从反向传播到BPTT:详细推导与问题解析
在本文中,我们将从反向传播算法开始,详细推导出反向传播通过时间(Backpropagation Through Time, BPTT)算法。重点讨论BPTT中的梯度消失和梯度爆炸问题,并解释如何解决这些问题。假设读者已经具备反向传播的基本知识,我们将简要回顾反向传播的核心概念,然后深入解析BPTT算法。
反向传播算法的简要回顾
反向传播算法(Backpropagation)是用于训练神经网络的一种有效方法。其核心思想是通过链式法则(Chain Rule)计算损失函数相对于各个权重的梯度,然后使用梯度下降法更新权重。以下是反向传播的主要步骤:
- 前向传播: 计算输入数据通过神经网络各层的输出。
- 计算损失: 通过损失函数计算预测输出与真实输出之间的误差。
- 反向传播: 通过链式法则计算损失相对于每个权重的梯度。
反向传播的详细过程涉及链式法则在多层网络中的应用,我们将这些步骤拓展到处理时间序列数据的BPTT算法中。
详情见:BP神经网络反向传播原理【数学原理、举例说明】
反向传播通过时间(BPTT)算法
BPTT是一种针对循环神经网络(Recurrent Neural Networks, RNNs)的训练算法,它将标准反向传播算法扩展到 时间序列数据 上。RNN的特点是其隐藏层不仅依赖于 当前的输入 ,还依赖于 前一时间步的隐藏状态 ,这使得RNN能够处理序列数据。然而,这也引入了计算梯度的复杂性,因为损失不仅与当前时间步的输出相关,还与之前时间步的隐藏状态相关。
前向传播
在BPTT中,前向传播是从时间步1到时间步T逐步计算每个时间步的隐藏状态和输出。
假设我们有一个输入序列 { x 1 , x 2 , … , x T } \{x_1, x_2, \ldots, x_T\} {x1,x2,…,xT} ,每个 x t x_t xt 是在时间步t的输入。RNN的隐藏状态 h t h_t ht 和输出 y t y_t yt 依次计算如下:
-
初始化: 首先,隐藏状态 h 0 h_0 h0 通常初始化为零或小的随机值。
h 0 = 0 (或小的随机值) h_0 = 0 \text{(或小的随机值)} h0=0(或小的随机值) -
时间步1的计算:
-
计算隐藏状态 h 1 h_1 h1:
h 1 = f ( W h x x 1 + W h h h 0 + b h ) h_1 = f(W_{hx} x_1 + W_{hh} h_0 + b_h) h1=f(Whxx1+Whhh0+bh)
这里, W h x W_{hx} Whx 是输入到隐藏层的权重矩阵, W h h W_{hh} Whh 是隐藏层到隐藏层的权重矩阵, b h b_h bh 是偏置, f f f 是激活函数(如tanh或ReLU)。这一步可以理解为将 当前输入 x 1 x_1 x1 与前一时间步的隐藏状态 h 0 h_0 h0 结合,通过一个激活函数得到当前时间步的隐藏状态 h 1 h_1 h1 。这与传统BP(Backpropagation)不同,传统BP不考虑时间步之间的依赖,而RNN通过引入隐藏层状态的
递归关系来捕捉 时间序列中的依赖性 。 -
计算输出 y 1 y_1 y1:
y 1 = g ( W h y h 1 + b y ) y_1 = g(W_{hy} h_1 + b_y) y1=g(Whyh1+by)
这里, W h y W_{hy} Why 是隐藏层到输出层的权重矩阵, b y b_y by 是输出层的偏置, g g g 是输出层的激活函数(通常为softmax或线性函数)。这一步可以理解为将隐藏状态 h 1 h_1 h1 转化为输出 y 1 y_1 y1 。
-
-
时间步t的计算(t=2, …, T): 对于后续的每个时间步,我们重复上述步骤:
-
计算隐藏状态 h t h_t ht :
h t = f ( W h x x t + W h h h t − 1 + b h ) h_t = f(W_{hx} x_t + W_{hh} h_{t-1} + b_h) ht=f(Whxxt+Whhht−1+bh)
这里,隐藏状态 h t h_t ht 是当前输入 x t x_t xt 与前一时间步隐藏状态 h t − 1 h_{t-1} ht−1 的结合,通过激活函数 f f f 得到。 -
计算输出 y t y_t yt:
y t = g ( W h y h t + b y ) y_t = g(W_{hy} h_t + b_y) yt=g(Whyht+by)
输出 y t y_t yt 是当前隐藏状态 h t h_t ht 通过激活函数 g g g 得到。
-
通过这一步步计算,我们将输入序列 { x 1 , x 2 , … , x t } \{x_1, x_2, \ldots, x_t\} {x1,x2,…,xt} 转化为隐藏状态序列 { h 1 , h 2 , … , h t } \{h_1, h_2, \ldots, h_t\} {h1,h2,…,ht} 和输出序列 { y 1 , y 2 , … , y t } \{y_1, y_2, \ldots, y_t\} {y1,y2,…,yt} 。
为什么要将输入序列转换为隐藏状态序列和输出序列?
