
提示:
文章目录
- 前言
- 一、InFusion:扩散模型助力,效率提高20倍!(2024)
- 1. 摘要
- 2. 算法
- 3. 效果
- 二、2D Gaussian Splatting
- 三、Bootstrap 3D:从扩散模型引导三维重建
- 1.摘要
- 2.相关工作
- 3.方法
- 1.Boostrapping by Diffusion 通过扩散模型促进
- 2.梯度方向和 Diffusion
- 4.实验
- 补充材料
- 四、GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
- 五、Gaussian Grouping:分割和编辑任何高斯
- 1.摘要
- 2.任何掩码输入和一致性
- 3.三维高斯渲染和分组
- 4.局部高斯编辑
- 5.实验
- 六、InstantSplat:无界稀疏视图的40秒无位姿高斯泼溅
- 总结
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、InFusion:扩散模型助力,效率提高20倍!(2024)

项目主页: https://johanan528.github.io/Infusion/
代码仓库: https://github.com/ali-vilab/infusion
机构单位: 中科大,港科大,蚂蚁,阿里巴巴
1. 摘要
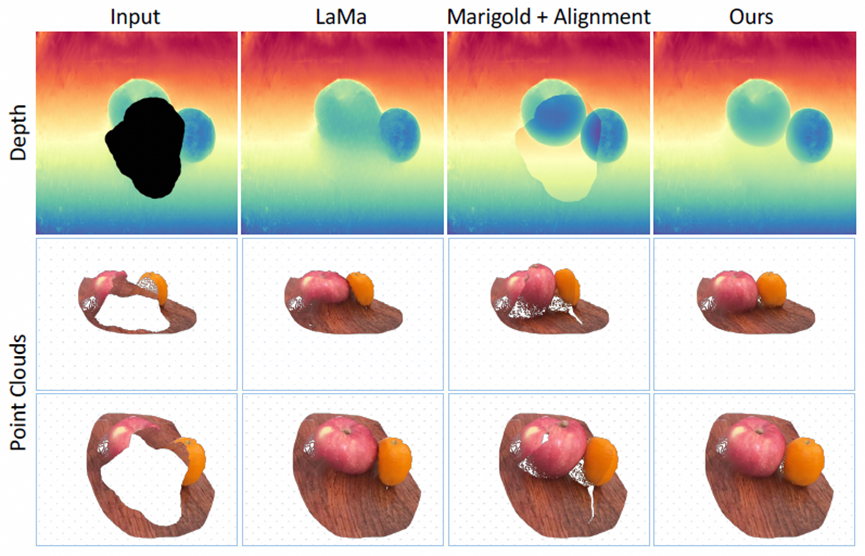
本工作研究了3D GS编辑能力,特别着重于补全任务, 旨在为不完整的3D场景补充高斯,以实现视觉上更好的渲染效果。与2D图像补全任务相比,补全3D高斯模型的关键是要确定新增点的相关高斯属性,这些属性的优化很大程度上受益于它们初始的3D位置。为此,我们提出 使用一个图像指导的深度补全模型来指导点的初始化 ,该模型基于2D图像直接恢复深度图。这样的设计使我们的模型能够以与原始深度对齐的比例填充深度值,并且利用大规模扩散模型的强大先验。得益于更精确的深度补全,我们的方法,称为InFusion,在各种复杂场景下以足够更好的视觉保真度和效率(约快20倍)超越现有的替代方案。并且 具有符合用户指定纹理 或 插入新颖物体 的补全能力。

(a)InFusion 无缝删除 3D 对象,以用户友好的方式进行纹理编辑和对象插入。
(b)InFusion 通过 扩散先验学习深度补全,显着提高深度修复质量。
现有方法对3D高斯的补全,通常使用对不同角度的渲染图象进行图像层次的补全,作为3D GS新的训练数据。但是,这种方法往往会因生成过程中的不一致而产生模糊的纹理,且速度缓慢。
值得注意的是,当初始点在3D场景中精确定位时,高斯模型的训练质量会显著提高。因此一个实际的解决方案是将需要补全位置的高斯设置到正确的初始点,从而简化整个训练过程。因此,在为需补全高斯分配初始高斯点时,进行深度补全是关键的,将修复后的深度图投影回3D场景能够实现向3D空间的无缝过渡。本文利用预训练的扩散模型先验,训练了一个深度补全模型。该模型在与未修复区域的对齐以及重构物体深度方面展现了显著的优越性。这种增强的对齐能力确保了补全高斯和原3D场景的无缝合成。此外,为了应对涉及大面积遮挡的挑战性场景, InFusion可以通过渐进的补全方式,体现了它解决此类复杂案例的能力。
2. 算法

