摘要
本研究介绍了AnyDoor,这是一款基于扩散模型的图像生成器,能够在用户指定的位置,以期望的形状将目标对象传送到新场景中。与为每个对象调整参数不同,我们的模型仅需训练一次,就能在推理阶段轻松地泛化到多样化的对象-场景组合。这种具有挑战性的零样本设置需要对特定对象进行充分的表征。为此,我们补充了常用的身份特征与细节特征,这些细节特征经过精心设计,既能保持外观细节,又允许多样化的局部变化(例如,照明、方向、姿势等),支持对象与不同环境的融合。我们进一步提出从视频数据集中借用知识,在那里我们可以观察到单一对象的多种形式(即沿时间轴),从而增强模型的泛化能力和鲁棒性。广泛的实验表明,我们的方法在虚拟试穿、形状编辑和对象交换等现实世界应用方面,相较于现有替代方案具有优越性,并展现出巨大的潜力。代码已在github.com/ali-vilab/AnyDoor上发布。
1. 引言
随着扩散模型的飞速发展[22, 37, 40, 41, 43, 62],图像生成正迅速发展。人类可以通过提供文本提示、涂鸦、骨架图或其他条件来生成喜欢的图像。这些模型的强大功能也为图像编辑带来了潜力。例如,一些工作[5, 24, 63]通过指令学习编辑图像的姿势、风格或内容。其他工作[53, 59]探索了在文本提示的指导下重新生成局部图像区域。在本文中,我们研究了“对象传送”,这意味着将目标对象准确且无缝地放置到场景图像的所需位置。具体来说,我们通过将目标对象作为模板,重新生成场景图像中标记有盒子/掩模的局部区域。这种能力在实际应用中是一个重要的需求,如图像合成、效果图像渲染、海报制作、虚拟试穿等。尽管迫切需要,但以前的研究者并没有很好地探索这个话题。Paint-by-Example[56]和ObjectStitch[47]以目标图像作为模板来编辑场景图像的特定区域,但它们无法生成一致的ID(身份)内容,特别是对于未经训练的类别。定制合成方法[18, 27, 33, 34, 42]能够为新概念进行生成,但不能指定给定场景的特定位置。此外,大多数定制方法需要在多个目标图像上进行微调,耗时近一个小时,这在很大程度上限制了它们在实际应用中的实用性。我们通过提出AnyDoor来解决这一挑战。与以前的方法不同,AnyDoor能够在零样本情况下生成高质量的ID一致的合成。为了实现这一点,我们用身份和细节相关特征来表示目标对象,然后将它们与背景场景的交互合成。具体来说,我们使用一个ID提取器来产生区分性的ID标记,并精心设计一个频率感知的细节提取器来获取作为补充的细节图。我们将ID标记和细节图注入到预训练的文本到图像扩散模型中,作为生成所需组合的指导。为了使生成的内容更具可定制性,我们探索利用额外的控制(例如用户绘制的掩模)来指示对象的形状/姿势。为了学习具有高多样性的定制对象生成,我们从视频中收集了同一对象的图像对,以学习外观变化,并利用大规模统计图像来保证场景的多样性。凭借这些技术,AnyDoor展示了零样本定制的非凡能力。如图1所示,AnyDoor在形状控制下的新概念合成方面表现出了有希望的性能(第一行)。此外,由于AnyDoor对编辑场景图像的特定局部区域具有高可控性,它很容易扩展到多主题组合(中行),这是许多定制生成方法探索的热门和具有挑战性的话题[3, 19, 27, 34]。而且,AnyDoor的高生成保真度和质量为更多奇妙的应用,如对象移动和交换(底部行)打开了可能性。我们希望AnyDoor能够作为各种图像生成和编辑任务的基础解决方案,并作为激发更多奇特应用的基本能力。
2. 相关工作
本地图像编辑
大部分先前的工作集中在使用文本指导编辑图像的局部区域。Blended Diffusion[2]在掩模区域进行多步混合以生成更和谐的输出。Inpaint Anything[59]涉及SAM[26]和Stable Diffusion[41],用文本描述的目标替换源图像中的任何对象。Paint-by-Example[56]使用CLIP[39]图像编码器将目标图像转换为引导的嵌入,因此在场景图像上绘制了语义一致的对象。ObjectStitch[47]提出了一个与[56]类似的解决方案,它训练一个内容适配器,将CLIP图像编码器的输出与文本编码器对齐,以指导扩散过程。然而,这些方法只能为生成提供粗略指导,通常无法为未经训练的新概念合成ID一致的结果。
