python:__set_name__使用
1 前言
在Python中,我们可以通过__set_name__方法来实现一些特殊的操作。该方法是在定义类的时候被调用,用于设置属性的名称。这样一来,我们就可以在类定义中动态地获取属性的名称,从而更好地完成一些操作。
参考functools中的cached_property类中的__set_name__方法使用,探讨python中__set_name__的使用场景,cached_property源码如下(本文基于python 3.9):
class cached_property:
def __init__(self, func):
self.func = func
self.attrname = None
self.__doc__ = func.__doc__
self.lock = RLock()
def __set_name__(self, owner, name):
if self.attrname is None:
self.attrname = name
elif name != self.attrname:
raise TypeError(
"Cannot assign the same cached_property to two different names "
f"({self.attrname!r} and {name!r})."
)
def __get__(self, instance, owner=None):
if instance is None:
return self
if self.attrname is None:
raise TypeError(
"Cannot use cached_property instance without calling __set_name__ on it.")
try:
cache = instance.__dict__
except AttributeError: # not all objects have __dict__ (e.g. class defines slots)
msg = (
f"No '__dict__' attribute on {type(instance).__name__!r} "
f"instance to cache {self.attrname!r} property."
)
raise TypeError(msg) from None
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
with self.lock:
# check if another thread filled cache while we awaited lock
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
val = self.func(instance)
try:
cache[self.attrname] = val
except TypeError:
msg = (
f"The '__dict__' attribute on {type(instance).__name__!r} instance "
f"does not support item assignment for caching {self.attrname!r} property."
)
raise TypeError(msg) from None
return val
__class_getitem__ = classmethod(GenericAlias)
2 使用
2.1 初识描述器和__set_name__方法的简单使用
参考官方文档:
https://docs.python.org/zh-cn/3.9/reference/datamodel.html#slots
在实现描述器中提到:
以下方法仅当一个包含该方法的类(称为 描述器 类)的实例出现于一个 所有者 类中的时候才会起作用(该描述器必须在所有者类或其某个上级类的字典中)。在以下示例中,“属性”指的是名称为所有者类 __dict__ 中的特征属性的键名的属性。
意即:具有以下任一方法(__get__、__set__、__delete__、__set_name__)的类被称为描述器类,而该描述器类的实例对象(类名(*args, **kwargs)为实例对象),必须存在于所有类中,描述器类定义的这些方法,才会生效执行。也就是比如如下所示:
class MyClass:
def __new__(cls, *args, **kwargs):
print("__new__")
return super(cls, MyClass).__new__(cls)
def __init__(self):
print("__init__")
self._name = None
def set_name(self, value):
print("set_name", value)
self._name = value
def __set_name__(self, owner, name):
print("__set_name__", owner, name)
self._name = name
def __get__(self, instance, owner):
print("__get__ MyClass", instance, owner)
def __set__(self, instance, value):
print("__set__ MyClass", instance, value)
def __delete__(self, instance):
print("__delete__ MyClass", instance)
class Person:
special = MyClass()
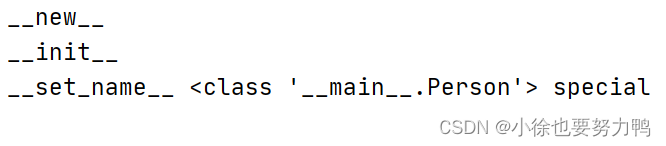
上述的MyClass类定义了__set_name__方法,也就是一个描述器类,而Person的special属性为MyClass描述器类的实例,也就是说MyClass描述器类的实例对象,存在于Person所有类中,那么就会在定义Person类时,会自动调用MyClass描述器类的__set_name__方法,上述代码执行结果如下:
__new__
__init__
__set_name__ <class '__main__.Person'> special
可见,__set_name__方法中传入的owner是描述器类实例的所有类Person,而name是所有类Person中,承接这个描述器类实例的属性名称,为special:
描述器类的方法如下:
- object.__get__(self, instance, owner=None)
调用此方法以获取所有者类的属性(类属性访问)或该类的实例的属性(实例属性访问)。 可选的 owner 参数是所有者类而 instance 是被用来访问属性的实例,如果通过 owner 来访问属性则返回 None。
此方法应当返回计算得到的属性值或是引发 AttributeError 异常。
PEP 252 指明 __get__() 为带有一至二个参数的可调用对象。 Python 自身内置的描述器支持此规格定义;但是,某些第三方工具可能要求必须带两个参数。 Python 自身的 __getattribute__() 实现总是会传入两个参数,无论它们是否被要求提供。
- object.__set__(self, instance, value)
调用此方法以设置 instance 指定的所有者类的实例的属性为新值 value。
请注意,添加 __set__() 或 __delete__() 会将描述器变成“数据描述器”。
- object.__delete__(self, instance)
调用此方法以删除 instance 指定的所有者类的实例的属性。
- object.__set_name__(self, owner, name)
在所有者类 owner 创建时被调用。描述器会被赋值给 name。
注意: __set_name__() 只是作为 type 构造器的一部分被隐式地调用,因此在某个类被初次创建之后又额外添加一个描述器时,那就需要显式地调用它并且附带适当的形参:
针对此举个栗子:
class MyClass:
def __new__(cls, *args, **kwargs):
print("__new__")
return super(cls, MyClass).__new__(cls)
def __init__(self):
print("__init__")
self._name = None
def set_name(self, value):
print("set_name", value)
self._name = value
def __set_name__(self, owner, name):
print("__set_name__", owner, name)
self._name = name
def __get__(self, instance, owner):
print("__get__ MyClass", instance, owner)
def __set__(self, instance, value):
print("__set__ MyClass", instance, value)
def __delete__(self, instance):
print("__delete__ MyClass", instance)
class Person:
pass
Person.desc = MyClass()
上述代码执行结果如下:
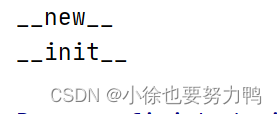
上述的栗子可知,我们并没有在Person类中定义MyClass描述器类实例的属性,而是在定义了Person类之后,为其添加属性desc,值为MyClass描述器类实例,可见并没有自动执行MyClass的__set_name__方法,即如上述所说,此时我们需要显式地调用MyClass的__set_name__方法并且附带适当的形参,修改如下:
m = MyClass()
Person.desc = m
m.__set_name__(Person, "desc")
结果如下:

上述我们调用__set_name__方法时,第一个参数是所有类,即Person;而第二个参数是描述器实例属性的对应名称,即’desc’。可见此时执行的结果,就和我们在定义所有类时就为其属性赋值为描述器类实例的效果一致了。
2.2 创建类对象官方文档说明
创建类对象参考文档:
https://docs.python.org/zh-cn/3.9/reference/datamodel.html#class-object-creation
创建类对象中提到如下:
一旦执行类主体完成填充类命名空间,将通过调用 metaclass(name, bases, namespace, **kwds) 创建类对象(此处的附加关键字参数与传入 __prepare__ 的相同)。
如果类主体中有任何方法引用了 __class__ 或 super,这个类对象会通过零参数形式的 super(). __class__ 所引用,这是由编译器所创建的隐式闭包引用。这使用零参数形式的 super() 能够正确标识正在基于词法作用域来定义的类,而被用于进行当前调用的类或实例则是基于传递给方法的第一个参数来标识的。
CPython implementation detail: 在 CPython 3.6 及之后的版本中,__class__ 单元会作为类命名空间中的 __classcell__ 条目被传给元类。 如果存在,它必须被向上传播给 type.__new__ 调用,以便能正确地初始化该类。 如果不这样做,在 Python 3.8 中将引发 RuntimeError。
当使用默认的元类 type 或者任何最终会调用 type.__new__ 的元类时,以下额外的自定义步骤将在创建类对象之后被发起调用:
- 首先,type.__new__ 将收集类命名空间中所有定义了 __set_name__() 方法的描述器;
- 接下来,所有这些 __set_name__ 方法将使用所定义的类和特定描述器所赋的名称进行调用;
- 最后,将在新类根据方法解析顺序所确定的直接父类上调用 __init_subclass__() 钩子。
在类对象创建之后,它会被传给包含在类定义中的类装饰器(如果有的话),得到的对象将作为已定义的类绑定到局部命名空间。
当通过 type.__new__ 创建一个新类时,提供以作为命名空间形参的对象会被复制到一个新的有序映射并丢弃原对象。这个新副本包装于一个只读代理中,后者则成为类对象的 __dict__ 属性。
因上述提到了type,这里我们简单分析下type类的使用:
参考官方文档type:
https://docs.python.org/zh-cn/3.9/library/functions.html#type
class type(name, bases, dict, **kwds)
传入一个参数时,返回 object 的类型。 返回值是一个 type 对象,通常与 object.__class__ 所返回的对象相同。
推荐使用 isinstance() 内置函数来检测对象的类型,因为它会考虑子类的情况。
传入三个参数时,返回一个新的 type 对象。 这在本质上是 class 语句的一种动态形式,name 字符串即类名并会成为 __name__ 属性;bases 元组包含基类并会成为 __bases__ 属性;如果为空则会添加所有类的终极基类 object。 dict 字典包含类主体的属性和方法定义;它在成为 __dict__ 属性之前可能会被拷贝或包装。
举个简单栗子,下面两条语句会创建相同的 type 对象:
class Xiaoxu:
age = 0
x = type('Xiaoxu', (), dict(age=0))
print(type(x))
print(x.__name__)
print(x.__bases__)
print(x.__dict__)
print("*" * 10)
print(isinstance(x, Xiaoxu))
# False
print(type(Xiaoxu))
print(Xiaoxu.__name__)
print(Xiaoxu.__bases__)
print(Xiaoxu.__dict__)
print("*" * 10)
print(Xiaoxu.__name__ == x.__name__)
print(Xiaoxu.__bases__ == x.__bases__)
print(Xiaoxu.__dict__ == x.__dict__)
# True
# True
# False
执行结果如下:
<class 'type'>
Xiaoxu
(<class 'object'>,)
{'age': 0, '__module__': '__main__', '__dict__': <attribute '__dict__' of 'Xiaoxu' objects>, '__weakref__': <attribute '__weakref__' of 'Xiaoxu' objects>, '__doc__': None}
**********
False
<class 'type'>
Xiaoxu
(<class 'object'>,)
{'__module__': '__main__', 'age': 0, '__dict__': <attribute '__dict__' of 'Xiaoxu' objects>, '__weakref__': <attribute '__weakref__' of 'Xiaoxu' objects>, '__doc__': None}
**********
True
True
False
提供给三参数形式的关键字参数会被传递给适当的元类机制 (通常为 __init_subclass__()),相当于类定义中关键字 (除了 metaclass) 的行为方式。
在 3.6 版更改: type 的子类如果未重载 type.__new__,将不再能使用一个参数的形式来获取对象的类型。
针对上述的说明,举个栗子,在所有类Owner中创建多个不同的描述器类实例对象属性:
class Ma:
def __new__(cls, *args, **kwargs):
print("__new__ Ma")
return super(cls, Ma).__new__(cls)
def __init__(self):
self._name = None
print("__init__ Ma", self._name)
def __set_name__(self, owner, name):
print("__set_name__ Ma", owner, name)
self._name = name
class Mb:
def __new__(cls, *args, **kwargs):
print("__new__ Mb")
return super(cls, Mb).__new__(cls)
def __init__(self):
self._age = None
print("__init__ Mb", self._age)
def __set_name__(self, owner, name):
print("__set_name__ Mb", owner, name)
self._age = name
class Owner:
a = Ma()
b = Mb()
执行结果如下:

根据上述可知,使用默认的元类 type,也可以自动触发收集类命名空间中所有定义了__set_name__() 方法的描述器,并分别执行其__set_name__() 方法的操作,演示如下:
class Ma:
def __new__(cls, *args, **kwargs):
print("__new__ Ma")
return super(cls, Ma).__new__(cls)
def __init__(self):
self._name = None
print("__init__ Ma", self._name)
def __set_name__(self, owner, name):
print("__set_name__ Ma", owner, name)
self._name = name
class Mb:
def __new__(cls, *args, **kwargs):
print("__new__ Mb")
return super(cls, Mb).__new__(cls)
def __init__(self):
self._age = None
print("__init__ Mb", self._age)
def __set_name__(self, owner, name):
print("__set_name__ Mb", owner, name)
self._age = name
# class Owner:
# a = Ma()
# b = Mb()
# type,参数分别为:类名,继承基类元组,类的属性
Owner = type("Owner", (), dict({"a": Ma(), "b": Mb()}))
执行结果和上述一致:

但是注意,上述方式改为如下:
Owner = type("Owner", (), dict({"a": Ma()}))
Owner.b = Mb()
执行结果如下:

可见这种方式也不会自动执行描述器Mb。
修改Owner如下:
class Owner:
a = Ma()
b = Mb()
def __new__(cls, *args, **kwargs):
print("__new__ Owner")
return super(cls, Owner).__new__(cls)
def __init__(self):
print("__init__ Owner")
print(self.a._name)
print(self.b._age)
c = Owner()
结果如下:

其实,实际使用中,描述器类自定义__set_name__方法,更常见于装饰器的使用,如下变式可见:
class Ma:
def __new__(cls, *args, **kwargs):
print("__new__ Ma")
return super(cls, Ma).__new__(cls)
def __init__(self, func):
self._name = None
self.func = func
print("__init__ Ma", self._name)
def __set_name__(self, owner, name):
print("__set_name__ Ma", owner, name)
self._name = name
class Mb:
def __new__(cls, *args, **kwargs):
print("__new__ Mb")
return super(cls, Mb).__new__(cls)
def __init__(self, func):
self._age = None
self.func = func
print("__init__ Mb", self._age)
def __set_name__(self, owner, name):
print("__set_name__ Mb", owner, name)
self._age = name
class Owner:
@Ma
def a(self):
pass
@Mb
def b(self):
pass
执行结果:

据结果可知,和我们上述在所有类中定义描述器类实例属性的效果是一致的。上述变式的重点是,修改描述器的__init__方法,增加func参数,然后在所有类Owner中,描述器作为装饰器修改所有类Owner的方法a或者b,装饰器的形式如下:
@wrap
def run():
pass
形如:
run = wrap(run)
所以在Owner类中,使用描述器类修饰方法,依然符合前面提到的,描述器类的实例必须存于所有类的属性中,于是就会自动调用描述器类的__set_name__方法。
2.3 __set_name__的详细使用
有了前面的概念分析,然后我们开始参考官方文档,描述器使用指南,进行下述的__set_name__使用分析:
https://docs.python.org/zh-cn/3.9/howto/descriptor.html#member-objects-and-slots
2.3.1 定制名称
当一个类使用描述器时,它可以告知每个描述器使用了什么变量名。
在此示例中, People类具有两个描述器实例 name 和 age。当类People被定义的时候,他回调了 LoggedAccess 中的 __set_name__() 来记录字段名称,让每个描述器拥有自己的 public_name 和 private_name:
import logging
logging.basicConfig(level=logging.INFO)
class LoggedAccess:
def __set_name__(self, owner, name):
self.public_name = name
self.private_name = '_' + name
def __get__(self, instance, owner):
value = getattr(instance, self.private_name)
logging.info('Xiaoxu Accessing %r giving %r', self.public_name, value)
return value
def __set__(self, instance, value):
logging.info('Xiaoxu Access Updating %r to %r', self.public_name, value)
setattr(instance, self.private_name, value)
class People:
# First descriptor instance
name = LoggedAccess()
# Second descriptor instance
age = LoggedAccess()
def __init__(self, name, age):
self.name = name # Calls the first descriptor
self.age = age # Calls the second descriptor
def birthday(self):
self.age += 1
x = People("xiaoxu", 99)
# INFO:root:Xiaoxu Access Updating 'name' to 'xiaoxu'
# INFO:root:Xiaoxu Access Updating 'age' to 99
print(x.name)
# INFO:root:Xiaoxu Accessing 'name' giving 'xiaoxu'
# xiaoxu
print(x.age)
# INFO:root:Xiaoxu Accessing 'age' giving 99
# 99
l = People("xiaoli", 18)
# INFO:root:Xiaoxu Access Updating 'name' to 'xiaoli'
# INFO:root:Xiaoxu Access Updating 'age' to 18
执行结果如下:

同时,这两个People实例仅包含私有名称:
print(vars(x))
print(vars(l))
结果如下:

我们调用 vars() 来查找描述器而不触发它:
print(vars(vars(People)['name']))
print(vars(vars(People)['age']))
结果:
{'public_name': 'name', 'private_name': '_name'}
{'public_name': 'age', 'private_name': '_age'}

此处小结:
descriptor 就是任何一个定义了 __get__(),__set__() 或 __delete__() 的对象。
可选地,描述器可以具有 __set_name__() 方法。这仅在描述器需要知道创建它的类或分配给它的类变量名称时使用。(即使该类不是描述器,只要此方法存在就会调用。)
在属性查找期间,描述器由点运算符调用。如果使用 vars(some_class)[descriptor_name] 间接访问描述器,则返回描述器实例而不调用它。
描述器仅在用作类变量时起作用。放入实例时,它们将失效。
描述器的主要目的是提供一个挂钩,允许存储在类变量中的对象控制在属性查找期间发生的情况。
传统上,调用类控制查找过程中发生的事情。描述器反转了这种关系,并允许正在被查询的数据对此进行干涉。
描述器的使用贯穿了整个语言。就是它让函数变成绑定方法。常见工具诸如 classmethod(), staticmethod(),property() 和 functools.cached_property() 都作为描述器实现。
2.3.2 验证器类
验证器是一个用于托管属性访问的描述器。在存储任何数据之前,它会验证新值是否满足各种类型和范围限制。如果不满足这些限制,它将引发异常,从源头上防止数据损坏。
这个 Validator 类既是一个 abstract base class (抽象基类)也是一个托管属性描述器。
from abc import ABC, abstractmethod
# XValidator继承了ABC抽象基类,作为一个抽象类使用
# 类似java中通过abstract定义的抽象类
class XValidator(ABC):
def __set_name__(self, owner, name):
self.private_name = "_" + name
self.original_name = name
def __get__(self, instance, owner):
return getattr(instance, self.private_name)
def __set__(self, instance, value):
self.validate(self.original_name, value)
setattr(instance, self.private_name, value)
@abstractmethod
def validate(self, original_name, value):
pass
自定义验证器需要从 Validator 继承,并且必须提供 validate() 方法以根据需要测试各种约束。
自定义验证器
这是三个实用的数据验证工具:
- OneOf 验证值是一组受约束的选项之一。
- Number 验证值是否为 int 或 float。根据可选参数,它还可以验证值在给定的最小值或最大值之间。
- String 验证值是否为 str。根据可选参数,它可以验证给定的最小或最大长度。它还可以验证用户定义的 predicate。
class OneOf(XValidator):
def __init__(self, *options):
# 将tuple元组形式的options转换为set
self.options = set(options)
def validate(self, original_name, value):
# {val!s}形如test; {val!r}形如'test'
# !s相当于str(val); !r相当于repr(val)
if value not in self.options:
raise ValueError(f'Error field {original_name} set.'
f'Expected {value!r} to be one of {self.options!r}')
class Number(XValidator):
def __init__(self, minvalue=None, maxvalue=None):
self.minvalue = minvalue
self.maxvalue = maxvalue
def validate(self, original_name, value):
if not isinstance(value, (int, float)):
raise TypeError(f'Expected {value!r} to be an int or float')
if self.minvalue is not None and value < self.minvalue:
raise ValueError(
f'Expected {value!r} to be at least {self.minvalue!r}'
)
if self.maxvalue is not None and value > self.maxvalue:
raise ValueError(
f'Expected {value!r} to be no more than {self.maxvalue!r}'
)
class String(XValidator):
def __init__(self, minsize=None, maxsize=None, predicate=None):
self.minsize = minsize
self.maxsize = maxsize
self.predicate = predicate
def validate(self, original_name, value):
if not isinstance(value, str):
raise TypeError(f'Expected {value!r} to be an str of {original_name!r}')
if self.minsize is not None and len(value) < self.minsize:
raise ValueError(
f'Expected {value!r} to be no smaller than {self.minsize!r}'
f' of {original_name!r}'
)
if self.maxsize is not None and len(value) > self.maxsize:
raise ValueError(
f'Expected {value!r} to be no bigger than {self.maxsize!r}'
f' of {original_name!r}'
)
if self.predicate is not None and not self.predicate(value):
raise ValueError(
f'Expected {self.predicate} to be true for {value!r} '
f'of {original_name!r}'
)
在真实类中使用数据验证器的方法:
class Component:
name = String(minsize=3, maxsize=10, predicate=str.isupper)
kind = OneOf('man', 'woman')
quantity = Number(minvalue=0)
def __init__(self, name, kind, quantity):
self.name = name
self.kind = kind
self.quantity = quantity
# XIAOXU将不会报错 ctrl + shift + U
c = Component('xiaoxu', 'man', 5)
执行结果如下:

其余使用场景的演示:
Component('XIAOXU', 'test', 5)
校验结果:

又比如:
Component('XIAOXU', 'man', -5)
校验结果:

Component('XIAOXU', 'man', "yes")
校验结果:

正确使用场景,将不会抛出异常:
Component('XIAOXU', 'man', 99)
这里再举一个验证器的栗子:
from typing import Callable, Any
class Validation:
def __init__(
self, validation_function: Callable[[Any], bool], error_msg: str
) -> None:
print("Validation初始化被执行")
self.validation_function = validation_function # 传进来的是匿名函数
self.error_msg = error_msg
def __call__(self, value):
print("call被执行")
if not self.validation_function(value): # lambda x: isinstance(x, (int, float))
raise ValueError(f"{value!r} {self.error_msg}")
class Field: # 描述符类
def __init__(self, *validations): # 用*接收,表示可以传多个,目前代码可以理解为传进来的就是一个个Validation的实例
print("Field初始化被执行")
self._name = None
self.validations = validations # 接收完后的类型是元组
def __set_name__(self, owner, name):
print("set_name被执行")
self._name = name # 会自动将托管类ClientClass的类属性descriptor带过来
def __get__(self, instance, owner):
print("get被执行")
if instance is None:
return self
return instance.__dict__[self._name]
def validate(self, value):
print("验证被执行")
for validation in self.validations:
validation(value) # 这是是将对象当成函数执行时,调用Validation的__call__魔法方法
def __set__(self, instance, value):
"""
:param self: 指的是Field对象
:param instance: ClientClass对象
:param value: 给属性赋值的值
:return:
"""
print("set被执行")
self.validate(value)
instance.__dict__[self._name] = value
# 给ClientClass对象赋值 {"descriptor": 42}
class ClientClass: # 托管类
descriptor = Field(
Validation(lambda x: isinstance(x, (int, float, complex)), "is not a number"),
# Validation(lambda x: x >= 0, "is not >= 0"),
)
if __name__ == '__main__':
"""
Validation初始化被执行
Field初始化被执行
set_name被执行 # 当Field()赋值给descriptor变量时,执行__set_name__
---------------------
set被执行
验证被执行
call被执行
"""
client = ClientClass() # 实例化对象
print("---------------------")
# 给上面实例化的对象中的属性(Field实例化对象)赋值为42
client.descriptor = 42
结果如下:

若改为如下:
client.descriptor = "xiaoxu"
执行验证,结果将抛出异常:

基于如上,下面再说明一下描述器的概念:
定义与介绍:
一般而言,描述器是一个包含了描述器协议中的方法的属性值。 这些方法有 __get__(), __set__() 和 __delete__()。 如果为某个属性定义了这些方法中的任意一个,它就可以被称为 descriptor。
属性访问的默认行为是从一个对象的字典中获取、设置或删除属性。对于实例来说,a.x 的查找顺序会从 a.__dict__[‘x’] 开始,然后是 type(a).__dict__[‘x’],接下来依次查找 type(a) 的方法解析顺序(MRO)。 如果找到的值是定义了某个描述器方法的对象,则 Python 可能会重写默认行为并转而发起调用描述器方法。这具体发生在优先级链的哪个环节则要根据所定义的描述器方法及其被调用的方式来决定。
描述器是一个强大而通用的协议。 它们是属性、方法、静态方法、类方法和 super() 背后的实现机制。 它们在 Python 内部被广泛使用。 描述器简化了底层的 C 代码并为 Python 的日常程序提供了一组灵活的新工具。
描述器协议
descr.__get__(self, obj, type=None) -> value
descr.__set__(self, obj, value) -> None
descr.__delete__(self, obj) -> None
描述器的方法就这些。一个对象只要定义了以上方法中的任何一个,就被视为描述器,并在被作为属性时覆盖其默认行为。
如果一个对象定义了 __set__() 或 __delete__(),则它会被视为数据描述器。 仅定义了 __get__() 的描述器称为非数据描述器(它们经常被用于方法,但也可以有其他用途)。
数据和非数据描述器的不同之处在于,如何计算实例字典中条目的替代值。如果实例的字典具有与数据描述器同名的条目,则数据描述器优先。如果实例的字典具有与非数据描述器同名的条目,则该字典条目优先。
为了使数据描述器成为只读的,应该同时定义 __get__() 和 __set__() ,并在 __set__() 中引发 AttributeError 。用引发异常的占位符定义 __set__() 方法使其成为数据描述器。
描述器调用概述
描述器可以通过 d.__get__(obj) 或 desc.__get__(None, cls) 直接调用。
但更常见的是通过属性访问自动调用描述器。
表达式 obj.x 在命名空间的链中查找obj 的属性 x。如果搜索在实例 __dict__ 之外找到描述器,则根据下面列出的优先级规则调用其 __get__() 方法。
调用的细节取决于 obj 是对象、类还是超类的实例。
通过实例调用
实例查找通过命名空间链进行扫描,数据描述器的优先级最高,其次是实例变量、非数据描述器、类变量,最后是 __getattr__() (如果存在的话)。
如果 a.x 找到了一个描述器,那么将通过 desc.__get__(a, type(a)) 调用它。
点运算符的查找逻辑在 object.__getattribute__() 中。这里是一个等价的纯 Python 实现:
def object_getattribute(obj, name):
"Emulate PyObject_GenericGetAttr() in Objects/object.c"
null = object()
objtype = type(obj)
cls_var = getattr(objtype, name, null)
descr_get = getattr(type(cls_var), '__get__', null)
if descr_get is not null:
if (hasattr(type(cls_var), '__set__')
or hasattr(type(cls_var), '__delete__')):
return descr_get(cls_var, obj, objtype) # data descriptor
if hasattr(obj, '__dict__') and name in vars(obj):
return vars(obj)[name] # instance variable
if descr_get is not null:
return descr_get(cls_var, obj, objtype) # non-data descriptor
if cls_var is not null:
return cls_var # class variable
raise AttributeError(name)
请注意,在 __getattribute__() 方法的代码中没有调用 __getattr__() 的钩子。这就是直接调用 __getattribute__() 或调用 super().__getattribute__ 会彻底绕过 __getattr__() 的原因。
相反,当 __getattribute__() 引发 AttributeError 时,点运算符和 getattr() 函数负责调用 __getattr__()。它们的逻辑封装在一个辅助函数中:
def getattr_hook(obj, name):
"Emulate slot_tp_getattr_hook() in Objects/typeobject.c"
try:
return obj.__getattribute__(name)
except AttributeError:
if not hasattr(type(obj), '__getattr__'):
raise
return type(obj).__getattr__(obj, name) # __getattr__
通过类调用
像A.x这样的点操作符查找的逻辑在 type.__getattribute__() 中。步骤与 object.__getattribute__() 相似,但是实例字典查找改为搜索类的 method resolution order。
如果找到了一个描述器,那么将通过 desc.__get__(None, A) 调用它。
完整的 C 实现可在 Objects/typeobject.c 中的 type_getattro() 和 _PyType_Lookup() 找到。
通过 super 调用
super 的点操作符查找的逻辑在 super() 返回的对象的 __getattribute__() 方法中。
类似 super(A, obj).m 形式的点分查找将在 obj.__class__.__mro__ 中搜索紧接在 A 之后的基类 B,然后返回 B.__dict__[‘m’].__get__(obj, A)。如果 m 不是描述器,则直接返回其值。
完整的 C 实现可以在 Objects/typeobject.c 的 super_getattro() 中找到。纯 Python 等价实现可以在 Guido’s Tutorial 中找到。
调用逻辑总结
描述器的机制嵌入在 object,type 和 super() 的 __getattribute__() 方法中。
要记住的重要点是:
- 描述器由 __getattribute__() 方法调用。
- 类从 object,type 或 super() 继承此机制。
- 由于描述器的逻辑在 __getattribute__() 中,因而重写该方法会阻止描述器的自动调用。
- object.__getattribute__() 和 type.__getattribute__() 会用不同的方式调用__get__()。前一个会传入实例,也可以包括类。后一个传入的实例为 None ,并且总是包括类。
- 数据描述器始终会覆盖实例字典。
- 非数据描述器会被实例字典覆盖。
2.3.3 自动名称通知
有时,描述器想知道它分配到的具体类变量名。创建新类时,元类 type 将扫描新类的字典。如果有描述器,并且它们定义了 __set_name__(),则使用两个参数调用该方法。owner 是使用描述器的类,name 是分配给描述器的类变量名。
实现的细节在 Objects/typeobject.c 中的 type_new() 和 set_names() 。
由于更新逻辑在 type.__new__() 中,因此通知仅在创建类时发生。之后如果将描述器添加到类中,则需要手动调用 __set_name__() 。
2.3.4 ORM (对象关系映射)示例
以下代码展示了如何使用数据描述器来实现简单 object relational mapping 框架。
其核心思路是将数据存储在外部数据库中,Python 实例仅持有数据库表中对应的的键。描述器负责对值进行查找或更新:
import pymysql
class Field:
def __init__(self):
self.conn = pymysql.connect(host="localhost",
database="xiaoxu",
user="root",
password="123456",
charset="utf8",
port=3306)
self.cursor = self.conn.cursor()
def __set_name__(self, owner, name):
self.fetch = f'SELECT {name} FROM {owner.table} WHERE {owner.key}=%s;'
self.store = f'UPDATE {owner.table} SET {name}=%s WHERE {owner.key}=%s;'
def __get__(self, obj, objtype=None):
self.cursor.execute(self.fetch, [obj.value])
return self.cursor.fetchone()[0]
def __set__(self, obj, value):
self.cursor.execute(self.store, [value, obj.key])
self.conn.commit()
class People:
table = "my_people"
key = "id"
id = Field()
my_name = Field()
my_age = Field()
birthday = Field()
def __init__(self, key, value):
self.key = key
self.value = value
p = People("id", "2")
print(p.id)
print(p.my_name)
print(p.my_age)
print(p.birthday)
表的数据如下所示:

数据为:

执行结果如下:

更新操作如下:
p.my_name = "小红来了"
执行结果无打印,重新查询数据:

重新查询数据,已更新成功:

再次执行如下:
p = People("id", "2")
print(p.id)
print(p.my_name)
print(p.my_age)
print(p.birthday)
可见结果(p.my_name))已经发生改变:

2.3.5 functools.cached_property使用分析
有了上述的多个栗子针对__set_name__方法的分析,我们再来具体分析下functools.cached_property的使用。
from functools import cached_property
class Xiaoxu:
@cached_property
def xiaoxu_names(self):
print("调用缓存属性:xiaoxu_names", self)
return "小徐"
x = Xiaoxu()
print(x.xiaoxu_names)
print(x.xiaoxu_names)
# 调用缓存属性:xiaoxu_names <__main__.Xiaoxu object at 0x01B1D880>
# 小徐
# 小徐
执行结果如下:

可以看到实现了缓存类的属性,而实际是定义的方法,但是执行时是获取的被修饰的实例方法的返回属性值,且具有缓存的效果。
下面分析cached_property的源码来看下如何实现缓存的效果的:
class cached_property:
def __init__(self, func):
self.func = func
self.attrname = None
self.__doc__ = func.__doc__
self.lock = RLock()
def __set_name__(self, owner, name):
if self.attrname is None:
self.attrname = name
elif name != self.attrname:
raise TypeError(
"Cannot assign the same cached_property to two different names "
f"({self.attrname!r} and {name!r})."
)
def __get__(self, instance, owner=None):
if instance is None:
return self
if self.attrname is None:
raise TypeError(
"Cannot use cached_property instance without calling __set_name__ on it.")
try:
cache = instance.__dict__
except AttributeError: # not all objects have __dict__ (e.g. class defines slots)
msg = (
f"No '__dict__' attribute on {type(instance).__name__!r} "
f"instance to cache {self.attrname!r} property."
)
raise TypeError(msg) from None
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
with self.lock:
# check if another thread filled cache while we awaited lock
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
val = self.func(instance)
try:
cache[self.attrname] = val
except TypeError:
msg = (
f"The '__dict__' attribute on {type(instance).__name__!r} instance "
f"does not support item assignment for caching {self.attrname!r} property."
)
raise TypeError(msg) from None
return val
__class_getitem__ = classmethod(GenericAlias)
cached_property类,定义了__set_name__方法,可以作为装饰器来使用,效果根据上述分析的,cached_property类装饰方法时,触发__set_name__方法,将方法的名称作为属性名self.attrname,然后核心是__get__方法,判断如果instance为None,也就是类.方法来调用时,直接返回self,如果instance不为None,也就是通过类实例.方法来调用缓存属性的,那么从类实例的__dict__中获取值(因为若类中定义了__slots__,但是__slots__里面没有定义__dict__属性,那么这种情况可能是没有__dict__的,所以源码判断了获取__dict__失败的场景)。
然后核心实现如下:
try:
cache = instance.__dict__
except AttributeError: # not all objects have __dict__ (e.g. class defines slots)
msg = (
f"No '__dict__' attribute on {type(instance).__name__!r} "
f"instance to cache {self.attrname!r} property."
)
raise TypeError(msg) from None
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
with self.lock:
# check if another thread filled cache while we awaited lock
val = cache.get(self.attrname, _NOT_FOUND)
if val is _NOT_FOUND:
val = self.func(instance)
try:
cache[self.attrname] = val
except TypeError:
msg = (
f"The '__dict__' attribute on {type(instance).__name__!r} instance "
f"does not support item assignment for caching {self.attrname!r} property."
)
raise TypeError(msg) from None
return val
-
首先定义了_NOT_FOUND为object(),作为从类实例的__dict__中获取方法名的属性时,若值不存在,则返回定义的默认值,也就是object();上述执行的语句是val = cache.get(self.attrname, _NOT_FOUND);
-
接下来判断if val is _NOT_FOUND,也就是实例对象的__dict__中还没有缓存该方法名属性值,如果判断成立的情况下,那么就通过with self.lock加锁,加锁后,再次调用cache.get(self.attrname, _NOT_FOUND)从类实例的__dict__中获取该缓存属性值,如果依然为空,那么就调用self.func(instance),也就是通过类实例对象来执行缓存属性的实例方法,由该实现也可知,缓存属性的实例方法不要有其他额外的参数;获取到需要缓存的值后,通过cache[self.attrname] = val将方法返回值缓存到该实例对象的__dict__中,key也就是属性值,即使用了@cached_property修饰的实例方法名称;这里的实现也提示了我们非常重要的一点,就是@cached_property的属性缓存,是基于实例对象来缓存的,如果你重新new,也就是重新定义了一个类实例对象,那么该实例的属性值又需要重新缓存了,这里需要特别注意。
-
另外特殊说明下,python这里的加锁的判断方式,也就是我们熟知的双重检测锁的使用方式。先从缓存中获取数据并判断数据是否为空,为空的情况下,先加锁,然后再次从缓存中获取数据并判断数据是否为空,如果依然为空,那么就执行数据的生成,并塞入缓存中,如果缓存中第一次或者第二次判断不成立,那么说明缓存中存在该值,直接返回该缓存值即可。这种加锁的前后各有一次获取值并判断的形式,就是双重检测锁。好处是,加锁前的为空判断,可以避免一些不必要的加锁情况,最外面的if判断不成立的情况下,无需加锁,直接返回结果,提升了代码性能;若第一次判断成立,获取到锁之后,第二次还要进行为空判断的目的是,避免在多线程的情况下,假设A、B两个线程都同时进行了第一次判断,同时判断均为空,在判断结果均成立时,如果加锁后没有第二次的判断,那么假设A线程首先抢到锁,进入同步代码块,而B则进入阻塞队列或者说形如乐观锁中B线程在自旋等待锁的释放(比如Java中synchronized的锁升级,升级为轻量级锁时就是使用CAS的自旋锁,也就是乐观锁);当A进行缓存值的获取和设置后,成功释放锁,另外的线程B在锁释放时抢到了锁,因为没有第二次判断,所以立马再次执行了一次缓存值的获取和设置,若我们需要使用这种加锁模式实现单例模式,那么很明显多次的赋值和我们的预期单例是不一样的(缓存值的设置也应当采用单例模式,因为不需要对重复的key设置缓存),所以需要使用双重检测锁来进行过单例模式的实现。反之,若加锁后存在第二次判断,则线程B获取到锁时,首先判断缓存值已经存在,自然就不需要重复的进行缓存值的获取和设置了。
-
当然,题外话,一般我们在Java中通过双重检测锁实现单例模式时,对于单例的实例对象,我们还需要加上volatile关键字,目的是为了禁止Java中指令的重排序。避免指令重排导致的情况是,假设线程A因为指令重排,先执行变量的赋值,再执行变量的初始化(指令重排导致先赋值再初始化,理想的预期是先初始化引用对象,再赋值给左边的变量;指令重排序在没有改变单线程程序的执行结果的前提下,可以提高程序的执行性能,但是多线程中就可能存在问题),在线程A执行完变量的赋值,还没执行变量的初始化时,如果此时线程B进行为空判断,由于对象已经赋值,那么判断不为空,线程B此时可以自由访问该对象,然后该对象还未初始化,所以线程B访问时将会发生异常。所以参考Spring的源码getHandlerMappings,对于Map对象handlerMappings,使用双重检测锁时,也为handlerMappings添加了volatile关键字。
到此,cached_property类缓存属性的实现方式已经全部分析完毕,下面简单演示下上述提到的,缓存是针对实例对象本身的这个情况:
from functools import cached_property
class Xiaoxu:
@cached_property
def xiaoxu_names(self):
print("调用缓存属性:xiaoxu_names", self)
return "小徐"
x = Xiaoxu()
print(x.xiaoxu_names)
print(x.xiaoxu_names)
y = Xiaoxu()
print(y.xiaoxu_names)
执行结果如下:

2.3.6 自定义__set_name__方法实现接口的post、get等请求装饰器
最后,以我们自定义的__set_name__方法,来举一个栗子,实现接口的post、get等请求装饰器,并结合pytest单测框架,来实现一个接口的请求,实现如下:
文件目录格式如下:
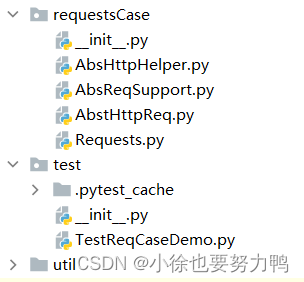
记得先安装pytest框架:
pip3 install pytest==8.2.1
查看pytest框架的版本:
pytest --version
结果:
pytest 8.2.1
具体实现如下:
AbsHttpHelper.py:
import functools
from requestsCase.AbstHttpReq import *
# import inspect
# class _partialHttp:
# __slots__ = "func", "args", "keywords", "__dict__", "__weakref__"
#
# def __instancecheck__(self, instance):
# return inspect.isclass(instance)
#
# def __new__(cls, func, /, *args, **keywords):
# if not callable(func):
# raise TypeError("the first argument must be callable")
#
# self = super(_partialHttp, cls).__new__(cls)
# __self, *arg = args
# # data_func:获取test单测返回的接口请求数据
# self.data_func = __self.func
# # self.func:这里指的是httpJsonPostRequest方法
# print(f"\n【func】:{func}\n")
# self.func = func
# self.method = __self.attrName
# self.args = args
# self.keywords = keywords
#
# self.__name__ = self.data_func.__name__
# print(f"函数名:{self.__name__}")
# return self
#
# def __call__(self, /, *args, **keywords):
# payloadOrFileOrParams = self.data_func(*args, **keywords)
# if not isinstance(payloadOrFileOrParams, dict):
# raise ValueError("request test method must return dict req data.")
# keywords = {**self.keywords, **payloadOrFileOrParams}
#
# if self.method.__eq__("get"):
# if not payloadOrFileOrParams.__contains__("params"):
# raise ValueError(f"get请求缺少params参数:{payloadOrFileOrParams},请检查")
# elif self.method.__eq__("post"):
# if not payloadOrFileOrParams.__contains__("params"):
# raise ValueError(f"post请求缺少payload参数:{payloadOrFileOrParams},请检查")
# elif self.method.__eq__("file"):
# if not payloadOrFileOrParams.__contains__("params"):
# raise ValueError(f"file请求缺少files参数:{payloadOrFileOrParams},请检查")
# else:
# raise ValueError("不支持的请求场景!")
#
# print("开始请求:")
# ret = self.func(*self.args, **keywords)
# print("结果:", ret)
# return ret
def _partialHttp(httpFunc, __self, head, /, **kwargs):
# data_func:获取test单测返回的接口请求数据
data_func = __self.func
method = __self.attrName
argsHttp = (head,)
# data_func是原本的单测对应的方法,这里使用单测方法的元信息如__name__\__doc__\__annotations__等等
# 将单测方法的元信息,添加到闭包的part方法上
@functools.wraps(data_func)
def part(*args, **keywords):
payloadOrFileOrParams = data_func(*args, **keywords)
if payloadOrFileOrParams is None:
payloadOrFileOrParams = {}
if not isinstance(payloadOrFileOrParams, dict):
raise ValueError("request test method must return dict req data.")
if payloadOrFileOrParams == {}:
if method.__eq__("get"):
payloadOrFileOrParams["params"] = {}
elif method.__eq__("post"):
payloadOrFileOrParams["payload"] = {}
elif method.__eq__("file"):
payloadOrFileOrParams["files"] = {}
else:
raise ValueError("un support")
elif method.__eq__("get"):
if not payloadOrFileOrParams.__contains__("params"):
raise ValueError(f"get请求缺少params参数:{payloadOrFileOrParams},请检查")
payloadOrFileOrParams["payload"] = {}
elif method.__eq__("post"):
if not payloadOrFileOrParams.__contains__("payload"):
raise ValueError(f"post请求缺少payload参数:{payloadOrFileOrParams},请检查")
elif method.__eq__("file"):
if not payloadOrFileOrParams.__contains__("files"):
raise ValueError(f"file请求缺少files参数:{payloadOrFileOrParams},请检查")
payloadOrFileOrParams["payload"] = {}
else:
raise ValueError("不支持的请求场景!")
keywordsHttp = {**kwargs, **payloadOrFileOrParams}
print(f"开始接口请求,【{argsHttp}】, 【{keywordsHttp}】.")
ret = httpFunc(*argsHttp, **keywordsHttp)
print("接口请求结束:", ret)
return ret
return part
class BindSelf(AbsHttpBase):
def __init__(self, func):
self.func = func
self.attrName = None
self.url = None
def __set_name__(self, owner, name):
if not self.attrName:
self.attrName = name
if self.attrName not in ["get", "post", "file"]:
raise ValueError("request name must be get or post.")
def __call__(self, url, /, *args, **kwargs):
self.url = url
self_ = self
print(f"\n【url】:{url}\n【method】:{self_.attrName}")
def __call__(__self, real_test_func, /, ):
__self.func = real_test_func
header = self.common_header_add_group_route("xiaoxu")
# return _partialHttp(self_.httpJsonPostRequest, __self, head, method=self_.attrName,
# url=self_.url)
# pytest必须使用function,才能执行case,上面使用类不会执行方法
return func_wrap(self_, __self, header, )
from types import MethodType
return MethodType(__call__, self_)
# BindSelf(get)("url")(test)
# test_case_func = BindSelf(get)("url")(test_case_func)(self, *arg, **kwaargs)
# 如果最终执行的不是function,pytest框架会忽略case执行,
# 所以我将上面的类改为了function的形式:_partialHttp()
def func_wrap(self_, __self, head, /, ):
return _partialHttp(self_.httpJsonPostRequest, __self, head, method=self_.attrName,
url=self_.url)
AbsReqSupport.py:
from requestsCase.AbsHttpHelper import BindSelf
class AbstractReqSupport:
"""
自定义的装饰器,用于修饰pytest该方法是get方法请求,还是post方法请求或者文件上传等请求
"""
@BindSelf
def get(self):
pass
@BindSelf
def post(self):
# self没有使用到
pass
@BindSelf
def file(self):
pass
AbstHttpReq.py:
import json
from abc import ABC, ABCMeta
from requestsCase.Requests import *
a_ = ABC
globals()["cookie"] = ""
class AbsHttpBase(metaclass=ABCMeta):
def httpJsonPostRequest(self, head1, method, payload, url, files=None, params=None):
print("请求参数:")
print(json.dumps(payload, indent=2).encode("utf-8").decode("unicode-escape"))
print("结果如下:")
res = None
if not files and payload and not params:
res = send_method(method, url, data=payload, headers=head1)
elif files and not payload and not params:
res = send_method(method, url, files=files, headers=head1)
elif params and not payload and not files:
res = send_method(method, url, params=params, headers=head1)
else:
# raise ValueError("unsupported request way, please add it.")
print("unsupported request way to do, please add it.")
print(json.dumps(res, indent=2).encode("utf-8").decode("unicode-escape"))
return res
def common_header_add_group_route(self, token):
cookie = globals()["cookie"]
if not cookie:
cookie = ""
cookie = cookie.strip()
user_agent = """Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/93.0.4577.63 Safari/537.36 """
lists = cookie.split(" ")
flag = False
for i in lists:
if i.strip().startswith("token"):
flag = True
if not flag:
lists[0] = lists[0] + ";"
lists.append("token=" + token)
cookie_new = "".join(lists)
header = dict()
header["Cookie"] = cookie_new
header["User-Agent"] = user_agent
return header
Requests.py:
import jsonpath
import requests
def send_method(method, url, headers=None, params=None, data=None, files=None):
if method.lower() == "post" and params is not None and data is None:
raise ValueError("post请求传参是data,请检查数据参数")
global response
if params and not data:
if isinstance(params, dict):
response = requests.request(method, url, params=params, headers=headers)
return response.json()
else:
print("params should be dict type!")
elif not params:
if files:
response = requests.post(url, data, headers=headers, files=files)
elif files and data:
response = requests.request(method, url, json=data, headers=headers, files=files)
elif not files and data:
response = requests.request(method, url, json=data, headers=headers)
else:
response = requests.request(method, url, headers=headers)
return response.json()
else:
print("request maybe is wrong.")
def get_key_value(data, pattern):
if isinstance(data, dict):
if pattern.startswith("$"):
return jsonpath.jsonpath(data, pattern)
else:
print("pattern must start with '$'")
else:
print("use jsonpath, data must be dict type")
根据pytest框架,我自定义的单测类TestReqCaseDemo.py:
import warnings
import pytest
from requestsCase.AbsReqSupport import AbstractReqSupport
warnings.filterwarnings("ignore")
py = pytest
class TestCase:
@AbstractReqSupport.get("http://localhost:8800/fruit/queryFruits")
def test_request(self):
params = {
"fruitId": "1006"
}
data = dict()
data["params"] = params
return data
执行前,说明下这个接口是我本地Java项目实现的get请求接口,部分源码如下:
@Controller
@RequestMapping(value = "/fruit")
@Slf4j
public class FruitController {
@Autowired
QueryFruitService queryFruitService;
@Autowired
ProcessorImpl<QueryFruitRequest, QueryFruitsResults> processor;
@ResponseBody
@RequestMapping(value = "/fruitsBySup", method = RequestMethod.GET)
public List<FruitVo> queryFruitsBySupplier() {
return null;
}
@ResponseBody
@RequestMapping(value = "/queryFruits", method = RequestMethod.GET)
public CommResult<QueryFruitsResults> queryFruits(QueryFruitRequest queryFruitRequest) {
Map<String, Object> params = Maps.newHashMap();
return processor.process(queryFruitRequest, new ProcessorCallBack<QueryFruitRequest, QueryFruitsResults>() {
@Override
public void validate(QueryFruitRequest params1) throws CommExp {
}
@Override
public QueryFruitsResults doProcess() throws CommExp {
log.info(String.format("请求进来了,传入的参数是:%s", queryFruitRequest));
List<FruitVo> fruitVos = queryFruitService.queryFruitsByCondition(queryFruitRequest);
QueryFruitsResults queryFruitsResults = new QueryFruitsResults();
if (!CollectionUtils.isEmpty(fruitVos)) {
queryFruitsResults.setFruitVoList(fruitVos);
}
return queryFruitsResults;
}
});
}
}
服务请求:

原本使用postman请求方式如下:

这里我们使用pytest结合实现的get请求装饰器,来发起接口请求:
对单测py文件,open in terminal并执行如下命令:
pytest TestReqCaseDemo.py -k "request" -s
执行结果如下:
collecting ...
【url】:http://localhost:8800/fruit/queryFruits
【method】:get
collected 1 item
TestReqCaseDemo.py 开始接口请求,【({'Cookie': ';token=xiaoxu', 'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(K
HTML,like Gecko)Chrome/93.0.4577.63 Safari/537.36 '},)】, 【{'method': 'get', 'url': 'http://localhost:8800/fruit/queryFruits', 'params'
: {'fruitId': '1006'}, 'payload': {}}】.
请求参数:
{}
结果如下:
{
"success": true,
"resData": {
"fruitVoList": [
{
"createTime": "22-7-4 上午2:04",
"modifyTime": "22-7-4 上午2:04",
"extraInformation": null,
"fruitNumber": 1006,
"fruitName": "黑布林",
"unitPrice": "6.98",
"crossOutPrice": "8.98",
"unitWeight": 500,
"supplierId": 877,
"fruitStockCount": 600,
"fruitSaleCount": 112
}
]
},
"code": "Fruit_Mall_952700200",
"msg": "Success",
"errorDesc": null
}
接口请求结束: {'success': True, 'resData': {'fruitVoList': [{'createTime': '22-7-4 上午2:04', 'modifyTime': '22-7-4 上午2:04', 'extraInf
ormation': None, 'fruitNumber': 1006, 'fruitName': '黑布林', 'unitPrice': '6.98', 'crossOutPrice': '8.98', 'unitWeight': 500, 'supplierI
d': 877, 'fruitStockCount': 600, 'fruitSaleCount': 112}]}, 'code': 'Fruit_Mall_952700200', 'msg': 'Success', 'errorDesc': None}
可见,单测执行的接口get请求效果,和postman的接口请求是一致的,且编码的形式更为灵活强大。