整体流程如下:
1)场景编辑初始化:首先,根据编辑需求和提供的mask,构造残缺的高斯场景。
2)深度补全:选择一个视角,渲染得到的利用图像修复模型如(Stable Diffusion XL Inpainting )进行,修复单张RGB图像。再利用深度补全模型(基于观测图像)预测出缺失区域的深度信息,生成补全的深度图。具体来说,深度补全模型接受三个输入:从3D高斯渲染得到的深度图、相应的修复后彩色图像和一个掩码,其中掩码定义了需要补全的区域。先使用变分自编码器(VAE)将深度图和彩色图像编码到潜在空间中。其中通过将深度图重复使其适合VAE的输入要求,并应用线性归一化,使得深度值主要位于[-1, 1]区间内。后将编码后的深度图加噪得到的近高斯噪声,将掩码区域设置为0的编码后的深度图,编码后的RGB指导图像,以及掩码图像,在channel维度进行连接,输入到U-Net网络进行去噪,逐步从噪声中恢复出干净的深度潜在表示。再次通过VAE解码得到补全后的深度图。
3)3D点云构建:使用补全的深度图和对应的彩色图,通过3D空间中的反投影操作,将2D图像点转换为3D点云,这些点云随后与原始的3D高斯体集合合并。
4)Gaussian模型优化:合并后的3D点云通过进一步迭代优化和调整,以确保新补全的高斯体与原始场景在视觉上的一致性和平滑过渡。
3. 效果
1.Infusion表现出保持 3D 连贯性的清晰纹理,而基线方法通常会产生模糊的纹理,尤其是复杂场景下

2.同时通过与广泛使用的其他基线方法的比较,以及相应的点云可视化。比较清楚地表明,我们的方法成功地能够补出与现有几何形状对齐的正确形状。
3.Infusion可以通过迭代的方式,对复杂的残缺gaussian进行补全。

5.得益于Infusion补全3d高斯点的空间准确性,用户可以修改补全区域的外观和纹理。

6.通过编辑单个图像,用户可以将物体投影到真实的三维场景中。此过程将虚拟对象无缝集成到物理环境中,为场景定制提供直观的工具

二、2D Gaussian Splatting
标题:2D Gaussian Splatting for Geometrically Accurate Radiance Fields
代码:https://github.com/hbb1/2d-gaussian-splatting
论文:https://arxiv.org/abs/2403.17888
三、Bootstrap 3D:从扩散模型引导三维重建

标题:Bootstrap 3D Reconstructed Scenes from 3D Gaussian Splatting
来源:电子科技大学;深圳先进技术研究院;中科院
1.摘要
3D高斯喷溅(3D-GS),已经为神经渲染技术的质量和速度设置了新的基准。然而,3D-GS的局限在合成新视角,特别是偏离训练中的视角。此外,当放大或缩小时,也会出现膨胀和混叠( dilation/aliasing)等问题。 这些挑战都可以追溯到一个潜在的问题:抽样不足。本论文提出了一个自举方法:采用一个扩散模型,利用训练后的3D-GS增强新视图的渲染,从而简化训练过程。该方法是通用的,并且可以很容易地集成。

2.相关工作
扩散模型。其预测过程可公式化如下:

此过程中,时间步0的原始分布从时间步t的分布中逐渐恢复,通过优化负对数似然的通常变分界进行训练。若所有的条件都被建模为具有可训练均值函数和固定方差的高斯模型,训练目标为:
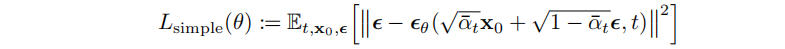
图像到图像的生成。这是扩散模型的一个实际应用。本文专门讨论了一种独特的生成形式,其中输入图像由扩散模型再生, 利用一个定义的破损强度 s r s_r sr 来促进可控的生成。 s r s_r sr 的大小直接影响输出图像与原始图像的偏差程度,值越大,变化就越大 。给定一个输入图像 I I I,在编码到潜在空间 x I x^I xI时,我们认为xI 是基于 s r s_r sr 的 T个时间步之一。 例如 s r s_r sr = 0.1和T = 1000,反向扩散过程中,在扩散的时间步长 T T T × s r s_r sr = 100处 直接应用 p θ ( x I ) p_θ(x^I) pθ(xI),只执行反向扩散过程的最后100个时间步长来进行部分再生。
3.方法
1.Boostrapping by Diffusion 通过扩散模型促进
在3D-GS的优化过程中,从稀疏的COLMAP [19,20]点集开始,通过分裂或克隆产生额外的点,最终得到数百万个小而密集的三维高斯模型。由于最大点的大小(分裂)和梯度的积累(克隆)阈值是需要调整的超参数,我们主要关注梯度的方向,这将显著影响新点生成的位置和方式。
因为训练数据集之外,存在一些看不见的部分,训练过的3DGS合成的新视图 I I I,可能不能准确地反映GT图像。我们将 I I I 视为 I ′ I' I′ 的“部分退化版本”。可以利用扩散模型,实现对 I I I 的 image-to-image integration,得到image density I ′ I' I′ 。 I ′ I' I′ 可以表示为添加到合成图像 I I I 中的噪声集合。

