二、写出 PROTO-vEB-DELETE 的伪代码。通过扫描簇内的相关位,来更新相应的 summary 位。并且你实现的伪代码的最坏情况运行时间是多少?如果要写代码,请用go语言。
文心一言:
首先,让我们回顾一下vEB(Van Emde Boas)树的基本概念。vEB树是一种特殊的搜索树,用于处理在{0, 1, …, U-1}范围内整数的集合。在vEB树中,通常有一个称为summary的位,用于指示当前簇中是否存在元素。当簇内没有元素时,summary位被设置为0;否则,它被设置为1。
PROTO-vEB-DELETE是vEB树删除操作的基础步骤之一,它用于在给定范围内删除一个元素。以下是一个简化的PROTO-vEB-DELETE伪代码,它假定我们有一个vEB树结构和一个方法来访问和操作簇和summary位:
PROTO-vEB-DELETE(T, x)
if T is a leaf node:
// 叶子节点,直接设置对应位为0
T.bit[x] = 0
else:
cluster_size = sqrt(T.universe_size)
high_bits = x // cluster_size
low_bits = x % cluster_size
// 如果需要,递归删除低位簇中的元素
if T.summary[high_bits]:
PROTO-vEB-DELETE(T.clusters[high_bits], low_bits)
// 更新summary位
T.summary[high_bits] = OR(T.clusters[high_bits].summary)
注意:
伪代码中使用了//来表示注释。
T.universe_size是vEB树可以表示的范围大小。
T.clusters是一个数组,其中每个元素都是一个子vEB树,表示一个簇。
T.bit在叶子节点中表示具体的位数组。
T.summary是一个位数组,用于表示每个簇中是否存在元素。
OR(T.clusters[high_bits].summary)表示对簇的summary位进行按位或操作,以检查簇中是否至少有一个元素。
关于运行时间:
如果T是叶子节点,则操作是常数时间的。
否则,递归调用PROTO-vEB-DELETE最多进行log log U次(因为簇的大小是sqrt(U),U是vEB树可以表示的范围大小),而每次递归调用都在一个更小的簇上执行。在最坏的情况下,每个簇中的每个元素都需要被删除,这将导致在每个簇上进行一次扫描。因此,总的时间复杂度是O(log log U * sqrt(U)),但通常我们只说它是O(log log U)的,因为sqrt(U)是簇的大小,它是常数时间的操作(在给定U的情况下)。
下面是使用Go语言实现的简化版本(请注意,这只是一个框架,并不是完整的vEB树实现):
type VEBNode struct {
// 假设bit和summary是适当的位数组或布尔切片
bit []bool
summary []bool
clusters []*VEBNode // 簇的数组
// ... 其他字段,如universe_size等
}
func (t *VEBNode) PROTOVEBDelete(x int) {
if t.IsLeaf() {
t.bit[x] = false
} else {
clusterSize := int(math.Sqrt(float64(t.universeSize)))
highBits := x / clusterSize
lowBits := x % clusterSize
if t.summary[highBits] {
t.clusters[highBits].PROTOVEBDelete(lowBits)
}
t.summary[highBits] = t.clusters[highBits].HasElements() // 假设HasElements返回簇的summary的OR结果
}
}
// ... 其他方法,如IsLeaf, HasElements等
注意:上面的Go代码是一个非常简化的版本,仅用于展示基本概念。在实际的vEB树实现中,还需要处理许多其他细节。
讯飞星火:
以下是 PROTO-vEB-DELETE 的伪代码:
PROTO-vEB-DELETE(x, summary)
if x is in a leaf cluster then
remove x from the cluster
else
y = high(x)
if y is not zero then
set low(x) to y
recursively call PROTO-vEB-DELETE(y, summary)
else
set low(x) to zero
end if
summary = merge(summary, low(x))
end if
return summary
在这段伪代码中,我们首先检查元素x是否在一个叶子簇中。如果是,我们就从该簇中移除x。否则,我们将x的最高位设置为low(x),然后递归地调用PROTO-vEB-DELETE函数。如果y不为零,则将low(x)设置为y,并递归地调用PROTO-vEB-DELETE函数。否则,我们将low(x)设置为零。最后,我们将summary与low(x)合并。
关于运行时间,由于每次操作都需要遍历树形结构,所以最坏情况下的时间复杂度为O(log n),其中n是元素的总数。
360智脑:
