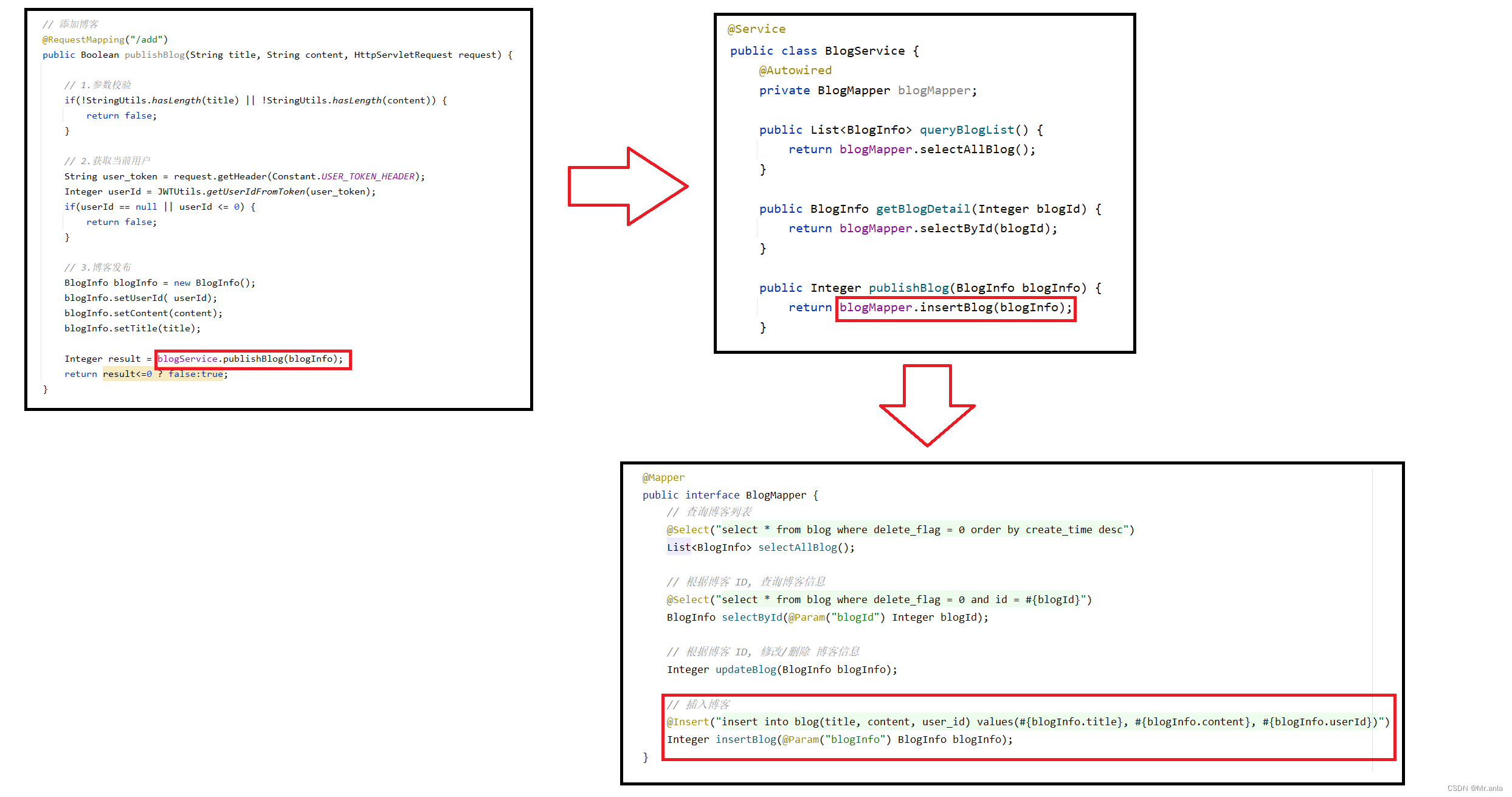
MEMORY USAGE name
import com. heima. jedis. util. JedisConnectionFactory ;
import org. junit. jupiter. api. AfterEach ;
import org. junit. jupiter. api. BeforeEach ;
import org. junit. jupiter. api. Test ;
import redis. clients. jedis. Jedis ;
import redis. clients. jedis. ScanResult ;
import java. util. HashMap ;
import java. util. List ;
import java. util. Map ;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp ( ) {
jedis = JedisConnectionFactory . getJedis ( ) ;
jedis. auth ( "123321" ) ;
jedis. select ( 0 ) ;
}
final static int STR_MAX_LEN = 10 * 1024 ;
final static int HASH_MAX_LEN = 500 ;
@Test
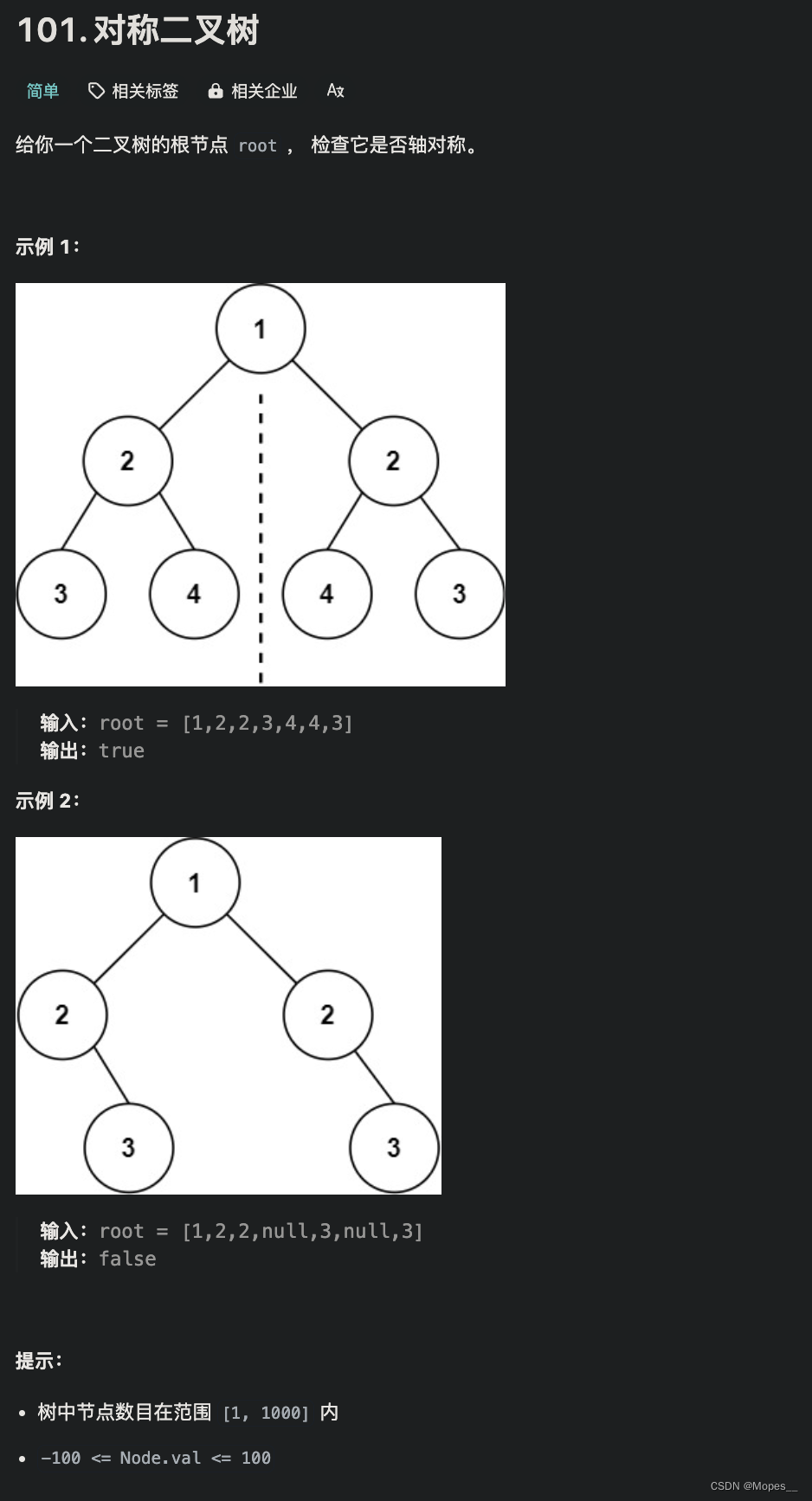
void testScan ( ) {
int maxLen = 0 ;
long len = 0 ;
String cursor = "0" ;
do {
ScanResult < String > = jedis. scan ( cursor) ;
