【摘要】大型语言模型 (LLM) 已显示出生成流畅且有说服力的内容的能力,这既带来了生产力机会,也带来了社会风险。要构建值得信赖的 AI 系统,必须区分机器生成的内容和人类创作的内容。领先的零样本检测器 DetectGPT 展示了值得称赞的性能,但其密集的计算成本却使其受损。在本文中,我们引入了条件概率曲率的概念,以阐明给定上下文中 LLM 和人类之间的词汇选择差异。利用此曲率作为基础指标,我们提出了 Fast-DetectGPT,这是一种优化的零样本检测器,它用更高效的采样步骤替代了 DetectGPT 的扰动步骤。我们对各种数据集、源模型和测试条件的评估表明,Fast-DetectGPT 不仅在白盒和黑盒设置中相对超过 DetectGPT 约 75%,而且将检测过程加快了 340 倍,如表 1 所示。
原文:Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
地址:https://arxiv.org/abs/2310.05130
代码:https://github.com/baoguangsheng/fast-detect-gpt
出版:Published as a conference paper at ICLR 2024
机构: Westlake University, Shanghai Polytechnic University更多文章解读,欢迎关注公众号“码农的科研笔记”
1 研究问题
本文研究的核心问题是: 如何高效地实现对机器生成文本的零样本检测。
假设某大型语言模型(如GPT-4)生成了一篇新闻报道,我们希望判断该报道是机器生成还是人工撰写。但问题是我们手头并没有GPT-4生成的文本样本来训练一个检测器。这时就需要一种"零样本"的检测方法,即无需使用目标模型的训练样本,而是利用某些通用的文本特征来进行判别。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
机器生成文本在流畅性和连贯性上已经接近甚至超越人类水平,很难从表面特征上进行区分。这对传统的基于语法、词汇等浅层特征的检测方法提出了挑战。
-
不同领域、语言、模型生成的文本具有不同的特点,很难找到一种通用的判别特征。这导致基于特定领域或模型训练的检测器很难迁移到新的场景中。
-
现有的零样本检测方法如DetectGPT虽然效果不错,但需要对每个待检测样本生成大量扰动,导致计算开销非常大。如何在保持检测精度的同时大幅降低计算成本是一个关键挑战。
针对这些挑战,本文提出了一种高效而精准的"Fast-DetectGPT"方法:
Fast-DetectGPT巧妙地利用了语言模型中蕴含的条件概率曲率信息。它的核心洞见是:人类和机器在给定上下文下对下一个词的选择存在系统性差异。机器倾向于选择概率更高的词,而人类则更看重词语搭配是否符合特定语义。因此,如果我们画出给定上下文下,目标词相对于其他备选词的条件概率优势,就会发现机器生成文本在目标词处呈现出正曲率,而人类书写文本则接近于零曲率。借助对负采样的巧妙设计,Fast-DetectGPT只需对目标文本做一次前向推理,就能估计出其条件概率曲率,从而实现了相比DetectGPT约340倍的加速。同时,它在新闻、故事、百科、生物医学等多个领域和英语、德语等多种语言上都实现了显著优于DetectGPT的检测精度。Fast-DetectGPT犹如一个经验丰富的文字"鉴定家",通过敏锐地捕捉词语选择的细微差异,以最经济高效的方式揭示文本的真实出处。
2 研究方法
本文聚焦于机器生成文本的零样本检测任务,即在不使用任何机器生成文本进行训练的情况下,判断一段给定文本是由人类还是机器生成。根据是否可以访问生成文本所用的源模型,可分为白盒和黑盒两种检测场景。在白盒场景下,检测器可以利用源模型进行评分以辅助做出判断;而在黑盒场景下,检测器无法获取源模型的任何信息,需要依赖于其他替代模型进行评分。
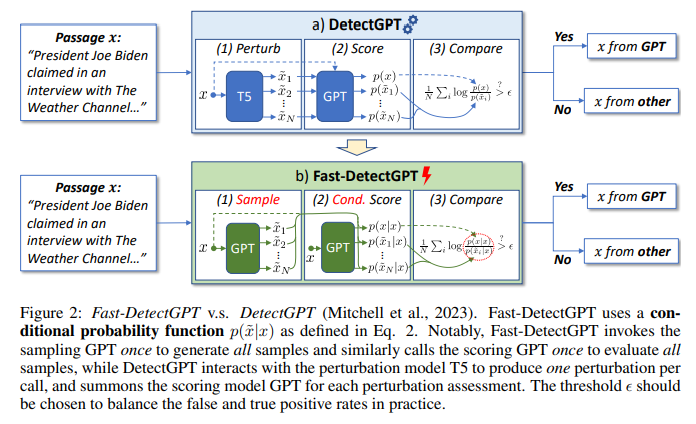
现有的领先零样本检测方法DetectGPT基于以下假设:机器生成文本的变体通常比原文具有更低的模型概率,而人类书写文本则无此特点。如图2(a)所示,其检测流程包括三个步骤:
-
扰动(Perturb):使用预训练的掩码语言模型(如T5)生成输入文本的多个略微改写的变体;
-
