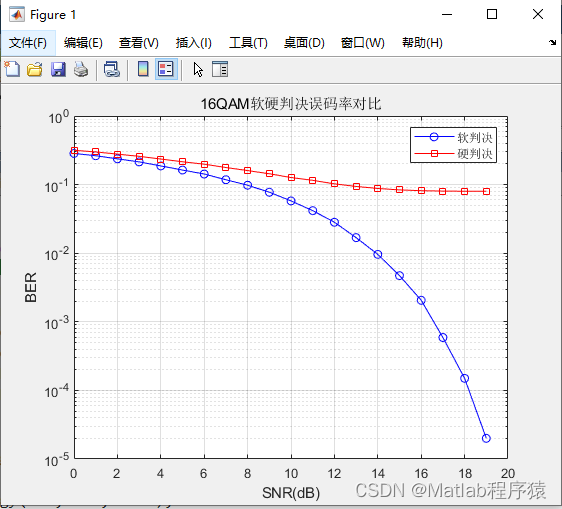
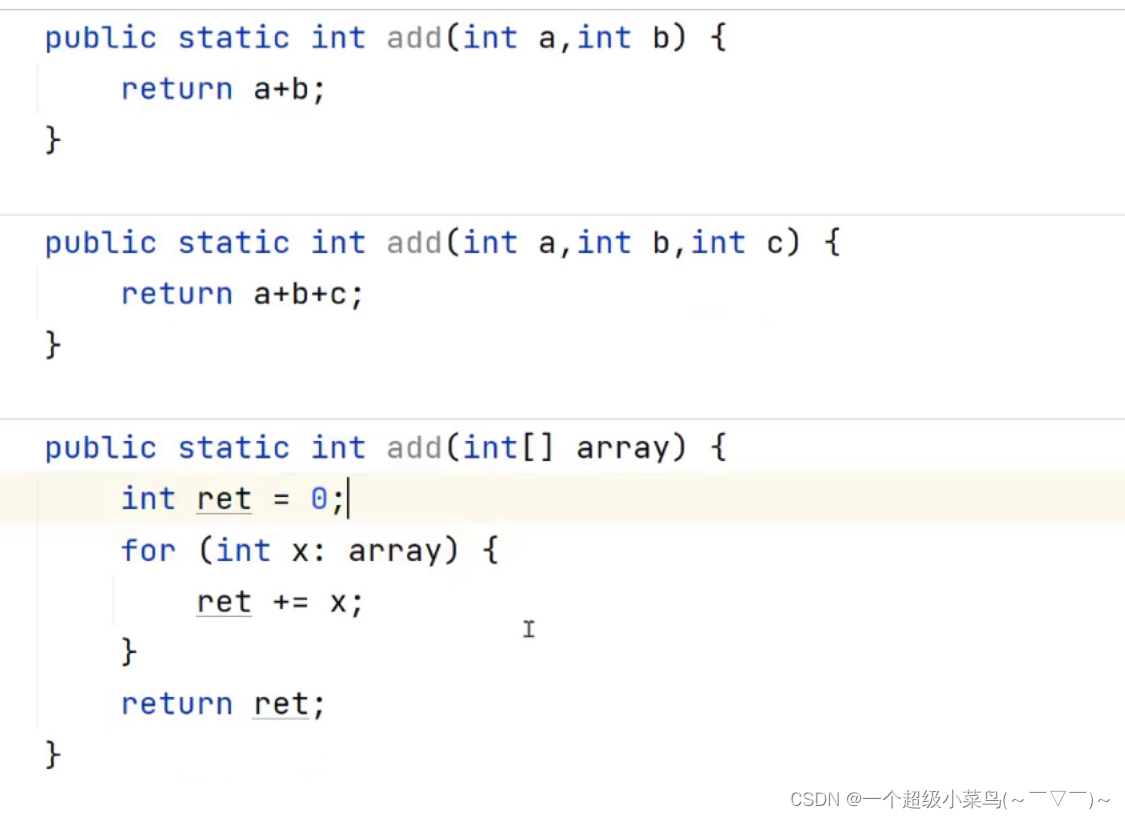
本篇是对Kaggle上Home Credit - Credit Risk Model Stability竞赛中的开源代码VotingClassifier Home Credit的解读。原链接在VotingClassifier Home Credit (kaggle.com)。
%%writefile script.py
import sys
from pathlib import Path
import subprocess
import os
import gc
from glob import glob
import numpy as np
import pandas as pd
import polars as pl
from datetime import datetime
import seaborn as sns
import matplotlib.pyplot as plt
import joblib
import warnings
warnings.filterwarnings('ignore')
ROOT = '/kaggle/input/home-credit-credit-risk-model-stability'
from sklearn.model_selection import TimeSeriesSplit, GroupKFold, StratifiedGroupKFold
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.metrics import roc_auc_score
import lightgbm as lgb
class Pipeline:
def set_table_dtypes(df):
for col in df.columns:
if col in ["case_id", "WEEK_NUM", "num_group1", "num_group2"]:
df = df.with_columns(pl.col(col).cast(pl.Int64))
elif col in ["date_decision"]:
df = df.with_columns(pl.col(col).cast(pl.Date))
elif col[-1] in ("P", "A"):
df = df.with_columns(pl.col(col).cast(pl.Float64))
elif col[-1] in ("M",):
df = df.with_columns(pl.col(col).cast(pl.String))
elif col[-1] in ("D",):
df = df.with_columns(pl.col(col).cast(pl.Date))
return df
def handle_dates(df):
for col in df.columns:
if col[-1] in ("D",):
df = df.with_columns(pl.col(col) - pl.col("date_decision")) #!!?