将输入序列转换为隐藏状态序列和输出序列的原因在于RNN的核心思想: 通过引入隐藏状态,模型能够捕捉序列数据中的时间依赖关系 。隐藏状态序列
{
h
1
,
h
2
,
…
,
h
t
}
\{h_1, h_2, \ldots, h_t\}
{h1,h2,…,ht} 是RNN对输入序列的内部表示,记录了前一时间步的信息,并将其传递给当前时间步。
数学上,这种递归关系可以理解为状态转移函数:
h
t
=
f
(
W
h
x
x
t
+
W
h
h
h
t
−
1
+
b
h
)
h_t = f(W_{hx} x_t + W_{hh} h_{t-1} + b_h)
ht=f(Whxxt+Whhht−1+bh)
这个公式表示当前的隐藏状态
h
t
h_t
ht 是当前输入
x
t
x_t
xt 和前一时间步隐藏状态
h
t
−
1
h_{t-1}
ht−1 的函数。通过这种递归关系,RNN能够记住之前时间步的信息,并在后续时间步中使用,从而捕捉长时间的依赖关系。
输出序列 { y 1 , y 2 , … , y t } \{y_1, y_2, \ldots, y_t\} {y1,y2,…,yt} 是模型的预测结果,通过将隐藏状态转化为输出,我们可以计算损失,并通过反向传播更新模型参数。
计算损失
计算损失是为了衡量模型输出与真实输出之间的误差。对于整个序列,我们通常采用均方误差(MSE)或交叉熵损失。假设真实输出序列为 { y ^ 1 , y ^ 2 , … , y ^ t } \{\hat{y}_1, \hat{y}_2, \ldots, \hat{y}_t\} {y^1,y^2,…,y^t} ,损失函数 L L L 可以表示为:
-
均方误差(MSE):
L = ∑ t = 1 T 1 2 ( y t − y ^ t ) 2 L = \sum_{t=1}^T \frac{1}{2} (y_t - \hat{y}_t)^2 L=t=1∑T21(yt−y^t)2
这里,我们计算每个时间步的输出 y t y_t yt 与真实输出 y ^ t \hat{y}_t y^t 之间的平方误差,并将所有时间步的误差求和。 -
交叉熵损失:
L = − ∑ t = 1 T [ y ^ t log ( y t ) + ( 1 − y ^ t ) log ( 1 − y t ) ] L = -\sum_{t=1}^T [\hat{y}_t \log(y_t) + (1 - \hat{y}_t) \log(1 - y_t)] L=−t=1∑T[y^tlog(yt)+(1−y^t)log(1−yt)]
这里,我们计算每个时间步的输出 y t y_t yt 与真实输出 y ^ t \hat{y}_t y^t 之间的交叉熵损失,并将所有时间步的损失求和。
反向传播
反向传播的目的是通过链式法则计算损失相对于每个权重的梯度,并更新权重。具体步骤如下:
-
计算输出层的梯度:
δ t y = ∂ ℓ ( y t , y ^ t ) ∂ y t ⋅ g ′ ( y t ) \delta^y_t = \frac{\partial \ell(y_t, \hat{y}_t)}{\partial y_t} \cdot g'(y_t) δty=∂yt∂ℓ(yt,y^t)⋅g′(yt)
这里, δ t y \delta^y_t δty 是第 t 时间步的输出层梯度。这个公式中的每个部分代表:- ∂ ℓ ( y t , y ^ t ) ∂ y t \frac{\partial \ell(y_t, \hat{y}_t)}{\partial y_t} ∂yt∂ℓ(yt,y^t) 是损失函数 ℓ \ell ℓ 对输出 y t y_t yt 的导数,它表示输出 y t y_t yt 的变化对损失函数 ℓ \ell ℓ 的影响。
