万里长征-03-搜狐
问题
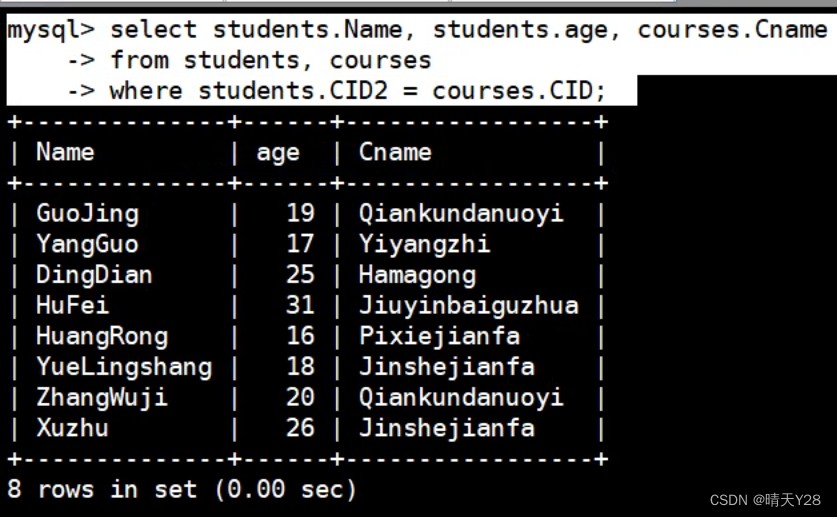
1.LeetCode103 二叉树的锯齿形层序遍历
103. 二叉树的锯齿形层序遍历 - 力扣(LeetCode)
2.LeetCode5 最长回文子串
5. 最长回文子串 - 力扣(LeetCode)
3.Kafka为何那么快
GPT问答
Kafka为何那么快
Kafka 以其高性能和低延迟广受欢迎,原因在于其设计中的几个关键因素:
- 顺序写入磁盘:
- Kafka 将消息顺序地写入磁盘,这比随机写入快得多,因为顺序写入可以充分利用磁盘的带宽。
- 零拷贝机制:
- Kafka 使用了零拷贝技术(Zero Copy),这使得消息在网络传输过程中不需要被多次拷贝,从而提高了传输效率。零拷贝技术允许数据直接从磁盘传输到网络缓冲区,而不需要在用户态和内核态之间进行数据拷贝。
- 分区和并行处理:
- Kafka 将数据分片成多个分区(Partitions),每个分区可以分配给不同的消费者,从而实现并行处理。多个分区可以分布在不同的机器上,实现负载均衡和高吞吐量。
- 批量处理:
- Kafka 支持批量消息传递(Batch Processing),可以在一次网络请求中发送或接收多条消息。这样减少了网络开销,提高了吞吐量。
- 高效的存储格式:
- Kafka 使用了一种高效的二进制消息格式。这种格式使得消息在写入和读取时都非常高效,减少了序列化和反序列化的开销。
- 高效的索引机制:
- Kafka 使用稀疏索引和段文件(Segment Files),使得消息查找非常高效。每个段文件都有一个索引,消费者可以快速找到消息的位置。
- 内存映射文件:
- Kafka 使用内存映射文件(Memory-Mapped Files),使得磁盘上的数据可以被直接映射到内存中进行读写操作,从而提高了 I/O 性能。
- 异步复制:
- Kafka 的副本机制是异步复制的,主节点在写入数据后不需要等待所有副本节点的确认,减少了写入延迟。
- 高效的网络协议:
- Kafka 使用了一种高效的二进制网络协议(基于 TCP),减少了网络通信的开销。
- 简化的消费者模型:
- Kafka 的消费者模型非常简化,不需要中心化的协调服务来管理消费者状态,消费者自己负责跟踪读取的偏移量(Offset),这减少了协调开销。
这些设计决策共同作用,使得 Kafka 能够实现高吞吐量、低延迟的消息处理能力,适用于大规模、高并发的数据流处理场景。
rabbitmq消息是顺序写入磁盘吗
RabbitMQ 的消息存储和处理机制与 Kafka 有一些显著的不同。RabbitMQ 并不总是顺序地将消息写入磁盘,其消息存储机制依赖于不同的持久性设置和队列类型。以下是一些关键点:
- 持久性设置:
- 如果消息和队列被标记为持久(durable),RabbitMQ 会将消息写入磁盘以保证在服务器重启后消息不会丢失。持久消息会在收到时立即被写入磁盘。
- 非持久消息通常只保存在内存中,虽然在内存压力大时也可能被写入磁盘,但这不是默认行为。
- 内存和磁盘的使用:
- RabbitMQ 首先将消息保存在内存中,以提高消息的吞吐量和处理速度。
- 当内存使用达到一定阈值时,RabbitMQ 会将消息转移到磁盘上,以防止内存溢出。这种情况下,消息写入磁盘的顺序可能会有所不同。
- 队列类型:
- 不同类型的队列有不同的消息存储策略。例如,经典队列(Classic Queue)和 Quorum Queue 在消息存储和复制上有不同的实现方式。
- Quorum Queue 是基于 Raft 共识算法实现的,提供了更高的可靠性和一致性的消息存储,但其性能和消息写入顺序可能会受到影响。
- 消息确认机制:
- RabbitMQ 支持多种消息确认机制(如消息确认、发布确认等),这些机制可以影响消息何时被写入磁盘以及写入的顺序。
总的来说,RabbitMQ 不总是顺序地将消息写入磁盘。消息的写入顺序和时机受多种因素影响,包括消息和队列的持久性设置、内存使用情况、队列类型和消息确认机制等。
相比之下,Kafka 设计上的一个显著特点是顺序写入磁盘,这使其在高吞吐量和低延迟的日志存储和流处理场景中表现优异。而 RabbitMQ 作为一个强大的消息队列系统,提供了丰富的功能和灵活性,但在消息持久化和存储机制上与 Kafka 有着不同的设计和优化。
总结
- 顺序写可以最大的利用磁盘的带宽
- 零拷贝允许磁盘直接到网络缓冲区,不用经过多次copy,内核不用多次切换
- 批量处理机制
4.MySQL中B树 B+树区别
GPT问答