df = df.with_columns(pl.col(col).dt.total_days()) # t - t-1
df = df.drop("date_decision", "MONTH")
return df
def filter_cols(df):
for col in df.columns:
if (col not in ["target", "case_id", "WEEK_NUM"]) & (df[col].dtype == pl.String):
freq = df[col].n_unique()
if (freq == 1) | (freq > 200):
df = df.drop(col)
return df
class Aggregator:
#Please add or subtract features yourself, be aware that too many features will take up too much space.
def num_expr(df):
cols = [col for col in df.columns if col[-1] in ("P", "A")]
expr_max = [pl.max(col).alias(f"max_{col}") for col in cols]
return expr_max
def date_expr(df):
cols = [col for col in df.columns if col[-1] in ("D")]
expr_max = [pl.max(col).alias(f"max_{col}") for col in cols]
return expr_max
def str_expr(df):
cols = [col for col in df.columns if col[-1] in ("M",)]
expr_max = [pl.max(col).alias(f"max_{col}") for col in cols]
return expr_max
def other_expr(df):
cols = [col for col in df.columns if col[-1] in ("T", "L")]
expr_max = [pl.max(col).alias(f"max_{col}") for col in cols]
return expr_max
def count_expr(df):
cols = [col for col in df.columns if "num_group" in col]
expr_max = [pl.max(col).alias(f"max_{col}") for col in cols]
return expr_max
def get_exprs(df):
exprs = Aggregator.num_expr(df) + \
Aggregator.date_expr(df) + \
Aggregator.str_expr(df) + \
Aggregator.other_expr(df) + \
Aggregator.count_expr(df)
return exprs
def read_file(path, depth=None):
df = pl.read_parquet(path)
df = df.pipe(Pipeline.set_table_dtypes)
if depth in [1,2]:
df = df.group_by("case_id").agg(Aggregator.get_exprs(df))
return df
def read_files(regex_path, depth=None):
chunks = []
for path in glob(str(regex_path)):
df = pl.read_parquet(path)
df = df.pipe(Pipeline.set_table_dtypes)
if depth in [1, 2]:
df = df.group_by("case_id").agg(Aggregator.get_exprs(df))
chunks.append(df)
df = pl.concat(chunks, how="vertical_relaxed")
df = df.unique(subset=["case_id"])
return df
def feature_eng(df_base, depth_0, depth_1, depth_2):
df_base = (
df_base
.with_columns(
month_decision = pl.col("date_decision").dt.month(),
weekday_decision = pl.col("date_decision").dt.weekday(),
)
)
for i, df in enumerate(depth_0 + depth_1 + depth_2):
