#include"stdio.h"#include<iostream>#include<cuda.h>#include<cuda_runtime.h>//Defining two constants
__constant__ int constant_f;
__constant__ int constant_g;#defineN5//Kernel function for using constant memory
__global__ voidgpu_constant_memory(float*d_in,float*d_out){//Thread index for current kernelint tid = threadIdx.x;
d_out[tid]= constant_f*d_in[tid]+ constant_g;}
常量内存中的变量使用 __constant__ 关键字修饰
使用 cudaMemcpyToSymbol 函数吧这些常量复制到内核执行所需要的常量内存中
常量内存应合理使用,不然会增加程序执行时间
主函数调用如下:
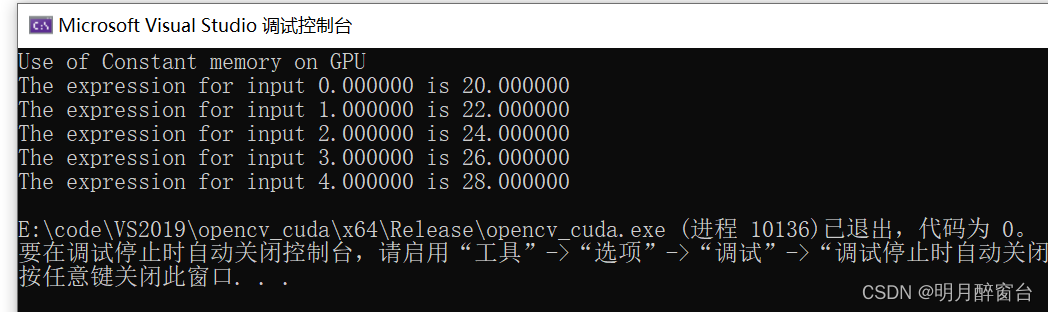
intmain(void){//Defining Arrays for hostfloat h_in[N], h_out[N];//Defining Pointers for devicefloat*d_in,*d_out;int h_f =2;int h_g =20;// allocate the memory on the cpucudaMalloc((void**)&d_in, N *sizeof(float));cudaMalloc((void**)&d_out, N *sizeof(float));//Initializing Arrayfor(int i =0; i < N; i++){
h_in[i]= i;}//Copy Array from host to devicecudaMemcpy(d_in, h_in, N *sizeof(float), cudaMemcpyHostToDevice);//Copy constants to constant memorycudaMemcpyToSymbol(constant_f,&h_f,sizeof(int),0,cudaMemcpyHostToDevice);cudaMemcpyToSymbol(constant_g,&h_g,sizeof(int));//Calling kernel with one block and N threads per block
gpu_constant_memory <<<1, N >>>(d_in, d_out);//Coping result back to host from device memorycudaMemcpy(h_out, d_out, N *sizeof(float), cudaMemcpyDeviceToHost);//Printing result on consoleprintf("Use of Constant memory on GPU \n");for(int i =0; i < N; i++){printf("The expression for input %f is %f\n", h_in[i], h_out[i]);}//Free up memorycudaFree(d_in);cudaFree(d_out);return0;}
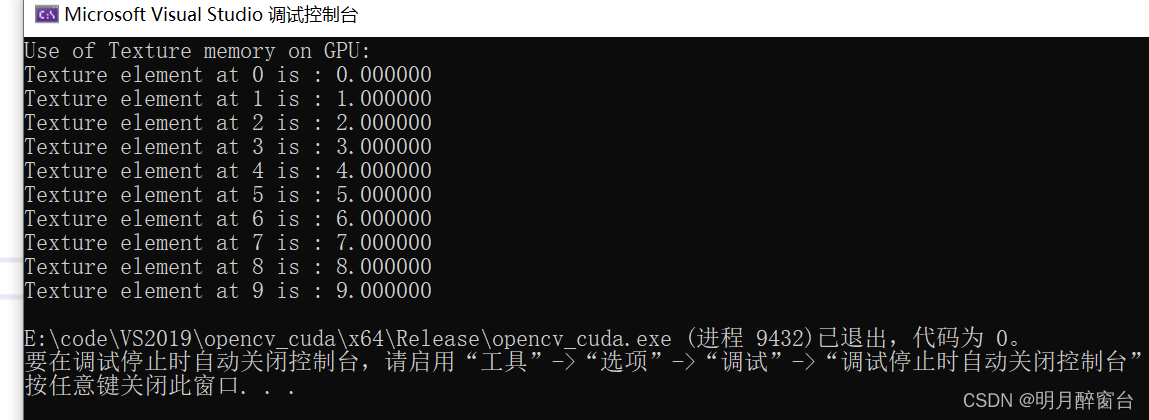
#include"stdio.h"#include<iostream>#include<cuda.h>#include<cuda_runtime.h>#defineNUM_THREADS10#defineN10//纹理内存定义
