目录
一、关于文件的打开和关闭
1. 文件的打开
2.文件的关闭
二、文件的读取
1. 文件的读_r
2. 使用readline
3.使用readlines
三、文件的写入
1. 文本的新建写入
2.文本的追加写入
四、文件的删除和重命名
1.文件的重命名
2.文件的删除
五、文件的定位读写
1.tell( )函数
2.seek( )函数
附录 P.S.
一、关于文件的打开和关闭
1. 文件的打开
在Python中,open函数用来打开文件,语法格式如下:

常见的文件打开模式:

又通过互相组合可以得到几个新的常见模式:

栗子:
当我们只打开某个文件时,要先确保这个文件是存在的。
所以,先创建一个文本文件(与创建python文件类似):
在项目栏中 鼠标右击-->新建-->文件
输入想命名的名字,写上后缀 .txt

然后输入内容...
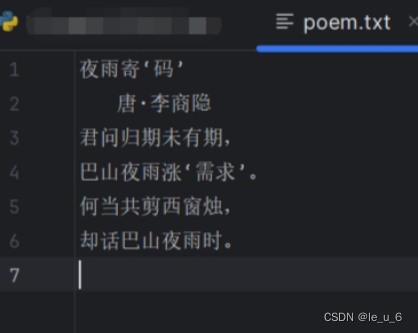
最后、回到python文件,打开一个文本文件

根据填写要求,文件名是一定要有的,模式可以选填,如果不填,则要保证文本是存在的,否则报错。

控制台结果显示:这个字符串表示的是一个已经打开的文本文件 poem.txt,它被设置为只读模式,并且使用 GBK 编码进行文本的编码和解码。
2.文件的关闭
文件的关闭强调打开了的文件,要使用close语句关闭。因为即便文件会在程序退出后自动关闭,但考虑到数据的安全性,在每次使用完文件后,都要使用close语句关闭文件,否则一旦程序奔溃就可能导致文件中的数据没有保存。

二、文件的读取
1. 文件的读_r
f = open("poem.txt", "r", encoding="utf-8")
'''打开事先备好的文本文件,填“r”读的模式,后面是编码方式
如果你测试的文本文件txt内容含有中文,最好写上encoding编码方式,否则报错'''
content = f.read() # 对f变量进行读取操作再赋给content
print(content)
f.close()打印结果:

2. 使用readline
readline方法是逐行读取,比较繁琐...
f = open('poem.txt', "r", encoding='utf-8')
c1 = f.readline()
c2 = f.readline()
c3 = f.readline()
c4 = f.readline()
c5 = f.readline()
c6 = f.readline()
print(c1)
print(c2)
print(c3)
print(c4)
print(c5)
print(c6)
f.close()考虑文本中存在换行以及print自带换行,最后结果是每行之间 空的比较大
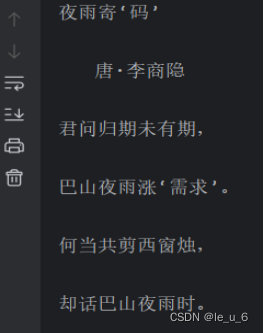
3.使用readlines
readlins的用法是把整个文本内容一次性都读取了。
栗子:

这里我们用with...as:语句。因为Python中 ,with...as:语句是一种很好的上下文管理器, 可以确保无论代码块中发生什么情况,文本资源最终都会被正确地释放和关闭。可以防止忘记写close( )。

