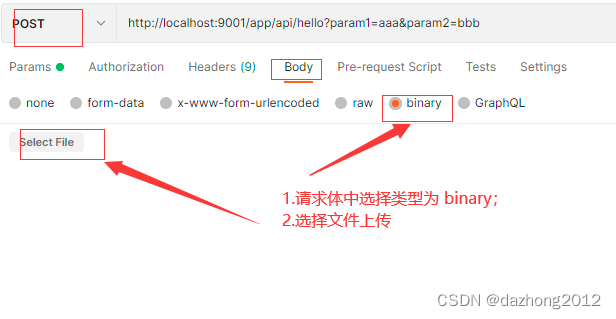
我们今天总结下2024年5月发表的最重要的论文,重点介绍了计算机视觉领域的最新研究和进展,包括扩散模型、视觉语言模型、图像编辑和生成、视频处理和生成以及图像识别等各个主题。
Diffusion Models
1、Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
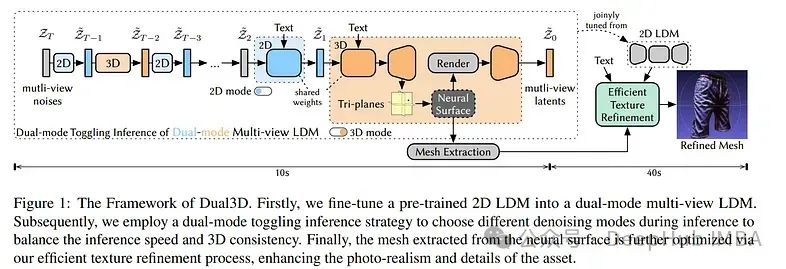
Dual3D是一个新的文本到3D生成框架,可以在1分钟内从文本生成高质量的3D图像。
为了克服推理过程中的高渲染成本,Dual3D提出了双模式切换推理策略,在3D模式下仅使用1/10的去噪步骤,在不牺牲质量的情况下仅在10秒内成功生成3D图像。
然后通过高效的纹理细化过程,可以在短时间内进一步增强3D资产的纹理。大量的实验表明,论文的方法提供了最先进的性能,同时显着减少了生成时间。
https://dual3d.github.io/
2、CAT3D: Create Anything in 3D with Multi-View Diffusion Models

3D重建的进步使高质量的3D捕获成为可能,但需要用户收集数百到数千张图像来创建3D场景。
而CAT3D,可以通过多视图扩散模型模拟真实世界的捕获过程来创建3D中的任何东西。给定任意数量的输入图像和一组目标视点,模型可以生成高度一致的场景。
这些生成的视图可以用作强大的3D重建技术的输入,以产生可以从任何视点实时呈现的3D表示。CAT3D可以在短短一分钟内创建整个3D场景,并且优于现有的单图像和少样本3D场景创建方法。
https://cat3d.github.io/
3、Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding

Hunyuan-DiT是一个文本到图像的扩散transformer ,具有对英语和汉语的细粒度理解。精心设计了transformer 结构、文本编码器和位置编码。
论文还从头开始构建一个完整的数据管道来更新和评估迭代模型优化的数据。对于细粒度的语言理解,训练了一个多模态大语言模型来改进图像的说明文字。
最后,Hunyuan-DiT可以与用户进行多回合多模态对话,根据上下文生成和提炼图像。与其他开源模型相比,浑源- dit通过拥有50多名专业评估人员的全面人工评估协议,在中文到图像生成方面达到了新的水平。
https://arxiv.org/abs/2405.08748
4、Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
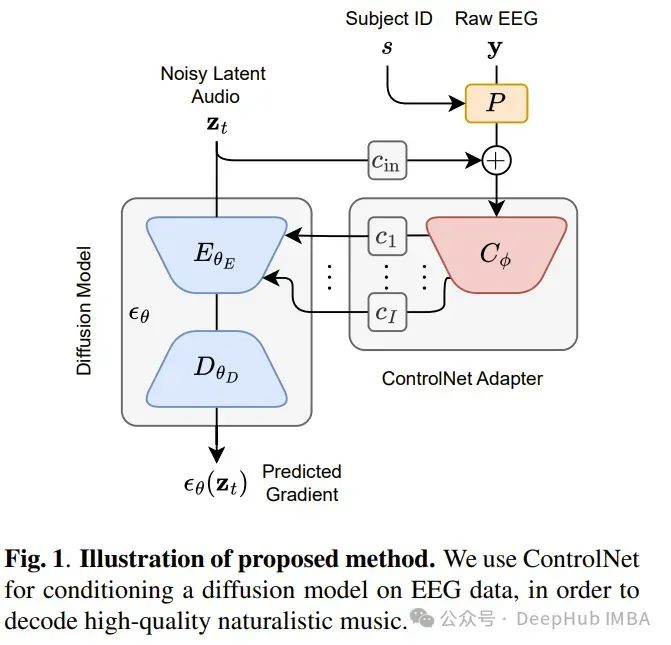
论文用于从脑电图(EEG)记录中重建自然主义音乐的任务,这个听着有些离奇
论文的研究首次尝试使用非侵入性脑电图数据实现高质量的一般音乐重建,直接在原始数据上采用端到端训练方法,无需手动预处理和通道选择。
不同于音色有限的简单音乐,如midi生成的曲调或单声部作品,这里的重点是复杂的音乐,具有多种乐器,人声和效果,丰富的谐波和音色。在公共NMED-T数据集上训练模型,并提出基于神经嵌入的指标进行定量评估。
这个的工作有助于神经解码和脑机接口的持续研究,为使用脑电图数据进行复杂听觉信息重建的可行性提供了见解。
https://arxiv.org/abs/2405.09062
视觉语言模型(VLMs)
1、What matters when building vision-language models?