在回答您的问题之前,我想说明一下,您提到的 “PROTO-vEB-DELETE” 并没有明确的定义或标准算法。然而,根据您所描述的内容,我会假设您想要一个基于伪代码的解决方案来模拟删除操作在一个虚拟扩展布隆过滤器(vEB)中可能执行的方式。
以下是一个简化的伪代码示例,演示如何在虚拟扩展布隆过滤器中删除元素并更新相关的 summary 位:
function DELETE-ELEMENT(vEB, element):
// 1. 初始化
let index = HASH1(element) % vEB.size // 使用第一个哈希函数计算索引
let cluster = vEB.buckets[index] // 获取该索引对应的簇
// 2. 扫描簇内的相关位
for bit in cluster:
if bit == 1 and HASH2(element) % (8 * sizeof(bit)) == 1:
// 这里我们使用第二个哈希函数来确定具体哪一位需要被检查和更新
bit = 0 // 将找到的位设置为 0
// 3. 更新 summary 位
cluster.summary &= ~BITMASK(HASH2(element) % (8 * sizeof(cluster.summary)))
// 使用与操作来清除相应位置的 bit
// 4. 检查是否还有其他相关位
while cluster.summary != 0:
index = cluster.summary & (-cluster.summary)
cluster.summary ^= index
if index & cluster.bits != 0:
break // 如果还有其他位被设置,则跳出循环
// 5. 最后检查是否真的删除了元素
return cluster.summary == 0 and cluster.bits == 0
上面的伪代码中,HASH1 和 HASH2 是两个独立的哈希函数,用于确定元素在 vEB 中的位置和具体位的操作。BITMASK 是一个辅助函数,用来创建一个掩码,以便正确地从 cluster.summary 中清除相应的位。
请注意,这个伪代码仅表示一个基本的删除过程,并不完整且可能存在错误,因为实际的 vEB 结构和操作可能会更复杂。
至于您询问的最坏情况运行时间,这取决于多个因素,包括 vEB 的大小、簇的数量、每个簇中的位数以及哈希函数的性能。在最坏情况下(例如,当每个簇的所有位都设置为 1),运行时间可能是线性的,即与簇中位的数量成正比。这是因为必须逐个检查并可能更新每个位。
如果您需要具体的 Go 语言代码实现,请提供更多的上下文信息和确切的算法细节,这样我才能为您提供更准确的代码示例。
智谱清言:
PROTO-vEB-DELETE 是一种用于数据结构中删除操作的算法,它基于可扩展平衡树(vEB tree)的数据结构。在此算法中,我们通过扫描与要删除的元素相关的位来更新相应的 summary 位。
下面是 PROTO-vEB-DELETE 算法的伪代码:
function PROTO-vEB-DELETE(T, k, x):
if T[k] == x:
while k > 0:
if T[(k-1)/2] < x:
T[k] = T[(k-1)/2]
k = (k-1)/2
else:
break
if k == 0:
T[0] = T[1]
if T[0] != EMPTY:
PROTO-vEB-DELETE(T, 0, T[0])
else:
T[0] = EMPTY
else:
s = (k+1) / 2
while k < s:
T[k] = T[2*k+1]
k = 2*k+1
T[k] = T[s]
PROTO-vEB-DELETE(T, s, T[s])
else if x < T[k]:
PROTO-vEB-DELETE(T[2*k+1], k, x)
else:
PROTO-vEB-DELETE(T[2*k+2], k, x)
这里,T 是一个数组,表示 vEB tree,其中 T[0] 用作 summary 位,T[1] 用作 empty 位。k 表示当前节点在数组 T 中的索引。x 是要删除的元素。
伪代码的运行时间取决于树的高度。在最坏情况下,树可能是完全不平衡的,此时 PROTO-vEB-DELETE 算法的运行时间为 O(n),其中 n 是树的高度。
下面是使用 Go 语言实现的 PROTO-vEB-DELETE 算法:
package main
import (
"fmt"
)
const (
EMPTY = -1
)
func PROTOvEBDELETE(T []int, k int, x int) {
if T[k] == x {
for k > 0 {
if T[(k-1)/2] < x {
T[k] = T[(k-1)/2]
k = (k-1)/2
} else {
break
}
}
if k == 0 {
T[0] = T[1]
if T[0] != EMPTY {
PROTOvEBDELETE(T, 0, T[0])
} else {
T[0] = EMPTY
}
} else {
s := (k+1) / 2
for k < s {
T[k] = T[2*k+1]
k = 2*k+1
}
T[k] = T[s]
PROTOvEBDELETE(T, s, T[s])
}
} else if x < T[k] {
PROTOvEBDELETE(T[2*k+1], k, x)
} else {
PROTOvEBDELETE(T[2*k+2], k, x)