定制图像生成
定制或称为主题驱动的生成旨在为特定对象生成图像,给定几个目标图像和相关文本提示。一些工作[9, 18, 42]微调一个“词汇表”来描述目标概念。Cones[33]找到所指对象的相应神经元。尽管它们可以生成高保真图像,但用户无法指定场景和目标对象的位置。此外,耗时的微调阻碍了它们在大规模应用中的使用。最近,BLIPDiffusion[28]利用BLIP-2[29]对齐图像和文本进行零样本定制。Fastcomposer[52]将图像表示与特定文本嵌入绑定,以进行多人生成。一些并行工作[30, 58, 61]也探索了使用一个参考图像来定制生成结果,但未能保持细节。
图像和谐化
经典的图像组合流程是切割前景对象并将其粘贴到给定的背景上。图像和谐化[7, 14, 20, 48]可以进一步调整粘贴区域,使其具有更合理的照明和颜色。DCCF[55]设计金字塔滤波器更好地和谐前景。CDTNet[15]利用双变换器。HDNet[8]提出了一个分层结构来考虑全局和局部一致性,并达到了最先进的水平。尽管如此,这些方法只探索了低级变化,编辑前景对象的结构、视图和姿势,或者生成阴影和反射并未被考虑。
3. 方法
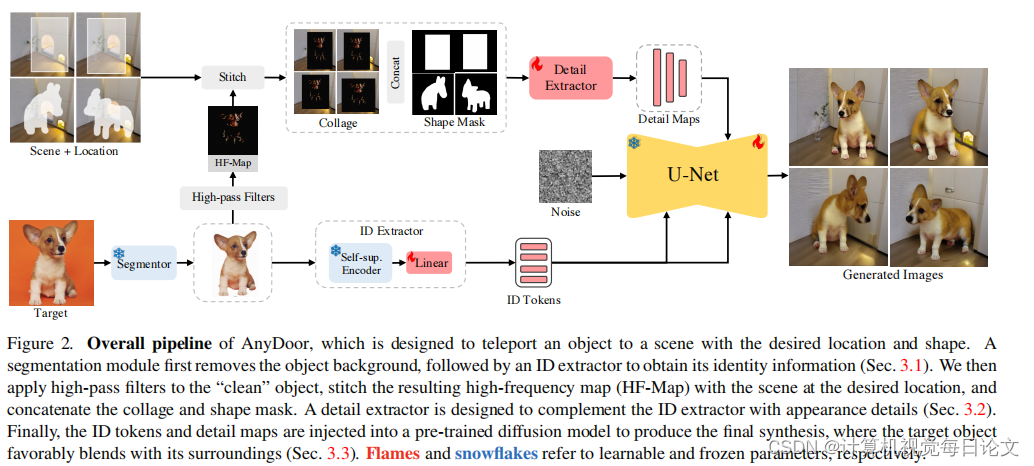
AnyDoor的流程如图2所示。给定目标对象、场景和位置,AnyDoor以高保真度和多样性生成对象-场景组合。核心思想是通过身份和细节相关特征来表示对象,并通过将这些特征注入预训练的扩散模型来重新组合它们。为了学习外观变化,我们利用包括视频和图像在内的大规模数据进行训练。
3.1. 身份特征提取
我们利用预训练的视觉编码器提取目标对象的身份信息。先前的工作[47, 56]选择CLIP[39]图像编码器来嵌入目标对象。然而,由于CLIP是使用粗略描述的文本-图像对进行训练的,它只能嵌入语义级信息,难以提供保留对象身份的区分性表示。为了克服这一挑战,我们进行了以下更新:
- 背景移除:在将目标图像输入ID提取器之前,我们使用分割器将背景移除,并将对象对齐到图像中心。分割器模型可以是自动的[26, 38]或交互式的[11, 12, 32]。这一操作已被证明在提取更整洁和区分性特征方面是有帮助的。
- 自我监督表示:在这项工作中,我们发现自我监督模型在保留更多区分性特征方面表现出强大的能力。在大规模数据集上预训练的自我监督模型自然具备实例检索能力,并且可以将对象投影到一个增强不变特征空间。我们选择当前最强大的自我监督模型DINOv2[36]作为我们ID提取器的骨干,它将图像编码为全局标记T1×1536g和补丁标记T256×1536p。我们连接这两种类型的标记以保留更多信息。我们发现使用单个线性层作为投影器可以将这些标记与预训练的文本到图像UNet的嵌入空间对齐。投影标记T257×1024 ID被记作我们的ID标记。
3.2. 细节特征提取
考虑到ID标记以低分辨率(16×16)表示,它们很难充分保持低级细节。因此,我们需要额外的指导来补充细节生成。拼贴表示:受到[6, 44]的启发,使用拼贴作为控制可以提供强大的先验,我们尝试将“背景移除的对象”缝合到场景图像的给定位置。有了这个拼贴,我们观察到生成保真度的显著提高,但生成的结果与给定目标过于相似,缺乏多样性。面对这个问题,我们探索设置一个信息瓶颈,以防止拼贴给出太多外观约束。具体来说,我们设计了一个高频地图来表示对象,它可以保持细节,同时允许多样化的局部变体,如手势、照明、方向等。高频地图:我们使用以下公式提取目标对象的高频地图:
𝐼ℎ=(𝐼𝑔𝑟𝑎𝑦⊗𝐾ℎ+𝐼𝑔𝑟𝑎𝑦⊗𝐾𝑣)⊙𝐼⊙𝑀𝑒𝑟𝑜𝑑𝑒Ih=(Igray⊗Kh+Igray⊗Kv)⊙I⊙Merode