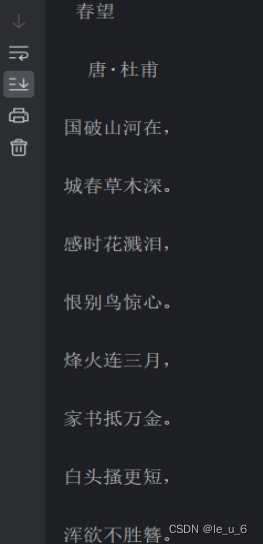
这里事先换了首诗,可看到系统自动加\n换行,所以为了好看点,readlines一般可以和for语句一起用:
with open("poem.txt", "r", encoding="utf-8") as f:
c = f.readlines()
for p in c: # 使用for循环,可以逐行显示序列
print(p)打印结果:
三、文件的写入
1. 文本的新建写入
向文件写入数据时,如果文件不存在,那么系统会自动创建一个文件并写入数据。如果文件存在,那么会清空文件原有的数据,重新写入新数据。
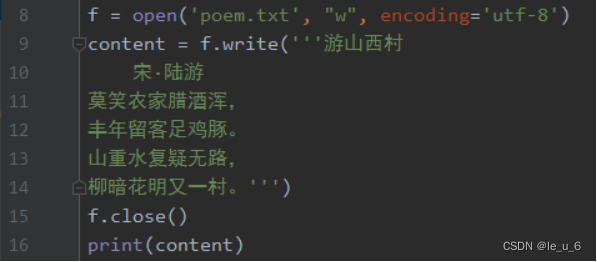
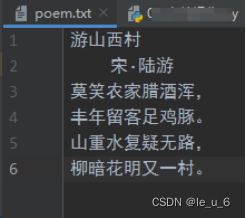
最后控制台显示的是 字符数:49

2.文本的追加写入
文本的追加写入,我们用模式“ a ”
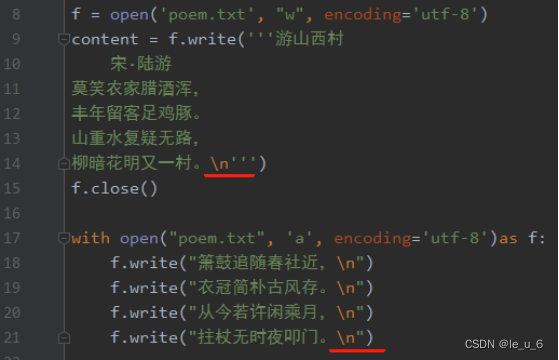
在文末添加内容根据注意换行啊
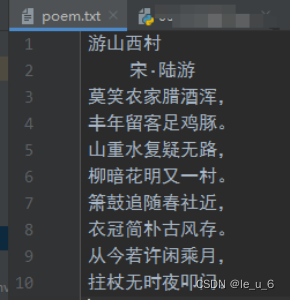
四、文件的删除和重命名
在Python中,我们要对文本文件进行删除和重命名的话,可以使用标准库中的os模块。与读取类似,对文件删除或重命名之前,最好先检查文件是否存在,以避免抛出异常。
1.文件的重命名
os模块通过rename函数对文件重命名,rename函数接收两个参数,分别是旧的文件名和新的文件名。
栗子:
# 引入os模块
import os
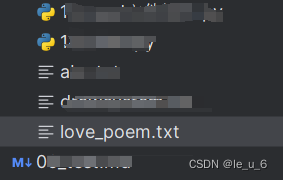
# 将 poem 改成 love_poem
os.rename('poem.txt', "love_poem.txt")运行后,会发现原来目录下面文本文件的名字已改
2.文件的删除
文件的删除用到os模块中的remove函数,remove函数接受一个参数,即要删除的文件的路径。如果文件被成功删除,该函数不会有任何返回值。如果文件不存在,os.remove()会抛出一个 FileNotFoundError 异常。
例如:
# 引入os模块
import os
# 删除love_poem的文本文件
os.remove('love_poem.txt')五、文件的定位读写
在Python中,文件的读写定位是指 “控制文件读写操作的位置”,以便于能够从文件的特定位置开始读取或写入数据。 通常通过文件的指针来实现,该指针指示下一次读写操作将在文本的哪个位置进行。以下两个函数是常见的获取和设置文件指针的位置。
1.tell( )函数
tell()函数会返回文件指针的当前位置,注意中英文字符对位置的影响。
# 打开一个存在的文本文件
f = open("poem.txt", "r", encoding="utf-8")
# 这里偏移量为4,
words = f.read(4)
print("第一次读取的数据:"words)
# 查找当前位置
position =f.tell()
print("第一次的位置是:",position)
words = f.read(16)
print("第二次读的数据:",words)
position =f.tell()
print("第二次位置是:,position)测试的文本:
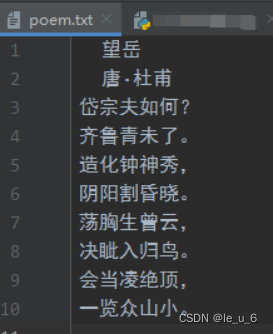
打印结果:
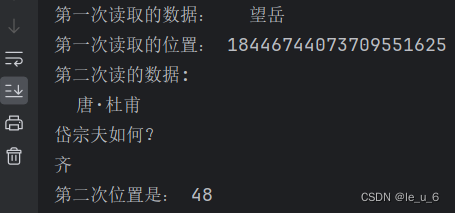
这里第一次位置1844.....我也不懂咋来的,希望有懂的大佬,不吝赐教,留言相告哈。
然后,转成字母,显示位置就正常^-^。


2.seek( )函数
如果希望 重置(重新定位) 指针的位置,可以考虑seek函数
seek函数语法格式:
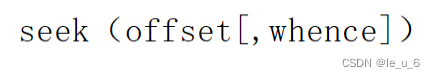
(1)offset : 表示偏移量,也就是需要移动的字节数。
(2)whence: 表示方向,该参数的值有以下三个:
0 : 是whence参数的默认值,表示从文件的起始位置开始偏移,所以也可以不写。
1 : 表示从文件当前的位置开始偏移。
2 : 表示从文件末尾开始偏移。
f = open("poem.txt", "r", encoding="utf-8")
words = f.read(4)
print("第一次读取的数据:", words)
position = f.tell()
print("第一次读取的位置:", position)
f.seek(10) # 从初始开始偏移10个
position = f.tell()
print("第二次位置是:", position)
words = f.read(20)
print("第二次读取的数据:", words)
f.close()后半段seek函数重新偏移从开头到位置10时,接着开始第二次读取20个字符,这20个字符是在第10个字符位置的基础上再往后读20个。
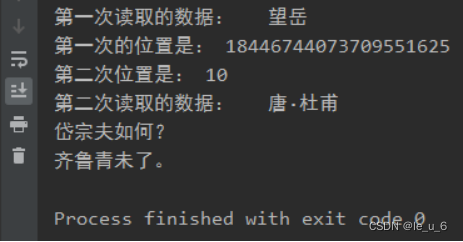
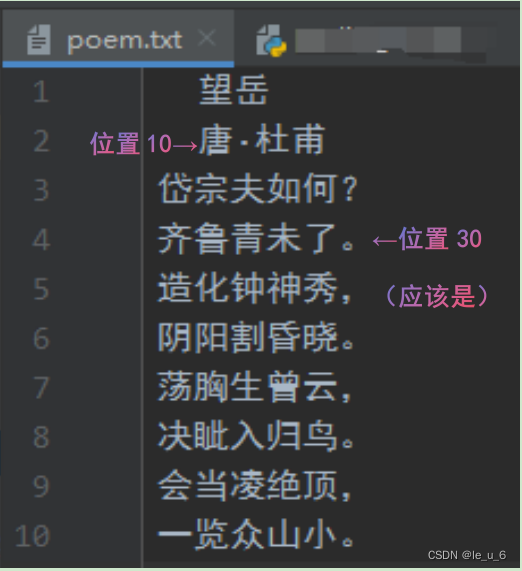
这里10大概是:一行5字+1符号+1换行,然后’唐’前我是2个空格
附录 P.S.
关于“字符、字节..”的一些百度:
1.空格: 在UTF-8编码中,一个空格字符(在 ASCII表中)占用一个字节。
2.中文字符: UTF-8 是一种可变长度的编码系统,中文字符可能占用3个字节或者更多,具体取决于字符的Unicode码点。
3.英文字符: 大多数英文字符(包括英文字母和一些基本标点符号)在 UTF-8 编码中通常占用一个字节。
4.中文标点: 中文标点符号的字节数也可能不同,一些常见的中文标点符号可能占2个或3个字节。
5.英文标点: 大多数英文标点符号,如句号(.)、逗号(,)、分号(;)等,在 UTF-8 编码中通常占用一个字节。
6.特殊字符: 一些特殊字符,如 emoji (表情)或其他非ASCII字符,可能占用更多的字节,。
总之,在处理文本时,字符计数通常是指逻辑字符的数量,而不是字节数。在UTF-8编码中,一个中文字符可能占用多个字节,但仍然被视为一个逻辑字符。同样,空格和标点符号,无论它们占用多少字节,通常每个都被视为一个逻辑字符。(如:len() 函数)来获取字符串的长度时,它返回的是逻辑字符的数量,而不是字节数。