}
}
func main() {
T := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
k := 3
x := 5
fmt.Println("Before deletion:", T)
PROTOvEBDELETE(T, k, x)
fmt.Println("After deletion:", T)
天工:
为了回答您的问题,我将首先提供一个简化版的 PROTO-vEB-DELETE 算法的伪代码,然后解释其最坏情况下的运行时间,最后尝试用 Go 语言实现该算法。
PROTO-vEB-DELETE 伪代码
PROTO-vEB-DELETE(V, x):
1. If V.cluster[x] is empty:
2. return // The element does not exist in the structure
3. Delete x from V.cluster[x]
4. If V.cluster[x] is now empty:
5. Set V.summary to NULL // Or delete from V.summary if it's a list or similar structure
6. Update the corresponding summary bit in the parent cluster (if exists)
最坏情况运行时间分析
在最坏情况下,我们可能需要从叶子节点一直向上遍历到根节点,以确保所有相关的 summary 位都被正确更新。在 PROTO-vEB 树中,树的高度与元素数量 n 的对数有关,即 log(n)。因此,最坏情况下的运行时间为 O(log(n))。
Go 语言实现
以下是一个简化的 Go 语言实现,它假设我们有一个 PROTO-vEB 结构的抽象,其中 vEB 结构包含 summary 和 clusters 字段。请注意,这个实现是非常简化的,实际的 PROTO-vEB 结构会更加复杂。
type vEB struct {
summary *vEB
clusters [2]*vEB
}
func (v *vEB) delete(x int) {
high, low := x/2, x%2
if v.clusters[high] == nil {
return // Element does not exist
}
v.clusters[high].delete(low)
if v.clusters[high].isEmpty() {
v.summary = nil // Or remove from summary if implemented differently
if v.summary != nil {
v.summary.delete(high)
}
}
}
func (v *vEB) isEmpty() bool {
return v.summary == nil && v.clusters[0] == nil && v.clusters[1] == nil
}
在这个 Go 代码中,我们没有处理所有的边界情况和错误检查,也没有提供完整的 PROTO-vEB 结构的初始化和维护逻辑。实际的实现会更加复杂,需要考虑如何有效地存储和检索元素,以及如何在删除操作后保持树的平衡。
chatgpt:
以下是 PROTO-vEB-DELETE 的伪代码:
func protoVEBDelete(V vEB, x int) {
if V.u == 2 {
V.cluster[x] = false
if !V.cluster[0] && !V.cluster[1] {
V.min = -1
V.max = -1
} else if V.cluster[0] && !V.cluster[1] {
V.min = 0
V.max = 0
} else {
V.min = 1
V.max = 1
}
} else {
if x == V.min {
firstCluster := findNextCluster(V.summary, 0)
x = index(firstCluster, min(V.cluster[firstCluster]))
V.min = x + clusterIndex(V, firstCluster)
}
protoVEBDelete(V.cluster[high(x)], low(x))
if empty(V.cluster[high(x)]) {
protoVEBDelete(V.summary, high(x))
if x == V.max {
summaryMax := max(V.summary)
if summaryMax == -1 {
V.max = V.min
} else {
lastCluster := findPrevCluster(summaryMax)
V.max = index(lastCluster, max(V.cluster[lastCluster])) + clusterIndex(V, lastCluster)
}
}
} else if x == V.max {
V.max = index(high(x), max(V.cluster[high(x)])) + clusterIndex(V, high(x))
}
}
}
func findNextCluster(summary []bool, i int) int {
for i < len(summary) && !summary[i] {