评分(Score):使用预训练的自回归语言模型(如GPT)评估原文本及其变体的概率;
-
比较(Compare):比较原文本与变体的概率差异,据此估计概率曲率,做出机器生成或人类书写的判断。
尽管DetectGPT在多个数据集上取得了不错的检测性能,但其需要调用模型上百次来生成扰动的变体文本并进行评分,导致了极大的计算开销。针对这一问题,本文提出了一种新的假设来检测机器生成文本。通过将文本生成视为一个基于token的序列决策过程,我们认为: 给定上下文时,人类和机器在选择token方面存在显著差异。具体而言,机器由于在大规模人类书写语料上进行了预训练,因此倾向于选择具有更高统计概率的词;而人类则是基于语义、意图和语境来构造句子,个体并不存在这种偏好。
基于以上假设,本文提出了Fast-DetectGPT方法。其核心是通过比较候选文本passage中每个位置的token与其他可能的替代token的条件概率差异,来估计passage在该位置的条件概率曲率。形式化地,给定passage 和可能的源模型θ,Fast-DetectGPT定义条件概率曲率为:
θϕθμσ
其中μϕθ表示由采样模型ϕ生成的替代样本的条件对数概率的期望,σϕθμ为其方差。直观而言,如果passage 的条件对数概率θ显著高于替代样本的平均水平μ,即曲率为正值,则很可能是由模型θ生成的;反之如果两者相近,即曲率接近0,则更可能出自人手。
图2(b)展示了Fast-DetectGPT的三步检测流程:
-
条件采样(Sample):使用采样模型ϕ在passage的每个位置独立地采样生成替代token,得到大量的样本;
-
条件评分(Conditional Score):将passage输入评分模型θ进行一次前向计算,即可得到passage和所有样本的条件概率;
-
比较(Compare):将passage和样本的条件概率代入曲率公式进行计算,据此做出判断。

算法1详细描述了Fast-DetectGPT的实现流程。值得一提的是,在Fast-DetectGPT中,条件采样步骤可以通过PyTorch的高效采样函数实现,生成10000个样本仅需一行代码:
samples = torch.distributions.categorical.Categorical(
logits=lprobs).sample([10000])
通过这种条件独立采样,Fast-DetectGPT只需调用评分模型一次,即可评估所有的样本,从而大大提升了检测效率。
此外,有趣的是,当采样模型和评分模型相同时,Fast-DetectGPT的条件概率曲率与Likelihood和Entropy两个基线方法存在紧密联系。具体而言,公式中的θ对应Likelihood,而μ对应Entropy。这两个传统的基线方法被认为是检测机器文本的基础特征,而Fast-DetectGPT巧妙地将二者结合,并通过标准化进一步提升了检测性能。
综上所述,Fast-DetectGPT利用了一个新的人机选词差异假设,并基于条件概率曲率实现了一种简单、高效、鲁棒的零样本机器文本检测方法。相比DetectGPT,其在保持较高检测精度的同时,将检测速度提升了两个数量级。Fast-DetectGPT为构建可信赖的人工智能系统提供了新的思路。
3 实验
3.1 实验场景介绍
该论文提出了一种基于条件概率曲率的快速检测机器生成文本的方法Fast-DetectGPT。论文的实验部分主要验证了Fast-DetectGPT在不同场景下的检测性能,包括白盒和黑盒检测,不同长度文本的检测,跨领域和语言的泛化,以及面对各种生成策略和对抗攻击的鲁棒性。
3.2 实验设置
-
Datasets: XSum(新闻摘要)、SQuAD(维基百科问答)、WritingPrompts(故事写作)、WMT16(英语德语翻译)、PubMedQA(生物医学领域问答)
-
Baseline: 零样本检测器DetectGPT、NPR、DNA-GPT;有监督检测器GPT-2 detector(基于RoBERTa)、GPTZero
- Implementation details:
-
白盒设置:使用源模型做采样和评分
-
黑盒设置:使用替代模型做采样和评分
-
对比DetectGPT:使用T5做扰动,GPT做评分
-
-
metric: AUROC(ROC曲线下面积),可同时评估不同阈值下的真假阳性率
-
环境:在Tesla A100 GPU上进行计算