其中 𝐾ℎ,𝐾𝑣Kh,Kv 表示水平和垂直的Sobel[23]核,作为高通滤波器。"⊗“和”⊙"分别指卷积和哈达玛德乘积。给定图像I,我们首先使用这些高通滤波器提取高频区域,然后使用哈达玛德乘积提取RGB颜色。我们还添加了一个侵蚀掩模Meroode,以过滤掉目标对象外轮廓附近的信息。如图3所示,DINOv2产生的标记更关注整体结构,难以编码背包上的标志等细节。相比之下,高频地图可以作为补充,帮助处理这些细节。形状控制:我们使用形状掩模来指示对象的姿态。为了模拟用户输入,我们对真实掩模进行不同比例的下采样,并应用随机膨胀/腐蚀来移除细节。为了保持处理单个框输入的能力,我们设置了一个0.3的概率使用内部框区域作为掩模。在训练期间,对象计数器将与形状掩模对齐。因此,用户可以通过在推理期间绘制粗略的形状掩模来控制目标对象的形状。在获得拼贴和轮廓图后,我们将它们连接起来并输入到细节提取器中。细节提取器是一个ControlNet风格的[62]UNet编码器,它产生一系列具有层次分辨率的细节图。
3.3. 特征注入
在获得ID标记和细节图后,我们将它们注入到预训练的文本到图像扩散模型中以指导生成。我们选择Stable Diffusion[41],它将图像投影到潜在空间,并使用UNet进行概率采样。我们注意到预训练的UNet为 𝑥^𝜃x^θ,它从初始潜在噪声 𝜖∼𝑈([0,1])ϵ∼U([0,1]) 开始去噪,并采用文本嵌入c作为条件生成新图像潜在z:
𝑧𝑡=𝛼𝑡𝑥^𝜃(𝛼𝑡𝑥+𝜎𝑡𝜖,𝑐)+𝜎𝑡𝜖zt=αtx^θ(αtx+σtϵ,c)+σtϵ
训练监督是一个均方误差损失:
𝐸𝑥,𝑐,𝜖,𝑡(∥𝑥^𝜃(𝛼𝑡𝑥+𝜎𝑡𝜖,𝑐)−𝑥∥22)Ex,c,ϵ,t(∥x^θ(αtx+σtϵ,c)−x∥22)
...
3.4. 训练策略
图像对收集:理想的训练样本是“同一对象在不同场景中的图像对”,现有的数据集并不直接提供。作为替代,先前的工作[47, 56]利用单个图像并应用旋转、翻转和弹性变换等增强。然而,这些简单的增强不能很好地代表姿势和视图的实际变化。为了解决这个问题,在这项工作中,我们利用视频数据集来捕捉包含同一对象的不同帧。数据准备流程如图4所示,我们利用视频分割/跟踪数据作为示例。对于一个视频,我们选择两帧并获取每个帧中实例的掩模。然后,我们删除一个图像的背景,并围绕掩模裁剪它作为目标对象。这个掩模可以用作扰动后掩模控制。对于另一个帧,我们生成框并删除框区域以获取场景图像,未掩模的图像可以作为训练真实情况。使用的完整数据列在表1中,涵盖了自然场景、虚拟试穿、显著性、多视图对象等多种领域。
自适应时间步采样:尽管视频数据对学习外观变化有益,但由于分辨率低或运动模糊,帧质量通常不满意。相比之下,图像可以提供高质量的细节和多样化的场景,但缺乏外观变化。为了利用视频数据和图像数据的优势,我们开发了自适应时间步采样,使不同模态的数据在去噪训练的不同阶段受益。原始扩散模型[41]对每个训练数据均匀采样时间步(T)。然而,观察到最初的去噪步骤主要集中于生成整体结构、姿势和视图,后续步骤涵盖细节如纹理和颜色。因此,对于视频数据,我们在训练期间增加了50%的可能性采样早期去噪步骤(500-1000),以更好地学习外观变化。对于图像,我们增加了50%的可能性采样后期步骤(0-500),以学习如何覆盖细节。

4. 实验
4.1 实施细节 超参数。我们选择Stable Diffusion V2.1 [41] 作为基础生成器。在训练期间,我们将图像分辨率处理为512×512。我们选择Adam [25] 优化器,初始学习率为1e−5。我们训练了两个版本的模型,原始版本仅使用框来指示位置,而加强版本使用形状掩模。在本文中,除非特别指明使用形状掩模,否则结果由原始版本生成。放大策略。在推理期间,给定场景图像和位置框,我们将框扩展为放大比率为2.0的正方形。然后,我们裁剪正方形并将其调整大小为512×512,作为我们的扩散模型的输入。因此,我们可以处理具有任意纵横比和极小或极大区域框的场景图像。基准。为了定量结果,我们使用DreamBooth [42] 提供的30个新概念构建了一个新的基准,用于目标图像。对于场景图像,我们手动从COCO-Val [31] 中选择了80张带有框的图像。因此,我们为对象-场景组合生成了2,400个图像。我们还在VitonHDtest [13] 上进行了定性分析,以验证虚拟试穿的性能。评估指标。在我们构建的DreamBooth数据集上,我们遵循DreamBooth [42] 计算CLIPScore和DINO-Score,因为这些指标可以反映生成区域与目标对象之间的相似度。此外,我们组织了一个由15名注释者组成的用户研究,从保真度、质量和多样性的角度对生成结果进行评分。