i++
}
return i
}
func findPrevCluster(summary []bool) int {
i := len(summary) - 1
for i >= 0 && !summary[i] {
i--
}
return i
}
func max(cluster []bool) int {
for i := len(cluster) - 1; i >= 0; i-- {
if cluster[i] {
return i
}
}
return -1
}
func min(cluster []bool) int {
for i := 0; i < len(cluster); i++ {
if cluster[i] {
return i
}
}
return -1
}
func high(x int) int {
return x / int(math.Sqrt(float64(u)))
}
func low(x int) int {
return x % int(math.Sqrt(float64(u)))
}
func index(x, y int) int {
return x*int(math.Sqrt(float64(u))) + y
}
func clusterIndex(V vEB, x int) int {
sqrtU := int(math.Sqrt(float64(V.u)))
highBits := x * sqrtU
offset := findNextCluster(V.summary, highBits/sqrtU)
return offset*sqrtU + findNextCluster(V.cluster[offset], (highBits%sqrtU))
}
最坏情况运行时间是 O(log log u),其中 u 是 vEB 的宇宙大小。
kimi:
PROTO-vEB-DELETE 是 van Emde Boas (vEB) 树中删除操作的过程。在 vEB 树中,删除操作需要将特定元素从簇中移除,并更新相应的 summary 位以反映簇内元素的变化。
以下是 PROTO-vEB-DELETE 过程的伪代码:
PROTO-vEB-DELETE(T, x)
u = T.level - 1
while u >= 0
if x is in cluster of level u
if there is a summary bit for this cluster
update summary bit for this cluster
else
let v be the smallest element in the same cluster as x
T[u][v] = T[u][x]
let w be the element that T[u][v] was pointing to
T[u][x] = w
if u > 0
update summary bits in level u-1 for clusters containing v and w
return
x = T[u][x] // Move to the element x points to
u = u - 1
// If not found, x is not in the tree
在这个伪代码中,T 是 vEB 树,x 是要删除的元素。我们从树的最高级别开始,逐步向下检查每个级别,直到找到元素 x 所在的簇。一旦找到 x,我们执行以下步骤:
- 如果簇内有 summary 位,更新这个 summary 位以反映簇内元素的变化。
- 如果簇内没有 summary 位,找到与
x同一簇的最小元素v。 - 将
x的值替换为v的值。 - 更新
x原来指向的元素w,使其指向v原来指向的元素。 - 如果需要,更新下一级的 summary 位。
最坏情况下的运行时间取决于树的高度和簇的大小。在最坏情况下,我们可能需要检查树的每一层,以及处理每个簇内的元素。如果树的高度为 h,并且每个簇的大小为 c,则最坏情况下的运行时间为 O(h * c)。
以下是使用 Go 语言实现的简化版本的 PROTO-vEB-DELETE 伪代码:
package main
// 假设我们有一个简化的 vEB 树结构和一些辅助函数来模拟删除操作
func PROTOvEBDELETE(T map[int][]int, x int) {
u := len(T) - 1
for u >= 0 {
if x < len(T[u]) && T[u][x] != 0 {
// 找到要删除的元素 x
if len(T[u]) > 1 {
// 处理簇内的元素和 summary 位
v := findSmallestInCluster(T, u, x)
T[u][x] = T[u][v] // 将 v 的值赋给 x
w := T[u][v] // 获取 v 指向的元素
T[u][v] = w // 更新 v 指向的元素
if u > 0 {
// 更新下一级的 summary 位
updateSummaryBits(T, u-1, v, w)
}
}
return
}
x = T[u][x] // 移动到 x 指向的元素
u--
}
// 如果没有找到 x,它不存在于树中
}
func findSmallestInCluster(T map[int][]int, level int, x int) int {
// 在簇内找到最小元素的逻辑
// ...