MySQL中B树 B+树区别
B树(B-Tree)和 B+树(B+ Tree)是两种常见的树形数据结构,用于数据库和文件系统的索引结构。它们都有助于高效地存储和检索数据,但它们在实现和性能上有一些关键的区别。
B树(B-Tree)
- 节点结构:
- B树的每个节点可以包含多个键和子节点指针。
- 每个节点的键和子节点指针数量有一个上限和下限,具体取决于树的阶(degree)。
- 所有叶子节点不一定在同一层。
- 叶子节点:
- 叶子节点包含实际的数据记录。
- 由于数据可以存在于所有节点(不仅仅是叶子节点),因此查找数据时可能在非叶子节点找到。
- 搜索效率:
- 查询过程中,数据可能在任何层次的节点中找到,导致查询路径可能较短。
B+树(B+ Tree)
- 节点结构:
- 内部节点(非叶子节点)只存储键和子节点指针,不存储实际数据。
- 叶子节点存储所有的数据记录。
- 所有叶子节点在同一层,并通过指针相互链接,形成一个链表结构。
- 叶子节点:
- 叶子节点包含所有的数据记录和指向相邻叶子节点的指针。
- 这种结构使得范围查询和顺序访问更加高效。
- 搜索效率:
- 数据记录只存在于叶子节点,因此查找数据时必须到达叶子节点,但由于叶子节点在同一层,所以树的高度较低,查找路径相对稳定。
主要区别总结
- 数据存储位置:
- B树:数据存储在所有节点中(包括内部节点和叶子节点)。
- B+树:数据仅存储在叶子节点中。
- 叶子节点的结构:
- B树:叶子节点没有特别的链接结构。
- B+树:叶子节点通过链表结构相互链接,便于范围查询和顺序访问。
- 树的高度:
- B树:由于数据存储在各层节点中,树的高度可能会比 B+树稍高。
- B+树:所有数据都在叶子节点中,内部节点的高度较低,树的高度更稳定。
- 查询效率:
- B树:数据可能在任何节点中找到,查询路径可能较短。
- B+树:数据必须到叶子节点才找到,但由于叶子节点在同一层,查找路径较稳定。
应用场景
- B树:适用于需要频繁插入和删除操作的场景,因为它不需要保持叶子节点的链表结构。
- B+树:适用于需要高效范围查询和顺序访问的场景,比如数据库索引结构。
在 MySQL 中,InnoDB 存储引擎使用 B+树作为其默认索引结构,因为这种结构非常适合数据库的范围查询和顺序访问。
给我用java类的方式,写出B+树的叶子结点结构和内部节点结构
假设每个节点可以存储一个固定数量的键,并且每个叶子节点包含一个指向下一个叶子节点的指针。
B+ 树叶子节点结构
public class BPlusTreeLeafNode<K extends Comparable<K>, V> {
private static final int MAX_KEYS = 4; // 假设每个节点最多存储4个键
private K[] keys;
private V[] values;
private int keyCount;
private BPlusTreeLeafNode<K, V> next;
}
B+ 树内部节点结构
public class BPlusTreeInternalNode<K extends Comparable<K>> {
private static final int MAX_KEYS = 4; // 假设每个节点最多存储4个键
private K[] keys;
private Object[] children; // 可以是叶子节点或内部节点
private int keyCount;
}
说明
- 叶子节点(
BPlusTreeLeafNode)包含键和值的数组以及指向下一个叶子节点的指针。 - 内部节点(
BPlusTreeInternalNode)包含键的数组和子节点指针的数组。 - 为了简化实现,假设每个节点最多存储4个键。
- 实际的插入和删除逻辑需要处理节点分裂、合并等操作,这里省略了具体实现。
这些类提供了 B+ 树节点的基本结构。在完整实现中,你需要实现插入、删除、查找等操作,以及处理节点的分裂和合并。
总结
- B+树,主要就是去看叶子节点和非叶子节点的特性
- 叶子节点才有值,非叶子节点只是做导航用的
- 为了满足范围查询,有个next相邻指针的概念
- 查询路径稳定,不会有大波动
5.、Netty、BIO、NIO、AIO框架
GPT问答
给我介绍下Netty、BIO、NIO、AIO
Netty 是一个基于 Java 的高性能、异步事件驱动的网络应用框架,主要用于开发高性能的网络服务器和客户端。Netty 提供了丰富的功能,如:
- 支持多种协议(如 HTTP、FTP、SMTP、WebSocket 等)。