- g ′ ( y t ) g'(y_t) g′(yt) 是输出层激活函数 g g g 对其输入 y t y_t yt 的导数。
根据链式法则,我们计算 ∂ ℓ ∂ y t \frac{\partial \ell}{\partial y_t} ∂yt∂ℓ 时,需要考虑:
∂ ℓ ∂ y t = ∂ ℓ ∂ g ( y t ) ⋅ ∂ g ( y t ) ∂ y t \frac{\partial \ell}{\partial y_t} = \frac{\partial \ell}{\partial g(y_t)} \cdot \frac{\partial g(y_t)}{\partial y_t} ∂yt∂ℓ=∂g(yt)∂ℓ⋅∂yt∂g(yt)
这里, ∂ ℓ ∂ g ( y t ) \frac{\partial \ell}{\partial g(y_t)} ∂g(yt)∂ℓ 是损失函数对激活函数输出的导数, ∂ g ( y t ) ∂ y t \frac{\partial g(y_t)}{\partial y_t} ∂yt∂g(yt) 是激活函数 g g g 对输入 y t y_t yt 的导数。
-
计算隐藏层的梯度:
隐藏层的梯度计算涉及当前时间步和未来时间步的影响:
δ t h = δ t y W h y T ⋅ f ′ ( h t ) + δ t + 1 h W h h T ⋅ f ′ ( h t ) \delta^h_t = \delta^y_t W_{hy}^T \cdot f'(h_t) + \delta^h_{t+1} W_{hh}^T \cdot f'(h_t) δth=δtyWhyT⋅f′(ht)+δt+1hWhhT⋅f′(ht)-
δ
t
y
W
h
y
T
⋅
f
′
(
h
t
)
\delta^y_t W_{hy}^T \cdot f'(h_t)
δtyWhyT⋅f′(ht) 是
当前时间步输出层梯度 传播回来的部分。具体来说, δ t y \delta^y_t δty 是输出层梯度,通过输出层到隐藏层的权重 W h y W_{hy} Why 传递回隐藏层,再乘以隐藏层激活函数 f f f 的导数 f ′ ( h t ) f'(h_t) f′(ht) 。 -
δ
t
+
1
h
W
h
h
T
⋅
f
′
(
h
t
)
\delta^h_{t+1} W_{hh}^T \cdot f'(h_t)
δt+1hWhhT⋅f′(ht) 是
未来时间步隐藏层梯度 传播回来的部分。这里, δ t + 1 h \delta^h_{t+1} δt+1h 是下一时间步的隐藏层梯度,通过隐藏层到隐藏层的权重 W h h W_{hh} Whh 传递回当前隐藏层,再乘以当前隐藏层激活函数的导数 f ′ ( h t ) f'(h_t) f′(ht)
-
δ
t
y
W
h
y
T
⋅
f
′
(
h
t
)
\delta^y_t W_{hy}^T \cdot f'(h_t)
δtyWhyT⋅f′(ht) 是
-
更新权重:
权重更新是通过梯度下降法进行的。梯度下降法的基本思想是沿着 梯度的反方向 更新权重,使得损失函数逐渐减小。-
输入到隐藏层的权重更新:
Δ W h x = ∑ t = 1 T δ t h ⋅ x t T \Delta W_{hx} = \sum_{t=1}^T \delta^h_t \cdot x_t^T ΔWhx=t=1∑Tδth⋅xtT
