相关说明
这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。
本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/gradient_descent.ipynb
本文将讨论利用PyTorch实现梯度下降法的细节。这是神经网络模型的共同工程基础。
关于大语言模型的内容,推荐参考这个专栏。
内容大纲
- 相关说明
- 一、为什么需要了解实现细节?
- 二、梯度下降法的理论基础
- 三、代码实现
一、为什么需要了解实现细节?
在我们使用经典机器学习模型对数据建模时,首先会从实际应用场景出发,初步分析数据的特征,获取灵感和直觉;然后,通过数学的抽象和变换,为问题选择合适的模型架构;最后,使用Python开源的算法库实现最终的模型,其中模型的参数已经被估计出来。
从软件设计的角度来讲,Python开源算法库在抽象(Abstraction)方面做得非常出色。它有效地隐藏了模型构建和训练的底层实现细节,使我们只需关注高层的概念和操作,即提供的一系列函数接口(API)。通过这些接口,通常只需几十行代码就能完成模型的构建和训练。在这个过程中,无须过多考虑模型背后复杂的数学计算,计机估计模型参数的算法实现也不再成为障碍。在理想情况下,所有底层的复杂性都被完美抽象,数据科学家的工作更加轻松和便捷(当然,作为硬币的另一面,这也可能导致数据科学家的门槛降低,进而影响相关职位的数量和薪水)。然而,不幸的是(或者幸运的是),由于模型涉及复杂的数学抽象和计算,即使软件设计和抽象再完美,也无法完全掩盖其复杂性,某些细节仍然可能“泄漏”出来,影响用户对系统的理解和操作,这就是抽象泄漏(Leaky Abstraction)。
举个例子,在训练逻辑回归模型时,某些数据集可能导致开源算法库出现错误,无法估计模型参数。对于相对经典或简单的模型,抽象泄漏的情况较少出现。然而,对于更复杂的模型,例如神经网络领域的深度学习和语言大模型,可能出现大量的抽象泄漏问题。如果不理解底层实现的细节,在这些领域将寸步难行:从理论角度来看,无法理解模型的精髓,就难以有效地优化模型,无法达到预期的模型效果;从实际应用角度来看,遇到程序问题难以修复,训练时间过长,除了参考示例实现,很难灵活运用算法库,也无法根据需求调整模型架构。
因此,这个系列的文章将深入研究开源算法库的核心细节,探讨如何基于模型的数学公式计算出相应的参数估计值。更具学术性的表述是——探讨解决最优化问题的算法。最优化问题有多种求解方法,不同算法适用于不同的模型,并在解决不同类型的问题上各有优势。鉴于篇幅限制,本文将重点关注最基础的算法:梯度下降法。后续的文章将继续讨论如何实现随机梯度下降法及其各种变种。
二、梯度下降法的理论基础
对于任何一个模型,它都对应着一个损失函数
L
L
L,假设选取的初始点为
a
0
,
b
0
a_0,b_0
a0,b0;现在将这两个点稍稍移动一点,得到
a
1
,
b
1
a_1,b_1
a1,b1。根据泰勒级数(Taylor Series)1,暂时只考虑一阶导数2,可以得到公式(1),其中
∆
a
=
a
1
−
a
0
,
∆
b
=
b
1
−
b
0
∆a = a_1 - a_0,∆b = b_1 - b_0
∆a=a1−a0,∆b=b1−b0。
∆
L
=
L
(
a
1
,
b
1
)
−
L
(
a
0
,
b
0
)
≈
∂
L
∂
a
∆
a
+
∂
L
∂
b
∆
b
(1)
∆L = L(a_1,b_1) - L(a_0,b_0) ≈\frac{∂L}{∂a} ∆a + \frac{∂L}{∂b} ∆b \tag{1}
∆L=L(a1,b1)−L(a0,b0)≈∂a∂L∆a+∂b∂L∆b(1)
如果令
(
∆
a
,
∆
b
)
=
−
η
(
∂
L
/
∂
a
,
∂
L
/
∂
b
)
(2)
(∆a,∆b)= -η(∂L/∂a,∂L/∂b) \tag{2}
(∆a,∆b)=−η(∂L/∂a,∂L/∂b)(2)
其中
η
>
0
η > 0
η>0,可以得到:
∆
L
≈
−
η
[
(
∂
L
/
∂
a
)
2
+
(
∂
L
/
∂
b
)
2
]
≤
0
∆L ≈ -η[(∂L/∂a)^2 + (∂L/∂b)^2] \le 0
∆L≈−η[(∂L/∂a)2+(∂L/∂b)2]≤0。这说明如果按公式(2)移动参数,损失函数的函数值始终是下降的,这正是我们想要达到的效果。如果一直重复这种移动,数学上可以证明,损失函数能最终得到它的最小值,整个过程就像鸡蛋在圆底锅里滚动一样,于是可以得到参数的迭代公式,见公式(3)。
a
k
+
1
=
a
k
−
η
∂
L
∂
a
b
k
+
1
=
b
k
−
η
∂
L
∂
b
(3)
a_{k + 1} = a_k - η \frac{∂L}{∂a} \\ b_{k + 1} = b_k - η \frac{∂L}{∂b} \tag{3}