df_base = df_base.join(df, how="left", on="case_id", suffix=f"_{i}")
df_base = df_base.pipe(Pipeline.handle_dates)
return df_base
def to_pandas(df_data, cat_cols=None):
df_data = df_data.to_pandas()
if cat_cols is None:
cat_cols = list(df_data.select_dtypes("object").columns)
df_data[cat_cols] = df_data[cat_cols].astype("category")
return df_data, cat_cols
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtype
if str(col_type)=="category":
continue
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
continue
end_mem = df.memory_usage().sum() / 1024**2
return df
ROOT = Path("/kaggle/input/home-credit-credit-risk-model-stability")
TRAIN_DIR = ROOT / "parquet_files" / "train"
TEST_DIR = ROOT / "parquet_files" / "test"
data_store = {
"df_base": read_file(TRAIN_DIR / "train_base.parquet"),
"depth_0": [
read_file(TRAIN_DIR / "train_static_cb_0.parquet"),
read_files(TRAIN_DIR / "train_static_0_*.parquet"),
],
"depth_1": [
read_files(TRAIN_DIR / "train_applprev_1_*.parquet", 1),
read_file(TRAIN_DIR / "train_tax_registry_a_1.parquet", 1),
read_file(TRAIN_DIR / "train_tax_registry_b_1.parquet", 1),
read_file(TRAIN_DIR / "train_tax_registry_c_1.parquet", 1),
read_files(TRAIN_DIR / "train_credit_bureau_a_1_*.parquet", 1),
read_file(TRAIN_DIR / "train_credit_bureau_b_1.parquet", 1),
read_file(TRAIN_DIR / "train_other_1.parquet", 1),
read_file(TRAIN_DIR / "train_person_1.parquet", 1),
read_file(TRAIN_DIR / "train_deposit_1.parquet", 1),
read_file(TRAIN_DIR / "train_debitcard_1.parquet", 1),
],
"depth_2": [
read_file(TRAIN_DIR / "train_credit_bureau_b_2.parquet", 2),
]
}
df_train = feature_eng(**data_store)
del data_store
gc.collect()
df_train = df_train.pipe(Pipeline.filter_cols)
df_train, cat_cols = to_pandas(df_train)
df_train = reduce_mem_usage(df_train)
nums=df_train.select_dtypes(exclude='category').columns
from itertools import combinations, permutations
nans_df = df_train[nums].isna()
nans_groups={}
for col in nums:
cur_group = nans_df[col].sum()
try:
nans_groups[cur_group].append(col)
except:
nans_groups[cur_group]=[col]
del nans_df; x=gc.collect()
def reduce_group(grps):
use = []