- 高度可配置的线程模型。
- 内置的编解码器,方便进行数据处理。
- 异步和事件驱动的编程模型,简化了并发编程。
Netty 的核心是基于 NIO 的,提供了更高的抽象层,使开发更容易和高效。
BIO (Blocking I/O) 是 Java 传统的 I/O 模型,基于流的阻塞式 I/O 操作。其特点是:
- 每个连接都会有一个独立的线程进行处理。
- 阻塞式 I/O 操作会导致线程等待,直到数据准备好。
- 简单易用,但在高并发场景下性能较差,因为线程资源会被大量消耗。
// 示例:BIO的Socket服务器
import java.io.*;
import java.net.*;
public class BioServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
while (true) {
Socket socket = serverSocket.accept(); // 阻塞等待连接
new Thread(() -> handle(socket)).start();
}
}
private static void handle(Socket socket) {
try (BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(socket.getOutputStream(), true)) {
String line;
while ((line = in.readLine()) != null) {
out.println("Echo: " + line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
NIO(Non-blocking I/O)
NIO (Non-blocking I/O) 是 Java 1.4 引入的一种新的 I/O 模型,提供了非阻塞式的 I/O 操作。其特点包括:
- 基于通道(Channel)和缓冲区(Buffer)。
- 使用选择器(Selector)管理多个通道,进行单线程多路复用。
- 非阻塞的 I/O 操作,不会阻塞线程。
// 示例:NIO的Socket服务器
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
public class NioServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(8080));
serverSocketChannel.configureBlocking(false);
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select();
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = socketChannel.read(buffer);
if (bytesRead > 0) {
buffer.flip();
socketChannel.write(buffer);
} else if (bytesRead == -1) {
socketChannel.close();
}
}
}
}
}
}
AIO(Asynchronous I/O)
AIO (Asynchronous I/O) 是 Java 7 引入的一种 I/O 模型,也称为 NIO.2。AIO 提供了异步的 I/O 操作,其特点包括:
- 异步非阻塞 I/O 操作,通过回调机制处理 I/O 事件。
- 更加高效地处理大量连接,适合高性能、高并发的网络应用。
// 示例:AIO的Socket服务器
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
public class AioServer {
public static void main(String[] args) throws IOException {
AsynchronousServerSocketChannel serverSocketChannel =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(8080));
serverSocketChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
@Override
