✨题目链接:
JZ38 字符串的排列
✨题目描述
输入一个长度为 n 字符串,打印出该字符串中字符的所有排列,你可以以任意顺序返回这个字符串数组。
例如输入字符串ABC,则输出由字符A,B,C所能排列出来的所有字符串ABC,ACB,BAC,BCA,CBA和CAB。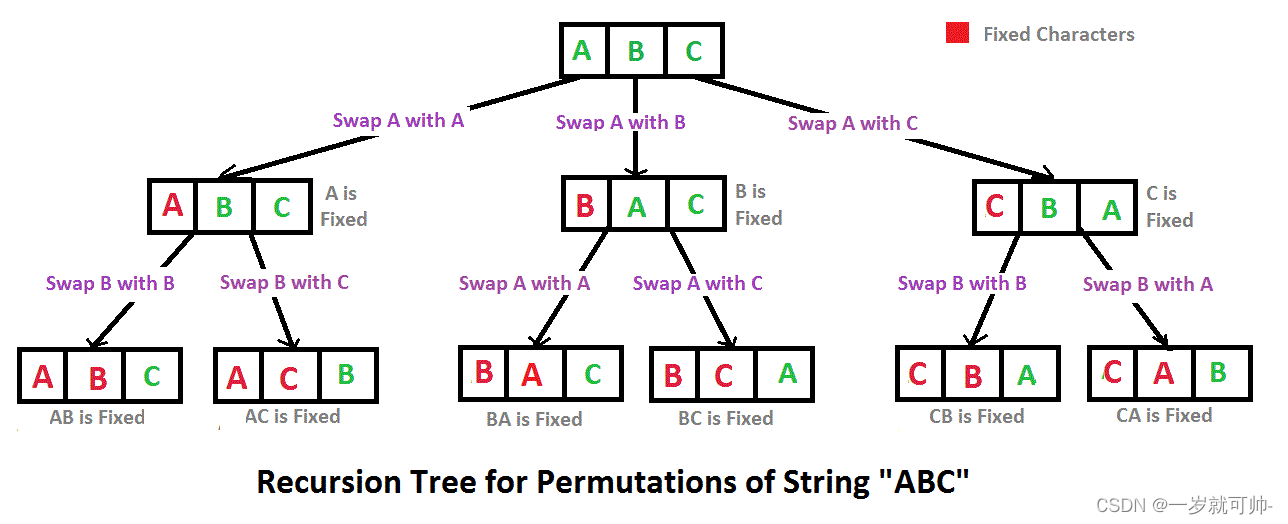
数据范围:𝑛<10
要求:空间复杂度 𝑂(𝑛!),时间复杂度 𝑂(𝑛!)
✨输入描述:
输入一个字符串,长度不超过10,字符只包括大小写字母。
✨示例1
📍输入
"ab"
📍返回值:
["ab","ba"]
📍说明
返回["ba","ab"]也是正确的
✨示例2
📍输入
"aab"
📍返回值:
["aab","aba","baa"]
✨示例3
📍输入
"abc"
📍返回值:
["abc","acb","bac","bca","cab","cba"]
✨示例4
📍输入
""
📍返回值:
[""]
✨解题思路
这道题目的解法看图片已经给我们提示一大半了
- 使用递归,每一层固定pos位置
- 每次swap pos位置和i位置
- 把swap后的str插入vector中
- 进入下层递归
因为此时我们vector中存的是所有可能的情况包括重复情况,所以我们要想办法去重操作
有两种去重的方法
- set 去重:set 可以自动去重来存储vector中的唯一元素,然后再将
set中的元素复制回vector - sort + unique 去重:你可以首先对
vector进行排序,然后使用unique来删除连续的重复元素。但请注意,unique只是将重复元素移到容器末尾并返回一个迭代器指向非重复区域的末尾,你需要通过调整vector的大小来真正删除这些元素。
两种方法的区别:不关心元素的顺序,那么使用set可能更简单。如果希望保留原始顺序,并且不介意在内部对元素进行排序,那么第二种方法可能更合适。
✨代码
#include <fstream>
#include <string>
#include <vector>
#include <iostream>
#include <set>
#include <algorithm>
using namespace std;
class Solution {
public:
/*
两种去重操作
*/
void removeDuplicates1(vector<string>& vec) {
set<string> s(vec.begin(), vec.end());
vec.clear(); // 清空原vector
vec.insert(vec.begin(),s.begin(), s.end()); // 插入去重后的元素
}
void removeDuplicates2(vector<string>& vec) {
sort(vec.begin(), vec.end()); // 排序
vec.erase(unique(vec.begin(), vec.end()), vec.end()); // 去重
}
void strsub(string str, vector<string>& vs, int pos) {
for (int i = pos; i < str.size(); i++) {
swap(str[pos], str[i]);
vs.push_back(str);
strsub(str, vs, pos + 1);
}
}
vector<string> Permutation(string str) {
vector<string> vs;
vs.push_back(str);
strsub(str, vs, 0);
removeDuplicates1(vs);
return vs;
}
};
※ 如果文章对你有帮助的话,可以点赞收藏!!谢谢支持