然而,在实践中实现这种理想的情况是非常困难的。这不仅是因为 1.目前可用的开源扩散模型不能很好地生成所有场景中的部分图像 ,而且还因为 2.许多场景本身都是复杂和独特的 。此外, 3.引导(bootstrap)的过程也引入了一定程度的不确定性 。理想情况下,构建的3D场景在所有角度都保持一致。然而,扩散模型引入的可变性使得保证扩散模型从一个新视角重新生成的场景与来自另一个新视角的场景无缝对齐具有挑战性。另外, 4.并不是合成的新视图图像的所有部分都应该被再生 ,如果我们将扩散过程应用到整个图像中,一些已经训练良好的部分会在一定程度上被扭曲。本文探索了一种更通用、更稳定的方法。
2.梯度方向和 Diffusion
引入Bootstrapping 的时机 。对于整体场景一致性的问题,需要从一个相对完整的阶段开始引导。对于通过扩散模型再生的新视图图像,如果周围的上下文相似且 homogeneous (应该翻译为同类或同质),这种环境下再生的内容往往变化不大。差异程度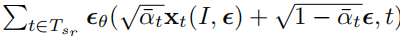
部分是有限的,不仅仅是由于初始上下文的相似性,还因为扩散过程只应用在最后几个时间步(t越接近0,t时刻引入的噪声越小)。
在3D-GS模型构建一个相对完整的场景后,对每个训练图像进行bootstrap。为了从训练图像 I t I_t It 中获得新图像 I n t I_n^t Int,稍微改变训练相机的 q v e c qvec qvec 和 t v e c tvec tvec,以获得新的视图相机。然后通过扩散模型D,重新生成 I d t I_d^t Idt=D( I n t I_n^t Int)。实践中,从每个训练像机中生成多个新视图。
可控的扩散方向。 重新生成的内容分为两个部分: 一个包含了对场景的忠实表示,但随着改变而改变,另一个显示了被扩散模型修改的场景的新的表示 。通过管理原始训练部分和bootstrap部分相关的损失比值,我们可以实现3D-GS模型的全局稳定训练过程。
bootstrap损失: L b L_b Lb= || I d t I_d^t Idt - I n t I_n^t Int||;对每个训练像机,使用混合损失:
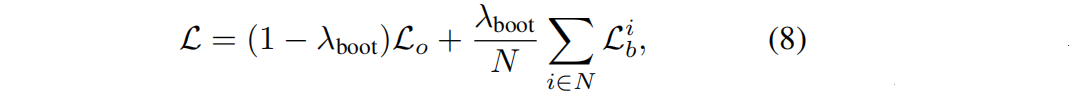
L o L_o Lo是GT图像的原始3D-GS损失, ∑ i ∈ N L b i \sum_{i∈N}L_b^i ∑i∈NLbi 是基于该训练摄像机及其周围像机的所有新视图变体引入的引导损失的和,N是总变体数。例如,如果训练摄像机有周围摄像机的两侧,并且我们用它的2个变体来引导每个摄像机,那么N是6。这种设计选择是由于大多数三维重建数据集[83–85]的共同特征,其中位于近距离的摄像机通常会捕捉相邻的场景.
对于训练中不可见的视角,渲染明显无序或缺乏细节,bootstrap足以在多个视点中进行一致的更改。在我们的方法中,当引导场景涉及到损失项设置中的相同部分时,我们会对这些公共区域的值进行平均(这些部分通常被合成了很多次),这确保了不同引导场景中的元素被规范化。
稠密化过程中,点被分裂或克隆。不完美部分的周围点被 initially flattened,以补偿重生的新视图渲染中的不一致性。经过多次迭代的积累,大点被分割成小点,小点沿着梯度方向被克隆(这是主要焦点,代表场景中的细粒度)。实际应用中,大的点可以被认为是较小的高斯分布的粗聚集。
补偿过程往往是不稳定的,因为渲染甚至在同一场景部分也发生变化。 然而,本文利用多个重新生成的新视图,来训练单个视图 。对于这些渲染,如果其中的细节不冲突,那么它们能表示看不见的细节,或可以自由修改的粗糙建模;如果它们之间存在冲突,则选择最普遍适用的方法来对齐。给定一个受到不同梯度方向更新的点,称为 ∑ i ∈ m ∂ g m \sum_{i∈m}∂g_m ∑i∈m∂gm。 m m m 为不同梯度方向的总数, ∂ g m ∂g_m ∂gm为对应的梯度。如果我们将这些高维梯度方向抽象成简单的二维方向,我们就可以进一步简化这个问题。
假设二维xy平面上的每个梯度只包含两个方向,正y指向GT,x表示偏差,为了简单起见,我们将每个方向分离成一个累积形式。我们假设扩散模型通常产生的图像与背景一致,但细节有所不同。然后通过建立一个适当的梯度积累幅度阈值,并将其与我们在等式8中概述的优化策略相结合,可以达到所期望的优化结果,如图3所示。