3.3 实验结果
实验一、在开源语言模型上的检测效果

目的:评估Fast-DetectGPT在GPT-2、OPT-2.7、Neo-2.7、GPT-J、NeoX生成文本上的检测效果,并与DetectGPT对比
涉及图表:表2
实验细节概述:在每个源模型上生成150-500个样本作为阳性类,再从数据集中随机抽取等量人类书写文本作为阴性类,分别在白盒和黑盒设置下评估Fast-DetectGPT和DetectGPT的AUROC
结果:
-
白盒设置下,Fast-DetectGPT平均AUROC达到0.9887,比DetectGPT的0.9554提升了相对74.7%
-
黑盒设置下,Fast-DetectGPT平均AUROC为0.9677,比DetectGPT的0.8736提升了相对76.1%
-
Fast-DetectGPT的推理速度比DetectGPT快340倍
实验二、在GPT-3、ChatGPT和GPT-4上的检测效果
目的:评估Fast-DetectGPT在GPT-3、ChatGPT、GPT-4生成文本上的检测效果,并与有监督检测器对比
涉及图表:表3
实验细节概述:用ChatGPT和GPT-4分别生成新闻、故事和医学问答领域的文本,每个领域150个样本。所有方法均使用黑盒设置。
结果:
-
Fast-DetectGPT在ChatGPT上平均AUROC为0.9615,比DetectGPT的0.8223高78.3%;在GPT-4上为0.9061,比DetectGPT高75.1%
-
Fast-DetectGPT整体超过了有监督的RoBERTa和GPTZero检测器
-
在1%误报率下,Fast-DetectGPT可检测出87%的ChatGPT生成文本;在10%误报率下,可检测出89%的GPT-4生成文本
实验三、可用性分析
目的:全面评估Fast-DetectGPT的实用性
涉及图表:图3、图4、图5
实验细节概述:
-
不同阈值下的精确率和召回率:绘制ROC曲线分析不同阈值的效果
-
不同长度文本的检测效果:将文本截断到不同长度评估AUROC
-
跨领域和语言的泛化性:在新闻、医学问答、英语、德语4个数据集上对比Fast-DetectGPT和有监督检测器
-
面对不同解码策略的鲁棒性:对比top-k采样、top-p采样、不同温度采样下的AUROC
-
面对对抗攻击的鲁棒性:使用T5做句子级别的释义攻击,随机交换相邻单词做去连贯性攻击
结果:
-
Fast-DetectGPT的AUROC随文本长度单调递增,表现出更好的稳定性
-
Fast-DetectGPT在跨领域和语言上明显优于有监督检测器,泛化性更好
-
Fast-DetectGPT在各种采样策略下依然保持优势,相对提升95%、81%、99%
-
在释义攻击下,Fast-DetectGPT从0.9641降到0.8715,相对下降最小;去连贯性攻击进一步验证了释义攻击主要影响连贯性
4 总结后记
本论文针对零样本检测机器生成文本的问题,提出了一种基于条件概率曲率(conditional probability curvature)的高效方法Fast-DetectGPT。通过度量给定上下文下机器和人类在词选择上的差异,Fast-DetectGPT在white-box和black-box两种设定下将检测准确率相对提高了约75%,同时将检测速度提高了340倍。实验结果表明,所提方法能够以更高效、更准确的方式区分机器生成文本和人类书写文本。
疑惑和想法:
-
除了token粒度的条件概率,是否可以设计出其他粒度(如phrase-level、sentence-level)的特征?它们在检测效果上是否有差异?
-
对于black-box设定,目前采用代理模型进行打分,如何选取最优的代理模型仍有待进一步研究。不同代理模型的选择是否会影响检测性能?
-
能否将Fast-DetectGPT的思想与现有的有监督检测器相结合,进一步提升检测性能和泛化能力?
可借鉴的方法点:
-
将统计特征与大语言模型相结合的思路值得借鉴,可以设计出更多形式的零样本检测方法,应用于其他需要鉴别机器生成内容的场景,如假新闻检测、学术抄袭检测等。
-
条件概率曲率作为一种衡量上下文相关性的指标,可以推广到其他需要度量文本局部一致性的任务中,如文本匹配、文本纠错等。
-
充分利用白盒模型API暴露的统计信息,设计更高效、更可解释的检测方案,为构建可信的人工智能系统提供支持。