4.2 与现有替代方案的比较 基于参考的方法。在图5中,我们展示了与以前的基于参考的方法相比的可视化结果。Paint-by-Example [56] 和 Graphit [16] 支持与我们相同的输入格式,它们将目标图像作为输入,无需参数调整即可编辑场景图像的局部区域。IP-Adapter [58] 是一种支持图像提示的通用方法,我们使用其修复模型进行比较。我们还比较了Stable Diffusion [41],这是一个文本到图像模型,我们使用其修复版本,并提供详细的文本描述作为条件,以进行文本描述的目标生成。结果表明,以前的基于参考的方法只能保持与背包上的狗脸等特征和树懒玩具颜色等图案的粗略一致性。然而,由于这些新概念没有包含在训练类别中,它们的生成结果与ID-consistent相差甚远。相比之下,我们的AnyDoor在零样本图像定制方面展现出了高度忠实的细节表现。
基于调整的方法。定制生成被广泛探索。以前的工作[10, 18, 33, 42, 45]通常微调特定主题的文本反转以呈现目标对象,从而使生成具有任意文本提示。与以前的基于参考的方法相比,它们可以更好地保持保真度,但存在以下缺点:首先,微调通常需要4-5个目标图像,并且需要近一个小时;其次,它们无法指定背景场景和目标位置;第三,当涉及到多主题组合时,不同主题的属性经常会混在一起。在图6中,我们包括了基于调整的方法进行比较,并同样使用Paint-by-Example [56] 作为以前的基于参考方法的代表。结果表明,Paint-by-Example [56] 对于像狗和猫这样的训练类别(第3行)表现良好,但对新概念(第1-2行)表现不佳。DreamBooth [42]、Custom Diffusion [27] 和 Cones [33] 对新概念提供了更好的保真度,但仍然遭受“多主题混淆”的问题。相比之下,AnyDoor 拥有基于参考和基于调整方法的优势,可以无需参数调整就能生成多主题组合的高保真结果。
用户研究。我们组织了一个用户研究,比较Paintby-Example [56]、Graphit [16] 和我们的模型。我们让15名注释者对30组图像进行评分。对于每组,我们提供一个目标图像和一个场景图像,并让这三种模型各自生成四个预测。我们准备了详细的规定和模板,从三个方面对图像进行评分:"Fidelity"(保真度)、"Quality"(质量)和"Diversity"(多样性)。"Fidelity" 衡量ID保持的能力,"Quality" 考虑生成图像是否和谐,不考虑保真度。由于我们不鼓励“复制粘贴”风格的生成,我们使用"Diversity" 来衡量四个生成提议之间的差异。用户研究结果列在表2中。它表明,我们的模型在保真度和质量方面拥有明显的优势,尤其是保真度。然而,由于[16, 56] 只保持了语义一致性,而我们的方法保留了实例身份。它们自然有更大的多样性空间。在这种情况下,AnyDoor 仍然比[16]获得了更高的评分,并且与[56] 有竞争性的结果,这验证了我们方法的有效性。




5. 结论
我们提出了AnyDoor用于对象传送。核心思想是使用区分性的ID提取器和频率感知的细节提取器来表征目标对象。在大量视频和图像数据的组合上训练,我们能够在场景图像的特定位置合成对象,并有效控制形状。AnyDoor为一般区域到区域映射任务提供了一种通用解决方案,并可能对各种应用产生益处。
局限性
尽管AnyDoor在保持对象识别方面展示了令人印象深刻的结果,但它在处理小字符或标志等细节方面仍然存在挑战。这个问题可能通过收集相关的训练数据、扩大分辨率和训练更好的VAE解码器来解决。