这里, δ t h \delta^h_t δth 是时间步 t t t 的隐藏层梯度, ⋅ x t T \cdot x_t^T ⋅xtT 表示输入 x t x_t xt 的转置。我们将所有时间步的梯度相加,得到输入到隐藏层权重的更新量。 -
隐藏层到隐藏层的权重更新:
Δ W h h = ∑ t = 2 T δ t h ⋅ h t − 1 T \Delta W_{hh} = \sum_{t=2}^T \delta^h_t \cdot h_{t-1}^T ΔWhh=t=2∑Tδth⋅ht−1T
这里, δ t h \delta^h_t δth 是时间步 t t t 的隐藏层梯度, ⋅ h t − 1 T \cdot h_{t-1}^T ⋅ht−1T 表示前一时间步隐藏状态 h t − 1 h_{t-1} ht−1 的转置。同样地,我们将所有时间步的梯度相加,得到隐藏层到隐藏层权重的更新量。 -
隐藏层到输出层的权重更新:
Δ W h y = ∑ t = 1 T δ t y ⋅ h t T \Delta W_{hy} = \sum_{t=1}^T \delta^y_t \cdot h_t^T ΔWhy=t=1∑Tδty⋅htT
这里, δ t y \delta^y_t δty 是时间步 t t t 的输出层梯度, ⋅ h t T \cdot h_t^T ⋅htT 表示当前时间步隐藏状态 h t h_t ht 的转置。我们将所有时间步的梯度相加,得到隐藏层到输出层权重的更新量。
-
这些权重更新公式通过链式法则计算各个权重的梯度,并使用梯度下降法更新权重,使得损失函数最小化。
梯度消失和梯度爆炸问题
在BPTT中,梯度消失和梯度爆炸是两个主要问题。这两个问题都与梯度在时间步长上的传播有关。随着时间步数增加,梯度的值可能会逐渐减小到几乎为零(梯度消失)或变得非常大(梯度爆炸),这会影响模型的训练效果。
梯度消失
随着时间步数的增加,梯度逐渐减小,最终可能变得非常接近于零。这导致模型无法有效更新权重,无法捕捉到长期依赖关系。
- 数学上,如果激活函数的导数 f ′ ( h t ) f'(h_t) f′(ht) 小于 1,多次相乘后会趋近于零。
- 比如,激活函数为 tanh \tanh tanh ,它的导数值在 [-1, 1] 之间,且通常小于 1。
梯度爆炸
随着时间步数的增加,梯度逐渐变大,最终可能变得非常大。这导致权重更新过大,模型无法收敛。
- 数学上,如果激活函数的导数 f ′ ( h t ) f'(h_t) f′(ht) 大于 1,多次相乘后会迅速增长。
- 比如,激活函数为 ReLU(修正线性单元),其导数在正区间为 1,如果某些参数或权重较大,梯度可能会迅速累积变大。
梯度传播过程中的数学推导
假设一个简单的RNN模型,隐藏层激活函数为 f f f ,我们考虑隐藏层的状态 h t h_t ht 及其梯度的传播过程。
基本概念和公式
-
隐藏层状态更新:
h t = f ( W h h h t − 1 + W h x x t + b h ) h_t = f(W_{hh} h_{t-1} + W_{hx} x_t + b_h) ht=f(Whhht−1+Whxxt+bh) -
输出层状态:
y t = g ( W h y h t + b y ) y_t = g(W_{hy} h_t + b_y) yt=g(Whyht+by) -
损失函数:
L = ∑ t = 1 T ℓ ( y t , y ^ t ) \mathcal{L} = \sum_{t=1}^T \ell(y_t, \hat{y}_t) L=t=1∑Tℓ(yt,y^t) -
输出层梯度:
δ t y = ∂ ℓ ( y t , y ^ t ) ∂ y t ⋅ g ′ ( y t ) \delta^y_t = \frac{\partial \ell(y_t, \hat{y}_t)}{\partial y_t} \cdot g'(y_t) δty=∂yt∂ℓ(yt,y^t)⋅g′(yt)
梯度传播到隐藏层
我们通过链式法则计算隐藏层梯度。首先从输出层梯度开始传播,考虑激活函数 f f f 的导数 f ′ ( h t ) f'(h_t) f′(ht) 。
隐藏层梯度的递归公式为:
δ t h = δ t y W h y T ⋅ f ′ ( h t ) + δ t + 1 h W h h T ⋅ f ′ ( h t ) \delta^h_t = \delta^y_t W_{hy}^T \cdot f'(h_t) + \delta^h_{t+1} W_{hh}^T \cdot f'(h_t) δth=δtyWhyT⋅f′(ht)+δt+1hWhhT⋅f′(ht)
假设激活函数 f f f 的导数在所有时间步长上都是一个常数 k k k,即 f ′ ( h t ) = k f'(h_t) = k f′(ht)=k。为了简化,我们假设权重矩阵 W h h W_{hh} Whh 和 W h y W_{hy} Why 也为常数。
梯度递归公式的展开
我们从最后一个时间步 T T T 开始,逐步向前展开递归公式:
δ T h = δ T y W h y T ⋅ k \delta^h_T = \delta^y_T W_{hy}^T \cdot k δTh=δTyWhyT⋅k
对于 T − 1 T-1 T−1 时间步:
δ T − 1 h = δ T − 1 y W h y T ⋅ k + δ T h W h h T ⋅ k \delta^h_{T-1} = \delta^y_{T-1} W_{hy}^T \cdot k + \delta^h_T W_{hh}^T \cdot k δT−1h=δT−1yWhyT⋅k+δThWhhT⋅k
将
δ
T
h
\delta^h_T
δTh带入:
=
δ
T
−
1
y
W
h
y
T
⋅
k
+
(
δ
T
y
W
h
y
T
⋅
k
)
W
h
h
T
⋅
k
= \delta^y_{T-1} W_{hy}^T \cdot k + (\delta^y_T W_{hy}^T \cdot k) W_{hh}^T \cdot k
=δT−1yWhyT⋅k+(δTyWhyT⋅k)WhhT⋅k
=
k
δ
T
−
1
y
W
h
y
T
+
k
2
δ
T
y
W
h
y
T
W
h
h
T
= k \delta^y_{T-1} W_{hy}^T + k^2 \delta^y_T W_{hy}^T W_{hh}^T
=kδT−1yWhyT+k2δTyWhyTWhhT
我们继续展开 T − 2 T-2 T−2 时间步:
δ
T
−
2
h
=
δ
T
−
2
y
W
h
y
T
⋅
k
+
δ
T
−
1
h
W
h
h
T
⋅
k
\delta^h_{T-2} = \delta^y_{T-2} W_{hy}^T \cdot k + \delta^h_{T-1} W_{hh}^T \cdot k
δT−2h=δT−2yWhyT⋅k+δT−1hWhhT⋅k
=
δ
T
−
2
y
W
h
y
T
⋅
k
+
(
δ
T
−
1
y
W
h
y
T
⋅
k
+
δ
T
h
W
h
h
T
⋅
k
)
W
h
h
T
⋅
k
= \delta^y_{T-2} W_{hy}^T \cdot k + \left( \delta^y_{T-1} W_{hy}^T \cdot k + \delta^h_T W_{hh}^T \cdot k \right) W_{hh}^T \cdot k