cursor = result. getCursor ( ) ;
List < String > = result. getResult ( ) ;
if ( list == null || list. isEmpty ( ) ) {
break ;
}
for ( String key : list) {
String type = jedis. type ( key) ;
switch ( type) {
case "string" :
len = jedis. strlen ( key) ;
maxLen = STR_MAX_LEN ;
break ;
case "hash" :
len = jedis. hlen ( key) ;
maxLen = HASH_MAX_LEN ;
break ;
case "list" :
len = jedis. llen ( key) ;
maxLen = HASH_MAX_LEN ;
break ;
case "set" :
len = jedis. scard ( key) ;
maxLen = HASH_MAX_LEN ;
break ;
case "zset" :
len = jedis. zcard ( key) ;
maxLen = HASH_MAX_LEN ;
break ;
default :
break ;
}
if ( len >= maxLen) {
System . out. printf ( "Found big key : %s, type: %s, length or size: %d %n" , key, type, len) ;
}
}
} while ( ! cursor. equals ( "0" ) ) ;
}
@AfterEach
void tearDown ( ) {
if ( jedis != null ) {
jedis. close ( ) ;
}
}
}
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. data. redis. core. RedisCallback ;
import org. springframework. data. redis. core. RedisTemplate ;
import org. springframework. data. redis. connection. RedisConnection ;
import org. springframework. data. redis. connection. lettuce. LettuceConnectionFactory ;
import io. lettuce. core. api. StatefulRedisConnection ;
import io. lettuce. core. api. sync. RedisCommands ;
@Service
public class RedisPipelinedService {
@Autowired
private RedisTemplate < String , String > ;
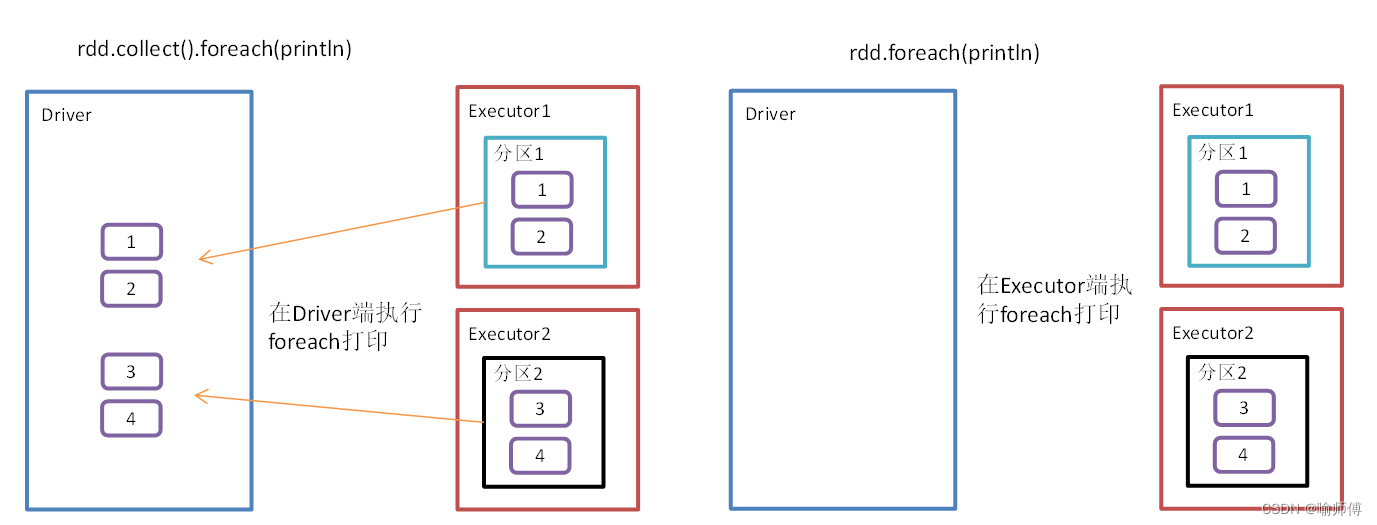
public void executePipelinedCommands ( ) {
redisTemplate. executePipelined ( ( RedisCallback < Object > ) connection -> {
RedisCommands < String , String > = connection. sync ( ) ;
commands. set ( "key1" , "value1" ) ;
commands. set ( "key2" , "value2" ) ;
return null ;
} ) ;
}
}