for g in grps:
mx = 0; vx = g[0]
for gg in g:
n = df_train[gg].nunique()
if n>mx:
mx = n
vx = gg
use.append(vx)
return use
def group_columns_by_correlation(matrix, threshold=0.8):
correlation_matrix = matrix.corr()
groups = []
remaining_cols = list(matrix.columns)
while remaining_cols:
col = remaining_cols.pop(0)
group = [col]
correlated_cols = [col]
for c in remaining_cols:
if correlation_matrix.loc[col, c] >= threshold:
group.append(c)
correlated_cols.append(c)
groups.append(group)
remaining_cols = [c for c in remaining_cols if c not in correlated_cols]
return groups
uses=[]
for k,v in nans_groups.items():
if len(v)>1:
Vs = nans_groups[k]
grps= group_columns_by_correlation(df_train[Vs], threshold=0.8)
use=reduce_group(grps)
uses=uses+use
else:
uses=uses+v
df_train=df_train[uses]
data_store = {
"df_base": read_file(TEST_DIR / "test_base.parquet"),
"depth_0": [
read_file(TEST_DIR / "test_static_cb_0.parquet"),
read_files(TEST_DIR / "test_static_0_*.parquet"),
],
"depth_1": [
read_files(TEST_DIR / "test_applprev_1_*.parquet", 1),
read_file(TEST_DIR / "test_tax_registry_a_1.parquet", 1),