=δT−2yWhyT⋅k+(δT−1yWhyT⋅k+δThWhhT⋅k)WhhT⋅k
=
δ
T
−
2
y
W
h
y
T
⋅
k
+
δ
T
−
1
y
W
h
y
T
W
h
h
T
⋅
k
2
+
δ
T
y
W
h
y
T
W
h
h
T
W
h
h
T
⋅
k
3
= \delta^y_{T-2} W_{hy}^T \cdot k + \delta^y_{T-1} W_{hy}^T W_{hh}^T \cdot k^2 + \delta^y_T W_{hy}^T W_{hh}^T W_{hh}^T \cdot k^3
=δT−2yWhyT⋅k+δT−1yWhyTWhhT⋅k2+δTyWhyTWhhTWhhT⋅k3
推广到一般情况,对于时间步 ( t ):
δ t h = δ t y W h y T ⋅ k + δ t + 1 h W h h T ⋅ k \delta^h_t = \delta^y_t W_{hy}^T \cdot k + \delta^h_{t+1} W_{hh}^T \cdot k δth=δtyWhyT⋅k+δt+1hWhhT⋅k
递归展开后,我们可以看到梯度会逐步乘以 ( k ),并传播到前面的时间步。这意味着:
δ t h = δ t y ⋅ ( W h y T ⋅ k t ) \delta^h_t = \delta^y_t \cdot (W_{hy}^T \cdot k^t) δth=δty⋅(WhyT⋅kt)
推导公式
假设 W h y W_{hy} Why 和 W h h W_{hh} Whh 为单位矩阵 I I I,我们简化得到:
δ t h = δ ⋅ k t \delta^h_t = \delta \cdot k^t δth=δ⋅kt
如果激活函数的导数 k < 1 k < 1 k<1 ,那么 k t k^t kt 会随着 t t t 增加而快速趋近于零,导致梯度消失。
具体示例
为了更直观地理解梯度消失和梯度爆炸,我们用一个简单的RNN模型和一个假设的初始梯度进行解释。
假设:
- 输入序列长度为 ( T )。
- 隐藏层激活函数为 ( tanh \tanh tanh )。
- 初始梯度为 ( δ = 1 \delta = 1 δ=1 )。
- 每一步的激活函数导数 ( f ′ ( h t ) = k f'(h_t) = k f′(ht)=k )(假设为常数)。
梯度消失示例
假设激活函数导数 k = 0.5 k = 0.5 k=0.5 ,即每一步的导数都小于 1。
随着时间步数 T T T 的增加,梯度会逐渐减小:
δ T h = δ ⋅ k T \delta^h_T = \delta \cdot k^T δTh=δ⋅kT
例如,当 T = 10 T = 10 T=10 时:
δ 10 h = 1 ⋅ 0. 5 10 = 1 ⋅ 0.00098 = 0.00098 \delta^h_{10} = 1 \cdot 0.5^{10} = 1 \cdot 0.00098 = 0.00098 δ10h=1⋅0.510=1⋅0.00098=0.00098
可以看到,梯度非常小,接近于零。
更进一步,如果 T = 20 T = 20 T=20:
δ 20 h = 1 ⋅ 0. 5 20 = 1 ⋅ 0.00000095 = 0.00000095 \delta^h_{20} = 1 \cdot 0.5^{20} = 1 \cdot 0.00000095 = 0.00000095 δ20h=1⋅0.520=1⋅0.00000095=0.00000095
