一、什么是查找表?
1.1 定义
查找表是由同一类型的数据元素构成的集合。例如电话号码簿和字典都可以看作是一张查找表。
1.2 查找表的几种操作:
1)在查找表中查找某个具体的数据元素;
2)在查找表中插入数据元素;
3)从查找表中删除数据元素;
1.3 静态查找表和动态查找表
在查找表中只做查找操作,而不改动表中数据元素,称此类查找表为静态查找表;反之,在查找表中做查找操作的同时进行插入数据或者删除数据的操作,称此类表为动态查找表。
1.4 关键字
在查找表查找某个特定元素时,前提是需要知道这个元素的一些属性。例如,每个人上学的时候都会有自己唯一的学号,因为你的姓名、年龄都有可能和其他人是重复的,唯独学号不会重复。而学生具有的这些属性(学号、姓名、年龄等)都可以称为关键字。
关键字又细分为主关键字和次关键字。若某个关键字可以唯一地识别一个数据元素时,称这个关键字为主关键字,例如学生的学号就具有唯一性;反之,像学生姓名、年龄这类的关键字,由于不具有唯一性,称为次关键字。
二、查找算法详解和实例
用关键字标识一个数据元素,查找时根据给定的某个值,在表中确定一个关键字的值等于给定值的记录或数据元素。在计算机中进行查找的方法是根据表中的记录的组织结构确定的。
2.1 顺序查找
顺序查找也称为线形查找,从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
c语言代码实例:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int key;//查找表中每个数据元素的值
//如果需要,还可以添加其他属性
}ElemType;
typedef struct{
ElemType *elem;//存放查找表中数据元素的数组
int length;//记录查找表中数据的总数量
}SSTable;
//创建查找表
void create(SSTable **st,int length){
(*st)=(SSTable*)malloc(sizeof(SSTable));
(*st)->length=length;
(*st)->elem =(ElemType*)malloc((length+1)*sizeof(ElemType));
printf("输入表中的数据元素:\n");
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
for (int i=1; i<=length; i++) {
scanf("%d", &((*st)->elem[i].key));
}
}
//查找表查找的功能函数,其中key为关键字
int search_seq(SSTable *st,int key){
st->elem[0].key=key;//将关键字作为一个数据元素存放到查找表的第一个位置,起监视哨的作用
int i=st->length;
//从查找表的最后一个数据元素依次遍历,一直遍历到数组下标为0
while (st->elem[i].key!=key) {
i--;
}
//如果 i=0,说明查找失败;反之,返回的是含有关键字key的数据元素在查找表中的位置
return i;
}
int main() {
SSTable *st;
int length;
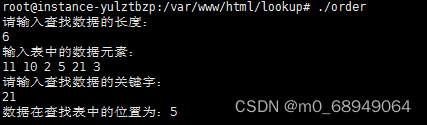
printf("请输入查找数据的长度:\n");
scanf("%d", &length);
create(&st, length);
printf("请输入查找数据的关键字:\n");
int key;
scanf("%d", &key);
int location = search_seq(st, key);
if (location == 0) {
printf("查找失败");
}else{
printf("数据在查找表中的位置为:%d \n\n",location);
}
return 0;
}输出结果:
2.2 二分查找(折半查找)
二分查找要求线形表中的结点按关键字值升序或降序排列,用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
过程说明:
对静态查找表{3,5,9,10,12,14,17,20,22,25,28}采用折半查找算法查找关键字为 10 的过程为:
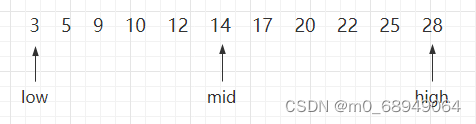
图 1 折半查找的过程(a)
如上图 1 所示,指针 low 和 high 分别指向查找表的第一个关键字和最后一个关键字,指针 mid 指向处于 low 和 high 指针中间位置的关键字。在查找的过程中每次都同 mid 指向的关键字进行比较,由于整个表中的数据是有序的,因此在比较之后就可以知道要查找的关键字的大致位置。
例如在查找关键字 10 时,首先同 14 作比较,由于10 < 14,而且这个查找表是按照升序进行排序的,所以可以判定如果静态查找表中有 10 这个关键字,就一定存在于 low 和 mid 指向的区域中间。
因此,再次遍历时需要更新 high 指针和 mid 指针的位置,令 high 指针移动到 mid 指针的左侧一个位置上,同时令 mid 重新指向 low 指针和 high 指针的中间位置。如图 2 所示:
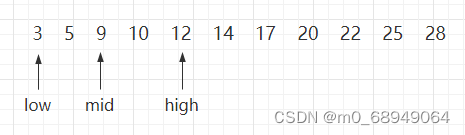
图 2 折半查找的过程(b)
同样,用 10 同 mid 指针指向的 9 作比较,9 < 10,所以可以判定 10 如果存在,肯定处于 mid 和 high 指向的区域中。所以令 low 指向 mid 右侧一个位置上,同时更新 mid 的位置。