对视觉语言模型(vlm)日益增长的研究是由大型语言模型和VIT的改进所驱动的。尽管在这个主题上有大量的文献,但论文观察到,关于vlm设计的关键决策通常是不合理的。
这些不受支持的决策阻碍了该领域的进展,因为很难确定哪些选择可以提高模型的性能。为了解决这个问题,论文围绕预训练模型、架构选择、数据和训练方法进行了广泛的实验。
研究成果包括Idefics2的开发,这是一个具有80亿个参数的高效基础VLM。Idefics2在不同的多模式基准测试中,在其尺寸类别中实现了最先进的性能,并且通常与尺寸为其四倍的模型相当。
https://arxiv.org/abs/2405.02246
2、Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
Xmodel-VLM是一个前沿的多模态视觉语言模型。它是为在消费级GPU服务器上高效部署而设计的。
通过严格的训练,从头开始开发了一个1b级的语言模型,使用LLaVA范式进行模态对齐,得到了一个轻量级但功能强大的多模态视觉语言模型。
在许多经典的多模态基准测试中进行的广泛测试表明,尽管Xmodel-VLM的尺寸更小,执行速度更快,但其性能可与大型模型相媲美。
https://arxiv.org/abs/2405.09215
图像生成与编辑
1、Compositional Text-to-Image Generation with Dense Blob Representations

现有的文本到图像模型难以遵循复杂的文本提示,因此需要额外的接地输入以获得更好的可控性。论文建议将场景分解为视觉原语:表示为密集的blob表示-包含场景的细粒度细节,同时是模块化的,人类可解释的,并且易于构建。
基于blob表示,开发了一个基于blob的文本到图像扩散模型,称为BlobGEN,用于合成生成,并且引入了一个新的掩码交叉注意力模块来解决blob表示和视觉特征之间的融合问题。
为了利用大型语言模型(llm)的组合性,引入了一种新的上下文学习方法来从文本提示生成blob表示。
大量实验表明,BlobGEN在MS-COCO上实现了优越的零样本生成质量和更好的布局制导可控性。当通过llm增强时,我们的方法在合成图像生成基准上显示出优越的数值和空间正确性。
https://blobgen-2d.github.io/
目标检测
1、Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection
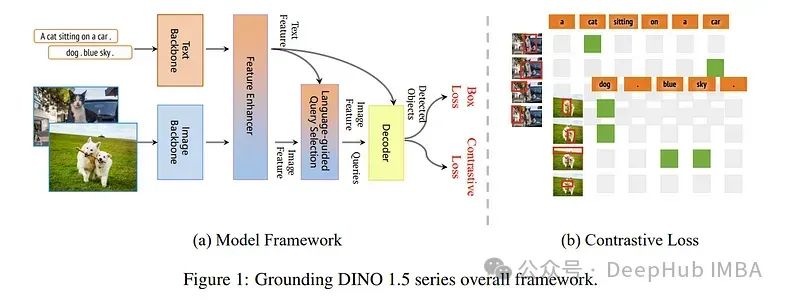
论文介绍了IDEA Research开发的一套先进的开集目标检测模型——ground DINO 1.5,该模型旨在推进开集目标检测的“边缘”。
该套件包括两种模型:Grounding DINO 1.5 Pro,一种高性能模型,在广泛的场景中具有更强的泛化能力;Grounding DINO 1.5 Edge,一种高效模型,针对许多需要边缘部署的应用所需的更快速度进行了优化。
Grounding DINO 1.5 Pro模型通过扩展模型架构,集成增强的视觉骨干,并将训练数据集扩展到超过2000万张带有注释的图像,从而实现更丰富的语义理解,从而改进了其前身。
Grounding DINO 1.5 Edge模型虽然是为降低特征尺度的效率而设计的,但通过在相同的综合数据集上进行训练,保持了强大的检测能力。
实验结果证明了DINO 1.5的有效性,DINO 1.5 Pro模型在COCO检测基准上达到了54.3 AP,在LVIS-minival零样本基准上达到了55.7 AP,创造了目标检测的新记录。
ground DINO 1.5 Edge模型在使用TensorRT进行优化后,在lis -minival基准测试中达到了75.2 FPS的速度,同时达到了36.2 AP的零样本性能,使其更适合边缘计算场景。
https://avoid.overfit.cn/post/f3bbe390f1024ab68fa6f16e44d1305a