前篇博文将OceanBase的存储架构巧妙地与自然界中的“水生态”进行了类比,今日我们转变视角,聚焦在与拥有相同LSM-Tree架构的其他产品的比较,深入探讨OceanBase相较于它们所展现出的独特性能。
众所周知,OceanBase数据库的存储引擎是以LSM-Tree架构为基础的。相较之下,传统的LSM-Tree结构在层次化存储方面往往表现得更为明显,而OceanBase的LSM-Tree实现则在此基础上有其独特之处。
我们以业界经典的LSM-Tree实现案例为例--单机存储引擎LevelDB:其数据流向和OceanBase数据库是类似的,数据会从可写的Activate Memtable->只读的Immutable Memtable->L0 ->L1 ->...->Ln 。磁盘数据被从上到下分成了多个层次,越下层的数据越旧。同时,在写入内存前,数据会先追加写入写前日志(WAL)中。
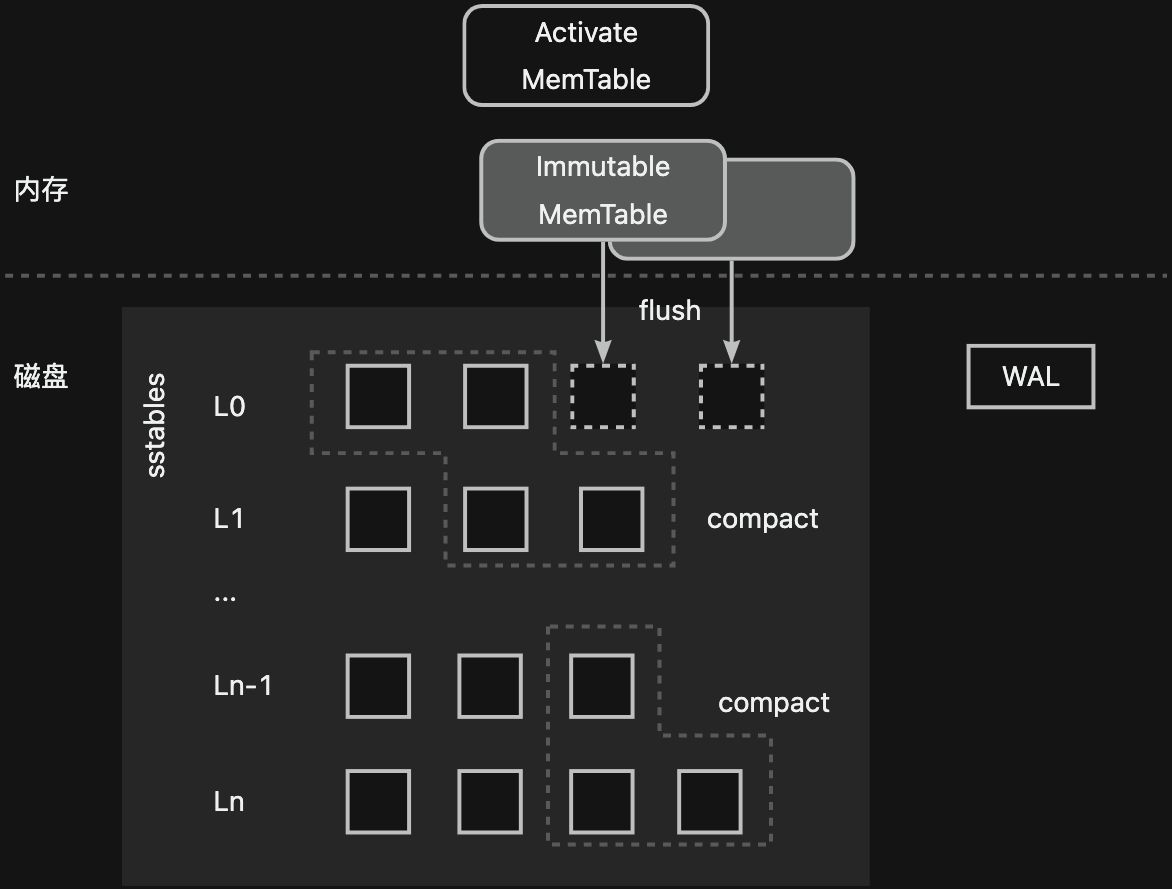
LevelDB中只读的内存数据通过Flush过程被下刷到磁盘,并按照键的顺序以SSTable文件的形式存储。L0层的SSTable文件间存在数据范围的重叠,每个SSTable文件可以被认为是一个sorted run(一个有序的集合,集合内每个元素唯一)。而L0层以下的每一层SSTable文件是有序不重叠的,也就是说,每一层的多个SSTable文件共同构成了一个sorted run。每层的SSTable文件会通过compact过程向下一层移动,每一次compact过程会涉及到相邻两层多个数据范围重叠的SSTable文件。这些SSTable文件的数据会重新进行排序与合并,形成一个新的SSTable文件。随着从上到下层数的增加,每层的可容纳SSTable文件总数据量会成倍数增长。
对于这样的分层结构,我们很容易注意到其中存在的几个问题:
- 读放大
- LSM-Tree的读操作需要从新到旧层层查找,这个过程可能需要多次I/O,放大了读盘次数。
- 空间放大
- 磁盘数据都是只读的,大量冗余和无效数据会占用额外的存储,放大了磁盘空间。
- 写放大
- 磁盘数据的有序整理不可避免的带来了额外的写入。
所谓的compact过程通过将层级之间的数据进行合并、清理无效的数据、减少上下层级有范围重叠的SSTable文件数量,改善了读放大与空间放大的问题,但由于增加了额外的磁盘写操作,引入了额外的写放大问题。
