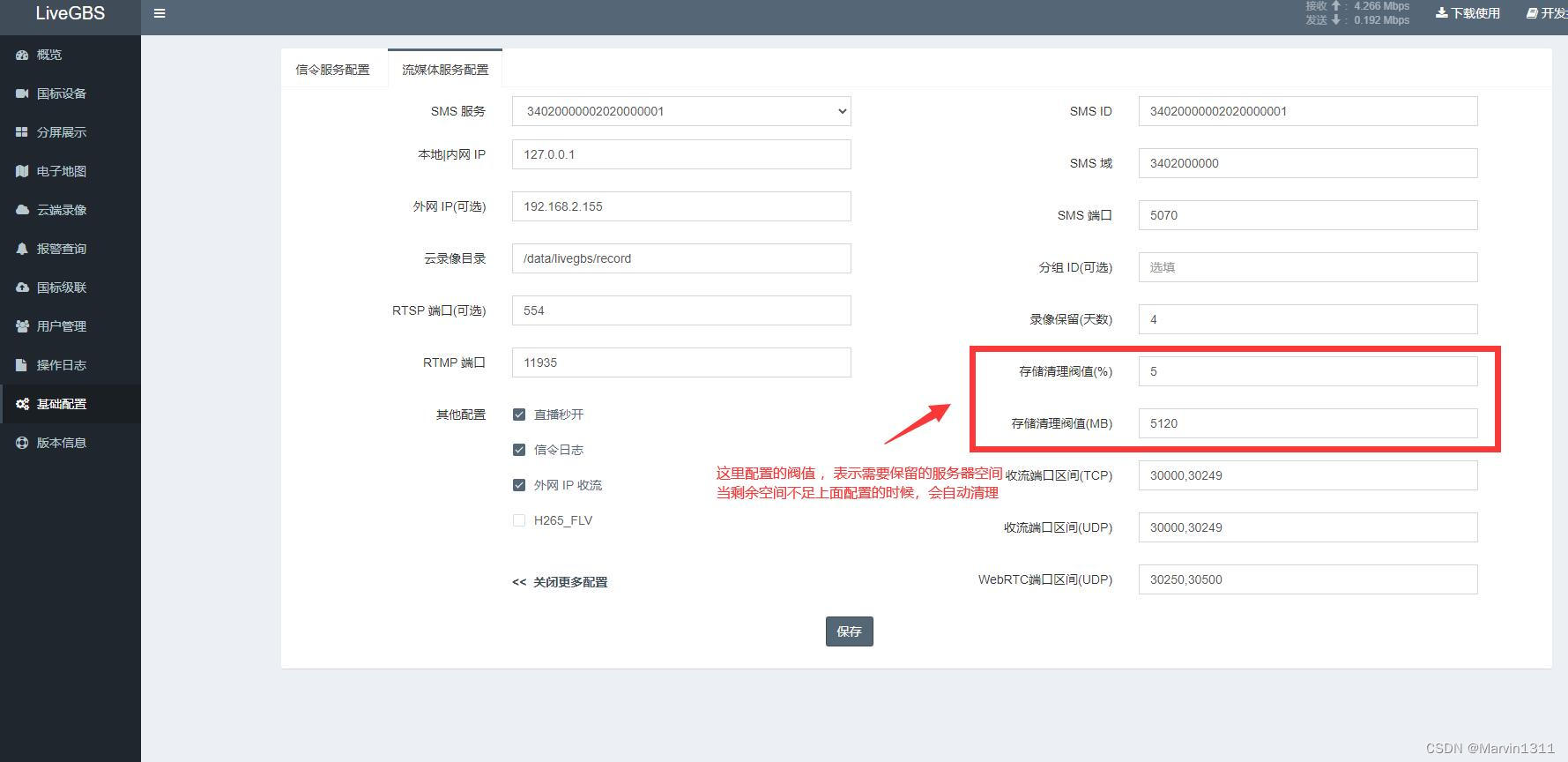
4.临时表空间
设置: innodb_temp_data_file_path=ibtmp1:12M;ibtmp2:120M:autoextend:max:500M
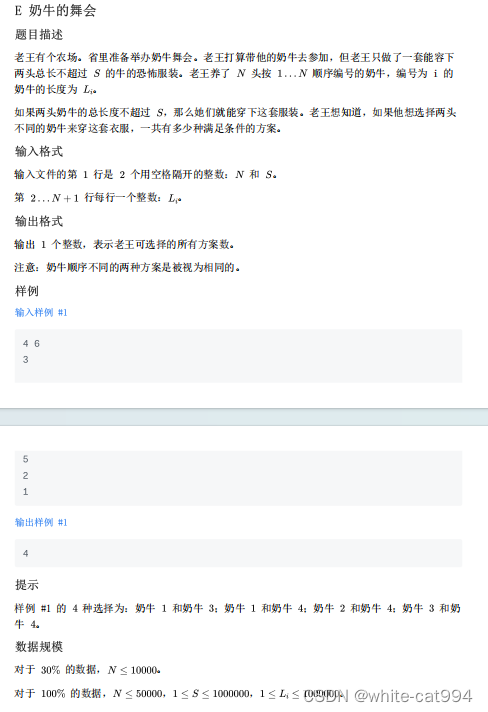
5.undo表空间
如何查看:
select @@innodb_undo_tablespaces; 一般在初始化的时候设置为3-5个
select @@innodb_max_undo_log_size; undo日志的大小,默认1G, 重启后可设置
select @@innodb_undo_log_truncate=on 开启undo自动回收的机制
select @@innodb_purge_rseg_truncate_frequency 触发自动回收的条件,单位是检测次数
如何设置:
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=on
innodb_purge_rseg_truncate_frequency = 32(次)
三、InnoDB内存结构
1.innodb_buffer_pool
select @@innodb_buffer_pool_size
innodb最大的内存区域,建议设置在物理内存的70%以下
作用:缓冲数据页,索引页,数据字典,AHI自适应hash索引,change buffer,DW
2.innodb_log_buffer
select @@innodb_log_buffer_size
用来存储内存数据页的变化,数据修改完成之后,会将日志写入到磁盘日志文件中(ib_logfileN)
四、InnoDB 8.0结构图例

五、InnoDB重要参数
1.redo log刷新磁盘策略
innodb_flush_log_at_trx_commit=0/1/2
| 0 | 每秒刷新redo buffer到os cache,然后fsync到磁盘, 资源消耗大 |
| 1 | 每次commit时刷新redo buffer到os cache,立即fsync到磁盘 默认值,在事务提交时立即刷新redo buffer到日志文件中,能够真正保证持久性 |
| 2 | 每次commit时刷新redo buffer到os cache,每秒钟fsync到磁盘 如果是边缘业务或者离线业务可以使用,有一定风险 |
2.刷盘方式,控制buffer pool和redo buffer数据和日志刷写到磁盘的方式
innodb_flush_method
| fsync | 默认值,刷新数据页和redo buffer到磁盘,都是先刷到os cache,然后再fsync到磁盘 |
| O_DIRECT | 刷写数据页时,跳过os cache,直接刷写到磁盘 刷写日志时,先刷到os cache,然后再fsync到磁盘 建议使用高IO能力的存储配合O_DIRECT,因为会对性能有影响 |




![[JAVASE] 类和对象(六) -- 接口(续篇)](https://img-blog.csdnimg.cn/direct/fb3b449d4c2447529c8093d89046c781.png)