texture <float,1, cudaReadModeElementType> textureRef;
__global__ voidgpu_texture_memory(int n,float*d_out){int idx = blockIdx.x*blockDim.x + threadIdx.x;if(idx < n){float temp =tex1D(textureRef,float(idx));
d_out[idx]= temp;}}intmain(){//Calculate number of blocks to launchint num_blocks = N / NUM_THREADS +((N % NUM_THREADS)?1:0);//Declare device pointerfloat*d_out;// allocate space on the device for the resultcudaMalloc((void**)&d_out,sizeof(float)* N);// allocate space on the host for the resultsfloat*h_out =(float*)malloc(sizeof(float)*N);//Declare and initialize host arrayfloat h_in[N];for(int i =0; i < N; i++){
h_in[i]=float(i);}//Define CUDA Array
cudaArray *cu_Array;cudaMallocArray(&cu_Array,&textureRef.channelDesc, N,1);//Copy data to CUDA Array,(0,0)表示从左上角开始cudaMemcpyToArray(cu_Array,0,0, h_in,sizeof(float)*N, cudaMemcpyHostToDevice);// bind a texture to the CUDA arraycudaBindTextureToArray(textureRef, cu_Array);//Call Kernel
gpu_texture_memory <<<num_blocks, NUM_THREADS >>>(N, d_out);// copy result back to hostcudaMemcpy(h_out, d_out,sizeof(float)*N, cudaMemcpyDeviceToHost);printf("Use of Texture memory on GPU: \n");for(int i =0; i < N; i++){printf("Texture element at %d is : %f\n",i, h_out[i]);}free(h_out);cudaFree(d_out);cudaFreeArray(cu_Array);cudaUnbindTexture(textureRef);}
题目描述
给你一个下标从 0 开始长度为 n 的字符串 num ,它只包含数字。
如果对于 每个 0 < i < n 的下标 i ,都满足数位 i 在 num 中出现了 num[i]次,那么请你返回 true ,否则返回 false 。
示例 1:
输入&a…
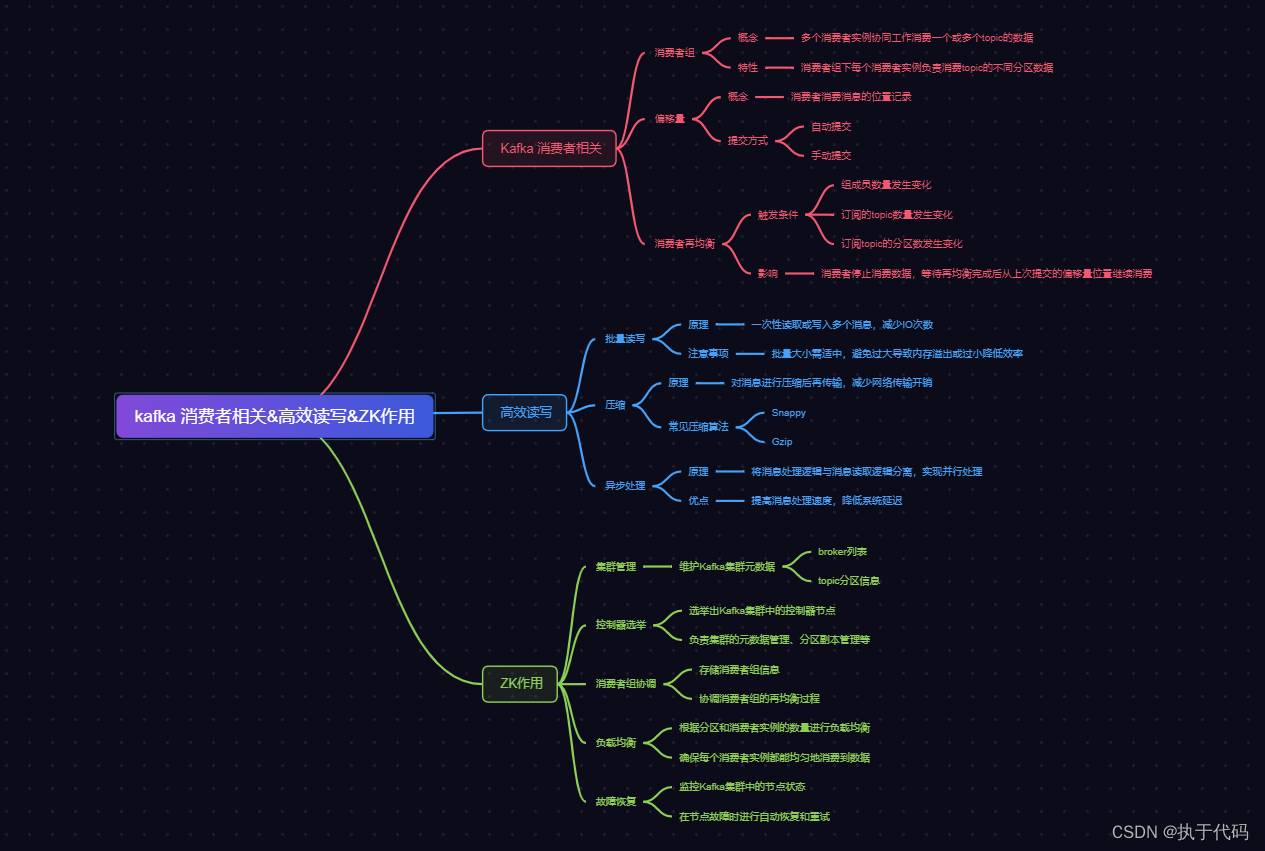
消费者分区分配策略 目录概述需求: 设计思路1.消费者分区分配策略2. 消费者offset的存储3. kafka消费者组案例4. kafka高效读写&Zk作用5. Ranger分区再分析 实现思路分析 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show …