梯度几乎为零,说明模型无法有效更新权重,导致无法捕捉长期依赖关系。
梯度爆炸示例
假设激活函数导数 k = 1.5 k = 1.5 k=1.5 ,即每一步的导数都大于 1。
随着时间步数 T T T 的增加,梯度会逐渐增大:
δ T h = δ ⋅ k T \delta^h_T = \delta \cdot k^T δTh=δ⋅kT
例如,当 T = 10 T = 10 T=10 时:
δ 10 h = 1 ⋅ 1. 5 10 = 1 ⋅ 57.67 = 57.67 \delta^h_{10} = 1 \cdot 1.5^{10} = 1 \cdot 57.67 = 57.67 δ10h=1⋅1.510=1⋅57.67=57.67
可以看到,梯度非常大,导致训练不稳定。
更进一步,如果 T = 20 T = 20 T=20:
δ 20 h = 1 ⋅ 1. 5 20 = 1 ⋅ 33252.32 = 33252.32 \delta^h_{20} = 1 \cdot 1.5^{20} = 1 \cdot 33252.32 = 33252.32 δ20h=1⋅1.520=1⋅33252.32=33252.32
梯度变得非常大,说明模型无法收敛,权重更新会过大,导致训练失败。
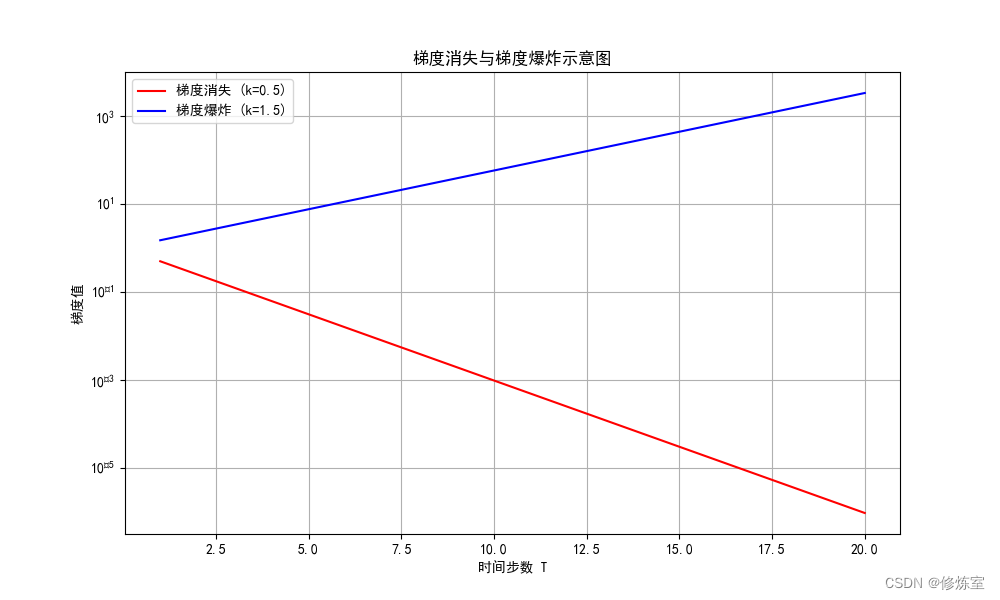
- 梯度消失:图中
红线表示的梯度随着时间步数 𝑇 增加而快速减小,趋近于零。这说明当时间步数增加时,梯度值变得非常小,无法有效更新权重,导致模型无法捕捉长期依赖关系。 - 梯度爆炸:图中
蓝线表示的梯度随着时间步数 𝑇 增加而快速增大。这说明当时间步数增加时,梯度值变得非常大,导致权重更新过大,训练过程变得不稳定,模型难以收敛。
解决梯度消失和梯度爆炸的方法
为了缓解梯度消失和梯度爆炸问题,可以采用以下几种常见的方法:
-
梯度裁剪(Gradient Clipping):
- 将梯度的绝对值限制在某个阈值范围内,防止梯度爆炸。
- 例如,当梯度超过某个阈值时,将其裁剪到这个阈值。
-
正则化方法:
- 使用L2正则化(权重衰减)防止过度活跃的神经元。
- 增加权重更新时的惩罚项,控制权重值不至于过大。
-
批归一化(Batch Normalization):
- 对每个时间步的隐藏状态进行归一化,稳定训练过程。
- 通过归一化,控制每个时间步的输出范围,防止梯度过大或过小。
-
调整激活函数:
- 选择适当的激活函数(如ReLU、Leaky ReLU等),防止梯度消失和爆炸。
- 例如,Leaky ReLU 在负区间也有非零导数,避免了完全的梯度消失问题。
为什么很小的梯度无法更新权重并导致无法捕捉长期依赖关系?
当梯度非常小时,反向传播的权重更新公式:
Δ W = − η ⋅ ∂ L ∂ W \Delta W = -\eta \cdot \frac{\partial \mathcal{L}}{\partial W} ΔW=−η⋅∂W∂L
梯度项 ∂ L ∂ W \frac{\partial \mathcal{L}}{\partial W} ∂W∂L 会非常小。这里, η \eta η 是学习率。当梯度接近零时,权重更新 Δ W \Delta W ΔW 也会接近零。这意味着神经网络的权重几乎不会发生变化,导致模型无法从训练数据中学习到有用的信息,从而无法有效捕捉长期依赖关系。
![[Linux]Crond任务调度以及at任务调度](https://img-blog.csdnimg.cn/direct/ae4d77323e2b4799bcb8724645bf2579.png)