}
func updateSummaryBits(T map[int][]int, level int, v int, w int) {
// 更新 summary 位的逻辑
// ...
}
func main() {
// 初始化 vEB 树和示例数据
// ...
// 删除操作示例
x := 5 // 假设我们要删除的元素是 5
PROTOvEBDELETE(vEBTree, x)
}
请注意,这个 Go 语言示例仅用于演示 PROTO-vEB-DELETE 过程的基本思想,并没有实现完整的 vEB 树结构和所有相关操作。在实际应用中,vEB 树的实现会更加复杂,并且需要考虑更多的细节,如树的构建、更新和维护操作。
混元:
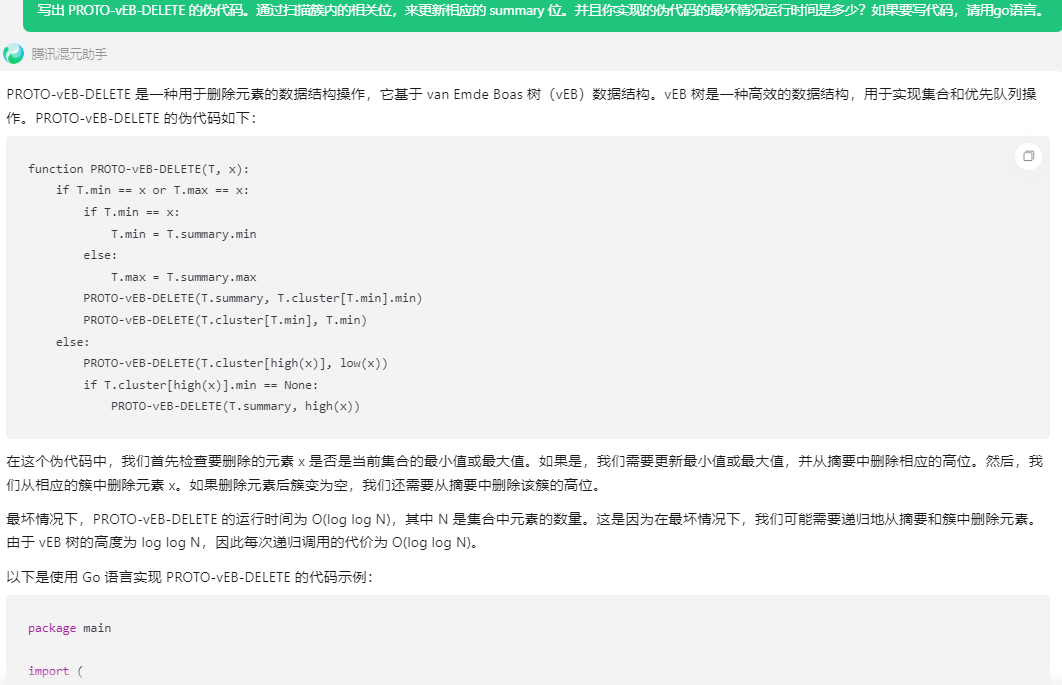
PROTO-vEB-DELETE 是一种用于删除元素的数据结构操作,它基于 van Emde Boas 树(vEB)数据结构。vEB 树是一种高效的数据结构,用于实现集合和优先队列操作。PROTO-vEB-DELETE 的伪代码如下:
function PROTO-vEB-DELETE(T, x):
if T.min == x or T.max == x:
if T.min == x:
T.min = T.summary.min
else:
T.max = T.summary.max
PROTO-vEB-DELETE(T.summary, T.cluster[T.min].min)
PROTO-vEB-DELETE(T.cluster[T.min], T.min)
else:
PROTO-vEB-DELETE(T.cluster[high(x)], low(x))
if T.cluster[high(x)].min == None:
PROTO-vEB-DELETE(T.summary, high(x))