经过几轮分裂后,点将足够小,在这些点上只会出现少量的梯度(即使没有,λboot也足够小)。为了进一步克隆,只有这些恰好指向一个方向的梯度和较小的偏差才有可能超过这个阈值,然后我们得到一个相对可靠的bootstrap克隆点,构成了该场景中的细节。
4.实验
数据集。数据集包括Mip-NeRF360 [83]的7个场景,两个来自 Tanks&Temples[84]的场景,两个场景来自 DeepBlending[85]的场景。
Baseline。原始3D-GS [1], Mip-NeRF360 [83],
iNGP [10] 和 Plenoxels [9],以及最近的 Scaffold-GS。
设置。对于bootstrap部分,使用 Stable Diffusion (SD) 2v.1模型 [30]及其精调模型作为初始扩散模型。共进行了4个阶段的实验,其中何时和如何应用bootstrap是不同的。实验初始阶段,以特定的时间间隔执行bootstrap,为每个引导跨度提供1000次迭代。在这1000次迭代间隔中,我们在前500次迭代中将 λ b o o t λ_{boot} λboot设置为 0.15,在剩下的500次迭代中将其降低为 0.05。在配置扩散模型时,我们采用了一个逐步降低的图像破损强度 s r s_r sr,范围从0.05到0.01,跨越100个DDIM [28]采样的时间步长。不同的数据集,有不同的策略来创建新的视图像机(随机或连续)。引导重新生成的图像将使用原始的SD2.1v模型来执行。在第二阶段的实验中,SD2.1v模型分别对每个训练数据集进行细化,同时保持其他配置不变。调整SD2.1v模型,结果有显著的波动:一些场景在指标上显示了明显的进展,而另一些场景表现出明显的退化,4.2节会讨论到。
在对每个场景的模型进行微调之后,为进一步解锁bootstrap的潜力,在第三阶段实验中,将扩散破损强度 s r s_r sr从0.15调整到0.01,每个场景的所有bootstrap图像都设置为随机。虽然最初三个阶段的实验已经证明了比最初的3D-GS有相当大的改进,但在渲染特定视图方面仍然存在挑战。因此,在第四阶段实验中,使用了一个upscale的扩散模型来进行bootstrap再生。
结果分析。bootstrap方法的有效性已经在各种场景中得到了证明,特别是在具有无纹理表面和观察不足的具有挑战性的环境中。此外,该方法还显示了其在改变相机进行新视图渲染时的适应性,突出了其在捕捉均匀细微差别方面的熟练程度,如图4。

指标对比。与原始3D-GS相比,仅应用一个interval的bootstrap后,质量指标的改进可以追溯到7k次迭代。即使第一阶段实验中简单地应用SD2.1v模型,与原始3D-GS相比也有着显著进展。此外,在对每个场景的SD2.1v模型进行微调后,在所有数据集和指标上都取得了最好的结果,在它们自己的数据集上的性能甚至超过了Mip-NeRF 360。鉴于第三阶段实验的总体性能指标与第二阶段相似,在补充材料中提供第三阶段实验的详细报告。

新视角伪影的缓解。除了指标,我们还解决了在改变相机变焦或渲染视图时出现的一些问题(一定程度上明显偏离了训练集)。通过生成如图5所示的伪细节,bootstrap减轻了在原始3D-GS中观察到的伪影。通过第三阶段实验,在特定视图中出现的伪影确实可以在保持强性能指标的同时得到缓解。第四阶段实验将主要集中于进一步减轻这些伪影(见附录说明)。从图1和图6中可以看出,第四阶段,在欠采样视图中观察到的失真和表下的混乱质量已经被大大修改。基于Mip-NeRF 360数据集的第四阶段实验表明,upscale扩散模型的应用在包含许多看不见的视图的开放场景中特别有效(可能是因为我们没有对它进行微调)。对于大多数室内场景,通过高upscale散模型引入显著的噪声往往会对性能指标产生实质性的负面影响。