为了权衡这三者,不同的实现者通常会采用不同的compact策略:
- size-tiered compaction
- 每层有多个大小相近的sorted runs,当某一层的数据总量达到限制后将整层合并,刷写到下一层成为一个更大的sorted run,直到最大的一层维护一个sorted run。这种方式对全局有序的要求最小,可以最大程度的减少写放大。但由于数据冗余度可能较大,读放大和空间放大问题较为严重。
- leveled compaction
- 每层一个sorted run,层级之间维持相同的数据倍数比,层级越高数据量越多。每层的数据量达到限制后与下一层进行合并。通常每个sorted run被划分为多个SSTable文件,以提供了更精细化的合并任务的拆分与控制。这种compact方式将相邻层级的多个SSTable降为一个,减小了读放大和空间放大。但由于compact时最差情况可能涉及下一层级的所有SSTable文件,写放大相对更大。
- tiered+leveled compaction
- 结合了size-tiered和leveled的compact方式,某些层包含多个sorted runs,某些层只有一个sorted run。
不难看出,LevelDB采用的是tiered+leveled的compact方式,其中L0层包含了多个sorted runs,其余层只有一个sorted run,但从compact的流程来说,L0层的多个sorted runs在合并到下一层的过程里会选择L1层有数据范围重叠的SSTable文件,更接近于leveled compaction的形式。
在了解完传统LSM-Tree架构的实现与相关知识后,我们通过下图简单回忆一下上篇博客讲到的OceanBase的存储架构。可以看到,OceanBase和LevelDB单机存储引擎的数据流转方向是近乎一致的,这也是同为LSM-Tree架构的显著相同点:数据都是先追加写到日志,再写入内存;内存都分为可写的与只读的两部分,通过冻结可写部分来生成只读部分,通过将只读部分下刷到磁盘形成持久化只读数据。
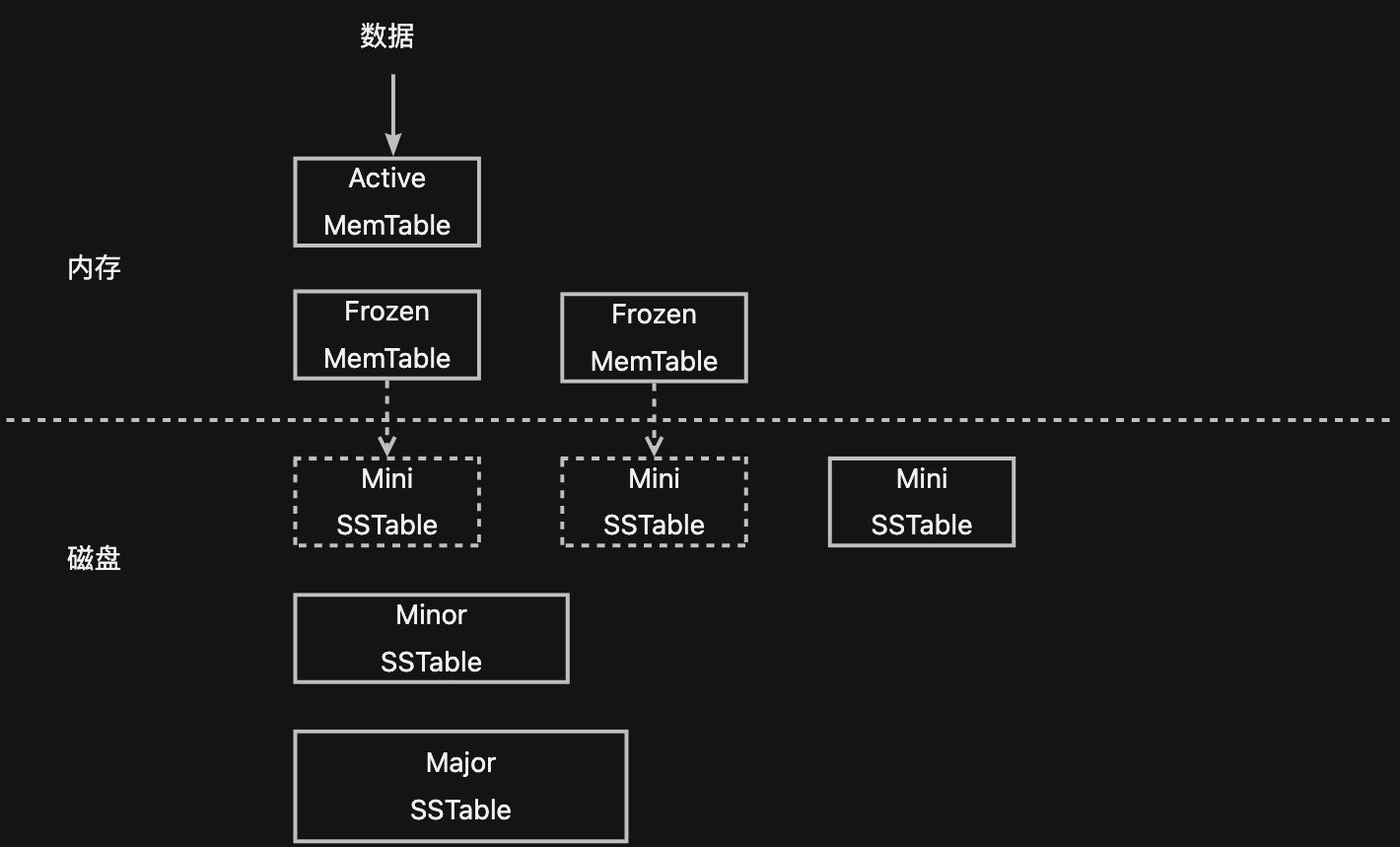
而两者的不同点主要集中在为了权衡读放大、写放大和空间放大所做的磁盘只读数据的组织和管理上。
LevelDB的每个SSTable是一个独立的文件,通过以多个SSTable文件组成一个sorted run的形式来细分每次compact操作;而为了能够有效减小写放大和空间放大,OceanBase希望没有修改过的数据不要进行重写,因此OceanBase将所有数据统一存储在一个文件(data_file)上,以定长块(宏块)的形式来分配和使用data_file的空间,每个SSTable由多个不连续的宏块组成,没有修改过的宏块能够在compact时直接重用。这种组织方式上的差异性进一步让OceanBase和LevelDB有了一些区别:
- Level的磁盘数据通常具有比较明显的层级划分,每层数据量的上限从上到下逐级增大,L0层由多个SSTable文件组成,每个SSTable文件是一个sorted run,L0层以下的每层都是一个sorted run,由一个或多个SSTable文件组成;如果以层级来划分OceanBase的磁盘数据的话,可以被认为有三层,由于有宏块这一细粒度有序集的存在,OceanBase中的L1层与L2层并不需要细分为多个SSTable,而是直接通过一个SSTable来组成sorted run。
从compact的角度来说,OceanBase也和LevelDB不一样。为了更好的控制写放大,OceanBase既可以通过tiered类型的compact过程将若干个Mini SSTable合成一个Mini SSTable,也可以通过leveled类型的compact过程将若干个Mini SSTable和一个Minor SSTable合成一个新的Minor SSTable。同时,为了最大程度的减小读放大与空间放大,OceanBase会定期进行full compact过程,将所有SSTable合成一个新的Major SSTable。由于该过程通常被放在业务低峰期,资源的大量占用被认为是可接受的。
另一方面,从具体的一些实现上来说,LevelDB的MemTable通常采用跳表的结构,而OceanBase的MemTable则采用了BTree+HashTable的混合结构。
从下一章开始,我们将展开讲讲OceanBase是如何整理SSTable的。当然,感兴趣的同学不妨先预习一下,在OceanBase的Github仓库里查看ob_compaction_util.h文件,我们将逐一揭秘其中“M系列”的compact过程。