public void completed(AsynchronousSocketChannel socketChannel, Void attachment) {
serverSocketChannel.accept(null, this); // 继续接受新的连接
ByteBuffer buffer = ByteBuffer.allocate(1024);
socketChannel.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
buffer.flip();
socketChannel.write(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
if (buffer.hasRemaining()) {
socketChannel.write(buffer, buffer, this);
} else {
buffer.clear();
socketChannel.read(buffer, buffer, this);
}
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
try {
socketChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
try {
socketChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
@Override
public void failed(Throwable exc, Void attachment) {
exc.printStackTrace();
}
});
// 防止主线程退出
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
总结
- BIO 适用于连接数目较小且固定的场景,编程模型简单直观。
- NIO 适用于连接数目多且连接较短的场景,能够通过单线程处理多连接,但编程复杂度较高。
- AIO 适用于连接数目多且连接较长的场景,能够实现完全的异步非阻塞 I/O 操作,编程模型复杂。
- Netty 基于 NIO,提供了更高的抽象层,简化了开发过程,同时具有高性能和高可扩展性,适用于大多数网络应用场景。
6.ZooKeeper的理解,分布式事务2PC、3PC、TCC、Paxos实现思路及优缺点
GPT问答
ZooKeeper是什么,有什么特性,为啥可以满足cp
Apache ZooKeeper 是一个开源的分布式协调服务,用于管理大型分布式系统中的配置信息、命名、同步和组服务等任务。它提供了一组简单的原语,分布式应用程序可以用它来实现更高层次的服务,例如同步、配置管理和命名等。
ZooKeeper 的特性
- 简化开发:通过提供简单的接口和一致性保证,简化了分布式应用程序的开发。
- 高可用性:ZooKeeper 通过其分布式架构实现高可用性。它的服务可以在多个服务器之间复制,保证即使个别节点失效也不会影响整个系统的运行。
- 严格的顺序保证:ZooKeeper 保证对所有更新操作的全局顺序。
- 高性能:ZooKeeper 在读操作上具有高性能,因为读操作可以在所有节点上进行。
- 一致性:ZooKeeper 保证客户端在任何时刻读到的数据是最新的或者是一个较新的数据版本。
ZooKeeper 的一致性模型
ZooKeeper 是一个 CP 系统(在 CAP 定理中),即它保证一致性(Consistency)和分区容忍性(Partition Tolerance),可能会在可用性(Availability)上做出牺牲。
- 一致性(Consistency):
- 在 ZooKeeper 中,当一个操作返回成功时,意味着系统所有节点的数据都是一致的。
- ZooKeeper 的一致性通过其严格的顺序保证和持久性机制实现。所有对 ZooKeeper 的写操作(例如创建、更新或删除节点)都会按照全局顺序写入日志,并且这些日志会在所有节点上进行复制。
- 分区容忍性(Partition Tolerance):
- ZooKeeper 能够在网络分区的情况下继续运行。它采用 ZAB (ZooKeeper Atomic Broadcast) 协议来保证在分区情况下的容错性。
- 当网络分区发生时,ZooKeeper 会选出一个主节点,只要超过半数的节点仍然能够通信,ZooKeeper 就能继续服务。
- 可用性(Availability):