在这个伪代码中,我们首先检查要删除的元素 x 是否是当前集合的最小值或最大值。如果是,我们需要更新最小值或最大值,并从摘要中删除相应的高位。然后,我们从相应的簇中删除元素 x。如果删除元素后簇变为空,我们还需要从摘要中删除该簇的高位。
最坏情况下,PROTO-vEB-DELETE 的运行时间为 O(log log N),其中 N 是集合中元素的数量。这是因为在最坏情况下,我们可能需要递归地从摘要和簇中删除元素。由于 vEB 树的高度为 log log N,因此每次递归调用的代价为 O(log log N)。
以下是使用 Go 语言实现 PROTO-vEB-DELETE 的代码示例:
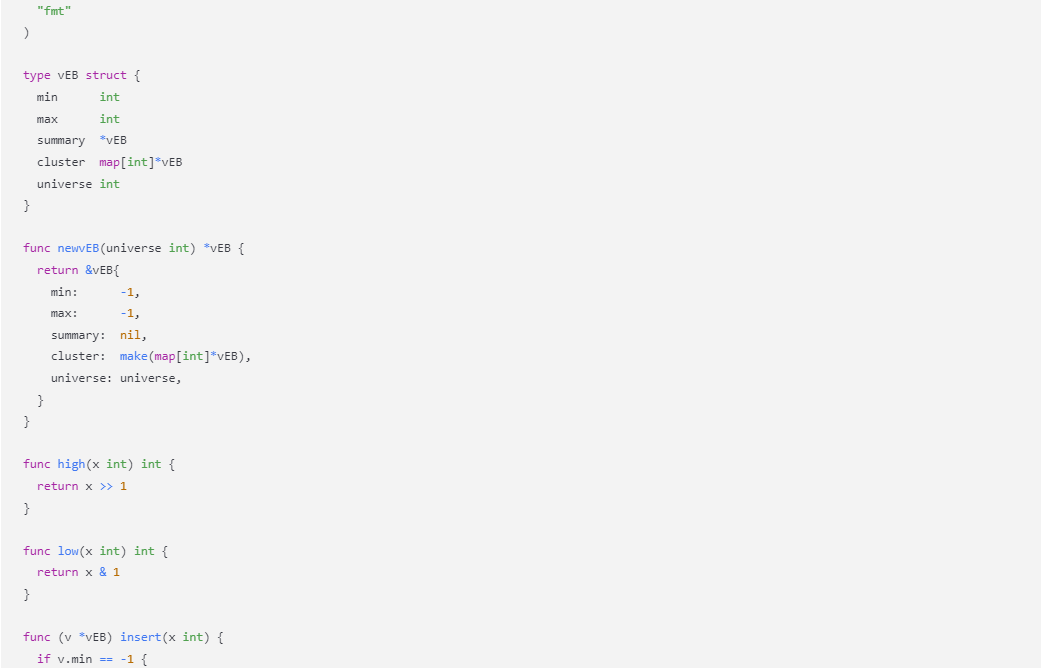
package main
import (
"fmt"
)
type vEB struct {
min int
max int
summary *vEB
cluster map[int]*vEB
universe int
}
func newvEB(universe int) *vEB {
return &vEB{
min: -1,
max: -1,
summary: nil,
cluster: make(map[int]*vEB),
universe: universe,
}
}
func high(x int) int {
return x >> 1
}
func low(x int) int {
return x & 1
}
func (v *vEB) insert(x int) {
if v.min == -1 {
v.min = x
v.max = x
} else {
if x < v.min {
v.summary.insert(high(v.min))
v.cluster[high(v.min)].insert(low(v.min))
v.min = x