read_file(TEST_DIR / "test_tax_registry_b_1.parquet", 1),
read_file(TEST_DIR / "test_tax_registry_c_1.parquet", 1),
read_files(TEST_DIR / "test_credit_bureau_a_1_*.parquet", 1),
read_file(TEST_DIR / "test_credit_bureau_b_1.parquet", 1),
read_file(TEST_DIR / "test_other_1.parquet", 1),
read_file(TEST_DIR / "test_person_1.parquet", 1),
read_file(TEST_DIR / "test_deposit_1.parquet", 1),
read_file(TEST_DIR / "test_debitcard_1.parquet", 1),
],
"depth_2": [
read_file(TEST_DIR / "test_credit_bureau_b_2.parquet", 2),
]
}
df_test = feature_eng(**data_store)
del data_store
gc.collect()
df_test = df_test.select([col for col in df_train.columns if col != "target"])
df_test, cat_cols = to_pandas(df_test)
df_test = reduce_mem_usage(df_test)
gc.collect()
df_train['target']=0
df_test['target']=1
df_train=pd.concat([df_train,df_test])
df_train=reduce_mem_usage(df_train)
y = df_train["target"]
df_train= df_train.drop(columns=["target", "case_id", "WEEK_NUM"])
joblib.dump((df_train,y,df_test),'data.pkl')

导入必要的库:代码开始部分导入了多个Python库,包括用于数据处理的NumPy、Pandas、Polars,以及用于可视化的Seaborn、Matplotlib等。