- 在 CAP 定理中,ZooKeeper 在某些情况下会牺牲可用性以保证一致性和分区容忍性。例如,在网络分区期间,如果无法达成多数节点的共识,ZooKeeper 可能会停止提供服务,以避免不一致的数据状态。
它通过 ZAB 协议和复制机制保证一致性和分区容忍性,这使得 ZooKeeper 在 CAP 定理中满足 CP 的要求。尽管在极端情况下可能会牺牲可用性,但这也是为了保证系统的一致性和整体可靠性。
分布式事务2PC、3PC、TCC、Paxos实现思路及优缺点
分布式事务在分布式系统中用于保证跨多个节点的操作要么全部成功,要么全部失败。以下是四种常见的分布式事务实现思路:2PC(Two-Phase Commit)、3PC(Three-Phase Commit)、TCC(Try-Confirm/Cancel)、Paxos。
- Two-Phase Commit (2PC)
实现思路
2PC 分为两个阶段:
- 阶段 1:准备阶段(Prepare Phase)
- 协调者(Coordinator)向所有参与者(Participants)发送准备请求(Prepare Request)。
- 参与者执行事务操作并将操作结果写入日志,但不提交(Commit),然后向协调者返回准备就绪(Ready)或失败(Abort)。
- 阶段 2:提交阶段(Commit Phase)
- 如果所有参与者都返回准备就绪,协调者发送提交请求(Commit Request),参与者提交事务。
- 如果有任何一个参与者返回失败,协调者发送回滚请求(Rollback Request),参与者回滚事务。
优点
- 实现相对简单。
- 容易理解和实现基本的事务一致性。
缺点
- 同步阻塞:所有参与者在等待协调者的决策时会被阻塞。
- 单点故障:协调者故障时,系统可能会进入不一致状态。
- 超时问题:参与者可能长时间等待协调者的指令。
- Three-Phase Commit (3PC)
实现思路
3PC 在 2PC 的基础上增加了一个准备提交阶段,分为三个阶段:
- 阶段 1:询问阶段(CanCommit Phase)
- 协调者向所有参与者发送询问请求(CanCommit Request)。
- 参与者返回同意(Yes)或拒绝(No)。
- 阶段 2:准备提交阶段(PreCommit Phase)
- 如果所有参与者都同意,协调者发送准备提交请求(PreCommit Request)。
- 参与者在准备提交阶段确认准备就绪。
- 阶段 3:提交阶段(DoCommit Phase)
- 协调者发送提交请求(DoCommit Request),参与者提交事务。
优点
- 减少了单点故障的影响:通过增加阶段,降低了协调者故障带来的风险。
- 更加非阻塞:参与者可以在等待协调者指令时进行超时处理。
缺点
- 实现复杂度增加。
- 仍然存在网络分区可能带来的问题。
- Try-Confirm/Cancel (TCC)
实现思路
TCC 模型分为三个操作:
- Try:尝试执行,预留资源。
- Confirm:确认执行,真正提交事务。
- Cancel:取消执行,释放资源。
优点
- 灵活性高:可以根据业务需求自定义 Try、Confirm 和 Cancel 的逻辑。
- 异步执行:Try 操作可以异步执行,提高系统性能。
缺点
- 实现复杂度高:需要明确实现每个步骤的业务逻辑。
- 一致性依赖于业务逻辑的正确实现。
- Paxos
实现思路
Paxos 是一种分布式一致性算法,用于在分布式系统中达成共识。主要步骤如下:
- 提议阶段(Prepare Phase)
- 提议者(Proposer)向所有接受者(Acceptor)发送提议请求,附带提议编号。
- 接受者返回承诺不再接受编号低于当前请求的提议。
- 提交阶段(Accept Phase)
- 提议者收到多数接受者的承诺后,发送提交请求。
- 接受者同意该提议并更新状态。
- 学习阶段(Learn Phase)
- 一旦提议被多数接受者接受,提议者通知所有节点该提议已被选定。
优点
- 高容错性:在大多数节点存活的情况下仍能达成一致。
- 非阻塞:在网络分区情况下仍能继续操作。
缺点
- 高复杂度:实现和理解相对复杂。
- 性能开销:多次通信和协调带来较高的性能开销。
总结
- 2PC 和 3PC 适用于需要严格事务一致性的场景,但存在同步阻塞和单点故障问题。
- TCC 提供了更高的灵活性和性能,但需要自定义业务逻辑实现。
- Paxos 适用于需要高容错和一致性的分布式系统,但实现复杂且性能开销较大。根据具体业务需求和系统特性选择合适的分布式事务方案,是设计分布式系统时的关键决策。
- 2PC和3PC在做取舍,一致性?可用性?