ak+1=ak−η∂a∂Lbk+1=bk−η∂b∂L(3)
也可以换一个类比角度来理解梯度下降法的核心思想。想象你站在一个山坡上,目标是要找到最低的山谷。公式(3)就如同导航,在山坡上指引着你下山的方向。如果地势是向下的(损失函数的偏导数 ∂ L ⁄ ∂ a < 0 ∂L⁄∂a < 0 ∂L⁄∂a<0),那么你会朝着这个方向迈出一步;相反,如果地势是向上的( ∂ L ⁄ ∂ a > 0 ∂L⁄∂a > 0 ∂L⁄∂a>0),那么你会退回一步,避免走向更高的地方。
在数学上,向量 ∇ L = ( ∂ L / ∂ a , ∂ L / ∂ b ) ∇L = (∂L/∂a,∂L/∂b) ∇L=(∂L/∂a,∂L/∂b)被称为损失函数L的梯度。这也是公式(3)表示的算法被称为梯度下降法的原因。同时可以证明,函数的梯度正好是函数值下降得最快的方向,因此梯度下降法也是最高效的“下降”方式。
综上,可以将梯度下降法的主要算法归纳为三步:根据当前参数和训练数据计算模型损失;计算当前的损失函数梯度;利用梯度,迭代更新模型参数,如图1所示。

需要强调的是,从严谨的数学角度来看,多元可微函数 L L L在点 P P P上的梯度,实际上是由 L L L在点 P P P上各个变量的偏导数构成的向量。然而在人工智能领域,尤其是神经网络领域,为了简化表达,我们通常会用“变量的梯度” 3这一术语来指代该变量在特定情况下的偏导数或者对偏导数的估计值。
三、代码实现
下面将探索如何利用PyTorch提供的封装函数来实现梯度下降法。实现梯度下降法涉及3个关键步骤。
- 根据当前参数和训练数据,计算模型损失。
- 计算当前的损失函数梯度:利用模型定义的损失函数及训练数据,计算得到当前损失函数的梯度。需要注意的是,损失函数梯度的计算依赖于损失函数的数学表达式、用于梯度计算的训练数据,以及当前的参数估计值。这一步可以由PyTorch封装好的反向传播算法4(Back Propagation,BP)来完成。
- 利用梯度,更新模型参数:在计算得到损失函数的当前梯度后,利用这个梯度来迭代更新模型参数的估计值。这一步可以由PyTorch提供的优化算法函数(例如torch.optim.SGD)来实现。
首先进行一些准备工作,包括生成训练所需的数据和定义模型的结构。尽管这部分代码相对简单,但仍需注意以下两点。
- 在程序清单1(完整代码)的第2—4行,对变量x进行归一化处理。这一步的目的在于保证梯度下降法的稳定性。实际上,读者可以很容易地修改代码,不对x进行归一化处理,但会影响梯度下降法的稳定性,进而可能导致无法收敛的情况。在实际建模过程中,几乎会对每个变量进行归一化处理,以确保模型的稳健性和可靠性。
- 在程序清单1的第9—28行,通过继承torch.nn.Module的方式来定义线性回归模型。在具体的实现中,需要重写两个核心函数:__init__和forward。__init__函数定义了模型所需的参数及相应的初始值,forward函数中描述了如何利用这些参数获得模型的预测结果5。
1 | # 产生训练用的数据
2 | x_origin = torch.linspace(100, 300, 200)
3 | # 将变量x归一化,否则梯度下降法很容易不稳定
4 | x = (x_origin - torch.mean(x_origin)) / torch.std(x_origin)
5 | epsilon = torch.randn(x.shape)
6 | y = 10 * x + 5 + epsilon
7 |
8 | # 为了使用PyTorch的高层封装函数,通过继承Module类来定义函数
9 | class Linear(torch.nn.Module):
10 | def __init__(self):
11 | """
12 | 定义线性回归模型的参数:a, b
13 | """
14 | super().__init__()
15 | self.a = torch.nn.Parameter(torch.zeros(()))
16 | self.b = torch.nn.Parameter(torch.zeros(()))
17 |
18 | def forward(self, x):
19 | """
20 | 根据当前的参数估计值,得到模型的预测结果
21 | 参数
22 | ----
23 | x :torch.tensor,变量x
24 | 返回
25 | ----
26 | y_pred :torch.tensor,模型预测值
27 | """
28 | return self.a * x + self.b
29 |
30 | def string(self):
31 | """
32 | 输出当前模型的结果
33 | """
34 | return f'y = {self.a.item():.2f} * x + {self.b.item():.2f}'