时间消耗比较见表2。一般来说,扩散时间步长的增加,这与破损强度 s r s_r sr有关,以及在我们的第四阶段实验中使用的upscale扩散模型,显著增加了额外的训练时间。
特征分析。比较了四个阶段的实验中的渲染细节。 在最初的两个阶段,如果我们仅仅根据生成质量进行评估,而不考虑地面真相,那么当用肉眼观察时,它们的质量似乎有最小的差异。在对每个特定场景进行微调后,我们观察到在特定环境细节方面取得了显著进展。例如,在图4的房间中,考虑了门上方的封闭摄像头。在我们的第一阶段实验中,相机只以一种类似于相机的基本形式表示。然而,在我们的第二阶段实验中,摄像机显示出与地面真相相似的曲线。第三阶段实验中,虽然由于DDIM采样步骤的增加,细节发生了改变和改进,如图5所示,但这些改变并不能完全弥补场景中存在的实质性缺陷。此外,这些产生的细节往往发生在低频率,这与我们的损失项密切相关。由于我们的方法强调增强相互协调而不是相互冲突的细节,由扩散模型产生的高频细节往往表现出可变性。最终,第四阶段实验能够显著地修改看不见的内容
消融实验。表3评估了扩散模型的超参数,只有破损强度 s r s_r sr和减重 λ b o o t λ_{boot} λboot是重要的。 常见的超参数通常会影响传统文本到图像生成的结果,如文本提示、文本提示比例和[30]中描述的eta,在我们的实验设置中影响很小。我们只在特定的时间间隔内应用bootstrap技术(第6000次迭代后进行连续的bootstrap),但发现这种方法导致不稳定性。当过度使用时,连续的引导往往会生成完全脱离上下文的场景。即使是专门对每个场景的扩散模型进行微调,它的不稳定性仍然是一个重要的问题。在第二阶段的设置中,通过连续引导获得的最高结果偶尔会超过我们的最佳记录。然而,实现这些优越的结果是相当具有挑战性的,所需的训练时间大约是我们的第三阶段实验的训练时间的2.5倍。这种时间和精力的显著增加突出了连续bootstrap的低效率,尽管它有可能实现稍微更好的性能指标。请注意,其他基础消融研究都是在第一阶段实验的配置上进行测试的。
补充材料
1.Bootstrapping 视角的创建。COLMAP中,相机内参在给定的场景中保持一致, 外参包括qvec和tvec(栅格化中必不可少的),引入两种类型的视图Bootstrap:随机的,和连续的 。对于随机视图的创建,在qvec和tvec中加入正态分布噪声,比例因子分别为0.1和0.2,然后对qvec进行归一化。对于连续法,将间隔均匀地插入后续摄像机的qvec和tvec中,然后对qvec进行归一化。
对 s r s_r sr和 λ b o o t λ_{boot} λboot的解释, s r s_r sr的递减设置相对容易理解。随着训练过程的进展,模型逐步改善了其对重建的三维场景的表示,因此需要更少的修改。在对SD2.1v模型进行微调后,我们建议通过微调的模型所做的改变应该更好地与GT一致。因此,我们可以在早期的迭代中应用更大的 s r s_r sr,以确保初始修正更有影响力。 λ b o o t λ_{boot} λboot设置为两阶段方法:第一阶段,使用一个更大的 λ b o o t λ_{boot} λboot来补偿伪影。这是通过使用扩散模型生成更多的上下文一致渲染来实现的,有助于稳定初始输出,后续阶段进一步细化。
Bootstrap间隔。对于共30k次迭代,Bootstrap仅应用于第6000、9000、15000、15000、18000、21000、24000、27000和29000次迭代,每次持续1000次迭代。这个时间与3,000个迭代周期相一致,其中3D-GS模型的占用率被重置。通过将Bootstrap干预与这些重置点同步,有效地实现理想的更改变得更容易,因为由于占用变量的重置(reset of occupancy variables),模型处于更容易接受修改的状态。另一方面,1000次迭代的Bootstrap间隔,与3000次迭代周期很一致,提供了一种平衡的方法来合并新的细节而不超载系统。这个间隔是最优的,因为扩散模型产生的细节可能会相互冲突,因此没有必要连续运行完整的训练周期。此外,Bootstrap损失的计算,如等式8中所述、是资源密集型的,显著减慢了整体的训练速度。
SD策略:我们认为新视图渲染图是“beoken”的,它们可以被扩散模型修正和增强。因此,选择用于微调的图像应该代表这些破碎的渲染图及其相应的GT。微调扩散模型的方法:利用一半的训练集来训练3D-GS模型。然后,我们在6000个迭代标记处使用模型来渲染训练集的剩余一半,由于潜在的差异和伪影,将这些渲染识别为“beoken的”渲染。这个过程对训练集的每一半重复两次,使我们能够生成数百张微调图像。此外,在4,000个迭代checkpoint处的原始3D-GS模型也适合使用,因为它为我们的目的显示了适当的缺陷水平。这个特定的checkpoint可以用来获得额外的微调渲染。
Upscale 扩散模型的实现。 Upscale diffusion 专门设计来解决重要的伪影,如distortion和 jumbled masses,我们认为这是广泛的“破坏”方面的渲染。为了缓解这些问题,首先使用微调的SD2.1v模型采用了一个再生过程。随后,为了进一步细化输出,我们应用一个isothermal 西格玛值为3的二维高斯模糊核来模糊图像。这个模糊的步骤有助于消除缺陷和减少噪音。在模糊后,我们将图像缩小了3倍;然后利用Upscale 扩散模型将图像放大四倍,其中采用强噪声增强来提高图像的质量和细节,如图7所示。我们实现了从第6000次迭代到第18000次迭代的模糊和升级过程,并结合了基本的引导技术。需要注意的是,图7中描述的情况只代表了第6000次迭代时的场景。随着引导通过这些迭代的继续,图像中的细节变得越来越细粒度和自然。Upscale扩散模型是原始的SD-x4-upscaling,没有进一步的微调。