![]()
设置警告过滤器:使用warnings.filterwarnings('ignore')来忽略警告信息,这在处理大型数据集时很常见。

定义数据路径:设置ROOT变量,指向包含输入数据的目录。
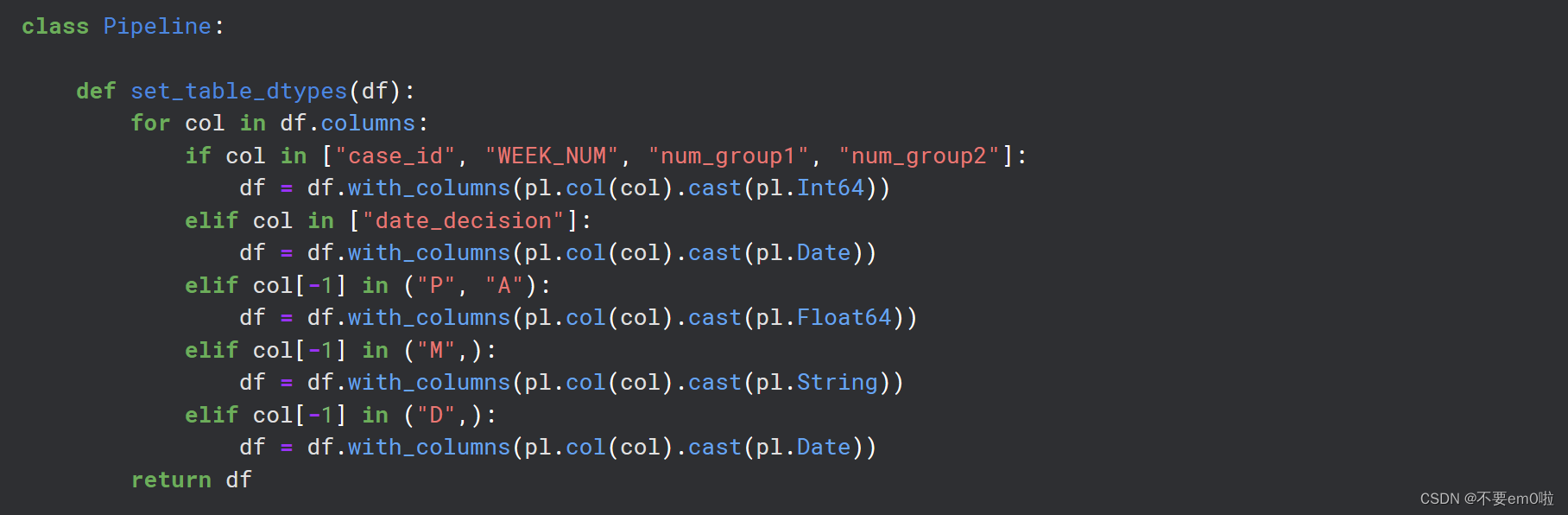
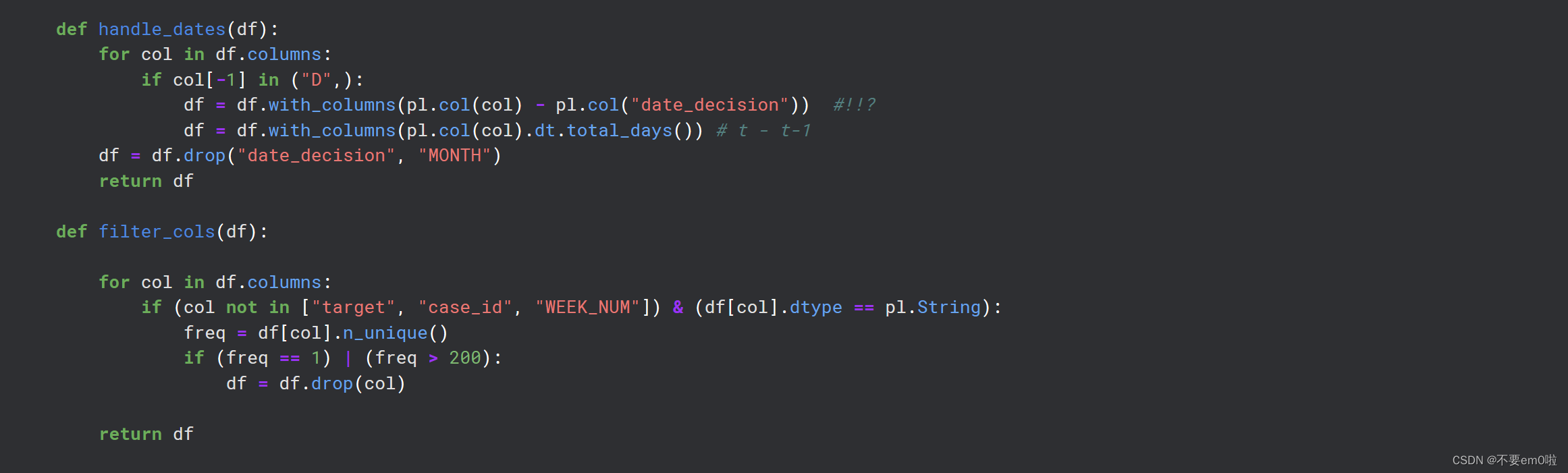
定义Pipeline类:这个类包含几个静态方法,用于设置数据类型、处理日期列和过滤列。
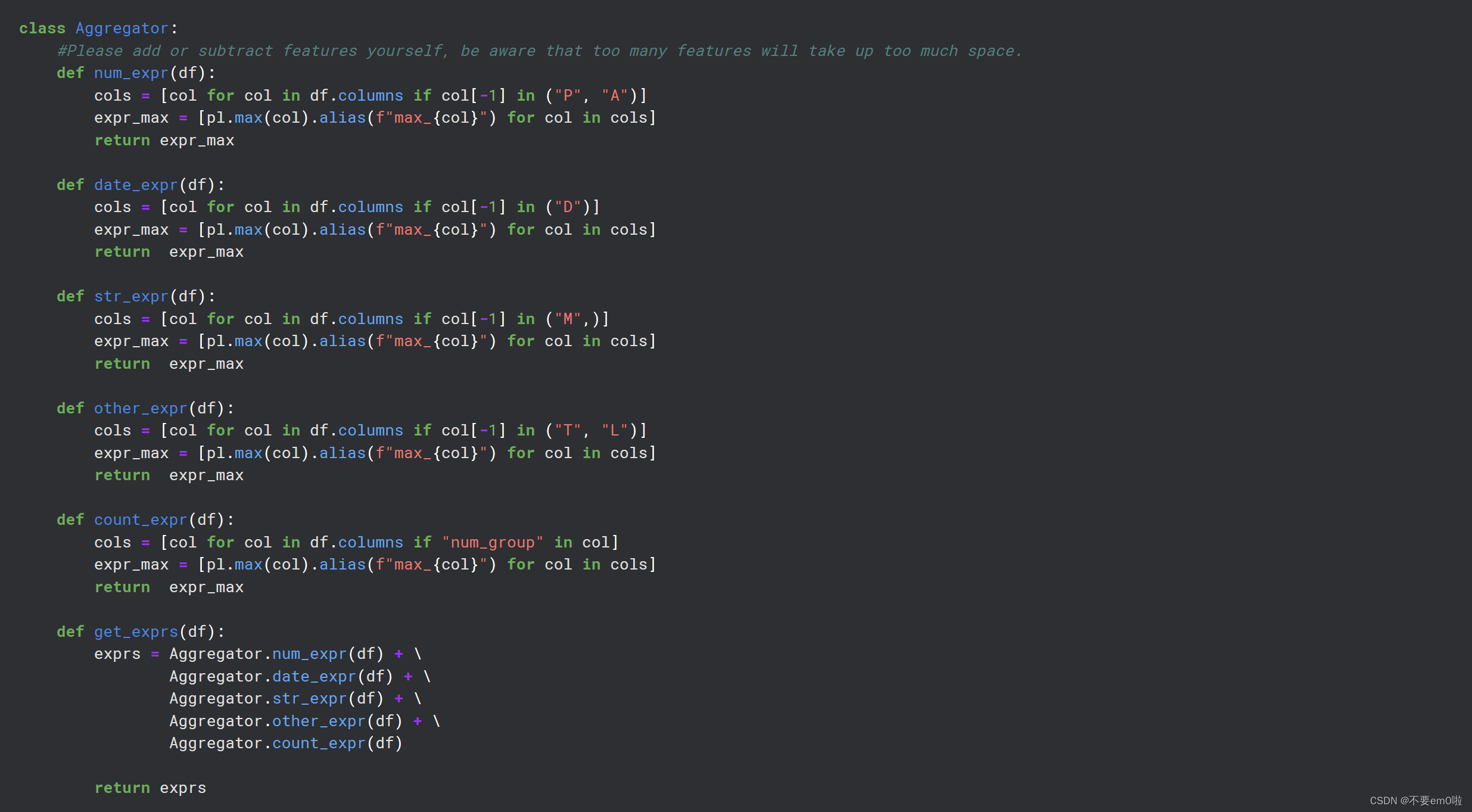
定义Aggregator类:这个类包含多个静态方法,用于聚合数据,如计算最大值等。
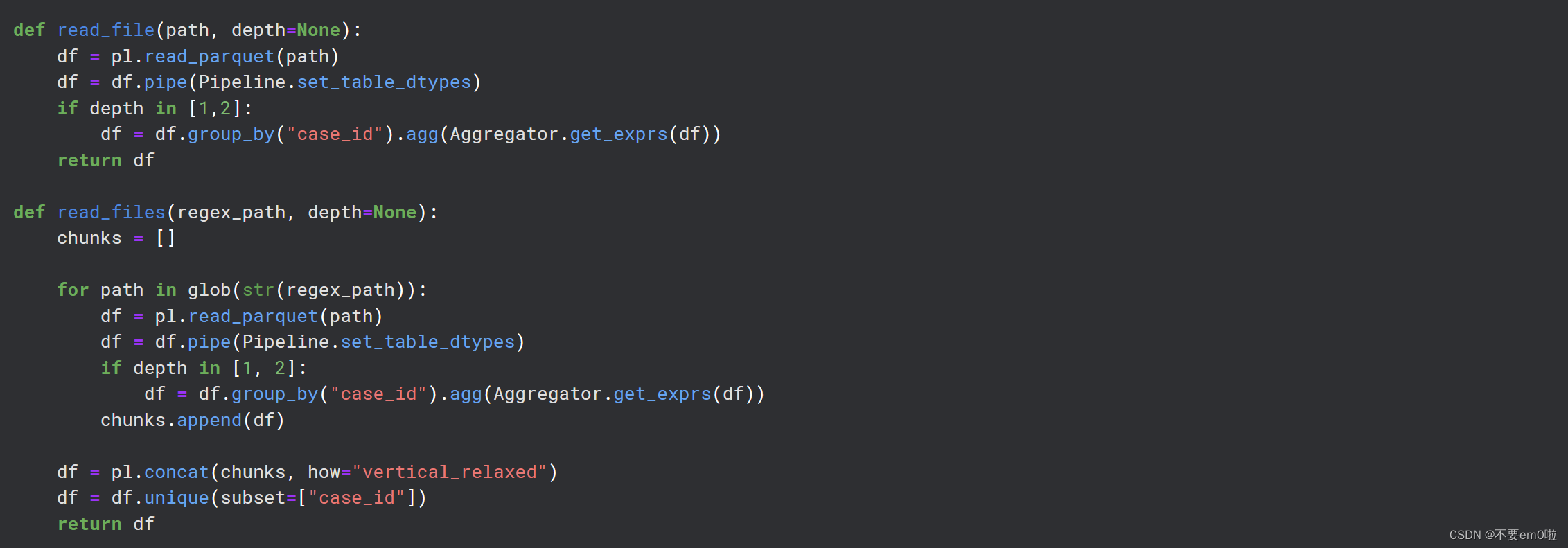
定义数据读取函数:read_file和read_files函数用于读取Parquet格式的文件,并将它们转换为Polars DataFrame。
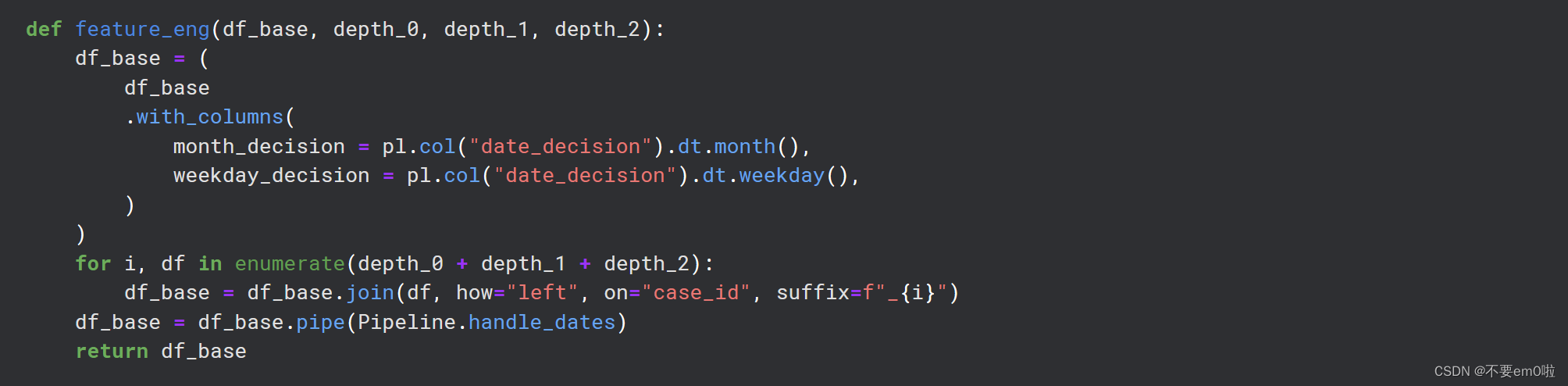
特征工程:feature_eng函数用于添加新特征,如决策月份和星期几等。

转换为Pandas DataFrame:to_pandas函数用于将Polars DataFrame转换为Pandas DataFrame,并优化内存使用。
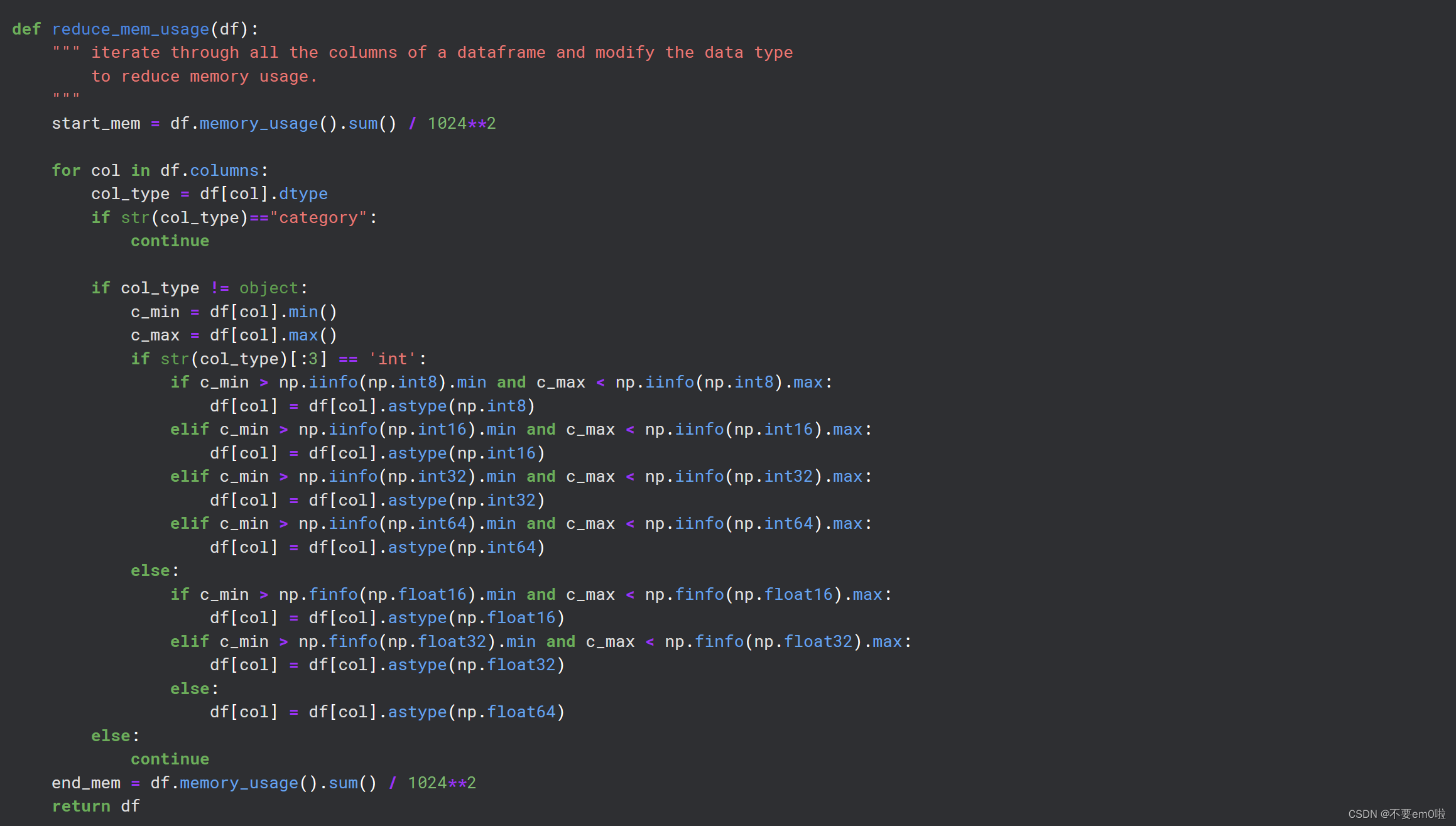
内存优化:reduce_mem_usage函数用于减少DataFrame的内存占用,通过将数据类型转换为更小的类型。
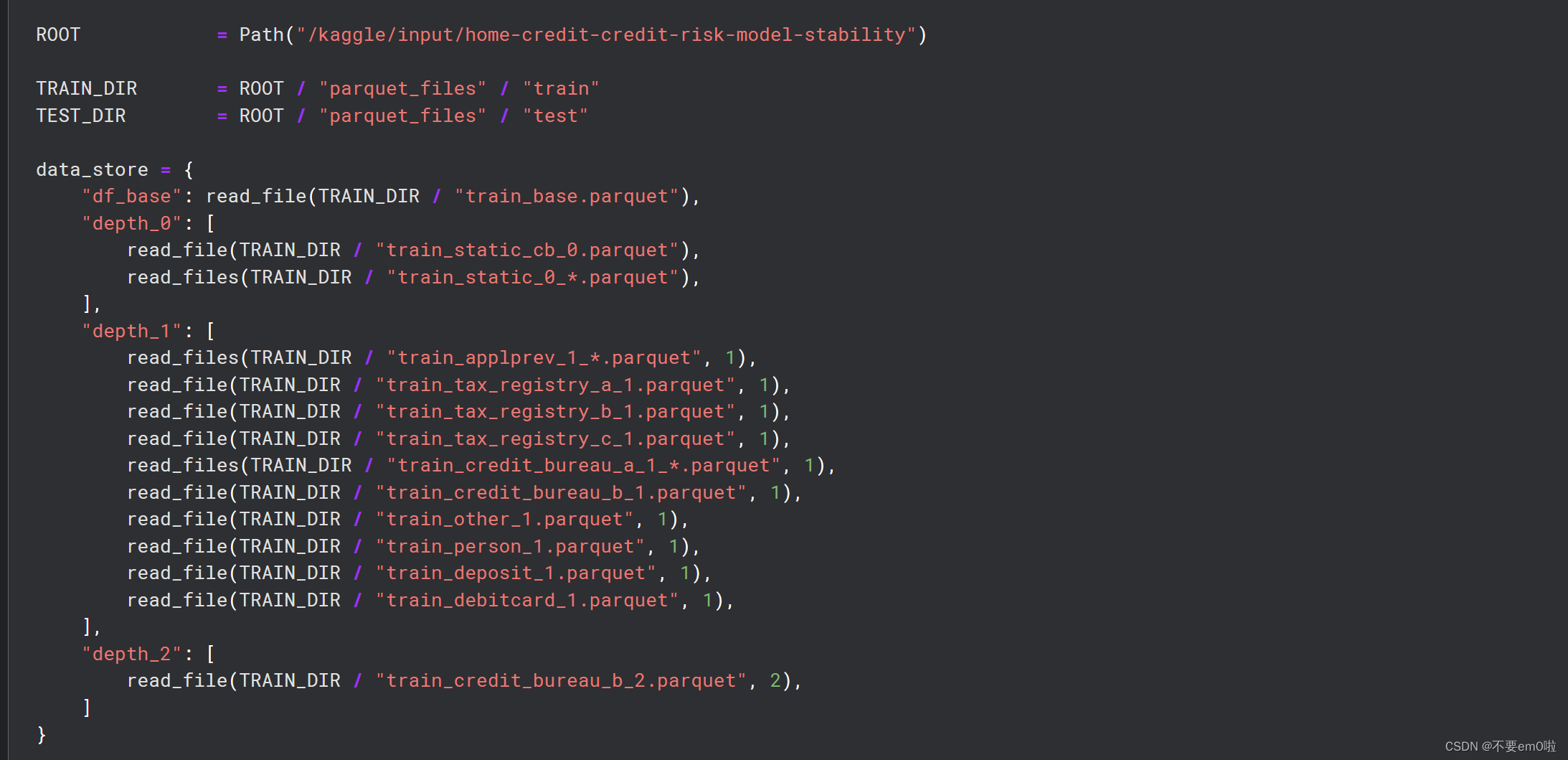

读取和处理训练数据:代码读取训练数据文件,应用特征工程,并进行内存优化。代码通过分析缺失值的模式,决定哪些列是有用的,并据此过滤列。
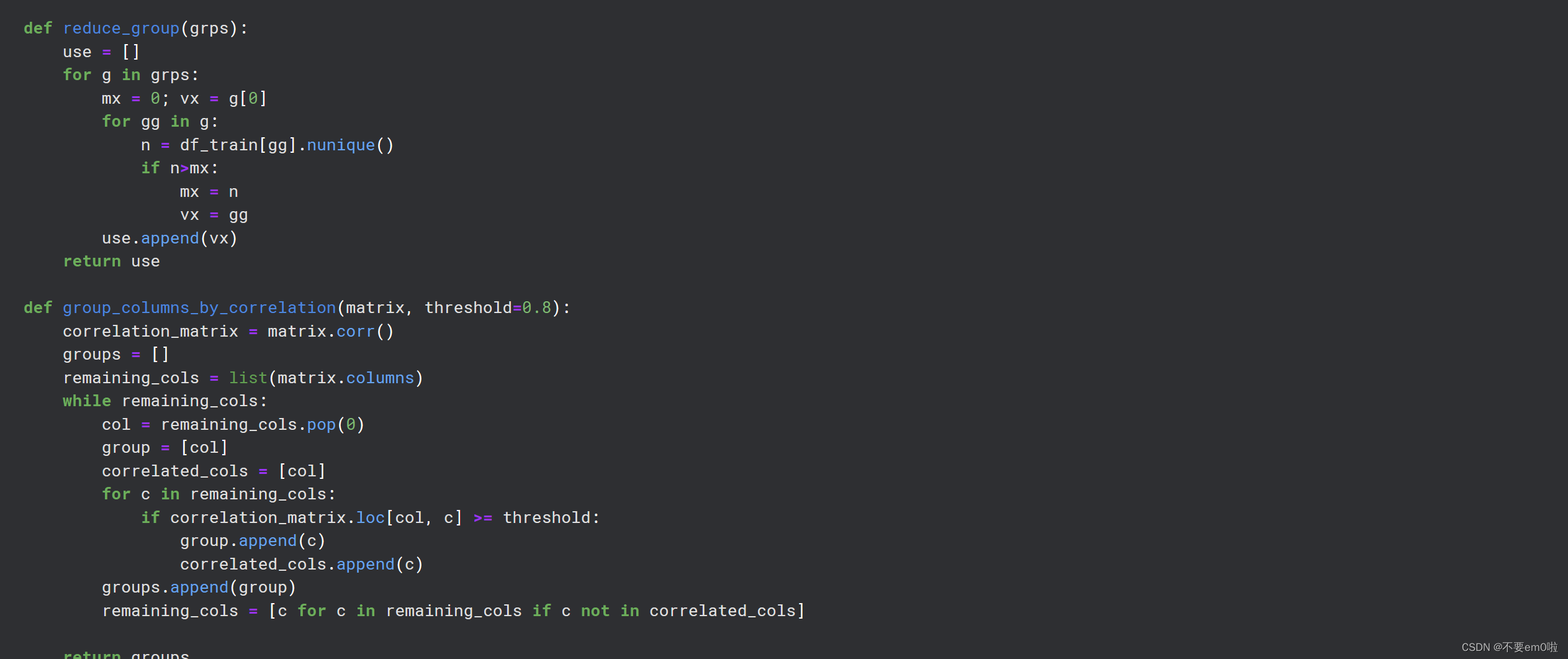
基于相关性分组列:group_columns_by_correlation函数用于基于列之间的相关性将它们分组。
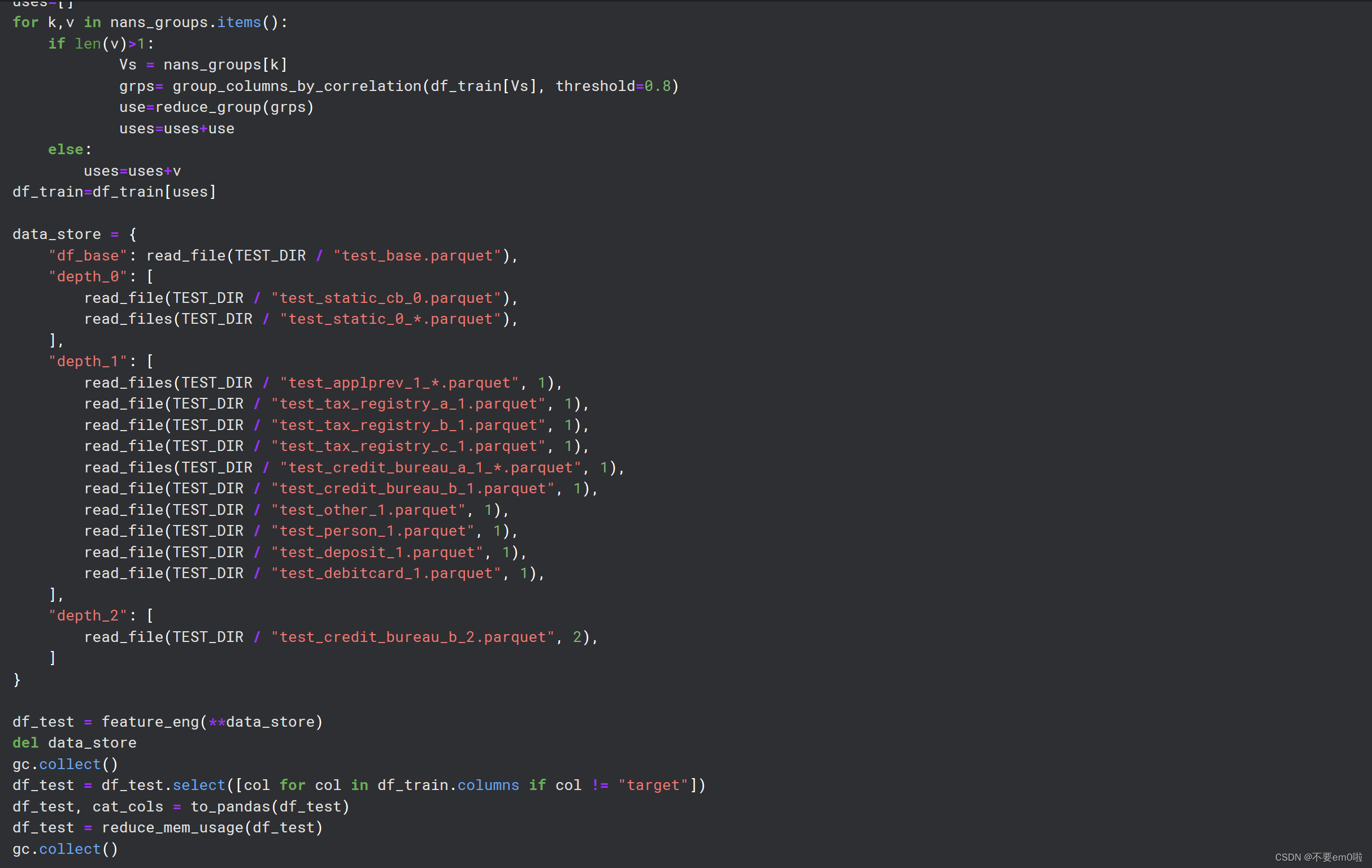

读取、处理和保存测试数据:类似地,读取测试数据文件,应用特征工程,并进行内存优化。设置目标变量,并将训练数据和测试数据合并。最后,使用joblib.dump将处理后的训练数据、测试数据和目标变量保存到一个文件中。