接下来,进入核心的算法实现阶段,如程序清单2所示,其中包括定义模型的损失函数、计算损失函数的梯度,以及计算迭代更新参数估计值。这些步骤相对固定,几乎适用于所有模型。或许第13行中的“将上一次的梯度清零”操作可能会引发一些读者的困惑。实际上,这行代码与反向传播算法的工作机制息息相关,后续的文章[TODO]将对其进行详细的解释和讨论。
1 | # 定义模型
2 | model = Linear()
3 | # 确定最优化算法
4 | learning_rate = 0.1
5 | optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
6 |
7 | for t in range(20):
8 | # 根据当前的参数估计值,得到模型的预测结果
9 | # 也就是调用forward函数
10 | y_pred = model(x)
11 | # 计算损失函数
12 | loss = (y - y_pred).pow(2).mean()
13 | # 将上一次的梯度清零
14 | optimizer.zero_grad()
15 | # 触发反向传播算法,计算损失函数的梯度
16 | loss.backward()
17 | # 迭代更新模型参数的估计值
18 | optimizer.step()
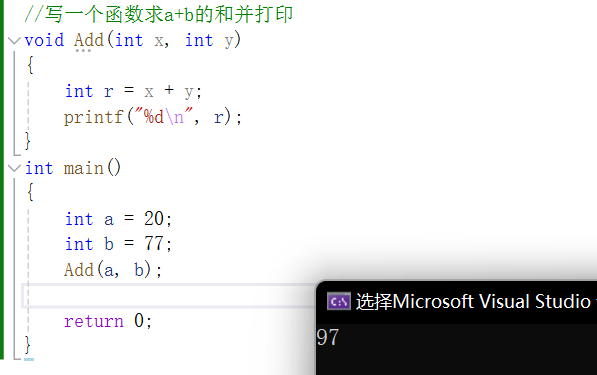
本章运用PyTorch提供的高级封装函数来实现梯度下降法。尽管如此,整个算法的核心难点仍然被这些函数隐藏了,其中有两个关键函数起到了重要作用。首先是optimizer.step(),负责实现参数的迭代更新,其细节相对简单,可以轻松地实现,如图2所示;其次是负责反向传播算法的loss.backward()函数,其实现相当复杂,将在后续的文章[TODO]中详细讨论。

回顾一下泰勒一阶展开式,假设 f ( x 1 , x 2 , ⋯ , x n ) f(x_1,x_2,⋯,x_n) f(x1,x2,⋯,xn)是一个一阶可导的函数,即 ∂ 2 f ∂ x i ∂ x j \frac{∂^2 f}{∂x_i ∂x_j } ∂xi∂xj∂2f都存在,则 f ( x 1 , x 2 , ⋯ , x n ) = f ( a 1 , a 2 , ⋯ , a n ) + ∑ i = 1 n ∂ f ( a 1 , a 2 ⋯ , a n ) ∂ x i ( x i − a i ) + o ( ∑ i ∣ x i − a i ∣ ) f(x_1,x_2,⋯,x_n)=f(a_1,a_2,⋯,a_n)+\sum_{i = 1}^n\frac{∂f(a_1,a_2⋯,a_n)}{∂x_i}(x_i-a_i) +o(\sum_i|x_i-a_i |) f(x1,x2,⋯,xn)=f(a1,a2,⋯,an)+∑i=1n∂xi∂f(a1,a2⋯,an)(xi−ai)+o(∑i∣xi−ai∣)其中, o ( ∑ i ∣ x i − a i ∣ ) o(\sum_i|x_i-a_i |) o(∑i∣xi−ai∣)表示相对于 ∑ i ∣ x i − a i ∣ \sum_i|x_i-a_i | ∑i∣xi−ai∣的极小值。因此在x很靠近a时,有 f ( x ) ≈ f ( a ) + ∑ i ∂ f ( a ) ∂ x i ( x i − a i ) f(x) ≈ f(a) + \sum_i\frac{∂f(a)}{∂x_i}(x_i - a_i) f(x)≈f(a)+∑i∂xi∂f(a)(xi−ai)。但是当x离a较远时,上述近似关系的误差就很大了。 ↩︎
如果考虑多阶导数,可以得到其他的最优化问题求解算法,比如使用二阶导数的共轭梯度法(Conjugate Gradient Method)等。这些算法对于特定问题可以更快地得到收敛解,但它们对损失函数的要求更多,计算复杂度也更高,并不适合神经网络和分布式机器学习,所以这里不做深入探讨。 ↩︎
这一概念在实际应用中非常重要,因为在优化算法中,需要计算或者估计损失函数关于某个参数的偏导数,以指导这个参数的更新。然而,若要准确地计算梯度,就需要对多元函数的每个偏导数进行计算,这让准确的数学表述变得非常烦琐。因此,通过使用“变量的梯度”这一术语,能够使表达更简洁,并在实际操作中更加便利地进行参数更新和优化。 ↩︎
在PyTorch中,算法的正式名字是自动微分(Autograd或Automatic Differentiation)算法。这两者指的其实是同一个算法。 ↩︎
或许有些读者会对“为什么将模型的预测函数称为forward”感到好奇。这是因为在神经网络领域,常常将计算模型的预测结果并评估损失的步骤称为向前传播,而将更新模型参数的步骤称为向后传播。这种命名习惯在PyTorch这个主要应用于神经网络的开源工具中得到了延续。 ↩︎