在高档扩散模型中加入显著的噪声增强确实可以导致已经训练良好的部分图像的改变;为防止这些改变可能导致的质量下降,训练过程中,等式8将项N的数量调整为8。该调整包含了6张由SD2.1v生成的Bootstrap图像,并添加了2个由高档扩散模型生成的额外图像。
四、GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
GauStudio,一种新的模块化框架,用于建模3D高斯溅射(3DGS),为用户提供标准化的、即插即用的组件,以轻松地定制和实现3DGS管道。是一种具有前景和skyball背景模型的混合高斯表示方法。实验表明,这种表示法减少了无界户外场景中的伪影,并改进了新的视图合成。最后,我们提出了高斯溅射表面重建(GauS),这是一种新的渲染然后融合方法,用于3DGS输入的高保真网格重建,不需要微调。总的来说,我们的GauStudio框架、混合表示和GauS方法增强了3DGS建模和渲染能力,实现了更高质量的新视图合成和表面重建。
五、Gaussian Grouping:分割和编辑任何高斯

1.摘要
Gaussian Splatting实现了高质量和实时的三维场景合成,但它只专注于外观和几何建模,而缺乏对细粒度的对象级场景的理解。Gaussian Grouping扩展了GS,在开放世界的三维场景中联合重建和分割任何东西:用一个紧凑的ID编码增强每个GS,根据它们的对象实例/隶属度进行分组,具体是利用SAM的二维mask预测,并引入三维空间一致性正则化,在可微渲染过程中监督ID编码。与隐式NeRF表示相比,离散的三维高斯模型具有高视觉质量、高粒度和高效率。在高斯分组的基础上,进一步提出了一种局部高斯编辑方案,该方案在三维对象去除、inpaint、着色和场景重构等多功能场景编辑应用中显示出了良好的效果。
高斯分组继承了SAM强大的zero shot二维场景理解能力,并通过产生一致的新视图合成和分割,将其扩展到三维空间。为进一步提高分组精度,引入了一种利用三维空间一致性的非监督三维正则化损失:使最近个k的三维高斯的ID编码,在特征距离上非常接近。这有助于三维物体内部的高斯分布或严重遮挡在渲染时更充分的监督。
2.任何掩码输入和一致性
保留了高斯模型的所有属性(如它们的数量、颜色、不透明度和大小),同时添加了新的身份编码参数(类似于颜色建模的格式)。这允许每个高斯分布被分配给其在3D场景中所表示的实例或东西。
为了模拟开放世界场景,我们采取了一组多视图捕获,以及由SAM自动生成的二维分割,以及通过SfM [40]校准的相应相机。

为了实现跨视图的二维mask的一致性,我们使用了一个训练有素的zero-shot tracker[7]来传播和关联mask。这还提供了3D场景中的mask id 的总数。图2 (b)可视化了关联起来的2D mask标签。相比于[39]提出的基于cost的线性分配方法,简化了训练难度,同时避免了每次渲染迭代中重复计算匹配关系,加速超过60×,并具备更好的性能,特别是在SAM的密集和重叠mask下。
3.三维高斯渲染和分组
ID 编码。为了将属于同一实例的三维高斯分组,除了现有的高斯性质,我们还在每个高斯分布中引入了一个新的参数:身份编码是一个长度为16的可学习的、紧凑的向量,足以以计算效率区分场景中的不同对象/部分。与场景的依赖于视图的外观建模不同,实例ID在各种渲染视图中是一致的。因此,我们将身份编码的SH degree设置为0,只对其 direct-current component进行建模。
通过渲染来分组。为了优化ID编码,图2(c)将ID 向量以可微的方式渲染为二维图像。从原始GS中提取可微的三维高斯渲染器,并将渲染过程类似于gs中的颜色(SH系数)优化。
GS采用神经点的 α ′ α' α′ 渲染[18,19],进行深度]排序和混合N个与像素重叠的有序点,计算所有高斯分布对单个位置像素的影响:

其中,每个像素的最终二维mask身份特征 E i d E_{id} Eid 是,每个高斯长度16的身份编码 e i e_i ei 的加权和,由该像素上的高斯影响因子 α i ′ α_i' αi′加权。参考[55],通过测量二维高斯的协方差 Σ 2 D Σ^{2D} Σ2D,乘以每个点学习到的不透明度 α i α_i αi,来计算 α i ′ α_i' αi′;其中 Σ 3 D Σ^{3D} Σ3D为三维协方差矩阵, Σ 2 D Σ^{2D} Σ2D为平面2D版本。J是3D-2D投影的仿射近似的雅可比矩阵,W是 world-to-camera的变换矩阵。
group损失:
1.二维ID损失。给定公式1中渲染的2D特性 E i d E_{id} Eid作为输入,使用一个线性层 f f f,将特征维数恢复到K+1,然后取 s o f t m a x softmax softmax( f f f( E i d E_{id} Eid))进行ID分类(K是3D场景中的mask总数),采用标准的交叉熵损失 L 2 d L_{2d} L2d进行K+1类别分类。
2.三维正则化损失。除了间接的二维监督,还引入无监督的三维正则化损失来约束ID编码 e i e_i ei的学习:利用三维空间一致性,通过最近的 k个三维高斯分布的ID编码与其特征距离拉近。这允许3D对象内部的三维高斯分布,或在基于点的渲染期间被严重遮挡(在几乎所有的训练视图中都不可见)得到更充分的监督。公式3的 F F F表示为与线性层(在计算二维身份损失时共享)相结合的softmax操作。用m个采样点将KL散度损失形式化为:
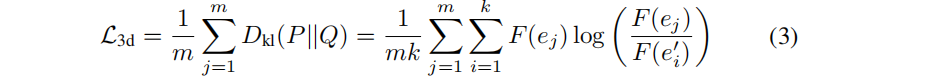 其中P包含三维高斯分布的ID编码
e
e
e,集合Q={
e
1
′
e_1'
e1′,
e
2
′
e_2'
e2′,…,
e
k
′
e_k'
ek′}是三维空间中的k个最近邻。结合原始GS的损失
L
o
r
i
L_{ori}
Lori,总损失为:
其中P包含三维高斯分布的ID编码
e
e
e,集合Q={
e
1
′
e_1'
e1′,
e
2
′
e_2'
e2′,…,
e
k
′
e_k'
ek′}是三维空间中的k个最近邻。结合原始GS的损失
L
o
r
i
L_{ori}
Lori,总损失为:
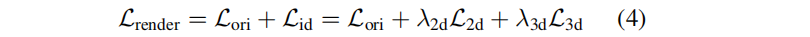
4.局部高斯编辑
图3用分组的三维高斯,来表示整个三维场景。基于解耦的场景表示,冻结大多数训练好的高斯,只调整相关的或新添加的高斯。对于三维对象的去除,只需删除编辑目标的三维高斯分布;对于三维场景的重新组合,在两个高斯群之间交换三维位置。过程没有参数调优。
对于三维inpaint,先删除高斯,然后添加新高斯,渲染由LAMA [41]的二维inpaint结果监督。对于三维对象着色或风格迁移,只调整相应高斯群的颜色(SH)参数,同时固定它们的三维位置和大小,以保留学习到的三维场景几何