7. Scala跟Java的区别关系
GPT问答
Scala跟Java的区别关系
Scala 和 Java 都是运行在 JVM(Java Virtual Machine)上的编程语言,但它们在设计理念、语法特性和应用场景等方面有着显著的区别和关系。以下是一些主要的区别和关系:
设计理念与范式
- Java 是一种面向对象编程(OOP)语言,强调类和对象的使用。
- Scala 是一种多范式编程语言,支持面向对象编程(OOP)和函数式编程(FP),其设计目标是提供一种更简洁、灵活和表达力更强的编程方式。语法简洁性
- Java 语法相对冗长,需要写较多的模板代码(boilerplate code)。
- Scala 语法简洁,减少了大量的模板代码。例如,Scala 中可以使用类型推断来减少显式类型声明。
// Java 代码示例
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
// Scala 代码示例
object HelloWorld extends App {
println("Hello, World!")
}
函数式编程支持
- Java 虽然在 Java 8 之后引入了 lambda 表达式和 Stream API,但其函数式编程特性相对有限。
- Scala 原生支持函数式编程,拥有强大的高阶函数、不可变数据结构和模式匹配等特性。
// Java 中的 lambda 表达式
List<String> list = Arrays.asList("a", "b", "c");
list.forEach(item -> System.out.println(item));
// Scala 中的高阶函数
val list = List("a", "b", "c")
list.foreach(println)
类型系统
- Java 使用相对传统的类型系统,泛型在某些情况下可能带来复杂性。
- Scala 拥有更强大和灵活的类型系统,包括类型推断、协变和逆变、隐式转换、类型类等特性。
并发编程模型
- Java 提供了线程、同步块、并发包(如
java.util.concurrent)等用于并发编程。 - Scala 提供了更高级的并发编程模型,如 Akka Actor 模型,用于简化复杂的并发编程。
互操作性
- Java 和 Scala 都运行在 JVM 上,因此它们可以互相调用。Scala 可以直接调用 Java 的类库,反之亦然。
// Scala 调用 Java 类库
import java.util.Date
val now = new Date()
println(now)
// Java 调用 Scala 类库
import scala.collection.JavaConverters;
List<String> list = Arrays.asList("a", "b", "c");
scala.collection.immutable.List<String> scalaList = JavaConverters.asScalaBufferConverter(list).asScala().toList();
System.out.println(scalaList);
社区与生态系统
- Java 拥有庞大的社区和丰富的类库、框架,如 Spring、Hibernate 等。
- Scala 也有自己的生态系统,如 Akka、Play Framework 和 Spark 等,但其社区相对较小。
编译器和工具链
- Java 编译器(javac)和工具链发展成熟,支持广泛的集成开发环境(IDE)和构建工具(如 Maven 和 Gradle)。
- Scala 编译器(scalac)相对复杂,编译时间较长,但也支持诸如 sbt 这样的构建工具和 IDE 插件。
总的来说,Scala 和 Java 各有优劣,选择使用哪种语言可以根据具体的项目需求、团队熟悉度和开发效率等因素来决定。
总结
- 互相是调用是我没想到的
写到最后