图 3 折半查找的过程(3)
当第三次做判断时,发现 mid 就是关键字 10 ,查找结束。
注意:在做查找的过程中,如果 low 指针和 high 指针的中间位置在计算时位于两个关键字中间,即求得 mid 的位置不是整数,需要统一做取整操作。
c语言代码实例:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int key;//查找表中每个数据元素的值
//如果需要,还可以添加其他属性
}ElemType;
typedef struct{
ElemType *elem;//存放查找表中数据元素的数组
int length;//记录查找表中数据的总数量
}SSTable;
//创建查找表
void create(SSTable **st, int length){
(*st) = (SSTable*)malloc(sizeof(SSTable));
(*st)->length = length;
(*st)->elem = (ElemType*)malloc((length+1)*sizeof(ElemType));
printf("输入表中的数据元素:\n");
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
for (int i=1; i<=length; i++) {
scanf("%d",&((*st)->elem[i].key));
}
}
//折半查找算法
int search_bin(SSTable *ST, int key){
int low=1;//初始状态 low 指针指向第一个关键字
int high=ST->length;//high 指向最后一个关键字
int mid;
while (low<=high) {
mid=(low+high)/2;//int 本身为整形,所以,mid 每次为取整的整数
if (ST->elem[mid].key==key)//如果 mid 指向的同要查找的相等,返回 mid 所指向的位置
{
return mid;
}else if(ST->elem[mid].key>key)//如果mid指向的关键字较大,则更新 high 指针的位置
{
high=mid-1;
}
//反之,则更新 low 指针的位置
else{
low=mid+1;
}
}
return 0;
}
int main(int argc, const char * argv[]) {
SSTable *st;
int length;
printf("请输入查找数据的长度:\n");
scanf("%d", &length);
create(&st, length);
printf("请输入查找数据的关键字:\n");
int key;
scanf("%d",&key);
int location = search_bin(st, key);
//如果返回值为 0,则证明查找表中未查到 key 值,
if (location == 0) {
printf("查找表中无该元素");
}else{
printf("数据在查找表中的位置为:%d \n\n",location);
}
return 0;
}输出结果:

2.3 分块查找
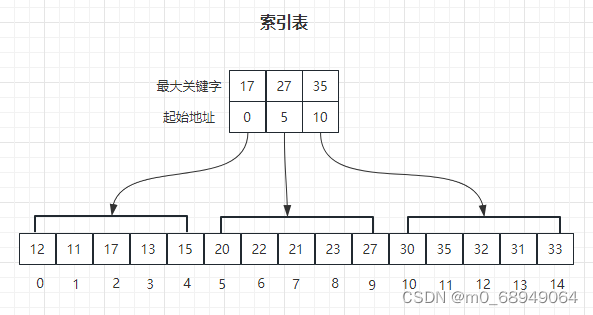
分块查找也称为索引查找,把线形分成若干块,在每一块中的数据元素的存储顺序是任意的,但要求块与块之间须按关键字值的大小有序排列,还要建立一个按关键字值递增顺序排列的索引表,索引表中的一项对应线形表中的一块,索引项包括两个内容:①键域存放相应块的最大关键字;②链域存放指向本块第一个结点的指针。分块查找分两步进行,先确定待查找的结点属于哪一块,然后在块内查找结点。
过程说明:
1、先选取各块中的最大关键字构成一个索引表。
2、查找分为两个部分,先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中。然后,在已确定的块中用顺序法进行查找。
c语言代码实例:
#include <stdio.h>
struct index /*定义块的结构*/
{
int key;
int start;
int end;
} index_table[4]; /*定义结构体数组*/
int block_search(int key, int a[]) /*自定义实现分块查找*/
{
int i, j;
i = 1;
while (i <= 3 && key > index_table[i].key) /*确定在那个块中*/
{
i++;
if (i > 3) /*大于分得的块数,则返回0*/
{
return 0;
}
j = index_table[i].start; /*j等于块范围的起始值*/
while (j <= index_table[i].end && a[j] != key) /*在确定的块内进行查找*/
{
j++;
if (j > index_table[i].end) /*如果大于块范围的结束值,则说明没有要查找的数,j置0*/
{
j = 0;
}
}
}
return j;
}
int main()
{
int i, j = 0, k, key, a[15];
printf("输入长度15的数据元素:\n");
for (i = 0; i < 15; i++)
{
scanf("%d", &a[i]); /*输入由小到大的15个数*/
index_table[i].start = j + 1; /*确定每个块范围的起始值*/
j = j + 1;
index_table[i].end = j + 4; /*确定每个块范围的结束值*/
j = j + 4;
index_table[i].key = a[j]; /*确定每个块范围中元素的最大值*/
}
printf("请输入要查找的关键字:\n");
scanf("%d", &key); /*输入要查询的数值*/
k = block_search(key, a); /*调用函数进行查找*/
if (k != 0)
{
printf("数据在查找表中的位置为:%d \n\n",k);
}else{
printf("未找到");
}
}输出结果:

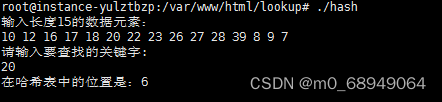
2.4 哈希表查找
哈希表查找是通过对记录的关键字值进行运算,直接求出结点的地址,是关键字到地址的直接转换方法,不用反复比较。假设f包含n个结点,为其中某个结点(1≤i≤n),
是其关键字值,在
与
的地址之间建立某种函数关系,可以通过这个函数把关键字值转换成相应结点的地址,有:addr(
)=H(
),addr(
)为哈希函数。
哈希地址只是表示在查找表中的存储位置,而不是实际的物理存储位置。f(x) 是一个函数,通过这个函数可以快速求出该关键字对应的的数据的哈希地址,称之为“哈希函数”。
2.4.1 常用的哈希函数的构造方法有 6 种:直接定址法、数字分析法、平方取中法、折叠法、除留余数法和随机数法。
构建哈希函数需要根据实际的查找表的情况采取适当的方法,通常考虑的因素有以下几方面:
- 关键字的长度。如果长度不等,就选用随机数法。如果关键字位数较多,就选用折叠法或者数字分析法;反之如果位数较短,可以考虑平方取中法;
- 哈希表的大小。如果大小已知,可以选用除留余数法;
- 关键字的分布情况;
- 查找表的查找频率;
- 计算哈希函数所需的时间(包括硬件指令的因素)
直接定址法:其哈希函数为一次函数,即以下两种形式:
H(key)= key 或者 H(key)=a * key + b
其中 H(key)表示关键字为 key 对应的哈希地址,a 和 b 都为常数。
例如有一个从 1 岁到 100 岁的人口数字统计表,如表 1 所示:

表 1 人口统计表
假设其哈希函数为第一种形式,其关键字的值表示最终的存储位置。若需要查找年龄为 25 岁的人口数量,将年龄 25 带入哈希函数中,直接求得其对应的哈希地址为 25(求得的哈希地址表示该记录的位置在查找表的第 25 位)。
数字分析法:如果关键字由多位字符或者数字组成,就可以考虑抽取其中的 2 位或者多位作为该关键字对应的哈希地址,在取法上尽量选择变化较多的位,避免冲突发生。
例如表 2 中列举的是一部分关键字,每个关键字都是有 8 位十进制数组成:

表 2
通过分析关键字的构成,很明显可以看到关键字的第 1 位和第 2 位都是固定不变的,而第 3 位不是数字 3 就是 4,最后一位只可能取 2、7 和 5,只有中间的 4 位其取值近似随机,所以为了避免冲突,可以从 4 位中任意选取 2 位作为其哈希地址。
平方取中法是对关键字做平方操作,取中间得几位作为哈希地址。此方法也是比较常用的构造哈希函数的方法。
例如关键字序列为{421,423,436},对各个关键字进行平方后的结果为{177241,178929,190096},则可以取中间的两位{72,89,00}作为其哈希地址。
折叠法是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。此方法适合关键字位数较多的情况。
例如,在图书馆中图书都是以一个 10 位的十进制数字为关键字进行编号的,若对其查找表建立哈希表时,就可以使用折叠法。
若某书的编号为:0-442-20586-4,分割方式如图 1 中所示,在对其进行折叠时有两种方式:一种是移位折叠,另一种是间界折叠:
- 移位折叠是将分割后的每一小部分,按照其最低位进行对齐,然后相加,如图 1(a);
- 间界折叠是从一端向另一端沿分割线来回折叠,如图 1(b)。