5.实验
数据集。实验改进了现有的 LERF-Localization[14]评估数据集,并提出了LERF-Mask数据集,在该数据集中,我们使用精确的掩模手动注释了LERF本地化中的三个场景,而不是使用粗糙的边界框。对于每个3D场景,我们平均提供了7.7个文本查询和相应的GT mask标签。
定性评估。在Mip-Nerf360中部9组场景中的7组上进行了高斯分组测试,LLFF [28]、Tanks&Temples[16]和Instruct-NeRF2NeRF[10]中获取了不同的3D场景案例来进行视觉比较。还采用了边界度量mBIoU来更好地进行分割质量测量。
实施细节。ID编码为16维,实现了类似于rgb特征的前向和后向的cuda栅格化。分类线性层有16个输入信道和256个输出信道。训练中, λ 2 d λ_{2d} λ2d = 1.0和 λ 3 d λ_{3d} λ3d = 2.0。Adam优化器,ID编码的习率为0.0025;线性层学习率为0.0005。三维正则化损失的k = 5和m = 1000。A100 GPU上进行30K迭代训练。
三维对象的删除,我们得到了对所选实例id进行分类的三维高斯分布。后处理包括首先去除异常值,然后使用凸包得到与删除对象对应的所有高斯函数。三维对象的inpaint,在删除区域附近初始化高斯分布,使用与SPIn-NeRF相同的LPIPS损失微调。
与现有的开放词汇表三维分割方法的对比,如LERF [14]。见表1,以及图5(我们的方法的分割预测具有清晰的边界,而基于LERF的相似度计算方法只提供了一个粗略的定位区域)。由于SAM不支持语言提示,我们采用Grounding DINO ]先识别2D图像中的框,然后根据框选择相应的掩码(右边第二列)。
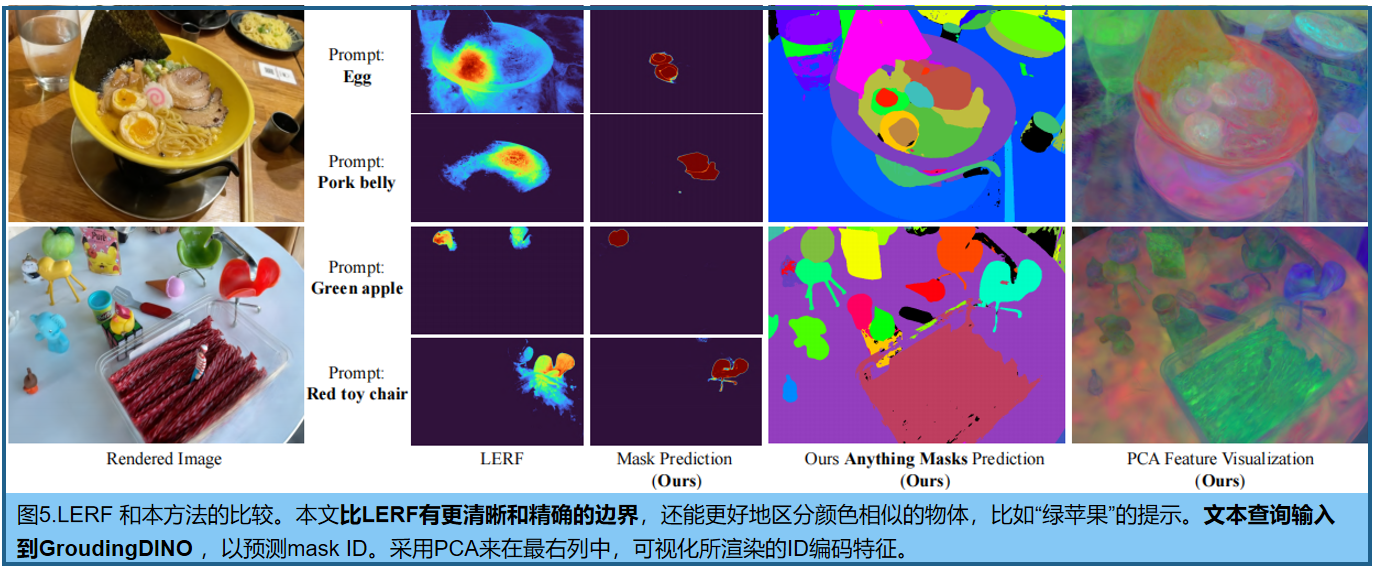

3D对象删除是从3D场景中完全删除一个对象,其中删除的实例/东西后面的背景可能会有噪声或因为没有观察而有一个洞。图6比较了GaussianGroup与蒸馏特征场(DFFs)[17]的去除效果。对于具有大对象的挑战性场景案例,我们的方法可以清晰地将三维对象从背景场景中分离出来。而DFFs的性能受到其clip蒸馏特性的质量的限制,这导致了完整的前景去除(列车箱)或不准确的区域去除与明显的伪影(卡车箱)

3D对象inpaint在物体去除的基础上,要进一步填充由于缺少观测值而导致的“空洞”,使其成为一个逼真的、视觉一致的自然三维场景。我们首先检测删除后所有视图中不可见的区域,然后在内部绘制这些“不可见区域”,而不是整个“二维对象区域”。在每个渲染视图中,我们采用二维inpaint图像来指导新引入的三维高斯图像的学习。在图7中,与SPIn-NeRF [31]相比,更好地保留了空间细节和多视图相干性。

六、InstantSplat:无界稀疏视图的40秒无位姿高斯泼溅
标题:《InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds》
作者:得克萨斯大学、英伟达研究院、厦门大学、格鲁吉亚理工学院
d
\sqrt{d}
d
1
0.24
\frac {1}{0.24}
0.241
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。







![[数据结构1.0]计数排序](https://img-blog.csdnimg.cn/direct/23ebeffbde1044878ac85646a05cad50.jpeg)