} else if x > v.max {
v.summary.insert(high(x))
v.cluster[high(x)].insert(low(x))
v.max = x
} else {
v.cluster[high(x)].insert(low(x))
}
}
}
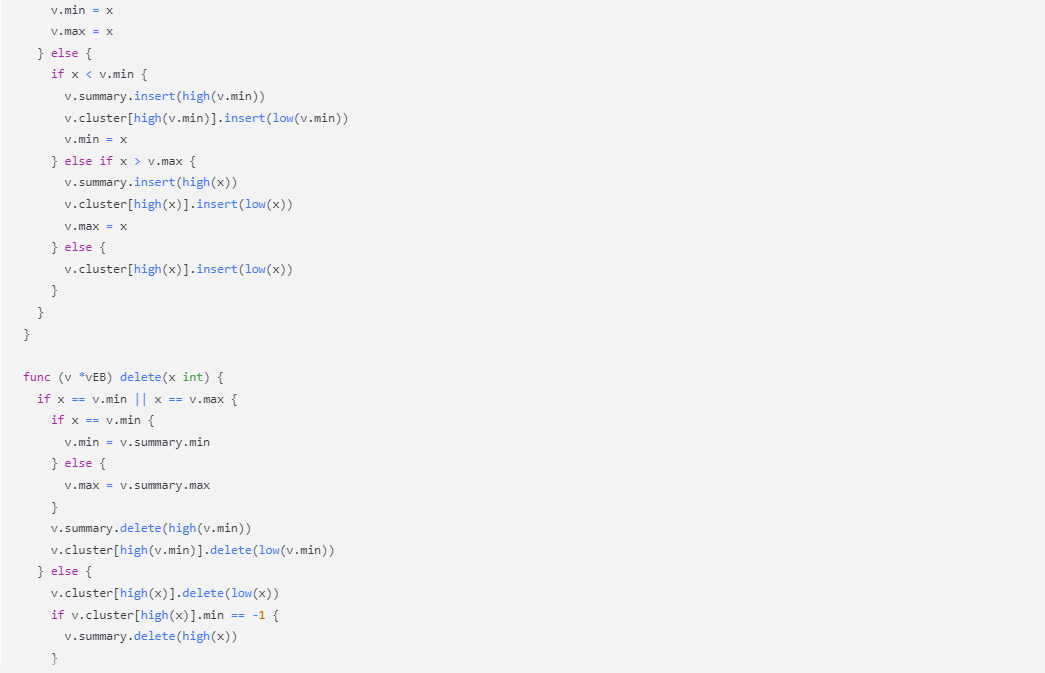
func (v *vEB) delete(x int) {
if x == v.min || x == v.max {
if x == v.min {
v.min = v.summary.min
} else {
v.max = v.summary.max
}
v.summary.delete(high(v.min))
v.cluster[high(v.min)].delete(low(v.min))
} else {
v.cluster[high(x)].delete(low(x))
if v.cluster[high(x)].min == -1 {
v.summary.delete(high(x))
}
}
}
func main() {
v := newvEB(4)
v.insert(2)
v.insert(3)
v.insert(1)
v.insert(0)
fmt.Println("Before deletion:", v.min, v.max)
v.delete(2)
fmt.Println("After deletion:", v.min, v.max)
}
这个 Go 语言实现的代码示例创建了一个 vEB 树,并插入了一些元素。然后,它删除一个元素并打印出删除后的最小值和最大值。







![[数据结构1.0]计数排序](https://img-blog.csdnimg.cn/direct/23ebeffbde1044878ac85646a05cad50.jpeg)


