大型人工智能模型,尤其是那些拥有千亿参数的模型,因其出色的商业应用表现而受到市场的青睐。但是,直接通过API使用这些模型可能会带来数据泄露的风险,尤其是当模型提供商如OpenAI等可能涉及数据隐私问题时。私有部署虽然是一个解决办法,但昂贵的授权费用对于许多企业来说是一笔不小的开支。Orion-14B系列模型的推出,旨在解决这一难题,提供一个既经济实惠又性能卓越的选择。
Orion-14B系列特点
Orion-14B系列模型以其百亿参数规模,在多个专业场景问题解答中超越了GPT-4等千亿参数级别的模型。更令人振奋的是,该系列模型能够在普通消费级显卡上运行,显著降低了硬件成本。
关键特性包括:
- 在20B参数规模水平的模型中,Orion-14B-Base在综合评估中表现优异。
- 强大的多语言能力,尤其在日语和韩语测试集中表现突出。
- 微调模型展现出强大的适应能力,在人工标注的盲测中表现卓越。
- 长聊天版本支持极长文本,最大支持320k令牌长度。
- 量化版本将模型大小减少70%,推理速度提高30%,性能损失不到1%。
模型系列
Orion-14B系列包括以下模型:
- Orion-14B-Base:一个具有14亿参数的多语言基础模型,预训练在2.5万亿token的多样化数据集上。
- Orion-14B-Chat:在高质量语料库上微调的聊天模型,旨在为大型模型社区的用户提供卓越的交互体验。
- Orion-14B-LongChat:长文本版本,擅长处理极长文本。
- Orion-14B-Chat-RAG:在自定义检索增强生成数据集上微调的聊天模型,检索增强生成任务中表现卓越。
- Orion-14B-Chat-Plugin:专为插件和功能调用任务量身定制的聊天模型,适用于代理相关场景。
- Orion-14B-Base-Int4:使用4位整数权重的量化基础模型。
- Orion-14B-Chat-Int4:使用4位整数权重的量化聊天模型。
模型基准测试
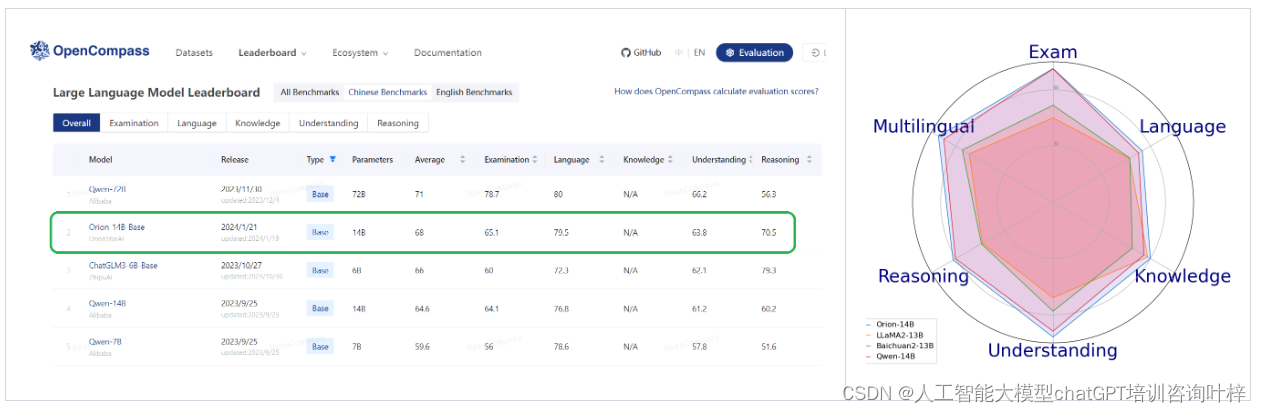
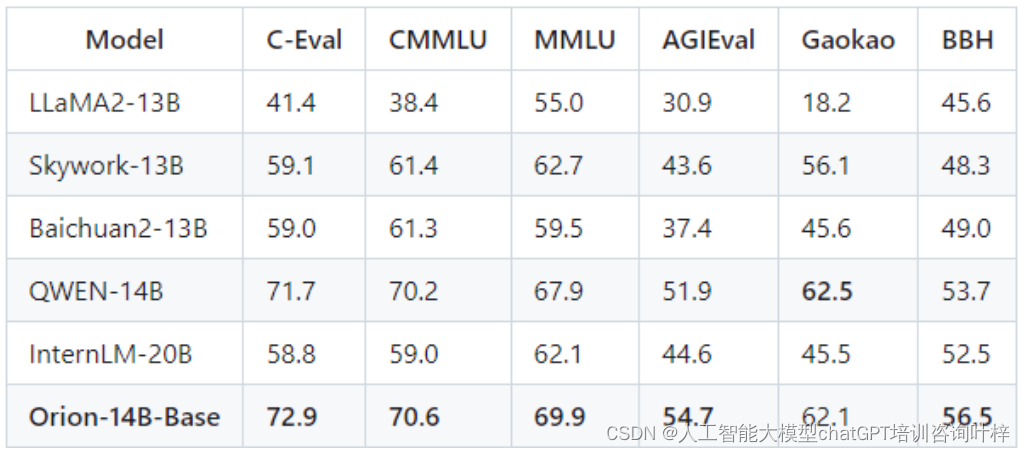
Orion-14B系列模型在专业场景问题解答方面进行了评估,测试结果表明,Orion-14B-Base模型在考试和专业知识评估上超越了其他同类模型,如GPT-4。这些评估通常包括对模型在特定领域知识的掌握程度和解答相关问题的能力进行测试。
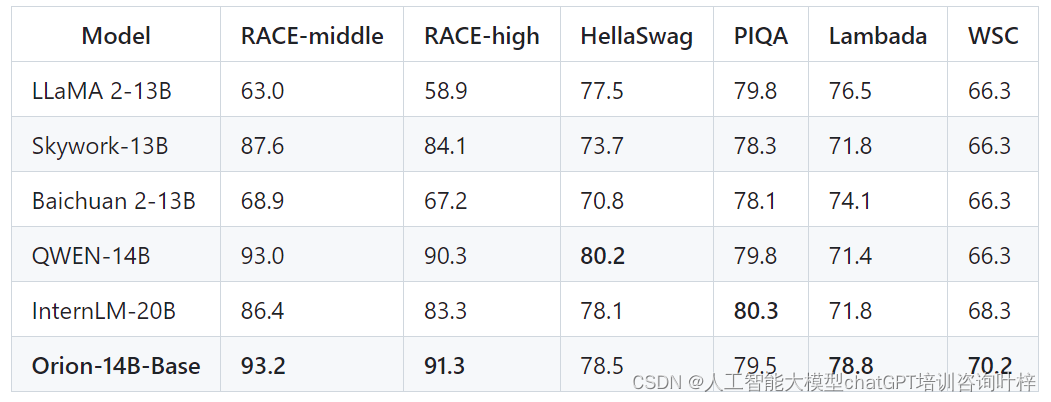
模型的语言理解能力通过诸如RACE-middle、RACE-high、HellaSwag、PIQA、Lambada、WSC等测试集进行评估。Orion-14B-Base在这些测试中表现出色,特别是在RACE-middle和RACE-high测试中,显示出模型在语言理解和常识知识方面的强大能力。
OpenCompass测试集是一系列设计用来评估语言模型在不同领域上的表现的测试。Orion-14B-Base在这些测试中同样展现了优秀的性能,证明了其在多个领域的广泛应用潜力。
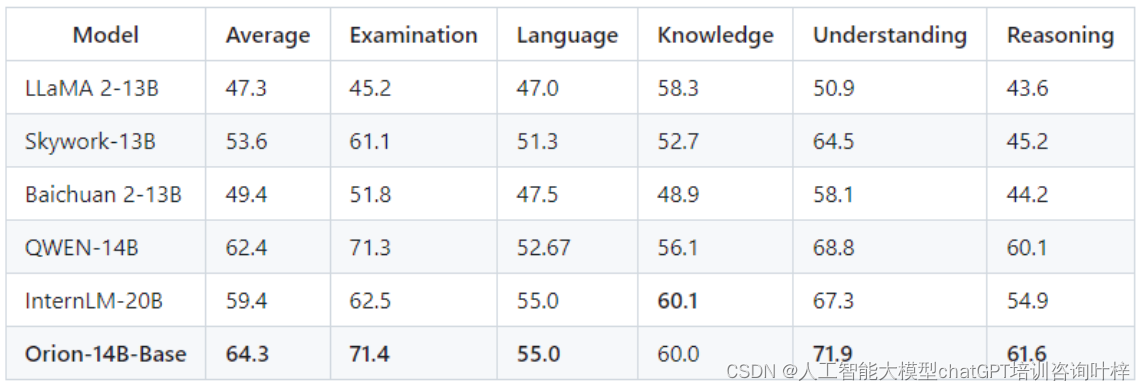
Orion-14B系列模型在多语言能力上进行了特别的优化。特别是在日语和韩语的测试集中,模型展现出了显著的性能,这表明Orion-14B系列在处理亚洲语言方面具有明显优势。
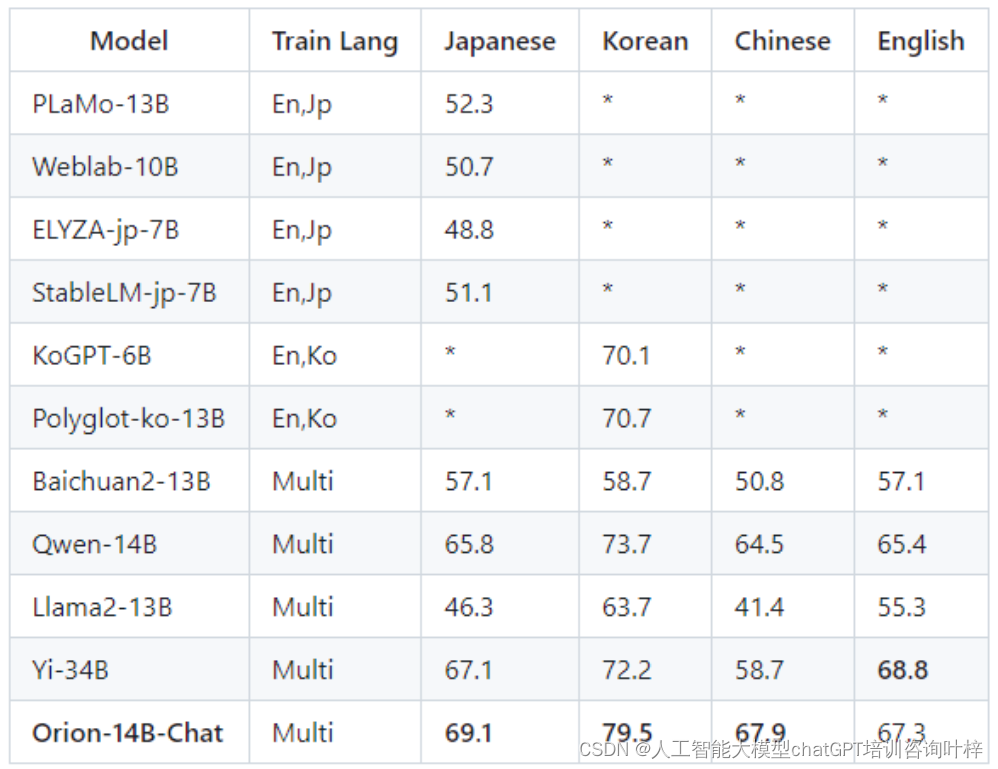
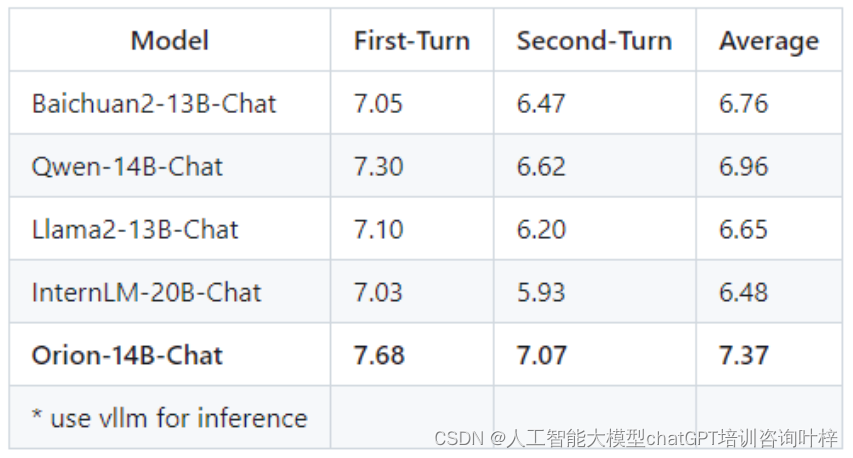
Orion-14B-Chat模型在MTBench和AlignBench等聊天模型主观评估中进行了测试。这些测试不仅关注模型的响应质量,还包括了对模型在不同领域的适应性和交互体验的评估。
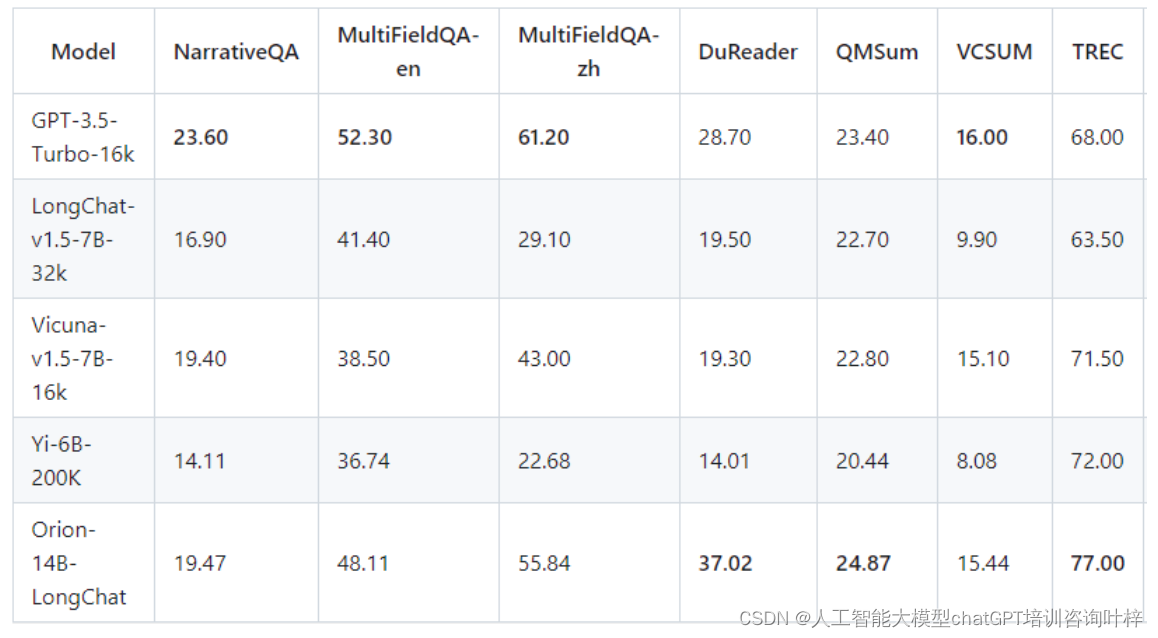
Orion-14B-LongChat模型在LongBench长聊天评估中表现出色,这表明该模型能够处理极长文本,适合需要长对话或长文本处理的应用场景。
Orion-14B-Chat-RAG模型在自定义的检索增强生成(RAG)测试集中进行了评估。这些测试旨在衡量模型在检索信息并结合生成任务中的表现,Orion-14B-Chat-RAG在这些测试中展示了其卓越的性能。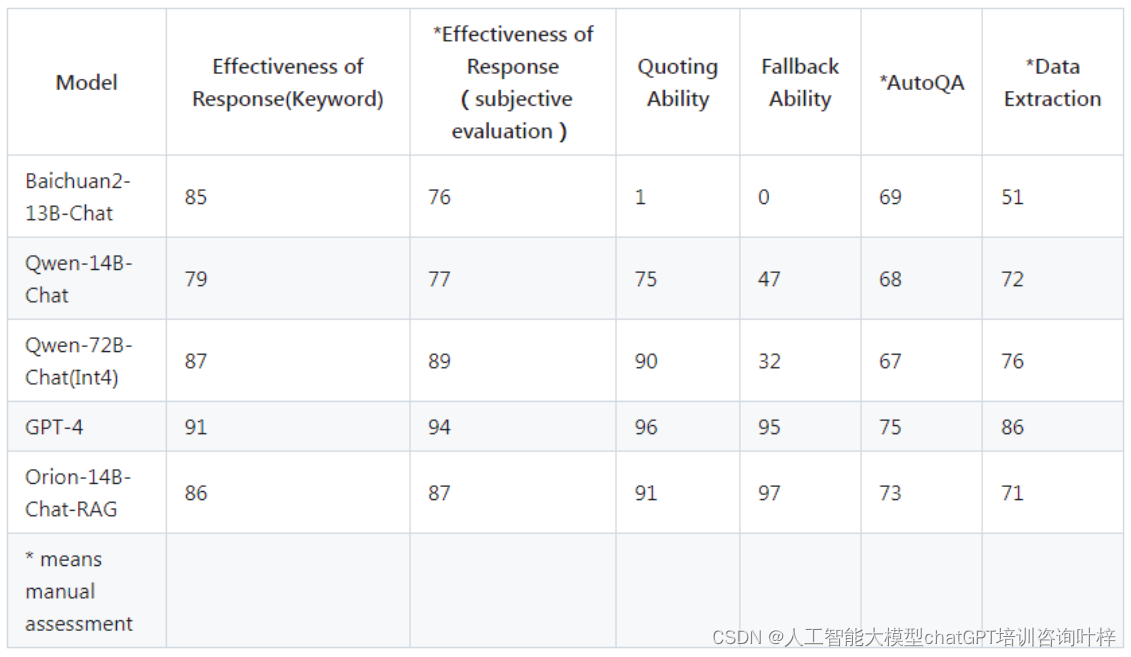
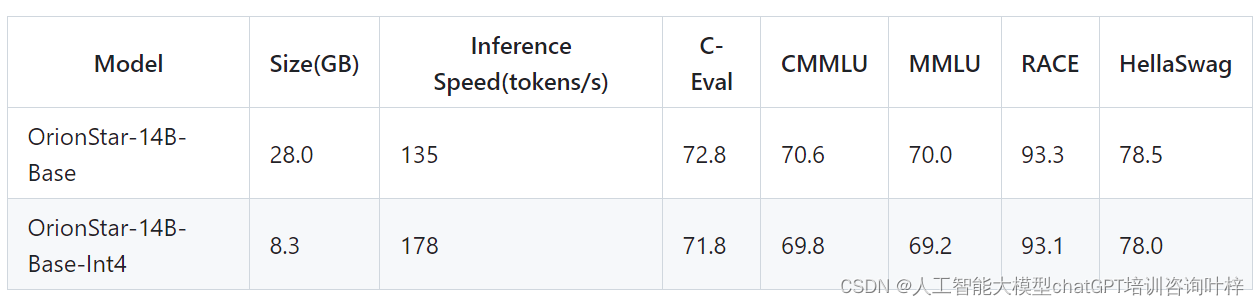
Orion-14B系列还包括了量化版本,如Orion-14B-Base-Int4,这些版本在保持性能的同时显著减少了模型大小并提高了推理速度。通过量化技术,模型能够在资源受限的环境中高效运行,同时保持较低的性能损失。
Python代码推理
Orion-14B系列模型支持通过Python代码进行直接推理。用户可以使用transformers库中的AutoModelForCausalLM和AutoTokenizer类加载模型和分词器。通过设置device_map='auto',模型可以自动利用所有可用的GPU资源进行加速。此外,通过指定torch_dtype=torch.bfloat16,可以在保持精度的同时优化内存使用和推理速度。
示例:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
messages = [{"role": "user", "content": "Hello, what is your name? "}]
response = model.chat(tokenizer, messages, streaming=False)
print(response)在这段代码中,model.chat函数用于生成模型的响应,streaming=False表示不使用流式输出。
命令行工具推理
Orion-14B系列模型还提供了命令行工具,方便用户在终端中快速进行模型推理。用户可以通过设置环境变量CUDA_VISIBLE_DEVICES来指定使用的GPU设备,然后运行命令行脚本进行推理。
示例命令如下:
CUDA_VISIBLE_DEVICES=0 python cli_demo.py这个命令行工具专为聊天场景设计,不支持调用基础模型。
直接脚本推理
用户还可以通过直接运行脚本进行模型推理。Orion-14B系列模型提供了基础模型和聊天模型的脚本示例。
基础模型推理示例命令:
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt hello聊天模型推理示例命令:
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt hi这些脚本允许用户通过命令行参数指定模型、分词器和输入提示。
vLLM推理
Orion-14B系列模型支持通过vLLM项目进行推理。vLLM是一个轻量级的推理库,可以与Orion-14B系列模型配合使用。
启动vLLM服务器的示例命令:
python -m vllm.entrypoints.openai.api_server --model OrionStarAI/Orion-14B-Chat这允许用户通过vLLM提供的API接口进行模型推理。
llama.cpp推理
Orion-14B系列模型还可以通过llama.cpp项目进行推理。llama.cpp是一个高效的推理引擎,支持多种模型格式。
用户首先需要将Hugging Face模型转换为GGUF格式,使用如下命令:
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf然后,使用llama.cpp运行生成任务,示例命令如下:
./main --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e这个命令设置了频率惩罚、top-k和top-p参数,并指定了模型文件和输入提示。
示例输出
Orion-14B系列模型的推理输出示例包括日常聊天和多语言聊天。例如,在英文聊天中,模型能够以友好和有帮助的方式回应用户的问候和提问。在日文和韩文聊天中,模型也能够以相应的语言进行流畅的对话。
这些推理方法展示了Orion-14B系列模型的灵活性和实用性,无论是通过编程接口、命令行工具还是与其他推理引擎的集成,都能够为用户提供强大且易于使用的模型推理能力。
项目链接:https://github.com/OrionStarAI/Orion


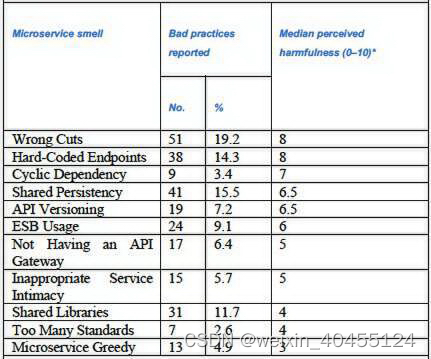


![如何在华为手机上恢复已删除的视频[4种解决方案]](https://img-blog.csdnimg.cn/img_convert/fb8b3861153f32e4f8b388f3e210cbe4.png)