图 1 移位折叠和间界折叠
除留余数法:若已知整个哈希表的最大长度 m,可以取一个不大于 m 的数 p,然后对该关键字 key 做取余运算,即:H(key)= key % p。
在此方法中,对于 p 的取值非常重要,由经验得知 p 可以为不大于 m 的质数或者不包含小于 20 的质因数的合数。
随机数法:是取关键字的一个随机函数值作为它的哈希地址,即:H(key)=random(key),此方法适用于关键字长度不等的情况。
注意:这里的随机函数其实是伪随机函数,随机函数是即使每次给定的 key 相同,但是 H(key)都是不同;而伪随机函数正好相反,每个 key 都对应的是固定的 H(key)。
2.4.2 处理冲突的方法
对于哈希表的建立,需要选取合适的哈希函数,但是对于无法避免的冲突,需要采取适当的措施去处理。
通常用的处理冲突的方法有以下几种:
- 开放定址法 H(key)=(H(key)+ d)MOD m(其中 m 为哈希表的表长,d 为一个增量) 当得出的哈希地址产生冲突时,选取以下 3 种方法中的一种获取 d 的值,然后继续计算,直到计算出的哈希地址不在冲突为止,这 3 种方法为:
- 线性探测法:d=1,2,3,…,m-1
- 二次探测法:d=12,-12,22,-22,32,…
- 伪随机数探测法:d=伪随机数

图 2 开放定址法
注释:在线性探测法中,当遇到冲突时,从发生冲突位置起,每次 +1,向右探测,直到有空闲的位置为止;二次探测法中,从发生冲突的位置起,按照 +12,-12,+22,…如此探测,直到有空闲的位置;伪随机探测,每次加上一个随机数,直到探测到空闲位置结束。
- 再哈希法
当通过哈希函数求得的哈希地址同其他关键字产生冲突时,使用另一个哈希函数计算,直到冲突不再发生。 - 链地址法
将所有产生冲突的关键字所对应的数据全部存储在同一个线性链表中。例如有一组关键字为{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函数为:H(key)=key MOD 13,使用链地址法所构建的哈希表如图 3 所示:
图 3 链地址法构建的哈希表
- 建立一个公共溢出区
建立两张表,一张为基本表,另一张为溢出表。基本表存储没有发生冲突的数据,当关键字由哈希函数生成的哈希地址产生冲突时,就将数据填入溢出表。
c语言代码实例:
#include "stdio.h"
#include "stdlib.h"
#define HASHSIZE 15 //定义散列表长为数组的长度
#define NULLKEY -1
typedef struct{
int *elem;//数据元素存储地址,动态分配数组
int count; //当前数据元素个数
}HashTable;
//对哈希表进行初始化
void init(HashTable *hashTable){
int i;
hashTable->elem= (int *)malloc(HASHSIZE*sizeof(int));
hashTable->count=HASHSIZE;
for (i=0;i<HASHSIZE;i++){
hashTable->elem[i]=NULLKEY;
}
}
//哈希函数(除留余数法)
int Hash(int data){
return data % HASHSIZE;
}
//哈希表的插入函数,可用于构造哈希表
void insert(HashTable *hashTable,int data){
//求哈希地址
int hashAddress=Hash(data);
//发生冲突
while(hashTable->elem[hashAddress]!=NULLKEY){
//利用开放定址法解决冲突
hashAddress=(++hashAddress)%HASHSIZE;
}
hashTable->elem[hashAddress]=data;
}
//哈希表的查找算法
int search(HashTable *hashTable,int data){
//求哈希地址
int hashAddress=Hash(data);
//发生冲突
while(hashTable->elem[hashAddress]!=data){
//利用开放定址法解决冲突
hashAddress=(++hashAddress) % HASHSIZE;
//如果查找到的地址中数据为NULL,或者经过一圈的遍历回到原位置,则查找失败
if (hashTable->elem[hashAddress] == NULLKEY || hashAddress==Hash(data)){
return -1;
}
}
return hashAddress;
}
int main(){
int i, result, key;
HashTable hashTable;
int arr[HASHSIZE];
printf("输入长度15的数据元素:\n");
for (i = 0; i < 15; i++)
{
scanf("%d", &arr[i]); /*输入由小到大的15个数*/
}
//初始化哈希表
init(&hashTable);
//利用插入函数构造哈希表
for (i=0;i<HASHSIZE;i++){
insert(&hashTable,arr[i]);
}
//调用查找算法
printf("请输入要查找的关键字:\n");
scanf("%d", &key); /*输入要查询的数值*/
result= search(&hashTable, key);
if (result==-1){
printf("查找失败");
}
else {
printf("在哈希表中的位置是:%d \n\n", result+1);
}
return 0;
}输出结果: